May 6-10, 1996, Paris, France
Due in large part to early development of the Mosaic WWW browser by
the National Center for Supercomputing Applications (NCSA), the access
load on the NCSA WWW server remains extremely high.
Using the NCSA WWW server as a high load testbed, we describe Avatar,
a virtual reality system for real-time analysis and mapping of WWW server
accesses to their point of geographic origin on various projections of
the Earth.
As HTTP protocols expand to demographic data, the Avatar architecture
can be extended to correlate this data as well.
Keywords:
virtual reality, demographics, access pattern analysis,
performance analysis, information mining
In March 1994, the WWW ranked eleventh among the most used NSFNet backbone services [12]. At that time, WWW data accounted for less than three percent of all NSFNet backbone packets. By March 1995, WWW traffic was ranked first and accounted for almost twenty percent of the NSFNet backbone packets. This growth trend continues unabated as new WWW sites are added each minute.
Given current use of the WWW for scientific and educational information sharing and its emerging use for electronic commerce, studying access patterns is an important first step in understanding network implications and in designing future generations of WWW servers that can accommodate new media types and interaction modes. However, the large number of requesting sites, the diversity of WWW data types (text, data, images, audio, and video), and the multiplicity of server performance metrics (e.g., network packets and page faults) make data correlation and understanding difficult. Proposed HTTP protocol extensions will add demographic data, further complicating correlation and heightening the need for sophisticated analysis techniques.
To support WWW performance analysis, we expanded Avatar, a virtual reality system designed to analyze and display real-time performance data [17], and we applied it to the analysis of WWW traffic. One variant of Avatar supports real-time display of WWW server accesses by mapping them to their geographic point of origin on various projections of the Earth. By allowing users to interactively change the displayed performance metrics and to observe the real-time evolution of WWW traffic patterns in a familiar geographic context, Avatar provides insights that are not readily apparent via more traditional statistical analysis. Moreover, it can be extended to accommodate demographic and point of sale information for correlation of electronic commerce patterns.
The remainder of this paper is organized as follows.
First, we describe the architecture of the
NCSA WWW server
and the performance data recorded by the server.
We build on this by describing real-time
data analysis software
that can map WWW
server requests to their geographic origin.
This is followed by a description of the
Avatar virtual reality system
and its geographic representations of WWW traffic,
by a discussion of our experiences,
and by discussion of future directions.
Finally, we summarize
related work
and our
conclusions.
Via statistical analysis and our
virtual reality tools,
we have identified server bottlenecks
and typical user access patterns
[10,11].
As a context for discussion of our data analysis and visualization experiences,
we first describe the architecture of the NCSA WWW server and provide
a more detailed description of the recorded performance data.
NCSA WWW Server Architecture
On an average weekday, NCSA's WWW server receives roughly 400K requests,
each of which is recorded with ancillary data describing the transaction.
At current request rates, these log files grow by over 50 megabytes per day.
In addition to the standard server request logs, NCSA also
records operating system and network performance metrics.
Together, the access logs and the server performance metrics permit
analysis of server stimuli (access patterns) and server responses.
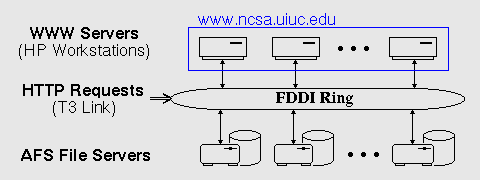
Figure 1: Real-time data collection and analysis architecture
Server Architecture
Beginning with the initial release of the NCSA Mosaic WWW browser,
NCSA's server site experienced explosive growth in the volume and
frequency of document requests.
To meet the increasing demand, NCSA adopted a scalable approach to
server design
[9]
capable of satisfying large numbers of
requests for small documents.
As
Figure 1
shows, the scalable server
consists of a set of dedicated HP 735 workstations that service WWW requests.
Document storage is provided by NCSA's Andrew (AFS) file
servers via a 100 megabit/second Fiber Distribution Data Interface (FDDI) ring.
Despite the multiplicity of servers, NCSA advertises a single domain name (www.ncsa.uiuc.edu) as its WWW server address. To equitably distribute incoming requests across the component servers, a modified Domain Name Server (DNS) at NCSA distributes the IP address for a different component server in response to each DNS query. These IP addresses are distributed in a round-robin fashion with a recommended time to live (TTL) of 15 minutes. This results in reasonably well-balanced load unless one or more remote systems ignore the recommended TTL and continue to cache the IP address of a single server.
Under this scheme, each server operates independently of the others. As demand grows, new workstations can be added to the server pool without reconfiguring existing servers, and workstation failures need not bring down the server complex.
Each of the access log entries consists of seven fields [13], including the IP address of the requesting client, the time of the request, the name of the requested document, and the number of bytes sent in response to the request. Despite the apparently limited information, it is possible to compute many performance metrics from the log entries and to glean several insights. For example, the extension of the file requested identifies the type of document requested and, with the number of bytes sent, suffices to compute the distribution of requests by data type and size.
Based on the file extensions, requests can be partitioned into at least six broad categories: text, images, audio, video, scientific data, and other. Within these divisions, we have classified text files as those with extensions such as html, txt, ps, doc, and tex. Graphics file extensions include gif, jpg, and rgb as well as other formats. Audio file extensions include au, aiff, and aifc. Video file extensions include mpeg, mov (QuickTime), and others. The scientific file category includes hdf, the NCSA Hierarchical Data Format (HDF). Finally, any remaining requests are placed in the "other" category.
The IP addresses provide additional information. By converting an IP address to a domain name, one can determine the components of the domain name and, often, the location of the requester. In the United States, common domain name extensions include education (edu), commercial (com), government (gov), and other (us). Outside the United States, countries typically use the ISO 3166 (1993) two letter country codes, or the network (net) extension. By exploiting these two letter country codes, one can identify the request's country of origin. As we shall see, IP addresses and domain names are the starting point for finer geographic distinctions, including mapping requests to specific latitude and longitude.
Simply put, the httpd log files provide a wealth of information
about incoming WWW requests.
Aggregating individual requests shows larger, evolving patterns that are
striking when visualized in real time.
Real-Time WWW Data Analysis
In earlier work, we characterized the NCSA WWW server access patterns
statistically
[10,
11].
This statistical analysis showed that request heterogeneity was growing
rapidly and that data type-specific caching could dramatically reduce
server access latencies.
We also developed a virtual reality system for interaction and display
of these dynamic statistics
[18].
Although this approach provided substantial insight into WWW server
performance and helped identify scalability limitations inherent in
the NCSA server architecture, it did little to aid our understanding
of either the origins of WWW requests or their temporal and spatial patterns.
This limitation motivated our development of software capable of correlating
request patterns with specific geographic locations.
Unlike users of WWW browsers, those who deploy WWW servers have a growing interest in understanding the geographic dispersion of access patterns. As digital cash makes electronic commerce via the WWW practical, providers of products can gain a competitive advantage by mining access patterns, much as large retail organizations currently mine point-of-sale information. For example, understanding which parts of the country (or world) most frequently purchase particular items from an online catalog is a major advantage --- given the geographic location of an incoming IP address, one can tailor the WWW server response by highlighting particular product types. Likewise, data on requester demographics [19] and correlation of this data with geographic information systems would permit selected targeting of product information. Finally, commercial Internet service providers could exploit knowledge of user access patterns to add new services in selected geographic regions.
To map IP addresses to geographic location, we first determine the domain name. For locations outside the United States, the suffix of the domain name typically is an abbreviation of the country name. In these cases, we map the request to the capital of the country. For all other cases, we query the whois database, retrieving the textual data associated with the IP address. We then search this data for city and country names. If a city or country name is found, we then retrieve the latitude and longitude from a local database of city and country names.
Because querying the whois database is expensive, often requiring a second or more to retrieve the desired data, we store the latitudes and longitudes of previously matched IP addresses to avoid repeated and unnecessary whois queries. If the whois query returns information that does not contain a city or country name, we record the IP address to avoid further, fruitless queries. Off-line, many of these failed queries can be identified and corrected in the database.
With our current database (35,000+ entries), about 95 percent of all requests to the NCSA WWW server can be successfully matched to latitude and longitude using only local data, 4.5 percent have undetermined latitudes and longitudes, and the remaining 0.5 percent must be found in the remote whois database. As our database continues to expand, the fraction of unresolvable requests continues to decline.
Despite our high success rate, network firewalls and national online services limit the accuracy of the latitudes and longitudes. For instance, an America Online (AOL) user might connect via modem from Irvine, California and access the NCSA What's New page. That person's IP address (aol.com) would yield Vienna, Virginia as its location because that is the site of the AOL headquarters. Similar problems arise with large, geographically disperse corporations that maintain a single Internet point of contact. Fortunately, such cases can be identified by name and can often be parsed by decomposing the domain name (e.g., intgate.raleigh.ibm.com is easily identified as an IBM site at Raleigh, North Carolina).
Although the primary use of our position database is to support geographic visualization of WWW request patterns in virtual environments, a WWW browser interface can be found at http://cello.cs.uiuc.edu/cgi-bin/slamm/ip2ll/. This interface exploits the Xerox PARC and US Census Tiger map servers to display the location of the IP address on a simple, two-dimensional map.
To integrate the geographic mapping of WWW requests with our existing analysis software and to support real-time data reduction and interaction, we decoupled analysis of the WWW server logs from the virtual reality system. The only medium of data exchange between the virtual environment and the analysis system is the Pablo self-describing data format [2], an extensible data meta-format with embedded data descriptions. This decoupling improves system performance and increases the flexibility to adapt the system to evolving goals.
By separating data visualization from data processing, display software development and processing software development can proceed in isolation. The display software currently supports virtual reality hardware such as head-mounted displays (HMDs) and the CAVE virtual reality theater. With the isolation, new displays --- such as a VRML representation --- may extend display support to the 2D desktop environment. For the data processing software, the isolation simplifies the integration of analysis extensions and the integration of new analysis mechanisms such as a relational database of access pattern, performance, and demographic data.
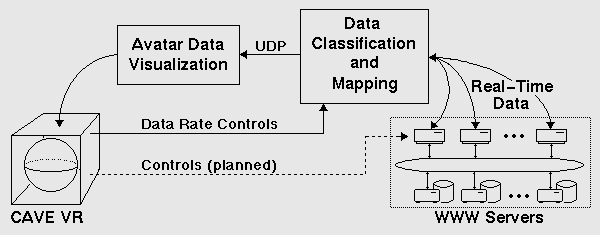
As Figure 2 shows,
data visualization and data classification execute concurrently on
separate platforms.
The data analysis software incrementally retrieves the WWW server logs
via TCP network sockets, classifies the domains and file types, finds the
geographic location of the IP address, and packages the data in the
Pablo Self
Defining Data Format (SDDF)
[15].
The SDDF allows Avatar to
inter-operate with performance instrumentation and analysis tools.
The packaged SDDF records are sent
via UDP sockets to the Avatar virtual reality software.
Avatar then
renders the data in the NCSA CAVE
[7],
an unencumbered
environment for immersive data analysis. In the following section, we
describe the data immersion software in detail.
Avatar Virtual Reality System
Avatar is a virtual reality framework, built on the Pablo performance
analysis toolkit
[15],
that supports multiple metaphors
to display dynamic data
[16, 17].
By separating the metaphor display software from the data processing
and interaction components, Avatar's software architecture has
allowed us to quickly create new display metaphors.
To date, we have developed three different display metaphors for performance data: time tunnels, scattercubes, and geographic displays. Time tunnels permit analysis of time lines and event driven graphs of task interactions (e.g., parallel or distributed tasks).
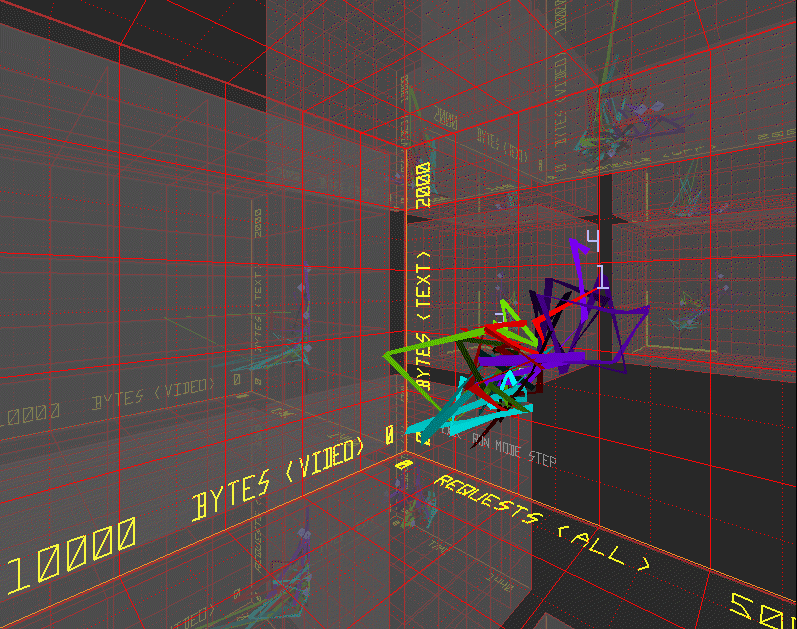
Scattercubes, a three-dimensional generalization of two-dimensional scatterplots, support analysis of very high-dimensional, non-grid based, time varying data. As an example, Figure 3 shows one three-dimensional projection of the dynamic behavior of the NCSA servers [18]. In the figure, the three axes correspond to one minute sliding window averages of the number of bytes of data transferred to satisfy requests for video clips, bytes transferred for text requests, and number of requests. The colored ribbons represent the trajectories of the NCSA WWW servers in the metric space. Through the translucent walls of the display, one can see three-dimensional projections of other metric triplets. In the virtual environment, one can fly through the projections to explore the data space, interactively rescale the axes, and enable or disable the history ribbons.
To complement the scattercube display of statistical WWW data and to represent the geographic dispersion of WWW requests, we developed a new display metaphor based on projections of the globe of the Earth. This metaphor is described below.
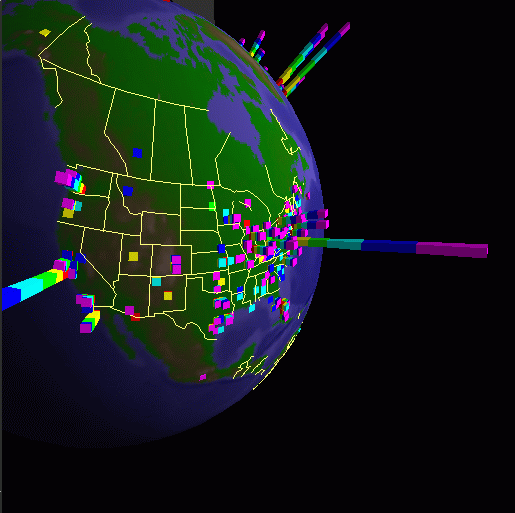
As Figure 4 shows, the globe consists of a texture map of the world on a sphere. The surface of the sphere includes altitude relief from the USGS ETOP05 database and political boundaries are drawn from the CIA World Map database.
On the globe or its projection, data can be displayed either as arcs between source and destination or as stacked bars. The former can be used to display point-to-point communication traffic [3], with the thickness, height, and color of the arc representing specific data attributes.
Stacked bars convey information through three mechanisms: position, height, and color bands. For WWW traffic, each bar is placed at the geographic origin of a WWW request. As we shall see in the description of our experiences, the bar heights show location-specific attributes of the requests, typically the number of bytes or the number of requests relative to other sites. The bar color bands represent the distribution of document types, domain classes, servers, or time intervals between successive requests.
The HMD version of Avatar includes speech synthesis and recognition hardware for voice-directed commands, and both the HMD and the CAVE versions use six degree of freedom trackers for head and hand (three-dimensional mouse) position location. Voice commands have the benefit that they can be executed at any time, and they do not consume space in the rendered scene. However, they require the user to be familiar with the command vocabulary.
To support both the CAVE and HMDs, while providing a virtual reality interface familiar to workstation users, the majority of all Avatar controls are realized via a familiar menu-based interface for data analysis and display. Later, we discuss the limitations of this approach. We implemented a library of windows that have labels, buttons, pull-down menus, sliders, and scroll boxes. Users select windows and menu items by pointing the three-dimensional mouse; a cursor drawn on the window indicates where the user is pointing, and audio feedback confirms menu selections. These windows can be moved, opened, and closed via the mouse and can be accessed from any location that has an unobstructed view of the desired window.
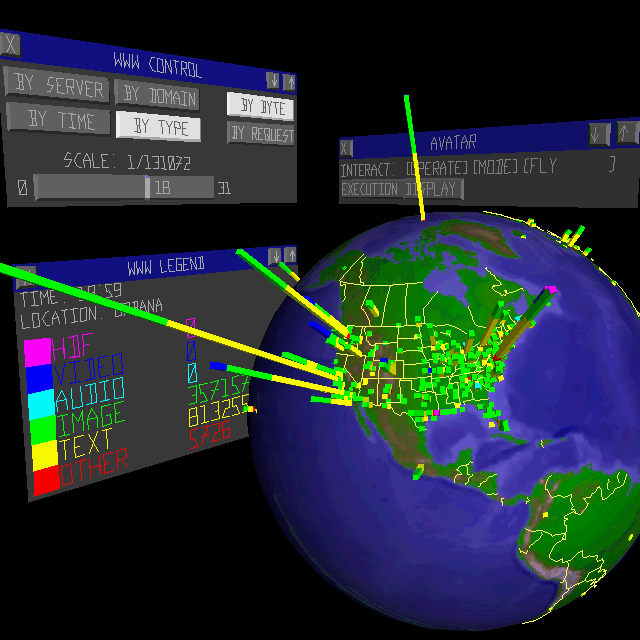
As shown in Figure 5, the menus for interaction with the geographic metaphor's display of WWW data control the scaling and position of the globe. The size of the globe and the height of the bars are controlled by sliders. The globe may be rotated by pressing buttons that increment or decrement the rotation speed, and a pull-down menu provides the option of warping to a predefined location (e.g., North America or Europe). Finally, one can select the characteristics of the displayed data.
In addition to providing a control mechanism, the windows convey
additional information about currently displayed data.
In
Figure 5,
they show the current time,
a color code for the stacked bars, and numerical values associated
with the color code.
Using the mouse, one can select a particular geographic site and
see the city name displayed with the legend.
Self Describing Data Format (SDDF)
Avatar builds on the Pablo (a registered trademark of the Board
of Trustees of the University of Illinois)
suite of performance instrumentation and analysis tools
[15].
A key component of the Pablo toolkit is the
Self Describing Data Format (SDDF) for performance data representation.
SDDF files and data streams consists of a group of record descriptors and
record instances.
Much as structure declarations in the C programming language specify
templates for storage allocation, SDDF descriptors define the structure
for record instances.
The data stream following the descriptors consists of a stream of descriptor
tag and data record pairs.
The descriptor tag identifies the descriptor that defines the juxtaposed
data.
By separating the structure of data from its semantics, the Pablo
SDDF library permits construction of tools that can extract and process
SDDF records and record fields with minimal knowledge of the data's
deeper semantics.
Via this mechanism, Avatar can process WWW data, parallel system
performance data, and generic statistical data with minimal software changes.
Figure 6 shows one of several record descriptors
used for the WWW data, and
Figure 7 shows one
possible record instance associated with this descriptor definition.
The timestamp is given in minutes past midnight, the server number is
represented by an integer identifier, and the
the request domain types are enumerations.
The possible file types are text, image, audio, video,
hdf and "other." The domain types differentiate the US sites. The
possible domain classes are edu, com, gov,
ca (Canada),
Europe and "other."
Because the Avatar software has no embedded knowledge of these
classifications, one can add or change the classification without
change to the display software.
Indeed, the scattercube display of
Figure 3
relies on other SDDF records that contain forty metrics on server
access patterns, network performance, and processor utilization.
The most striking attribute of Figures
4 and 8,
two snapshots of a single
day separated by twelve hours, is the wide variation in request frequency.
Sites that act as firewalls, typically large corporations and commercial
Internet service providers, appear as the originating point for the largest
number of accesses.
Smaller sites, typically universities, government laboratories, and small
companies, constitute a large fraction of all accesses, but they are
geographically distributed more uniformly.
Reflecting the evolution of the Internet, visual comparison of typical days
in the life of the NCSA WWW server from 1994 and 1995 shows that government
and commercial access is growing much more rapidly than that of educational
institutions.
Second, the distribution of the sites follows
population lines --- in the United States, these are the coastal areas
and regions east of the Mississippi River.
Because inexpensive Internet access is limited outside universities and
larger urban areas, these sites originate the largest number of requests.
Access to the NCSA WWW server from outside the United States is common,
though far less frequent than from sites in the United States.
There is little traffic from South America, Africa, or countries of the
former Soviet Union, but Europe and the Pacific Rim have thriving WWW
communities.
As one would expect, the periods of heaviest activity and the
distribution of requests by Internet domain track the normal
business day.
In the early morning hours (Eastern Standard Time), Europe is a major
source of activity at the NCSA WWW server.
As the morning progresses, the east coast of the United States becomes
active.
Near the middle of the day, the activity in Europe fades, while the
United States requests peak. In the evening, the United States
west coast has the highest level of activity.
Interestingly, the characteristics of the requested documents also
change with time of day.
Requests for audio and video files are much more common during the
normal business day than during the evening hours.
During the evening, text and image files predominate.
We conjecture that this reflects both lower bandwidth links to Europe
and Asia and low speed modem-based access via commercial service providers.
This variation has profound implications for the design of future WWW
servers and browsers --- based on the capabilities of the system hosting
the browser and the bandwidth of the link connecting the server and
browser, the server and browser should negotiate the resolution of
images to be transmitted and any guarantees for quality of service
(e.g., for video).
Finally, using
Avatar we were able to track failures of the NCSA
server load balancing mechanism.
Large load imbalances can result when certain locations, particularly firewall
sites, cache the IP address of a single workstation server longer than
the recommended fifteen minutes and repeatedly fetch data using that address.
Statistically, we knew this occurred, but we had never seen its effects.
With the geographic display of which servers satisfied requests from
particular sites, we could see the effect in real time.
Indeed, we found sites that used just one IP address for an hour or longer.
At present, Avatar processes and
displays data from a single WWW server.
However, as the WWW continues to grow and diversify, understanding the
global impact of WWW traffic becomes more difficult.
Fortunately, a substantial fraction of current WWW servers export
some statistics on access patterns.
Combining data from these servers would provide a global view of
access patterns not presently possible.
In addition, in remote demonstrations we have found that the one minute
updates of server behavior used by Avatar can easily
be transmitted across even heavily loaded network links, making
global analysis feasible.
A second limitation of Avatar is the inability to adaptively cluster
data based on density.
High population areas (e.g., New York and Los Angeles) are major
sources of WWW traffic.
Variable resolution reduction and data display would allow us to zoom
closer to selected regions and gain a more detailed perspective
than is presently possible with fixed region clustering.
Third, related to variable resolution, we would like to make finer mapping
distinctions outside the United States.
To date we have mapped U.S. sites to the city of origin,
Canadian sites to
their provincial capitals and other sites to their country capital.
The whois queries often return non-U.S. cities which we cannot
place on the globe due to the lack of a world-wide city databases that
hold latitude and longitude information. While such databases do
exist, they are often not readily available to the public. With the
incorporation of new databases we plan to enhance the mapping
capabilities of the globe display. We are currently in the process of
adding such databases for Canada and the United Kingdom.
Fourth, geographic displays are but one way to study WWW server data.
In [18] and the
Avatar description,
we presented an alternate perspective, based on
statistical graphics, that shows the time-evolutionary behavior of
server performance metrics (e.g., page faults and context switches)
and their correlation with request types.
Ideally, these two displays should be coupled, allowing one to correlate
multiple display views.
Fifth, a much richer set of statistics is needed. As WWW servers
begin to support financial transactions, recording details of the
transactions and mining that data for competitive advantage will become
increasingly important. In the future, the transactions will include
demographic data [19]
that will add a rich set of dimensions to
the geographic display.
WWW users may provide profiles about their
interests and other personal information to receive WWW pages
tailored to their desires. Commercial sites could use the geographic
display of demographics to correlate their cyber-customers with their
real-world customers.
Displays such as those in
Figure 5
provide the metaphor for interactive query and
display of data correlations.
Finally, one of the more difficult implementation problems in virtual
reality is user interaction.
Capitalizing on new hardware technology and the kinematic and haptic senses
requires a judicious balance of new and familiar interaction techniques.
Avatar's use of windows and menus can obstruct the user's vision of
surrounding imagery.
Consequently, Avatar allows the user to temporarily disable the window
and menu interface to provide an unobstructed view of the data display.
However, a richer set of interaction techniques are needed, particularly
those to specify the more complex queries that are needed to correlate
demographic data.
User WWW access patterns and demographics have been analyzed by a large
group of researchers (e.g., Pitkow et al [14]).
Likewise, there a many studies of server behavior and caching strategies
(e.g., Abrams et al [1]).
The focus of our work is on understanding short-term trends and geographic
display.
To support WWW performance analysis, we expanded Avatar,
a virtual reality
system designed to analyze and display real-time performance data and
applied it to the analysis of WWW traffic.
We have found that the geographic display metaphor has provided new
insights into the dynamic of traffic patterns and provides a model
for development of a WWW server control center, similar to that in
network operations [3].
SDDFA
#1:
"Mosaic_Metric" {
int "time";
int "server";
int "size";
int "file_type";
int "domain_type";
float "latitude";
float "longitude";
char "city"[];
char "state"[];
char "country"[];
char "hostname"[];
};;
"Mosaic_Metric" {
1300, 1, 12000, 2, 3, 40.112, -88.200,
[6] "URBANA", [2] "IL", [3] "USA",
[8] "www-pablo.cs.uiuc.edu"
};;
Analysis Experiences
Though quantitative analysis of WWW server access patterns is best conducted
statistically
[10, 14],
understanding temporal variations and detecting patterns is simplest
with dynamic graphics.
The geographic representations of the WWW server logs were much more intuitive
and provided the same insights with considerably less effort than the
statistical methods.
We have found that the most valuable aspect of the geographic display
is its real-time nature --- one can easily study temporal variations and
see the day-by-day effects of evolving document trees, changing network
topology and bandwidth, and new service providers.

Figure 8: WWW patterns (August 22, 1995 at 6 PM)
Research Directions
Although our geographic display has allowed us to understand
the temporal evolution of WWW requests in ways not easily possible
via other mechanisms, many issues remain unresolved, notably
display of data from multiple WWW servers, variable resolution clustering
of sites, and a richer set of statistics and query mechanisms.
Related Work
Our work draws on a large body techniques for visualization of network
data in the geographic domain.
Notable examples include Becker et al's
[3]
techniques
for displaying communication traffic, and Cox's
[6]
animation of NSFNet traffic.
Both show network connections by drawing links between nodes and show
inbound traffic by assigning traffic volume to a range of colors.
Our work is rooted in information visualization
[8]
and statistical graphics
[5]
with emphasis on interactive exploration.
Conclusions
Given the rapid growth of WWW traffic and the emerging use of the WWW
for commercial use, studying access patterns is an important first
step in understanding network implications and in designing future
generations of WWW servers.
However, the large number of requesting sites, the diversity of WWW
data types (text, data, images, audio, video), and the multiplicity of
server performance metrics (e.g., network packets, context switches,
and page faults) make data correlation and understanding extraordinarily
difficult.
Acknowledgments
We thank Bob McGrath for installing our daemon on NCSA's WWW servers
and Bob Olson at Argonne National Laboratories for an initial
script on converting IP addresses to latitude and longitude. We also
thank Thomas Kwan for his work on the data retrieval system.
References