May 6-10, 1996, Paris, France
Andersen Consulting
3773 Willow Rd
Northbrook, IL 60062
jin.w.chang@ac.com, colin.t.scott@ac.com
The Technology Reinvestment Project Support Environment ( TSE ) introduces the notion of "agent - based workflow" in order to facilitate various parts of workflow process. Unlike some of the well known groupware products such as InterNotes or Web Forum which simply provide a passive information space, the goal of TSE is to enable active collaborative work among participants working on the TRP's "component based software engineering environment".
keywords - agent, collaboration, workflow.
The mission of the Technology Reinvestment Project ( TRP ) at Andersen Consulting is to provide an extensible set of tools which support heterogeneous, component-based software solutions. The basic foundation for the above software solution is an extension of Andersen's own Eagle Process which defines various processes such as initial business modeling, as well as software lifecycle activities such as object oriented analysis and design. The efforts in the TRP Support Environment ( known as TSE ) are intended to support the above processes by providing a collaborative environment among participants allowing them to transcend the requirements of being in the same place and working together at the same time. Unlike some of the well known groupware products such as InterNotes or Web Forum which simply provide a passive information space, the goal of TSE is to enable active collaborative work among participants working on the TRP's "component based software engineering environment". The active collaboration implies that the system knows the importance of individual work items and dynamically organizes a person's agenda based on that knowledge. In addition, the system also monitors any changes in the status of relevant deliverables and deliberations involved with work processes in order to notify the appropriate participants.
The core concept of TSE is based on the WWW and a distributed set of agents which facilitate various parts of workflows in order to improve efficiency among participants and that of overall process. Although the original concept of an agent, "acting on behalf of someone else" is simply lost in current A.I research on agents, it is precisely this notion which TSE adopts. In other words, the agents in TSE largely act on behalf of participants, organizing their agenda, looking for important events ( such as a deliverable is complete ), and advising steps necessary to accomplish a given task.
The concept of agent, in particular that of a mobile agent which travels around the network on behalf of its owner, has gained significant interest in various areas of computation such as artificial intelligence,[1] distributed computing and communications. Consequently, there have been multiple publications regarding mobile agents, and the benefits seemed obvious for a collaborative environment. Indeed, the issues for mobile agents have been discussed and the requirements for an agent infrastructure ( so called agent meeting point ) were investigated by Eichmann and Chess et al., respectively.[8] [9] Additionally, the infrastructure was later extended by Goldszmidt and Yemini to encompass real-time control [10] and recently, Anselm Lingnau et al. proposed an architecture based on WWW and HTTP protocols.[11]
Unfortunately, these publications have largely ignored the details of workflow processes involved with mobile agents. For example, a typical organization usually has its own workflow processes defining business activities and overall control flow of work. It seems reasonable to assume that mobile agents in an active collaborative environment should have process information embedded within themselves in order to find a target destination once an activity has been initiated. Additionally, a mobile agent must know the various characteristics of the actual roles involved with workflow processes. For example, a mobile agent at a project leader's machine may have all the access privileges to a deliverable schedule while a mobile agent at a programmer's may not. Obviously, this difference is not bound to a actual machine but by the roles participants play. In fact, if a programmer is allowed to act as a project leader ( perhaps, because a project leader is sick ), a mobile agent must change its characteristics dynamically in order to avoid any disruptions in the workflow process.
It has been suggested that the "next generation" of workflow tool has to be able to reconcile workflow process models and software with a rich variety of activities and behaviors that comprise "real" work.[12] This implies that workflow system not only has to be able to integrate other softwares with standardized interfaces and interchange formats but also has to provide capabilities to handle informal processes, "occasionally attached" processes, or processes that are not fully defined. Unfortunately, current workflow systems lack most of the above capabilities. Current systems largely assume a closed network where all software is available on a homogeneous platform and all participants are locally linked together at the same time.
The notion of a mobile agent, on the other hand, provides an elegant way of executing processes across spatial and temporal spaces. By traveling to the machine and executing locally, it enables participants to transcend the requirements of being in the same place and working together at the same time. Unfortunately, if a mobile agent is to provide full execution functionalities of workflow, it will simply be too inefficient. Additionally, the notion of an agent server in order to manage a definition, instantiation, and the execution of mobile agent becomes crucial, and consequently, the existing HTTP protocol has to be augmented in order to support the above activities.[11]
For these reasons, the approach in TSE adopted the concept of "agent - based workflow". The advantage for such hybrid system is that by utilizing an existing workflow tool, a workflow agent ( or an agent server in the sense of [11] ) can simply be a facilitator agent providing interfaces between agents and the workflow tool. Thus, a mobile agent can interface with a workflow agent in order to retrieve necessary information such as time constraints, dependencies, destinations, skill requirements, and priorities. Additionally, by utilizing the Workflow Management Coalition's recently proposed APIs, a workflow agent can provide an uniform interface to any of the existing workflow tools without knowledge of their internals.
Within TSE, there are multiple authoritarian agents ( AA ), actor agents ( ACA ) and personal agents ( PA ) for each user. The personal agent is responsible for organizing a user's agenda and for communicating with multiple actor agents and an actual participant. The actor agents are mobile agents which act on behalf of certain roles such as object modeler or application developer and communicate with multiple authoritarian agents as well as a personal agent. The authoritarian agents are autonomous processes running on a network which offer a specialized set of valuable functions in a specific domain.
All of the agents in TSE whether they are AA, ACA or PAs, shares some common characteristics including:Authoritarian agents usually work as facilitators for a set of specialized functions such as workflow, communication, integrated performance support, and deliberation. Authoritarian agents typically know how to retrieve valuable information either from existing tools or from their own repository. In this regard, an authoritarian agent is like an expert for a specific domain.
Authoritarian agents work as cgi programs basically taking 2 arguments - one for the performative, and the other for the content. The performative determines the type of a speech act while the contents are used for sharing knowledge. Once invoked, the authoritarian agents review their messages, consult their own virtual knowledge bases, translate the domain knowledge into TACL and communicate the knowledge to other agents.
One of the most important authoritarian agents is a workflow agent. A workflow agent interfaces with an existing workflow repository through the standard Workflow Management Coalition APIs ( WfMC API ). A workflow AA communicates various properties of workflow processes such as definitions, actors, applications and deliverables. The existing workflow tool ( any of them as long as they conform with WfMC API ) actually manages the repository, while the workflow AA simply acts as an facilitator providing an interface between other agents and the workflow tool.
A communication agent is responsible for overall communication between multiple PAs and between PAs and AAs. A communication agent contains a current registry of all connected agents and works as a facilitator between multiple PAs and authoritarian agents. Thus, a communication agent enables anonymous agent interactions which support location transparency of service, request decomposition, content based routing and perspective translation. For example, when a PA updates a requirement change, communication agent notifies all influenced PAs and a workflow AA.
A storage agent is responsible for providing a uniform access mechanism ( in this case, simply HTTP protocol ) to multiple project database systems. A storage agent will interface with the various generic database APIs and offer various storage related functions such as queries, insertion and replication of components and other work items. Since a storage agent provides database independent protocols, the other agents can simply communicate without knowing the details of the underlying database schemes.
An integrated performance support agent ( IPS AA ) is responsible for context sensitive help and guidance, explanation and tutoring related to the overall TRP process. It retrieves various information on TRP processes based on the WfMC APIs, and guides a participant efficiently. An IPS AA interfaces with CoGenTex's Model Explainer [13] in order to generate natural language descriptions of the object models developed through TRP's component specification tool.
A M-Remap ( meta remap ) agent is responsible for managing overall deliberations involved with various workflow processes. The deliberation agent works with a revised IBIS [2] model in order to provide traceability of the overall deliberations involved with various workflow processes. Unlike some of the deliberation management tools such as REMAP [3] ( a derivation of IBIS ) where the deliberation process is largely limited to the analysis process, the deliberations in TSE can occur at any part of the workflow processes. The deliberation agent is also a facilitator agent which provides an interface to the existing issue management systems such as TRP-REMAP.
An actor agent may be viewed as a specific instance of a personal agent with a certain role such as object modeler. An actor agent has a list of goals, tasks and a process in which a specific role is involved just like an individual working for a designated workflow process. Actor agents are mobile agents because they may travel around a network, and also process agents because they already have builtin processes - in other words, they already know where to go and who to talk to. A similar analogy can be made from an individual working in any business organization - for example, a manager knows where to go and who to talk to in order to get his budget approved.
Actor agents get instantiated when the associated process is created. When the execution is complete, the status of the tasks in the process is updated. Each instance of an actor agent has an unique ID and its behaviors may be changed by simply re-defining the default goals and the definition of the associated process. The actor agents in TSE are mostly derived from the TRP processes for various actors such as functional architect or object modeler.
Personal agents act on behalf of actual participants. A personal agent represents an actual individual in a business organization with multiple roles ( actor agents ). Upon login, the personal agent consults a user profile which contains a list of preferred tools, authoritarian agents and their locations, local host name and address, name of HTTP server and port number, a user skills, WWW browser of choice, etc. After determining the address of workflow AA, the personal agent communicates to retrieve the participant's agenda list from the workflow AA. Based on this agenda list and a user profile, the personal agent constructs HTML pages and invokes WWW browser for those pages.
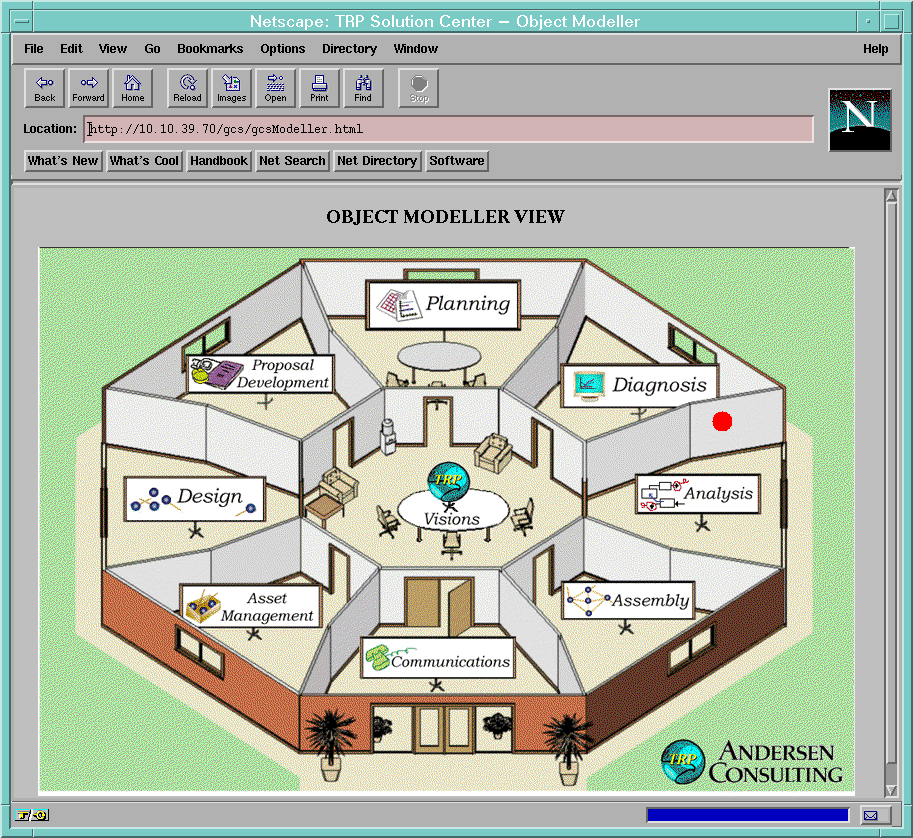
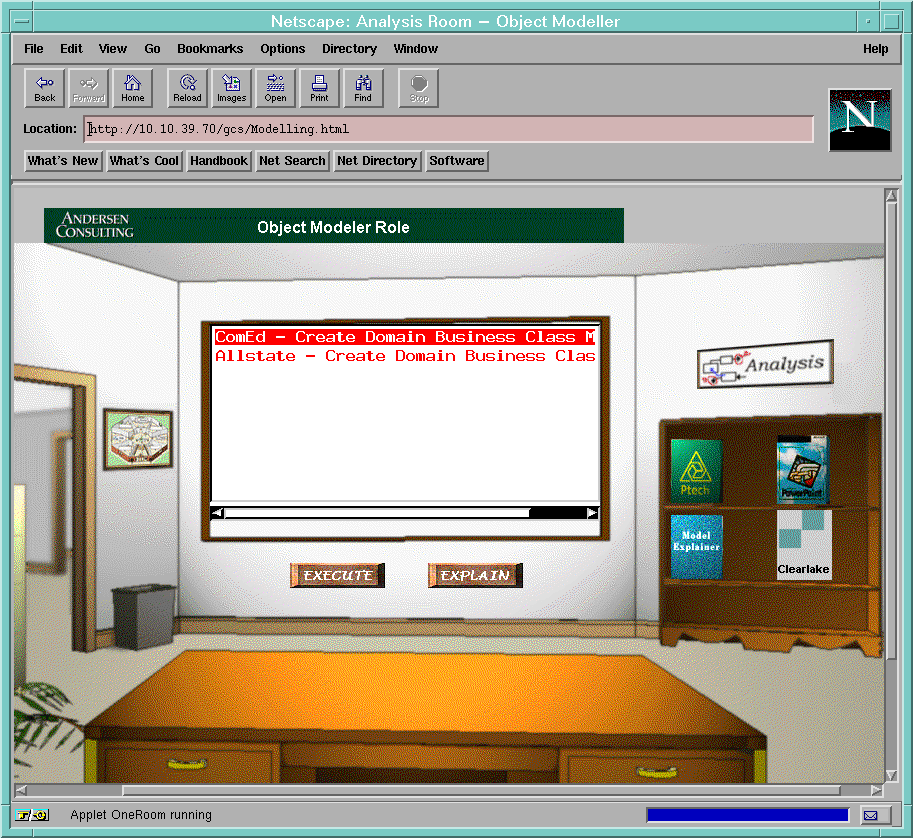
The overview page and the agenda page are shown in figure-1 and figure-2 ( see Figure section ). The initial overview page is based on the "room" metaphor which represents the patterns of various meta level activities in software engineering lifecycle. The "red dot" in the specific room ( i.e., analysis room ) shows that there are some tasks which can be identified by the specific pattern of activities - analysis. The agenda page allows a user to be able to invoke various tools of his choice ( by simply clicking a tool icon such "Microsoft Word" from a bookshelf ) and to view deliverables based on time, priority and the overall process ( by Explain button ). Additionally, personal agent allows the user to schedule informally planned tasks ( i.e., personal tasks or tasks that are not yet a part of overall workflow processes. )
The communication between agents is text-based since this requires minimal modifications to the HTTP protocol and allows participants to understand the context in which agents communicate. The basic performatives in agent communication are tell and ask. The tell performative is used to record the various forms of knowledge while the ask performative is used to query the encoded knowledge. Although there are other performatives [4] that may be useful in describing agent communication, the TSE only supports these two performatives. This is because reasoning with a model of workflow processes does not demand the full spectrum of conversation performatives and the well known performatives such as deny sometimes lacks precise semantics.[7]
All messages between agents are marked with Greenwich mean time in order to avoid the time differences between agents located at remote sites. Although it will be useful for agents to understand various temporal relations as in [5], agents generally prefer to believe the latest message in order to resolve any conflicts. Obviously, this implies that all agents are updated simultaneously which may be an unreasonable assumption in practice. As a result, the notion of tolerable time difference is adapted. The tolerable time difference specifies the time interval in which agents can safely prefer to believe the latest message from the previous.
The content of knowledge for the above two performatives is encoded in the form of basic workflow entities. The notion of workflow entities is derived from the epistemic computation [6] and it is recursively defined as a pair of workflow entities and binary relationships between them. Unlike well known knowledge interchange formats such as KIF, workflow entities are simpler, yet they provide built-in semantics such as inheritance, attribute ownership and precedence.
Using an analogy from first order logic, workflow entities are classified as term, atomic, compound ( although this is not defined in first order logic, it just semantically makes sense ) or contextual. The terms are simply workflow entities which refer to nouns and pronouns in our natural language such as "scenario", "organization", or "deliverable". The atomic workflow entities consist of a couple of term workflow entities and a relation. Thus, an atomic workflow entity has the form of "Ea r Eb." where Ea , Eb are both terms and r is a relation. An example for atomic workflow entities may be "object_modeling requires scenario.". The notion of compound workflow entities has the form, Ea r1 (Eb r2 Ec ) where each of Es is recursively defined. The contextual workflow entities have a basic form of { ( Ea r Eb )*}. As an example, a contextual workflow entity for "object_modeler" may be { Object_modeler analyzes objects. Object_modeler analyzes actors. Object_modeler writes ( scenario contains actors ). }. It can be immediately noticed that contextual workflow entities are similar to a set of formulas in first order logic.
The relations refer to the principal part of a verb ( such as "be" instead of "is" or "are") in our natural language and express semantic associations between workflow entities. Relations may have many aliases - for example, the relation symbol, ">" may have an alias symbol, "is greater than". Although the syntactical flexibility is never intended, the aliases may be particularly useful during communication. In order to facilitate non-ambiguous parsing of the workflow entities, the relation may need to be denoted by "[ ]". Obviously, in the case of atomic workflow entities ( i.e., non-recursive workflow entities ), it does not needed to be denoted by "[ ]".
In workflow entities, there are number of built-in relations shown below to enrich the semantics involved with overall agent communication.
The notion of "or join" or "and join" can be simply specified either using multiple "require" workflow entities or a contextual workflow entity, respectively. As an example, when "review scenario" require { scenario, "business goals" }., it assumes both scenario and "business goals" are required ( "and join" ). On the other hand, when "review scenario" require scenario. and "review scenario" require "business goals"., it assumes either scenario or "business goals" is required ( "or join" ).
Variables are used to "ask" about the encoded knowledge and are instantiated when appropriate knowledge is found. The variables are represented by prefixing any symbols with "_" ( underscore ) and the instantiated variables return workflow entities. This implies that the instantiated variable could be any form of workflow entities including a contextual workflow entities. Anonymous variable ( simply represented as "_") acts like anonymous variables in logic programming except again, they are used to represent a workflow entity.
Typical "tell" performative can be simply accomplished by ending it with a period (.) and ask performative, with a question mark (?). The tell performative is used to record the various forms of workflow entities while the ask performative is used to query the encoded workflow entities. The variables can occur at either performatives and they are instantiated when the response is formed after the communication is initiated. For example, the tell performative may be "object_modeling.", "Object_modeling requires scenario." or "{ object_modeling. Object_modeling requires scenario. }" while the ask performative can be "object_modeling?", "_what requires scenario?" or "_every_goals?".
In the case of queries where there is no instantiated variables such as "object_modeling?", it semantically implies that "Is there an encoded workflow entity called object_modeling?". The answer may be "{yes. object_modeling}" which implies that the workflow entity called object_modeling is encoded or "{no. unknown.}" which implies that the workflow entity called object_modeling is not encoded and it is unknown.
The ask performative can be either compound such as "Object modeling" require (scenario have _what)? or contextual, such as { _what? _what requires scenario? } In the case of compound, the ask performative only applies to the surface level relation. In other words, the ask performative in the above workflow entity, "Object_modeling" require ( scenario have _what )? implies that what is the workflow entity which is required by the "object modeling" and has the structure of "scenario have _what". For the ask performative in contextual workflow entity, the instantiated value of a variable has to satisfy all of its occurrences in contextual workflow entities.
Below is the grammar for the workflow entities and relations described in earlier sections.
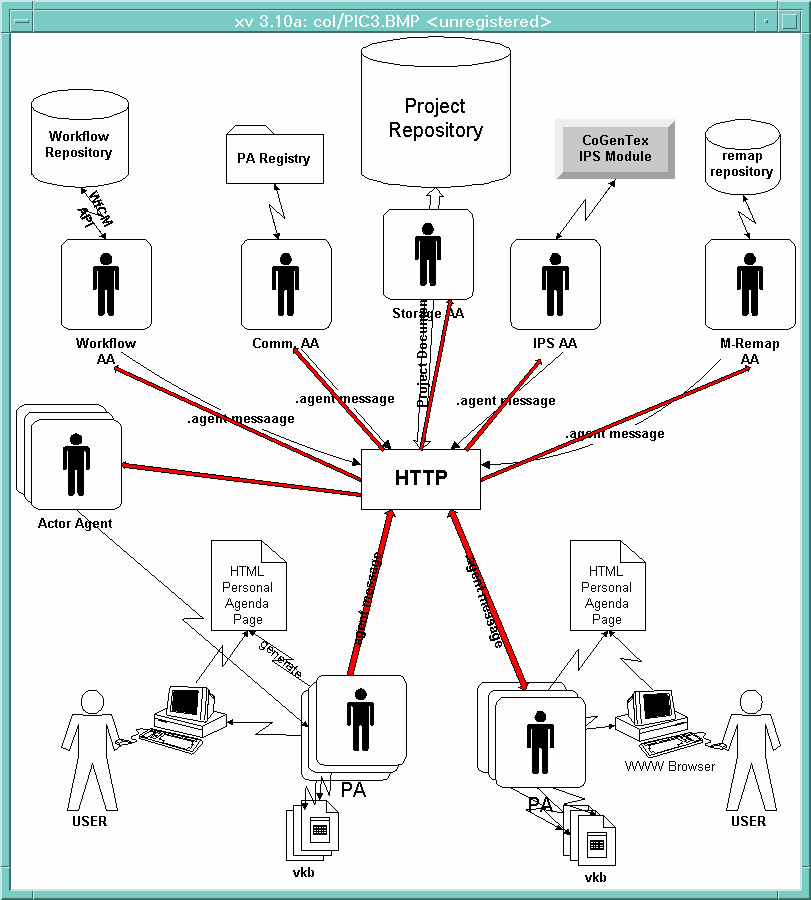
The above architecture has not made any explicit assumptions about WWW or HTTP, therefore, it can potentially be implemented in any platform which support multi-threading and messaging. However, the popularity of the WWW, and the availability of HTTP present a readily available platform for TSE. In addition, the available JAVA embedded WWW browsers such as Netscape allow easy development of integrated TSE across heterogenious platforms. The overall architecture based on WWW and HTTP is shown in figure-3 ( see Figure section ).
The agents in TSE commmunicate using TACL based on HTTP protocol. The TACL message using HTTP protocol is structured based on the machine name, port address, agent id and a message - "http://machine_name:port/agent_name/TACL_message". For example, a personal agent may send a request to a workflow AA asking about the tasks list for the specific user such as "http://machine_foo:7777 /workflow_aa_1/TACL/{ Tom be actor. _Task_list be task? _Task_list have Tom? }".
The following describes simple scenario involved with a object modeling process where 2 participants named Tom and Jon collaborate.
First, assume following workflow entities and Greenwich mean time being represented as a simple integer:
"Object modeling" be process. "Object modeling" have { "write scenario". "review scenario". }.
"Write scenario" be task. "Review scenario" be task. Task have status.
"Write scenario" have actor. "Review scenario" have actor.
{ "Write scenario" produce scenario. "Review scenario" produce comments. "Review scenario" require scenario. }
{ "Write scenario" require "word processor". "Review scenario" require "word processor" "Word processor" be application. }
{ "Word processor" have executable. Word.exe be executable. }
Given the above definition, assume that workflow AA is called to create instances of object modeling process, write scenario and review scenario tasks for specific project, ABC. They are specified as:
{ ABC be project. "Test object modeling" be "object modeling". "Write test scenario" be "write scenario". "Review test scenario" be "review scenario". } { "Write test scenario" have { status, actor }. Tom be actor. Ready be status. } { "Review test scenario have { status, actor }. Jon be actor. Wait be status. }
Now examine a simplified scenario for baselining an object model. Assume that every object modelers have to approve the model in order to baseline it. One can imagine where both Tom and Jon have different skills and as a result, treated differently in the process. However, such details are omitted from the following example.
Assume the following workflow entities - Tom be "object modeler". Jon be "object modeler".
The initial release of TSE has been implemented with JAVA, C++ and Netscape as a WWW browser. The system is being delivered to be used in a real development environment at Raytheon as a part of the TRP at the end of April, 1996. Unfortunately, the notion of a storage AA and its scope with the TRP project is still being determined. Therefore, the first release of TSE employ a primitive storage AA which saves, deletes and retrieves project related files.
Although there are some security constraints involved with JAVA applets and a WWW browser such as Netscape which prohibit an elegant solution to many of TSE's detail implementation ( such as its inability to read a file), the agent - based workflow on WWW offers a promising way of helping individuals manage their work by providing a clear context for performing that work.
[1] Riecken, D., Intelligent Agents, CACM, vol.37, July 1994.
[4] Genesereth, M. Finin, T., Weber J., & Wiederhold, G., Specification of the KQML Agent - Communication Language, Feb. 1994.
[5] Allen, J., Maintaining Knowledge about Temporal Intervals, CACM 26, (11),1983.
[7] Cohen, P., Communicative Actions for Artificial Intelligence, ICMAS-95, pp. 65-72, 1995
[8] Eichmann, D., Ethical Web Agents , 2nd International WWW Conf., Dec. 1994
[13] CoGenTex,Model Explainer , Internal Document
 |
 |
 |