![\begin{figure}\centering %\includegraphics[width=0.4\columnwidth, angle=-90]{pdf/pagerank-over-time.pdf}\ \vspace{-2.5mm} \vspace{-0.55cm} \end{figure}](pp044-berberich-img1.png)
|
Link-based ranking methods like PageRank [7] play a crucial role in today's search engines. In this context, such methods indicate the importance of individual Web pages based on the current state of the Web graph. This current state contains all pages and links that were added but not yet removed and is thus the result of the Web's entire evolution. However, methods like PageRank do not properly reflect the evolutionary trajectory of the Web (i.e., links and pages recently removed or added), which is substantial as reported in [2,5,6]. As a consequence, PageRank and the like are not appropriate to serve information needs on timelines and trends as the following example demonstrates.
We use a bibliographic network derived from the Digital Bibliography & Library Project (http://dblp.uni-trier.de) as a showcase here, since obtaining an adequate Web dataset would involve frequent crawling of a significant fraction of the Web. Let us, on the one hand, consider an information need for seminal publications in database research. In our bibliographic network, PageRank identifies E. F. Codd's A Relational Model of Data for Large Shared Data Banks as the most important publication, which is reasonable given this information need. On the other hand, the information need could be for publications in databases that are not yet very important but currently gain a lot of importance; a scenario for which PageRank fails as the example demonstrates. Figure 1 plots PageRank scores of the aforementioned publication and Agrawal et al.'s Mining Association Rules between Sets of Items in Large Databases for the years 1990 through 1999. Although, for any of the depicted times Codd's paper is ahead in terms of importance by an order of magnitude at least, its importance score is close to stagnation. In contrast, the other paper improves its importance score in the considered period by a factor of more than ten.
If the second information need arises at any point between 1993 and 1999, Agrawal et al.'s paper could be identified as a better result by means of the trend contained in its time series of PageRank scores.The BuzzRank method proposed in this work builds on this idea. It analyzes time series of importance scores and quantifies the contained trends based on a growth model of importance scores. Thus, for instance, in a bibliographic network, the method identifies those publications that have significantly increased their importance in a specific time interval, which -more colloquially- are the publications that caused significant buzz in that period. Therefore, BuzzRank's objectives differ from earlier related work [1,3,8] that sought to improve link-based importance ranking by means of temporal features. However, BuzzRank is complementary rather than a replacement to PageRank, and thus seeks to serve information needs as the one above.
BuzzRank exploits the fact that importance scores co-evolve with the Web graph and considers the following time series of importance scores for individual pages.
Let ![]() denote the
graph snapshot at time
denote the
graph snapshot at time ![]() consisting
of the set of nodes
consisting
of the set of nodes ![]() and the
set of edges
and the
set of edges ![]() . The vector of
PageRank scores computed on the graph
. The vector of
PageRank scores computed on the graph ![]() is referred to as
is referred to as ![]() . Since PageRank scores are not comparable across
graphs from different points in time (with different graph
sizes), a new kind of normalization problem arises that we solve
as follows. The vector
. Since PageRank scores are not comparable across
graphs from different points in time (with different graph
sizes), a new kind of normalization problem arises that we solve
as follows. The vector ![]() is
normalized dividing by
is
normalized dividing by
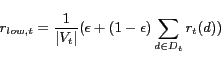
For an individual node ![]() we consider the time series of importance scores
we consider the time series of importance scores
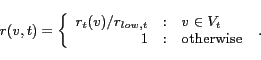
The growth of PageRank scores over time has been modeled by
Cho et al. [4]
using the logistic growth model (aka. Verhulst growth
model) - a specific case of the following generic growth
model:
We assume for the growth rate ![]() that it is time-invariant as
that it is time-invariant as ![]() within
within
![]() . Later
this assumption is empirically substantiated. Using the
time-invariant growth rate we obtain the following exponential
growth model for times in the considered time
interval
. Later
this assumption is empirically substantiated. Using the
time-invariant growth rate we obtain the following exponential
growth model for times in the considered time
interval
Since the series of observation times
![]() does not necessarily include
does not necessarily include
![]() , the value
, the value
![]() may be
unknown. Therefore, an additional parameter
may be
unknown. Therefore, an additional parameter
![]() is
introduced to the model, so that we obtain the final
model
is
introduced to the model, so that we obtain the final
model
Using the method of least squares we fit the model to
the observed time series values, i.e., we minimize
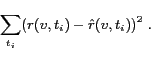
This growth rate ![]() quantifies the trend in the time series of the node's importance
scores and thus, as we argued in the introduction, is a good
indicator for the buzz caused by the node in the considered
time-interval. BuzzRank provides its final ranking assigning
every node
quantifies the trend in the time series of the node's importance
scores and thus, as we argued in the introduction, is a good
indicator for the buzz caused by the node in the considered
time-interval. BuzzRank provides its final ranking assigning
every node ![]() its estimated growth
rate
its estimated growth
rate ![]() as a score.
as a score.
Since no adequate Web dataset is available (i.e., time series of periodically repeated Web crawls), we use the free DBLP bibliographic dataset for our preliminary experiments. We only consider the period from 1989 through 1999 as this period has the most densely recorded citations in DBLP. In the graph that we derive from DBLP nodes represent publications and edges represent citations.
As input to BuzzRank we computed PageRank vectors for the
graphs at times corresponding to the begins of the years 1989
through 1999 yielding a total of eleven observations per time
series. The damping factor for the PageRank computations was set
to
![]() .
.
In the first of our experiments, we empirically analyze our
assumption that ![]() can be considered as time-invariant. Note that if
can be considered as time-invariant. Note that if ![]() is nearly
constant over a period of
is nearly
constant over a period of ![]() successive observations, there must be a strong linear
relationship observable between
successive observations, there must be a strong linear
relationship observable between
![]() and the log-transformed
time series values
and the log-transformed
time series values
![]() .
Therefore, we computed correlation coefficients for varying
.
Therefore, we computed correlation coefficients for varying
![]() across all nodes. Since
we are only interested in the strength of the linear relationship
but not in its direction, we computed average absolute
correlation coefficients for different values of
across all nodes. Since
we are only interested in the strength of the linear relationship
but not in its direction, we computed average absolute
correlation coefficients for different values of ![]() . For three successive
observations (i.e.,
. For three successive
observations (i.e., ![]() ) this
yields a value of
) this
yields a value of ![]() . For
four up to seven successive observations, slightly lower but
consistent values about
. For
four up to seven successive observations, slightly lower but
consistent values about ![]() are observed. Thus, there is a strong linear
relationship and therefore assuming time-invariance for
are observed. Thus, there is a strong linear
relationship and therefore assuming time-invariance for
![]() is
reasonable.
is
reasonable.
As a second experiment we computed rankings using BuzzRank for
two year intervals (i.e., three successive observations). For
most publications in DBLP only the year of publication is known,
consequently granularities more fine-grained than the year-level
are not meaningful. In Table 1 the
publications top-ranked by BuzzRank for the two year intervals
are given.
The results indicate that BuzzRank indeed brings publications
related to hot topics in the respective period to the top. For
the intervals ![]() and
and
![]() , for instance,
publications related to the Web and XML are ranked
at the top respectively. In marked contrast, the use of PageRank
resulted in the publication by E. F. Codd mentioned in the
Motivation to be the top-ranked item in each time interval.
, for instance,
publications related to the Web and XML are ranked
at the top respectively. In marked contrast, the use of PageRank
resulted in the publication by E. F. Codd mentioned in the
Motivation to be the top-ranked item in each time interval.
[1] E. Amitay, D. Carmel, et al.
Trend Detection Through Temporal Link Analysis.
JASIST, 55(14):1270-1281, 2004.
[2] Z. Bar-Yossef, A. Z. Broder, et al.
Sic Transit Gloria Telae: Towards an Understanding of the Web's
Decay.
WWW '04.
[3] K. Berberich, M. Vazirgiannis, et al.
Time-aware Authority Ranking.
Internet Mathematics, 2006.
[4] J. Cho, S. Roy, et al.
Page Quality: in Search of an Unbiased Web Ranking.
SIGMOD '05.
[5] D. Fetterly, M. Manasse, et al.
A large-scale study of the evolution of web pages.
Software: Practice and Experience, 34(2):213-237,
2004.
[6] A. Ntoulas, J. Cho, et al.
What's New on the Web?: The Evolution of the Web from a Search
Engine Perspective.
WWW '04.
[7] L. Page, S. Brin, et al.
The PageRank Citation Ranking: Bringing Order to the Web.
Stanford Tech. rep., 1998.
[8] P. S. Yu, X. Li, et al.
On the Temporal Dimension of Search.
WWW '04.