May 6-10, 1996, Paris, France
Nick N. Duan
Bell Atlantic, Internet Services Center of Excellence
Most of the Java applets on the Web today are developed primarily for visualization and 3D interactive animation. Serious doubts have been raised about the feasibility of using Java in the domain of enterprise applications. Compared with the conventional CGI-based approach for developing database applications, Java-based approach provides a high degree of flexibility, scalability, portability and robustness. Through the use of HORB, a software tool based on the concept of Object Request Broker, Java client and server objects can be created easily and accessed transparently. A methodology using Java and HORB for developing database applications is proposed, with the objective to establish a robust Web infrastructure in a corporate environment.
World Wide Web, Java, Database, Object Request Broker, Distributed Object Computing, Multi-tiered Client/Server Systems
The advent of Java has transformed the World Wide Web from a simple, static HTML-based exhibition hall to a dynamic, distributed computing arena. Combining advanced features of C++ and other object-oriented languages, Java is designed as a powerful and secure language for developing portable, interactive applications on the Internet. Unlike a static HTML document with only limited graphic features, a Java applet, a small piece of Java code, can be executed on a Java-enabled browser such as Netscape Navigator and Sun's HotJava with animation and interactive graphics, hence providing a higher level of user interaction and information exchange on the Web.
Despite all the media attention and alliances of software vendors behind Java, most of the Java applets on the Web today are developed primarily for visualization and 3D interactive animation [1]. Many people have raised serious doubt about the feasibility of using Java in the domain of enterprise applications. These applications require a high degree of scalability and interoperability among multiple databases in a heterogeneous environment. As large companies are moving their corporate information infrastructure towards the Web and the CGI-based (Common Gateway Interface) approach becomes widely used in the process of integrating the Web with various database systems, it becomes a tough judgment whether the use of Java would contribute to developing mission-critical applications and meet the objective of improving business processes. Obviously, Java still has a long way to go before reaching the maturity of having a rich set of class libraries and rapid prototyping tools. However, because of its well designed object-oriented features and its adaptability on the Web, Java is leading the wave of creating a open distributed environment and will indeed benefit business processes in the long run.
In a corporate environment, the information repository usually encompasses a wide spectrum of databases, from mainframe based legacy systems to UNIX workstations and personal computers. The mainstream today of developing enterprise applications is to establish a flexible and scalable distributed object computing (DOC) infrastructure, enabling seamless integration of information components on heterogeneous platforms. Compared with the conventional, server-centric information systems, DOC-based approaches are more advantageous in terms of flexibility, scalability, portability and robustness [2]. DOC-based platforms currently available in the industry include the Common Object Request Broker Architecture (CORBA) [3], proposed by Object Management Group (OMG), Object-Oriented Distributed Computing Environment (OODCE) [4], developed by Open Software Foundations (OSF), and Network OLE [5], developed by MicroSoft. These platforms are usually expensive to implement and requires specialized development expertise. There are quite a few attempts in integrating CORBA with the Web [6], but the use of HTTP-based server prevents such systems from becoming truly distributed. Java, on the other hand, is less complex and inexpensive. It possesses all the desirable features of DOC and fits well with the existing Web infrastructure.
In this paper, a methodology of developing distributed database applications in Java is presented, using a software tool called HORB (HIRONA Object Request Broker) [7]. HORB, developed by Dr. Hirona Satoshi at ETL in Tokyo, is based on the concept of Object Request Broker in DOC. It is written completely in Java for developing distributed client and server objects, including Java applets. It provides a high level of abstraction with all socket interfaces encapsulated within the HORB. A developer only needs to deal with application level objects, and the development effort can be largely reduced. We hope, through the use of distributed objects, to come up with a generic framework for rapid application development on the Web, in a flexible, efficient and cost-effective way.
In the remaining sections, a review of the conventional CGI-based approach for database access is given first, in comparison with the Java-based approach. Next, the concept of utilizing Java-based mobile objects in a multi-level, heterogeneous database environment is illustrated, followed by the introduction of HORB, along with its pros and cons in comparison with CORBA. Then, an experimental design of Java objects for database applications is demonstrated. Finally, important steps for creating distributed Java objects using HORB are summarized and directions of future development are highlighted.
A typical database application on the Web today consists of three components: a Web browser or sometimes called a Web client, a HTTP server with a CGI program, and a database server. A database query is initiated by sending a user request (usually using HTML forms) from the Web client to the HTTP server. Upon receiving the user request, the HTTP server invokes the CGI program to assemble user input data into database-specific SQL statements, and send them to the database server for processing. The query results will be returned by the database server to the CGI program, and then passed to the Web client through the HTTP server. Since CGI is the de facto standard for interfacing HTTP server with external applications, this database access scheme becomes the most commonly used method in today's Web world.
The concept of CGI was originated from the initial Web development for providing a generic interface between a HTTP server and user-defined server applications. Despite of its simplicity and wide acceptance, there are some common problems associated with the CGI-based approach. The first one is that the communication between a client and the backend database must always go through the HTTP server in the middle, which likely becomes a bottleneck if there is a large number of users accessing the HTTP server simultaneously. For every request submitted by a Web client or every response delivered by the database server, the HTTP server has to convert data from or to a HTML document. This certainly adds a lot of overhead for query processing.
The second problem is lack of efficiency and transaction support in a CGI-based access scheme. For every query submitted to the backend database server through CGI, the database server has to perform the same logon and logout procedure, even for subsequent queries submitted by the same user. This process certainly consumes a lot of time and resources, especially when a large number of clients are accessing the database at the same time. Because a CGI program can only handle queries in a batch mode, it is difficult to support on-line database transactions which contain multiple queries executed with control functions in an interactive mode.
This problem is inherited from the statelessness of HTTP, which is the standard protocol for client/server communications on the Web. Stateless means that a sever response to a client request does not depend on the history of previous request and response messages. A stateless protocol such as HTTP is appropriate for single-query type of applications, it is not sophisticated enough to handle session-oriented database applications where efficiency and transaction functions are of major concern. Many developers have proposed different solutions to get around the statelessness of HTTP [8], but the full functionality of database systems can only be utilized if the underlying protocol is able to support stateful client/server interactions.
The third problem is lack of user access control. Because of the statelessness of HTTP, a database query has to be sent by a Web client in one batch, along with the necessary user ID and password. This is not considered as a secure practice since request data is usually sent by the Web clients to the HTTP servers in plain ASCII format. For security reasons, user ID and passwords are usually embedded in the CGI program to access the backend database, and control of user access is handled by the HTTP server. The HTTP server security functions deal only with user domain control and does not have fine-tuned access control functions with various privileges (such as read, write, database administrator, database owner, etc.) at the database level. In an enterprise environment, it is desirable to use existing user access control functions provided by the database server so that the same security and access privileges can be enforced across the enterprise network.
The fourth problem is lack of presentation graphics, due to the limitation of HTML. An HTML document is static with no dynamic presentation graphics such as bar charts and 2D or 3D diagrams. Although VRML (Virtual Reality Markup Language), a variation of HTML, is able to handle complex 3D graphics, but it still relies on the HTTP and provides no direct communication interfaces. It is possible to make presentation graphics through generating images in GIF or other graphic formats, this method is slow and space consuming because all the images have to be generated by a CGI program on the HTTP server side. One of the major advantage of client/server computing is that all user specific functions, e.g. graphical presentation of query results, should be performed at the client side. This is only possible if a Web client is capable of performing active graphic functions.
All the aforementioned problems can be easily solved if a Java applet is used to perform the client activities. Java is the first successful commercial implementation of mobile code, programs that can be transmitted to and executed on a remote machine [9]. A Java applet is capable of making its own network connection using sockets. It is possible to access databases from an applet directly, without any interventions by the HTTP server. This approach will not only eliminate the bottleneck imposed by CGI on the HTTP server, but also provide session-oriented communications. Unlike the CGI-based approach where the database connection is closed as soon as the query is finished, an applet, once it connects to a database, can keep the connection open as long as the applet is alive and the user is in session. Thus, interactive queries and complex database transactions can be supported through the use of applets. Since no restrictions or access control by the HTTP server is imposed on the applet-server connection, user access control can be handled by the native security mechanism of the database server. With a rich set of graphic drawing functions available in Java's Abstract Window Toolkit (AWT) class library, a Java applet is capable of handling sophisticated presentation graphics, utilizing the full strength of distributed computing in a true object-oriented environment.
The real potential of utilizing Java for Web applications lies in the mobility and connectivity of Java applets. A Java applet running on a Java-enabled browser functions like a self-contained Web client. The easiest way to create a database client in Java is to construct wrapper classes of vendor-specific client library functions (assuming they are written in C), and compile the wrapper classes as dynamic linked library. However, because of security reasons, only standalone Java applications are able to connect to dynamic linked libraries. An Java applet, when running on a Web browser, usually does not have the permission to access any files on the local file system. The only way for an applet to access a remote server is through Java's socket interface.
In general, there are two methods to construct a Java applet as a client for accessing a remote database server. One is to use a two-tier architecture in which all client functions are implemented entirely in Java (see Figure 1). The other one is to use a 3-tier architecture, in which a standalone Java server is used as a gateway, passing the request and response messages between the applet and the remote database server (see Figure 2). The former requires extensive programming effort because a Java client has to be implemented at the protocol level for vendor-specific databases. The latter is easier to implement, because the gateway server can be created as a standalone Java application with native client library functions wrapped in Java classes. It communicates as a server with the Java applet at one end in user-defined protocols, while accessing the database server at the other end in native client/server protocols.
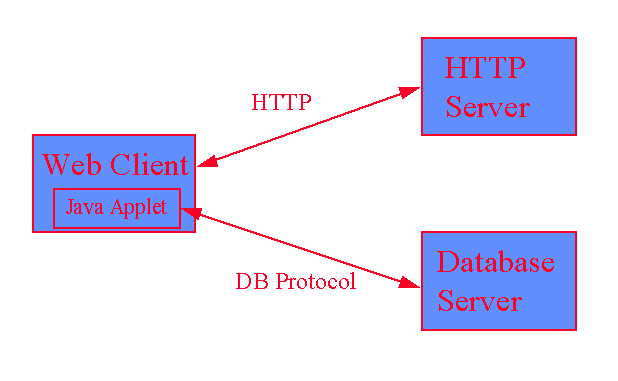
Figure 1: Two-tier Database Architecture Using Java
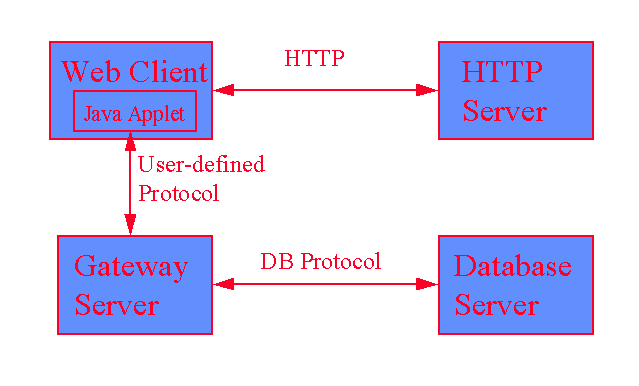
Figure 2: Three-tier Database Architecture Using Java
Current implementation of database clients using two-tier architecture includes MsqlJava [10], a Java class library that implements the original library functions of the shareware database MiniSQL. Client/server implementations using three-tier architecture include Weblogics's dbKona/T3 [11] and OCI/Java Gateway by Vincent Engineering [12]. The former provides a rich class library for developing both client and server in Java for accessing relational databases, including Oracle, Sybase and Informix. The latter is an implementation of Oracle Call Interface for connecting with Oracle databases. For performance reasons, the dbKona/T3 server also offers record caching at both the client and the gateway server side.
Existing commercial database products in Java tend to replicate the existing functions for SQL-type of client/server interactions. They provide an extensive API (APplication Interface) class libraries so that most database functions with all parameters can be set and issued by the client. The result is that the system could become quite complex and the learning curve is high because developers have to deal with a complete new set of APIs and protocols. In some cases, this approach may also restrict the freedom of developers because no other APIs are given for database access. From a practical standpoint, it is not necessary to equip an applet client with all functionality like a conventional client in a LAN environment because complex database functions can be done (or must be done because of security reasons) through conventional database clients on the server directly. An applet as a database client does not need to handle complete database manipulations. It only needs to know what user input to pass, what result to get and how to represent them.
The approach taken in HORB (HIRANO Object Request Broker) is quite different than most of the commercial Java-based client/server products. It reflects the current mainstream of distributed object computing. Basically, HORB uses the same approach as CORBA for developing object-oriented distributed applications. It contains a IDL compiler called HIDL and an object request broker, HORB, both are written in Java. HIDL generates both the client proxy (client side stub) and the server skeleton (server side stub) classes through the server class file or the interface file written completely in Java. Just like in CORBA, the remote object invocation is handled by the Object Broker HORB. The socket layer interfaces are completely encapsulated within the stub classes so that server objects can be accessed transparently by client objects. Furthermore, HORB is capable of handling both object passing by value and passing by reference, providing a transparent interface of remote objects.
Although HORB is not CORBA-compliant, in many cases, HORB is more suitable for developing light-weight Web applications, compared with using a standard CORBA package because of the following reasons:
In this section, we demonstrate the methodology for developing database applications using HORB through a design experiment. We use a three-tier architecture to support the interactions between the database client, implemented as a Java applet, and the database server using Sybase. The gateway server which is implemented in Java, acts as a server against the applet and as a client against the Sybase server. The gateway class contains a set of native methods implemented using Sybase DB library functions. It runs as a standalone Java application and communicates with the applet through HORB (see Figure 3).
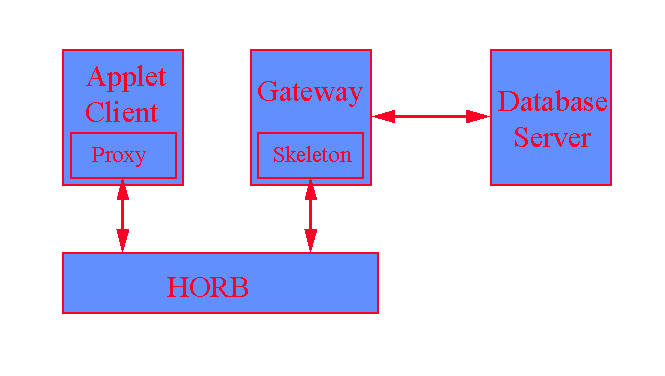
Figure 3: Database Access through HORB
In HORB, either a server class file or an interface declaration file can be used by the HIDL compiler to generate the server skeleton and the client proxy. Since our example is quite simple, we choose the first option to use a server class file. The source code of the gateway server is shown as follows:
package sybhorb;
class Sybconnect {
String username;
String password;
String sqlquery;
String fromtable = " from employee where ";
public Sybconnect(Request req, String uname, String passwd) {
username = uname;
password = passwd;
sqlquery = new String("select ");
sqlquery = sqlquery.concat(req.select());
sqlquery = sqlquery.concat(fromtable);
sqlquery = sqlquery.concat(req.where());
}
public native int execSQL();
public native void dbLogin();
public native void dbExit();
static {
System.loadLibrary("Sybjava");
}
}
public class Server {
//
// Gateway server for accessing Sybase
//
public Table makeQuery(Table restable, Request request) {
// creating interface with the native C lib
Sybconnect myquery = new Sybconnect(request);
myquery.dbLogin();
myquery.execSQL();
restable.setTableContent();
myquery.dbExit();
return restable;
}
}
The server class of the gateway contains the class Sybconnect, which implements the native methods implemented using Sybase DB-lib functions. For demonstration purposes, only three functions are implemented: execSQL(), dbLogin() and dbExit(). A database query is initiated by the server when the makeQuery function is called. It receives a Request object containing the query specification, and a Table object for storing the query result.
After compiling the server class file and generating the server skeleton and the client proxy files, the client class can be compiled, either by using the javac compiler or the HIDL compiler. The client code is given as follows:
package sybhorb;
import horb.orb.*;
class Client {
Server_Proxy server;
Table tbl;
Client(Table table, Request rqs) {
String host = serverhost;
// initialize gateway server
try {
HORB orb = new HORB();
} catch (Exception e) {}
if (host.length()==0) host = "-";
try {
Server_Proxy server = new Server_Proxy(new HorbURL(host, null));
} catch (Exception e) {}
tbl = table;
}
public Table sendQuery(Request rqs) {
String host = "-";
Table result = null;
try {
result = server.makeQuery(tbl, rqs);
} catch (Exception e) {}
return result;
}
}
The client class is defined as an applet-independent class. It takes the reference of a Table object which stores the query result, and the reference of a Request object which contains the query request. Both Table and Request objects are defined in the top level applet object and linked directly with user-defined interface components. A standard Server_Proxy class, generated by the HIDL compiler, is used by the applet class for remote invocation of the server function makeQuery.
Using this architecture, the applet and the gateway only need to agree on a request and a return class, i.e. Table and Request for data exchange. Both classes can be application-specific with little or no structural information of the database. In fact, the applet can be considered as a high level of abstraction for representing business objects, with all database specific entities encapsulated within the gateway server. By implementing a variety of native database functions within the Sybconnect class, a client applet is capable to access remote databases transparently, including mainframe legacy systems, in a true distributed computing environment.
As a result, the use of HORB eliminates the burden of dealing with socket level programming and enables rapid development of distributed applications on the Web. The basic process of creating distributed client and the gateway server objects using HORB can be summarized in the following steps:
In this paper, we have demonstrated a methodology for developing distributed database applications on the Web using Java. Compared with the conventional CGI-based approach for database applications, the Java-based approach is more flexible, portable, scalable and robust. It provides a means to achieve a high degree of object mobility, targeted specifically to the Web. Based on the concept of Object Request Broker, HORB provides an efficient way for developing Java-based client/server applications, in which low level communications are handled automatically by a request broker, allowing developers to concentrate on high level application objects.
Following the proposed methodology, future development will be conducted in identifying generic request and return classes in database applications, and in creating presentation classes through the use of AWT in Java. We hope that through the use of Java, a new strategy to develop, deploy and maintain client/server applications can be established. Instead of installing client packages on users' computers and upgrading them for every new release, a user can download the client software in the form of a Java applet directly from the Web. The cost for maintaining and deploying client software can be radically reduced. By using a uniform Web infrastructure with mobile Java applets, mission-critical applications can be supported in the most efficient and effective fashion within a corporate environment.