May 6-10, 1996, Paris, France
Stéphane Perret, Andrzej Duda
IMAG-LSR,
2, rue Vignate, F-38610 Gières, France,
Stephane.Perret@imag.fr, Andrzej.Duda@imag.fr
The World-Wide Web is a distributed hypermedia system: the user downloads a HTML document from a remote server and follows links to access other documents. This operation scheme has many advantages that explain the great success of the system. However, it also suffers from some drawbacks that we could try to alleviate. For example, the operation of the system is strictly synchronous: the user must wait for the transfer of a document and access another one only when the transfer is completed. The user may experience considerable delays because of overloaded servers or increased network bandwidth usage. Synchronous access limits user performance if the underlying communication network does not provide sufficient bandwidth. Moreover, many accessed documents may be not really useful to the user who realizes it only after the transfer is completed. This results in wasted bandwidth of the network and wasted user time. Finally, this mode of operation is not suitable for applications running on nomadic or mobile computers that may occasionally disconnect, because the WWW access protocol is based on the traditional client-server model in which a client application must remain active when accessing a server.
At the same time, there appears new kinds of distributed applications that make extensive use of information distributed over a large number of servers. One class of such applications makes use of intelligent agents [5 ]. Intelligent agents are autonomous entities performing complex tasks on behalf of a user. An agent is able to make decisions about the strategy, the order, and the place of performing its tasks. An agent visits nodes where the data are stored and performs its tasks on the nodes near the data, instead of bringing them to one centralized place. In this way, network traffic can be significantly reduced. Agent programming approach can be beneficial for many new applications such as commercial transactions or service brokerage.
Another class of new applications is distributed indexing. Existing search engines like Web Crawler, Jumpstation, Lycos, Infoseek, AltaVista, or Inktomi use robots for indexing: they fetch a HTML document from a WWW server, analyze the text and find anchors pointing to other documents. The operations are repeated recursively for all documents designated by URLs found in the anchors. These systems overburden network resources by transmitting entire documents, rather than the index data. Moreover, a robot controls all the operations locally and must be operational during the task. Indexing application would gain from another approach in which a robot moves to a WWW server, goes over the local subspace of documents and returns index data as a result. This scheme has several advantages: the network traffic is reduced, only WWW servers must be operational during the task (the client node may disconnect after initializing the task), and parallel indexing of several servers can be easily accomplished.
Other new applications include advanced information access and data mining. Such applications evaluate complex queries that involve large amounts of data distributed over many nodes. Typically, the results of a query evaluated at one node provide partial information needed to complete the query at other nodes. For example, one server (such as Discover, a content router for WAIS servers [13 ]) may provide a list of other servers to which the query must be forwarded. This kind of applications can benefit from moving computation closer to data and exploiting potential massive parallelism.
The drawbacks of the WWW access scheme and the emergence of new applications call for a change in network programming paradigm. In fact, we need a new network programming support that provides the following features:
We have designed a network programming model called Mobile Assistant Programming (MAP) [12 ] that supports the development and efficient execution of applications accessing information resources on large scale networks of heterogeneous computers. The user can activate an assistant to perform some tasks on information servers and disconnect. The results, which are persistent, can be obtained at some later time. Assistants are high-level interpreted programs that retain their state while moving between nodes and gathering results. This approach reduces network traffic and elapsed time by shipping function to data. Assistants save their state to survive node and data link failures. The model also addresses massive parallelism: assistants can generate clones to perform complex tasks in parallel.
We have implemented the Mobile Assistant Programming model using the WWW framework and the Scheme programming language [11 ]. Assistants are Scheme programs whose execution state can be saved, transferred to a remote WWW server, cloned, or restored. The implementation is based on two useful features of the WWW: the HTTP POST method and the CGI script invocation mechanism. We have modified the Scheme interpreter to remove some unsafe primitives and to add MAP primitives. We have enriched the Scheme interpreter with the ability to save and restore the execution state. To support information access, we have provide a set of Scheme primitives for dealing with WWW documents.
We have developed an application that searches for relevant HTML documents on a set of WWW servers. The application analyzes HTML documents on remote WWW nodes and returns relevant documents. By moving closer to data, the application significantly improves the overall performance: both elapsed time and network traffic are reduced. As the application caches the relevant documents in local storage close to the user, so that all relevant documents can be browsed efficiently after the search is completed.
Our experience with the application shows that the MAP model is a powerful paradigm for programming new applications for information access on the WWW, because it provides disconnection transparency, mobility, and parallelism. A MAP application can be activated from a mobile or nomadic host as well as from a fixed-location node. By reducing the number of communications as well as the volume of transferred data, application performance is significantly improved and network traffic is reduced.
In the remainder of this paper, we briefly present the Mobile Assistant Programming model (Section 2 ), and its implementation based on Scheme and WWW (Section 3 ), explain the architecture of MAP applications, and overview a search application (Section 4 ), discuss related work (Section 5 ), and outline conclusions (Section 6 ).
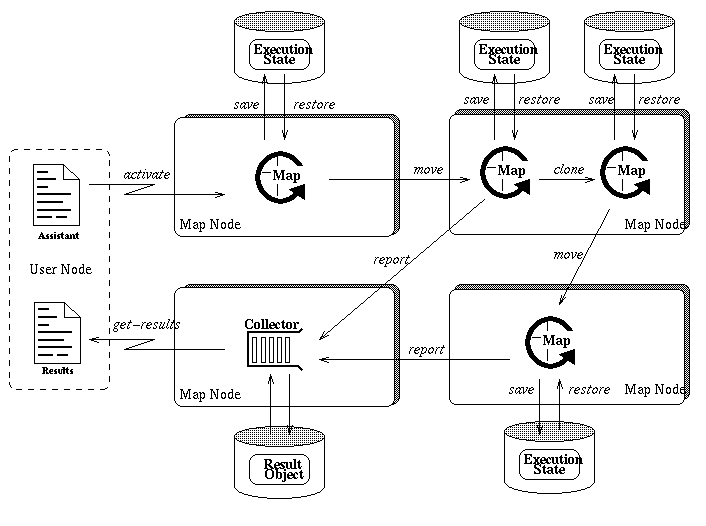
To make the paper self-contained, we provide below an overview of the main concepts of the MAP model (for a more complete description see [12 ]). An application activates an assistant program on a remote node to accomplish a complex task. An interpreter interprets the assistant program and its execution state can be saved to persistent storage (this action is called a checkpoint). In case of a node failure, assistants are restored from persistent storage automatically. To accomplish its task, an assistant moves to a remote node, clones other assistants and reports results. The results are collected in a result collector, a persistent object located on any node in the system and unique for an activation. An application can get results from the collector. Figure 1 presents the principles of the MAP programming model.
Figure 1: Principles of the MAP programming model
The basic primitives of the MAP model are as follows:
MAP primitives require some system support for checkpointing and communication. They are used by MAP primitives, but they are not accessible by the programmer. The system support operations are as follows:
In the MAP model, assistants are asynchronous independent entities. They execute in parallel, independently of one another. There is no communication between assistants and each assistant reports results directly to the collector. Reporting is also asynchronous---each assistant can generate as many reports as it wishes at any time. A mobile host may access partial results or check for the termination of all assistants at will. These features of the model make execution of an application transparent to the underlying communication system. That means that an application can be executed on a nomadic or a mobile host as well as on a fixed-location node indifferently.
Persistent execution of assistants is based on checkpointing---the execution state of an assistant is saved to persistent storage. When an assistant executes a primitive that modifies its external environment such as move, clone, or report, a checkpoint is taken in the primitive. The primitive and the checkpoint are executed as one atomic action, so that an assistant can be restored after a node failure in a consistent state and continue its execution. After a failure, a node restores all the assistants that were active before a failure. This mechanism allow assistants to progress in computation in spite of node failures.
Security is the major issue in a programming model such as MAP, in which external programs execute on remote nodes. There are two problems that must be addressed: access control and resource control. Concerning access control, we assume that assistants execute in a standard Internet environment, so we need an authentication mechanism to verify if an assistant has rights to execute on a MAP node. We use the digital signature scheme provided by PGP that allows a MAP node to verify if data transmitted over the network come from an authorized user or another authorized MAP node. We assume that we do not need systematic encryption for transmitting the code or the state of assistants. However, we guarantee that it is not modified and it comes from an authenticated sender. If an assistant needs to handle sensible information that should be protected for privacy, it can use a public key encryption scheme provided as a Scheme primitive. We also assume that MAP nodes are protected from external threats and they can store private keys needed for authentication in a secure manner.
Resource control has three aspects: data access, system functions, and resource consumption. The use of a safe, high level interpreted language can address the first two aspects---assistants do not have access to data nor to system functions. This is the case with our implementation in Scheme described below. Resource consumption control is enforced on a per user basis. According to the identity of the user that have initiated an assistant, we limit resource consumption at different levels. For example, we restrict execution time, memory usage, disk space and network traffic volume of assistants. User groups of different resource consumption levels are defined in a MAP node configuration file and are used to control resource usage.
We have implemented the Mobile Assistant Programming model using the WWW framework and the Scheme programming language (for more detailed description see [11 ] ; an example of activation can be made at http://fidji.imag.fr/map.html). As we are interested in applications that need to access data distributed over the Internet, WWW was an obvious choice for the first prototype. The implementation is based on the HTTP POST method and the CGI script mechanism. The POST method provides a means for transferring information to a remote WWW server and a CGI script provide support for executing MAP primitives.
Scheme has many advantages: its a fully fledged programming language with first-class procedures. The source code for its interpreter is widely available and it can run on many heterogeneous platforms [3 ].
Our implementation is based on three elements:
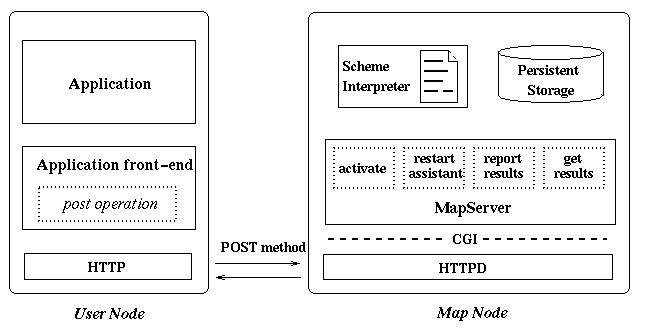
A MAP node is a WWW server that supports mobile assistants---it runs a httpd daemon and provides MapServer, a CGI script with the following components: the modified Scheme interpreter, functions implementing MAP primitives and local service interface. Figure 2 present the structure of the implementation.
Figure 2: Implementation structure
The activate primitive takes the source code of an assistant and transfers it to the MapServer of an Activation Node using the post operation. The activate function of the MapServer initializes the assistant by starting the Scheme interpreter and initializes the result collector object on Result Node implemented as a file accessible by the get-results primitive.
The get-results primitive retrieves results by transferring a collector capability to the MapServer of Result Node using the post operation. The get-results function of the MapServer accesses the collector result object, checks for the termination of all assistants and returns formatted results. The termination detection is based on the information provided by each assistant when it exits: the identity of its creator and the number of clones it has created. The information allows MapServer to construct the graph of assistant cloning that can be used for debugging or for verification if all assistants of a given activation have terminated.
The move primitive saves the execution state of an assistant to a checkpoint file and invokes the post operation to transfer the state to a remote MapServer. The restart-assistant function of the MapServer takes the execution state of an assistant, saves it to persistent storage, rebuilds the execution state of the Scheme interpreter and resumes the execution. Finally, it returns a status indicating a successful move primitive and the checkpoint file at the origin node is removed.
The clone primitive is entirely implemented as a Scheme primitive. It copies the current state of the execution and modifies the assistant identifier in the copy's state. Then, it takes a checkpoint of the copy's state as well as of its own state. Finally, it starts the Scheme interpreter to restore the state of the clone and to resume execution.
The report primitive transfers the result report via the post operation to the MapServer of the Result Node. The report-results function of the MapServer saves the result report to the collector result object and the assistant is checkpointed to persistent storage at the current execution node. When an assistant exits, the information about all clones created by the assistant is passed to the MapServer of the Result Node. Only one collector object is used to collect result reports for a given activation, because it is common to all assistants of the activation.
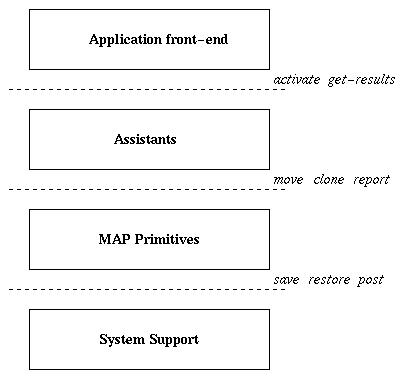
The MAP model provides flexible support for programming new applications that require disconnection transparency, mobility, and parallelism. The functional architecture of the model is presented in Figure 3 . It is composed of four layers: application front-end layer that provides user interface, activates an assistant, and checks for results, assistants layer that performs useful work for the application and are programmed using MAP primitives, MAP primitives layer that performs basic MAP operations, and system support layer that performs checkpointing and communication.
Figure 3: Functional architecture
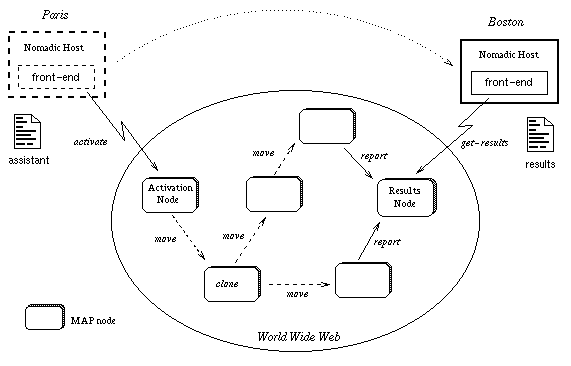
Developing an application using MAP consists of writing an application front-end and a program for an assistant. The application front-end activates the assistant on a chosen MAP node (Activation Node) and specifies another node (Result Node) that holds collector object for results. An application may run on a nomadic or a mobile node as well as a fixed-location node. The execution of assistants takes place on MAP nodes set up on WWW servers. Figure 4 presents an example of an application that runs on a nomadic host and on several WWW servers. The user activates an assistant in Paris, goes to Boston while the assistant and its clones execute in the network, and requests the results on arrival in Boston.
Figure 4: Application example
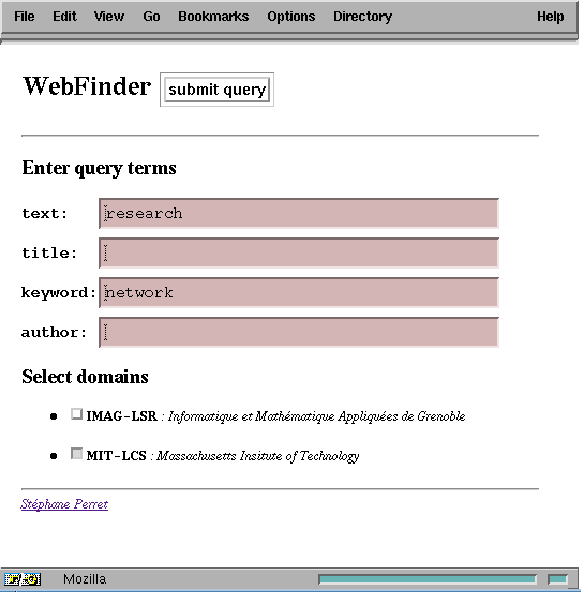
To validate our MAP platform as a support for information access applications, we have developed an application that searches for HTML documents on a set of WWW servers. The application front-end is simply Netscape WWW browser and a CGI script that presents to the user a FORM document to enter the parameters of a search: a query and DNS (Domain Name System) domains containing WWW servers on which the search is performed in parallel (Figure 5 ). Each proposed domain includes a MAP node that allows execution of assistants that access HTML documents on WWW servers in the domain. The scope of the search is defined by a root URL to start with and a regular expression on the name of WWW servers.
Figure 5: Opening document of the application
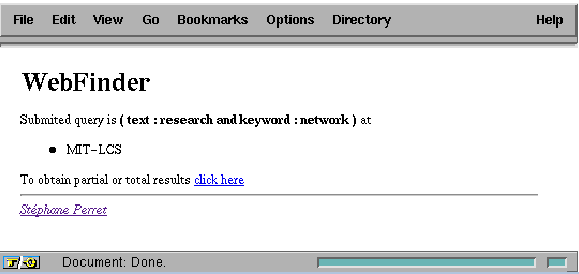
The user query is a conjunction of attributes. Currently, we support four attributes corresponding to different structures of a HTML document: text - all terms of the document, title - terms of the document title, keyword - terms appearing in the headers, and author - terms appearing in the address part of a HTML document ( <ADDRESS> tag). For example, query keyword:network and author:smith matches all documents with term network in the headers and signed by smith. The application confirms the activation by returning a HTML document with an anchor for the collector capability (Figure 6). This document is later used for obtaining results.
Figure 6: Response document with collector capability
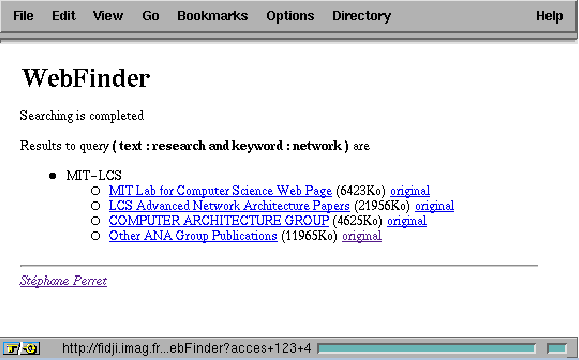
For each domain chosen by the user, the application clones an assistant to execute on a MAP node in a given domain. The assistant accesses all HTML documents starting at a given root URL that can be found on WWW servers which names match the regular expression associated with the domain proposed to the user. Then, the assistant parses the documents. The documents that match the user query are included in a report. The application front-end collects the reports and caches the documents in a temporary local space of WWW documents. After the search is completed, the user can efficiently browse all relevant documents, because they are stored in the local storage. The original documents can also be accessed. Figure 7 presents the HTML document with the results of a search.
Figure 7: Results of a search
We have compared the performance of our MAP application with the performance of a WWW robot that executes the same task. The robot retrieves every document from remote WWW servers and analyzes it locally. Table below presents this performance comparison. In this experiment, we used a different query, namely keyword:network. 121 HTML documents of total size 1300 KBytes have been accessed and 14 relevant documents of total size 150 KBytes have been found. Clearly, moving document processing closer to the data stored at remote WWW servers and transferring only relevant documents results in better performance.
WWW Robot : 2277s
MAP Application : 540s
Table: Performance of the MAP application vs. WWW robot
Our experience with MAP and the search application developed on top of it shows that significant performance improvement can be achieved by moving computation closer to the data: both the elapsed time and network traffic are reduced. User performance is also improved: the user can run several queries on interesting topics, disconnect and when the results are available in a local store, they can be browsed efficiently.
Our model is based on the idea of assistants that are asynchronous, persistent, and parallel processes. They execute independently of the entity that created them and can migrate from node to node as well as create other assistants. The model differs from previous work in several aspects explained below.
A programming agent is a concept that appears frequently in the context of artificial intelligence [5 ]. An agent is a high-level concept that allows specification of complex tasks in a declarative language. Such agents may easily use MAP as a low level execution and communication support. Another type of agents is based on a procedural approach. It is represented by scripting languages such as TCL [10 ], Apple Events, and Telescript [15 ]. For example, a subset of TCL commands - Safe-TCL permits the delivery of active e-mail messages that interact with their recipients and take differential actions based on the recipients' responses [2 ].
Telescript is a software platform for remote programming in an electronic marketplace . The basic entities are agents and places. An agent is an active object that carries data and procedures. Agents occupy places representing real world entities such as a shop or a box office. Agents can change places using a go instruction and communicate with other agents using a meet instruction. The MAP programming model is similar to Telescript. However, in Telescript, the execution model is based on rendez-vous between agents. The details of the meet instruction are not given in the white paper [15 ] and it is not clear how a client agent requests a service from a server agent (some kind of a communication protocol must be defined between these two entities). In MAP, there is no server agent that represents a service. Instead, an assistant migrates to and executes its code on a server node, so that assistants can be thought of as passive mobile processes programmed by means of a high-level interpreted language. Compared to Telescript, MAP offers assistant cloning to exploit inherent parallelism in a large scale network. Returning results is also different in MAP: at each stage of the execution an assistant can report results.
An infrastructure for mobile agents similar to MAP has been recently proposed by Lingnau et al. [7 ]. Agents written in TCL and Perl can execute on nodes that run an agent server. Each agent server maintains an abstract information space composed of triples: a key, a access control list, and a value. The infrastructure requires a modified HTTP server, because agents are encapsulated as MIME contents. Rover combines relocatable dynamic objects and queued remote procedure calls to provide a uniform distributed object architecture for code shipping, object caching, and asynchronous object invocation [6 ]. De Roure et al. discusses the role of agents in a distributed multimedia information system (DMIS) engineered according to the principles of open hypermedia [4 ]. Madsen proposes to use agents for generating maps of the Web that can be used by researchers and students interested in knowledge relating to specific subject areas [9 ].
Several proposals for mobile code have recently appeared. Java [1 ] is an interpreted portable object-oriented language that allows a client to dynamically download classes and execute them within its address space. Omniware [8 ] is similar to Java and provides a variant of C++ with safety protection based on software fault isolation. Both proposals are based on the remote evaluation model [14 ] and do not provide any support for computation migration.
We have defined a model for programming applications that access distributed data on large scale networks. The goal of the model is to enhance the ability of applications to perform complex actions in a large scale network by moving computation closer to data scattered over servers. The model takes into account all the important aspects of large scale networks such as the WWW: large scale, distributed information, limited bandwidth, disconnected operation, server failures, and heterogeneity. As a result, assistants are asynchronous persistent processes that work in parallel to accomplish a useful task. Our model can be successfully used for programming new applications for information access on the WWW: it allows disconnected operation, reduces network delays, and exploits potential massive parallelism of the network.
We have implemented the Mobile Assistant Programming model using the WWW framework and the Scheme programming language. We have used it as a platform to develop a mobile application that searches for relevant HTML documents on a set of WWW servers. The performance of the application is much better than that of traditional approaches based on robots. In addition, we found ease of programming and mobile transparency particularly useful.
To largely benefit from our approach, we need wide deployment of the execution support for assistants. For example, it would be desirable that major WWW information servers provide MAP support to allow more experiments with indexing and searching. In reality, just a few nodes distributed geographically can significantly reduce network traffic and latency, and provide useful support for mobile applications. So, we would like to propose the creation of a pool of nodes: each participant provides a machine supporting MAP and in return, she or he can use all the machines in the pool for activation of mobile applications.