May 6-10, 1996, Paris, France
Stathes P. Hadjiefthymiades (stathes@wand.di.uoa.gr)
Drakoulis I. Martakos (martakos@di.uoa.gr)
Department of Informatics, Faculty of Science
University of Athens
TYPA Building, University Campus at Ilisia,
Athens, Greece
Abstract
The World Wide Web (WWW) service currently experiences a tremendous grow-up, often imposing the necessity for the retrieval of information residing in RDBMSs. This paper presents a generic framework comprising a standardised approach as well as a software prototype for the implementation of such RDBMS-to-WWW links. The term generic illustrates the fully dynamic character of the proposed framework. Such character renders feasible the functional adaptation to any RDBMS-database-table combination, providing the means for QBE form set-up and non-predefined SQL queries execution.
Keywords: RDBMS-to-WWW links, Query Specification File (QSF), On-the-fly Form generation, Query Execution, Dynamic SQL, Multi-table QBE, Joins, CGI.
Nowadays, it is widely agreed that WWW evolves to the defacto standard for telematic applications in wide area networks. This hypermedia Internet service, adhering to the client-server model of computation, was conceived and developed at CERN, European Particle Physics Laboratory in Geneva by Tim Berners-Lee and his colleagues [1]. WWW greatly owns its success in the standardisation which governs in the communication between information servers (WWW servers) and clients (WWW browsers). Clients can operate in a variety of textual or graphical environments executing on diverse hardware platforms (PCs, Macintoshes, SUN Sparcs, etc.). The same applies to WWW servers (Windows NT, Windows 95, UNIX, etc.). The three standards which are primarily involved in their communication are: URI (Universal Resource Identifiers) [2], [3] HTTP (HyperText Transfer Protocol) [4] and HTML (HyperText Markup Language) [5].
WWW servers carry specialised software, called HTTPD (HTTP Demon) which receives and dispatches HTTP requests. The need to incorporate information sources other than static HTML files (pages) forced the standardisation of the communication between HTTPD and application programmes. Such standardisation attempts resulted to the specification of Common Gateway Interface (CGI) [6].
CGI applications handling the retrieval of information from databases controlled by RDBMSs (i.e. Sybase, SQL Server) have been around for quite a long time. Initial attempts to integrate RDBMSs and HTTPDs led to the development of sets of libraries (mainly in C or Perl, available on the Net) which could provide access to SQL databases. This approach was mainly based on Embedded SQL or other classical database APIs (e.g. SQL Server's DB Library). As a very small number of software interfaces were placed between the HTTPD and the database manager, response times were considerably low. Drawbacks in this scenario (herein after referred to as Scenario A) included: the need to restructure and recompile application programmes each time a new database access (retrieval, insertion, etc.) was required. Database and table definitions were hard coded (fully customised solution, application specific). CGI programmes developed in this way could not be reused for other queries in the context of the WWW server while their deployment required a significant programming effort and knowledge of the standards involved (CGI, URI, etc.). Scenario A is presented in Figure 1.a.
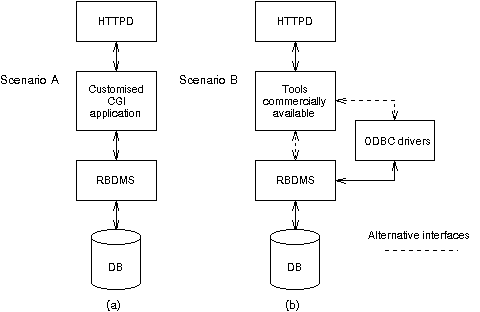
Figure 1: Scenarios for WWW to RDBMS links
Scenario B, presented in Figure 1.b, approaches the same problem in a different way. The basic functional component in scenario B is a commercial product capable of interfacing a variety of different RDBMSs to HTTPDs. Such products, in most cases, employ ODBC (Open DataBase Connectivity) drivers in order to accomplish connectivity to a range of relational systems (flat file systems are also accessible through ODBC). Indicative examples of such tools are dbWeb coming from Aspect Software Engineering [7] and Nomad’s WebDBC [8]. WWW server administrators specify DB accesses (selects, insertions, etc.) in specialised files or URLs. Deficiencies of this scenario include: the overhead of placing multiple software interfaces between the HTTPD and the database administration system. Employing ODBC drivers usually imposes a significant time delay in database accesses. Most of these products are available for the Windows NT environment and costly while their memory requirements are impressively high. Finally, the characteristics and structure of the WWW-to-database link are dictated and confined by the features of the product, thus providing limited flexibility. Pros in this scenario include the limited need for programming and the reusability of the software components involved.
This paper discusses a different approach, whose principal objective is to bridge the gap between the two scenarios presented above. It concerns the specification, design and prototype development of a generic interface (Scenario B) which accesses databases in a way similar to the one analysed in Scenario A. Thus, the derived prototype is both reusable and fast. Work presented is based on widely accepted standards such as CGI, HTTP, Dynamic SQL while the developed prototype integrates certain software modules which are publicly available (i.e. the CGI libraries in C accompanying the NCSA httpd). The concept of the Query Specification File (QSF) is introduced. QSFs constitute a core idea in the proposed framework. Their design was driven by the need to obtain a database - table independent WWW gateway to RDBMSs (i.e. QSFs incorporate database as well as presentation related components). QSF is analysed in detail in Chapter 2. Chapter 3 presents the architecture of the developed prototype as well as certain technical details. Emphasis is placed on issues related to database access and query string formulation. Database access in implemented through an X/Open compliant memory structure setting the basis towards an RDBMS independent gateway (truly generic). Finally, Chapter 4 summarises the overall work presented and concludes to some suggestions about future work (expansion of the prototype, inclusion of other facilities) and research on this area.
Work in this paper assumes that the process of database access is divided in two distinct stages (1 and 2). Stage 1 refers to the set-up of a QBE (Query By Example) form for the specification (by the user) of the query to be executed. QBEs that can be built through our prototype comprise a subset of the original QBEs as proposed by Zloof [9]. The only section of a SELECT statement users can affect, through their interaction with the QBE form, is the WHERE clause. Stage 2 refers to the presentation of query results to the user. At this point, it should be noted that our prototype is capable of handling only the retrieval of information (i.e. SELECT statements) from databases. Insertion, deletion and update capabilities are to be incorporated in subsequent versions of the software and require some additional work in the field of user authentication (for the purpose of matching granted privileges to user IDs etc.). Figure 2 presents the basic components involved in the process of database access (in relation to the WWW service) as well as the sequence of information exchanges between them. Exchanges with numbers ranging from 1 to 7 constitute Stage 1. Remaining exchanges constitute Stage 2. Figure 2 also indicates the internal structure of the developed prototype.
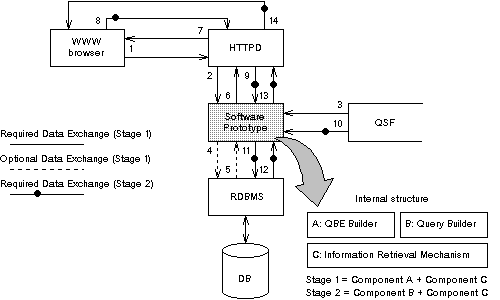
Figure 2: Sequence of information exchanges & prototype internal structure
As indicated in Figure 2, prior to each database access and output to HTTPD the prototype extracts data from the QSF. QSFs are considered a core idea in the process of database access and support the operation of the prototype in both Stages (1 and 2). QSFs are plain text files that contain commands and fields capable of fully specifying the database access process in the context of the WWW service (presentation and database access). The content of a typical QSF is provided in Figure 3.
$DATABASE-NAME test $QBE header.html footer.html $QBE-FIELDS ttable1.number,[first_option,second_option,third_option] ttable1.name,[DATABASE] ttable1.code,<SIZE=30 MAXLENGTH=80> ttable2.code,<TYPE=PASSWORD> x.code1 $SUBMIT-STRING Submit Query $RESET-STRING Reset Form ' Comment Line $SELECT-FIELDS ttable1.x ttable2.y $JOINS ttable1.cd=ttable2.cd,<per> ttable2.code=10,<1> $RESULTS-TABLE header.html footer.html
Figure 3: Typical Query Specification File
A QSF is divided in sections. Each section constitutes a different QSF component. Some sections are used, exclusively, for building up and/or specialising HTML elements (presentation related) while others are indispensable to the database access process (database related).
QSF sections consist of a header and a body. Section header is preceded by "$" and determines the kind of action to be taken when the prototype executable encounters the line(s) of the section body. For example, the $DATABASE-NAME header instructs the prototype to consider the content of the next line as the database name. Additional information concerning the lines of the section body is provided within "< >" constructs at the end of each line. In the case of $QBE-FIELDS, the "[ ]" construct indicates the range of values applicable in the respective entry. This last feature is used for the population of combo lists in QBE forms. The exact meaning of each section will be analysed in detail in subsequent paragraphs. Lines preceded by single quotes are considered comment lines. Different lines in the QSF are handled as different entries-fields.
It is very important to visualise the database access process in relation to the QSF. Figure 4 demonstrates the scope of the various components of the QSF.
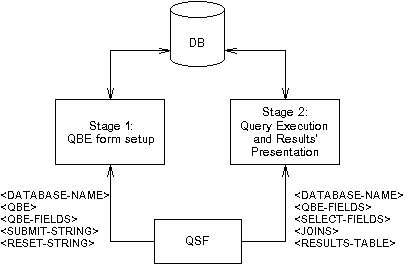
Figure 4: Relation between QSF and Stages 1 and 2
The information contained in QSF sections is interpreted by the prototype as follows:
DATABASE-NAME: The name of the database containing the tables to be accessed by the query. Databases, in relational terminology, are collections of logically associated files (tables).
QBE: This section contains a two lines body. The first line is interpreted as the name of the HTML file to be displayed before the entry fields comprising the QBE. In other words, this HTML file will be incorporated as a form header. The second line contains the name of the file to be used as a footer in the QBE form.
QBE-FIELDS:
This is one of the most important sections of the QSF. The length of its body, in lines, is not fixed. Each line represents a different entry field which will participate in the QBE formulation. Fields comprising the QBE form are existing database fields (given in the form table_name.field_name). Users, through their interaction with the WWW browser, may impose logical restrictions to be satisfied by the respective fields in the query results. Specified restrictions are logically combined through the AND operator (conjunction). Their combination constitutes the WHERE part of the query (in this paper SQL query=SELECT part+FROM part+WHERE part). QBE field definitions contained in the QSF are mapped, by the prototype, to valid HTML FORM elements. This mapping, in some cases, requires access to the underlying database (exchanges 4 and 5 in Figure 2). Such cases will be analysed in detail in the following sections.
SUBMIT-STRING, RESET-STRING: Both QSF sections contain single line bodies. Their contents are incorporated in the FORM definition returned by the prototype as captions for the SUBMIT, RESET buttons respectively.
SELECT-FIELDS: The body length of this section is not fixed. Each line represents a different database field to be included in the SELECT part of the SQL query. Aggregate function calls are also applicable in this section. Practically, the body length dictates the number of columns to be returned by the query.
JOINS:
The body length of this section is not fixed. Each line represents a different join restriction to be included in the WHERE part of the query. Join restrictions correlate fields in different database tables. Their inclusion may be required or not, depending on the nature of the query and the field restrictions imposed by users during their interaction with the QBE form. The QSF syntax provides for both cases through "< >" constructs. Entries followed by <per> should always form part of the WHERE clause (permanent association). Entries followed by <x> should be incorporated in case the formulated query contained restrictions on the xth entry of the QBE-FIELDS section (ad hoc association). In effect, this section presents an effort to extent the classical, single table QBE mechanism.
RESULTS-TABLE: This section contains a two lines body. The first line is interpreted as the name of the HTML file to be displayed before the results' table (query results are returned in HTML TABLEs). The second line contains the name of the file to be used as a footer in the results' page.
Some of the sections presented above affect accesses to the underlying database while others the presentation of HTML pages generated by the prototype. Such separation is presented in Table 1.
QSF section DB related HTML related DATABASE-NAME * QBE * QBE-FIELDS * * SUBMIT-STRING, RESET-STRING * SELECT-FIELDS * JOINS * RESULTS-TABLE *
Table 1: Classification of QSF sections
$QBE-FIELDS entries to HTML commands
For the purposes of the following paragraph the reader should refer to the QSF example presented in Figure 3. $QBE-FIELDS entries followed by "[]" constructs are converted to HTML <SELECT> commands. Select options (<OPTION>) can be provided within the "[]" construct (explicit declaration) or, alternatively, extracted from the database (implicit declaration). An example for the former case is given through the entry:
ttable1.number,[first_option,second_option,third_option]
of the QSF in Figure 3. This entry is expanded to the following HTML commands:
ttable1.number: <SELECT NAME="fld1"> <OPTION> <OPTION>first_option <OPTION>second_option <OPTION>third_option </SELECT><p>
The field is assigned the name "fld1" since its definition in the first encountered in this section. The first option (empty) is the option selected in the initial state of the form (default). Since the number of visible items is not defined, the resulting form entity will always be a pop-down menu. An example for the latter case is given through the entry:
ttable1.name,[DATABASE]
In this case the prototype formulates and executes the query "SELECT DISTINCT ttable1.name FROM ttable1" and returns all results as select options (preceded by the <OPTION> element). An empty option is also included as the first option. This field is assigned the name "fld2".
Entries without "[ ]" constructs are expanded to Input fields. If no additional information is provided an <INPUT name="fldx"> element is returned (x takes integer values starting from 1). Thus, the fifth entry of the QBE-FIELDS section in Figure 3 is converted to:
x.code: <INPUT name="fld5"><p>
The remaining entries of the example are followed by "< >" constructs. Data contained in "< >" are syntactically valid HTML definitions (not parsed by the prototype) and incorporated (without modifications) in the derived input element. Thus the entry:
ttable1.code,<SIZE=30 MAXLENGTH=80>
is converted to:
ttable1.code: <INPUT SIZE=30 MAXLENGTH=80 NAME="fld3"><p>
For the purpose of validating the design work presented in this paper we built a software prototype capable of interfacing httpd (tested with NCSA httpd 1.5) to the Informix RDBMS (Standard Engine Ver. 5). Both components operated in a typical SVR4 UNIX system. Prototype was built in C using the Embedded SQL precompiler (esql) and consists of two executables (bfrm and xqry). The former executable handles all Stage 1 procedures while the latter implements Stage 2. As showed in Figure 2, both executables share a common information retrieval mechanism (component C).
As indicated in Figure 2, all Stage 1 procedures (bfrm) are dispatched by the combination of components A and C (data retrieval mechanism). The invocation of the prototype can be accomplished through the inclusion of the following hypertext link in a typical HTML page:
<A href="cgi-bin/bfrm?path_to_QSFs/test.qsf">Access to INFORMIX database through test.qsf</A>
When the above link is activated (exchange 1, Figure 2), httpd sets up a CGI environment and invokes the bfrm executable (exchange 2). The latter reads the portion of the query specification file (exchange 3) pertaining to Stage 1 (as indicated in Fig.4) and builds the QBE form accordingly. As soon as the QBE form appears in the WWW browser (exchanges 6 & 7), Stage 1 procedures are completed. The preparation of the QBE form is basically the role of component A. Stage 1 may also include database accesses (if [DATABASE] constructs are included in the QSF). In such case component C is invoked.
The QBE form is a valid HTML page containing a FORM section. The FORM element has the following format:
<FORM ACTION="/cgi-bin/xqry" METHOD="POST">
Input and Select elements are contained in the FORM section according to the contents of the Query Specification File and the mapping mechanism presented in Section 2. One additional Input element is included in the FORM section for the purpose of passing the QSF path and filename to the xqry executable. The relevant HTML command is provided below:
<INPUT TYPE="hidden" NAME="fld0" VALUE="path_to_QSFs/test.qsf">
Thus, the xqry executable (Stage 2) knows how to handle information returned by the QBE form. It can map the "fld" values (passed through standard input due to POST method) to the entries of the QBE-FIELDS section, retrieve the required SELECT-FIELDS, JOINS, build up the appropriate SQL statement and execute it on the specified database.
The dataflow diagram of Stage 1 is relatively simple and presented in Figure 5 (numbers in circles denote exchanges of data with respect to Figure 2).
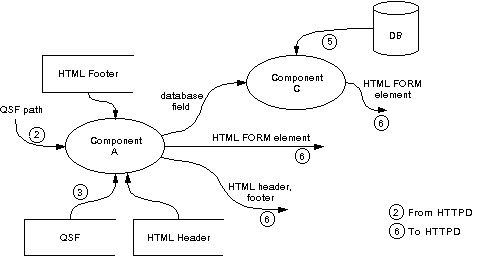
Figure 5: QBE Form set-up process (Stage 1)
Figure 6 illustrates the process of query set-up and execution (Stage 2), through a typical data flow diagram (numbers in circles denote relevant information exchanges with respect to Fig. 2). The various processes presented in Figure 6 are briefly presented below.
As pointed out in the introduction of this paper, the prototype (more accurately, component B in the xqry executable) integrates part of the CGI utilities accompanying the NCSA httpd. This part is used for the purpose of decoding CONTENT_LENGTH characters of standard input (stdin). The contents of input stream, after the decoding process, are mapped to specific database fields (according to the QSF) and properly transformed in order to become syntactically correct parts of an SQL statement (adaptation to SQL syntax). Indicative examples of such transformation (performed by component B) are provided in Table 2.
field, decoded value WHERE part component (component after decoding) (component after mapping & transformation) fldx=Stathe* table_A.field_B MATCHES "Stathe*" fldx=Drak? table_A.field_B MATCHES "Drak?" fldx=Stathes|Drakoulis table A.field_B="Stathes" OR table_A.field_B="Drakoulis" fldx=<Hadjiefthymiades table_A.field_B<"Hadjiefthymiades" fldx=<90 table_A.field_B<90 fldx=<>40 table_A.field_B<>40 fldx=80|23 table_A.field_B=80 OR table_A.field_B=20 fldx=a80|23 table_A.field_B="a80" OR table_A.field_B="20" fldx=Drakoulis table_A.field_B="Drakoulis"
Table 2: Formulation of WHERE part components
After the processing described above, xqry builds the WHERE part of the SELECT statement to be executed. Join restrictions, if applicable (if they were specified as permanent (<per>) or users interacted with the respective QBE fields), are concatenated to the above string. The SELECT and FROM parts are easily constructed and combined. Subsequently, the SQL statement (contained in a simple string) is submitted to the information retrieval component (component C, Figure 2) for further processing.
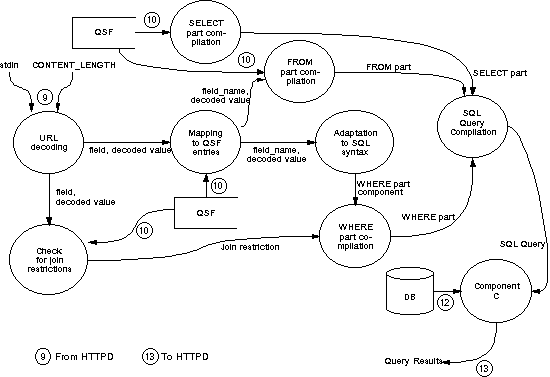
Figure 6: Query set-up and execution (Stage 2)
Query execution is implemented through Dynamic SQL which has be subjected to standardisation by X/Open. Dynamic SQL allows applications to interact with database tables and fields without prior knowledge of their structure, datatypes, length etc. (fully dynamic access) [10]. Data retrieval throughout the prototype is based on the Dynamic SQL capabilities of the X/Open compliant Informix RDBMS [11]. The retrieval mechanism presented below is mainly used in Stage 2 (exchanges 11, 12) but also included in Stage 1 for the population of combo lists in QBE forms (optional exchanges 4, 5). Component C in Figure 2 represents this mechanism.
When executing a query in Dynamic SQL, space in memory can be allocated ad hoc, according to the contents of the system Descriptor Area (DA). DA is a fully standardised (X/Open) memory structure (a perplexing combination of pointers and arrays) indicating the number of columns fetched as well as their particular characteristics (datatype, length, name, precision, scale, etc.). Furthermore, DA contains pointers to the actual data. As the database access through 3-GLs (i.e. C, COBOL) is cursor based, pointers to data are updated each time a new row is fetched by the system. In our case, component C scans the whole Descriptor Area after each invocation of the cursor FETCH command and prints its contents. The overall mechanism for database access (herein referred to as component C) is presented in Figure 7.
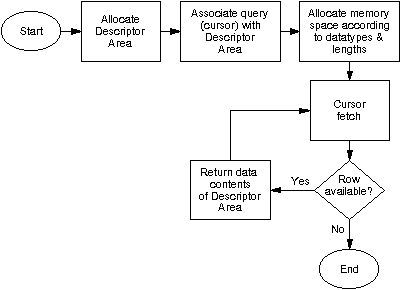
Figure 7: Information retrieval through the Descriptor Area (component C)
The aforementioned X/Open structure rendered our prototype capable of accessing any database table, without the need for hardcoded definitions, system tables lookup etc. In addition to the above, through the functionality of the DATABASE command (Embedded SQL), the prototype could access the whole range of available databases. As databases and query specification files can reside in totally different directories from those of httpd (irrelevant to httpd directory structure), the security of the interface is guaranteed. In the case of Informix OnLine Server (which is also compatible with our prototype), databases are no longer visible in the UNIX file system. Finally it should be noted that in Stage 2, query results are presented to the user in HTML tables (HTML 3).
Throughout this paper we presented a generic approach for interfacing HTTPDs to RDBMSs. The need for such links is frequently experienced due to the tremendous grow-up of the WWW service. Our approach is, primarily, based on the Query Specification File. The philosophy of QSF design was demonstrated through a brief description of its various sections. A significant amount of time was consumed, during QSF design, in order to tackle the problem of multi-table QBEs (resulting to queries containing joins). We concluded to a classification of join restrictions (<per>, <x>) which provides a very flexible mechanism for QBE set-up. A clever utilisation of such facility extends the range of queries our prototype is capable of handling.
Another important issue addressed, refers to the retrieval of information from RDBMSs. In this respect, older gateways incorporated hard coded definitions which resulted to very limited software reusability. Newer commercially available, generic tools are mainly ODBC based and appeared in the computer market very recently. Our prime concern was the development of a relatively simple and fast software tool. We persisted in classical database APIs (Embedded SQL) but employed the SQL Descriptor Area, a standardised memory structure, in order to render our prototype generic. Thus, we managed to built a database/table independent interface between any CGI compliant HTTP demon (UNIX based) and Informix. We believe that many problems still need to be resolved.
Future work in this area will include research on issues related to insertions, deletions and updates of data in the context of the WWW service. The SQL Descriptor Area provides for the dynamic implementation of all cases. However, the functional combination of stateless HTTP and non-idempotent database operations needs to be thoroughly investigated. BLOB (Binary Large OBjects) handling may also constitute a future enhancement to our prototype. Relevant libraries for the Informix RDBMS, are available in firm's WWW server (http://www.informix.com).
Our prototype, currently, handles relatively simple SQL queries. It can be easily expanded (through the inclusion of additional sections in the QSF) for the purpose of dispatching more complex queries (incorporating ORDER BY, HAVING, GROUP BY etc.). Furthermore, the QSF structure could be expanded for the purpose of covering the individualities of each RDBMS (query optimisation approach, etc.) thus allowing the prototype to take full advantage of them.
As pointed out, our software prototype is capable of interfacing to the X/Open compliant Informix RDBMS (SE and OnLine). Currently, we are in the process of investigating its portability to other relational systems. We believe that this investigation will verify our allegations due to the X/Open standards adopted. Perhaps, only minor changes will be needed towards a totally generic framework. To incorporate these changes (if needed) we will proceed with the development of a variety of interfacing modules like those presented in Figure 8. RDBMS dependent functions will be separated from others, resulting in a layered software architecture.
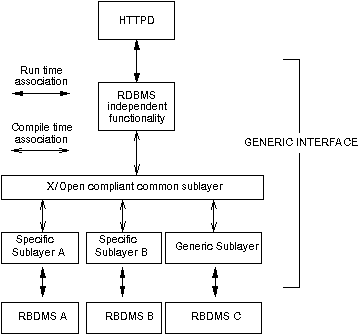
Figure 8: Target architecture for RDBMS independent software
Additional work will be done in the fields of QSF validation and construction. Currently, no validation is realised throughout the prototype operation on the contents of the QSF. Tables and fields are not verified against the specified database. To this respect, a supplementary visual editing utility capable of constructing validated QSFs is considered a required component of the prototype in its future versions. Such utility is currently under development.
[1] Berners-Lee T., Cailliau R., Luotonen A., Frystyk Nielsen H. and Secret A.: The World -Wide Web, Communications of the ACM, Vol.37 No.8. (August 1994).
[2] Berners-Lee T.: Universal Resource Identifiers in WWW: A Unifying Syntax for the Expression of Names and Addresses of Objects on the Netwrok as used in the World Wide Web, RFC 1630, CERN (June 1994).
[3] Berners-Lee T., Masinter L. and McCahill M. Editors: Uniform Resource Locators (URL), RFC 1738, CERN, Xerox Corporation, University of Minnesota (December 1994).
[4] Berners-Lee T., Fielding R.T. and Frystyk Nielsen H.: Hypertext Transfer Protocol - HTTP/1.0, HTTP Working Group, Internet Draft (October 1995).
[5] Ragget D.: HyperText Markup Language Specification Version 3.0, HTML 3.0, Internet Draft (March 1995).
[6] December John and Ginsburg M.: HTML & CGI Unleashed, Sams.net Publishing (1995).
[7] Laurel Jim: dbWeb White Paper, Aspect Software Engineering Inc. (August 1995).
[8] WebDBC White Paper #1, A Quick Overview of the WebDBC 1.0 Architecture, Nomad Development Corporation (February 1995).
[9] Zloof M.M.: Query By Example, Proc. NCC 44, Anaheim, Calif. (May 1975). Montvale, N.J.: AFIPS Press (1977).
[10] Date C. J.: An Introduction to Database Systems Vol. I, Addison Wesley (1990).
[11] Guide to SQL: Reference, Informix Software Inc. (December 1991).