Phishers can make victims visit their sites by spoofing emails
from users known by the victim, or within the same domain as the
victim. Recent experiments by Jagatic et al. [3] indicate that over ![]() of college students
would visit a site appearing to be recommended by a friend of
theirs. Over
of college students
would visit a site appearing to be recommended by a friend of
theirs. Over ![]() of the
subjects receiving emails appearing to come from a friend entered
their login credentials at the site they were taken to. At the
same time, it is worth noticing that around
of the
subjects receiving emails appearing to come from a friend entered
their login credentials at the site they were taken to. At the
same time, it is worth noticing that around ![]() of the subjects in a
control group entered their credentials; subjects in the control
group received an email appearing to come from an unknown person
within the same domain as themselves. Even though the same
statistics may not apply to the general population of computer
users, it is clear that it is a reasonably successful technique
of luring people to sites where their browsers silently will be
interrogated and the contents of their caches sniffed.
of the subjects in a
control group entered their credentials; subjects in the control
group received an email appearing to come from an unknown person
within the same domain as themselves. Even though the same
statistics may not apply to the general population of computer
users, it is clear that it is a reasonably successful technique
of luring people to sites where their browsers silently will be
interrogated and the contents of their caches sniffed.
Once a phisher has created an association between an email address and the contents of the browser cache/history, then this can be used to target the users in question with phishing emails that - by means of context - appear plausible to their respective recipients. For example, phishers can infer online banking relationships (as was done in [4]), and later send out emails appearing to come from the appropriate financial institutions. Similarly, phishers can detect possible online purchases and then send notifications stating that the payment did not go through, requesting that the recipient follow the included link to correct the credit card information and the billing address. The victims would be taken to a site looking just like the site they recently did perform a purchase at, and may have to start by entering their login information used with the real site. A wide variety of such tricks can be used to increase the yield of phishing attacks; all benefit from contextual information that can be extracted from the victim's browser.
There are several possible approaches that can be taken to address the above problem at the root - namely, at the information collection stage. First of all, users could be instructed to clear their browser cache and browser history frequently. However, many believe that any countermeasure that is based on (repeated) actions taken by users is doomed to fail. Moreover, the techniques used in [8,4] will also detect bookmarks on some browsers (such as Safari version 1.2). These are not affected by the clearing of the history or the cache, and may be of equal or higher value to an attacker in comparison to the contents of the cache and history of a given user. A second approach would be to once and for all disable all caching and not keep any history data; this approach, however, is highly wasteful in that it eliminates the significant benefits associated with caching and history files. A third avenue to protect users against invasive browser sniffing is a client-side solution that limits (but does not eliminate) the use of the cache. This would be done based on a set of rules maintained by the user's browser or browser plug-in. Such an approach is taken in the concurrent work by Jackson et al. [1]. Finally, a fourth approach, and the one we propose herein, is a server-side solution that prevents cache contents from being verified by means of personalization. Our solution also allows such personalization to be performed by network proxies, such as Akamai.
It should be clear that client-side and server-side solutions not only address the problem from different angles, but also that these different approaches address slightly different versions of the problem. Namely, a client-side solution protects those users who have the appropriate protective software installed on their machines, while a server-side solution protect all users of a given service (but only against intrusions relating to their use of this service). The two are complimentary, in particular in that the server-side approach allows ``blanket coverage'' of large numbers of users that have not yet obtained client-side protection, while the client-side approach secures users in the face of potentially negligent service providers. Moreover, if a caching proxy is employed for a set of users within one organization, then this can be abused to reveal information about the behavioral patterns of users within the group even if these users were to employ client-side measures within their individual browsers; abuse of such information is stopped by a server-side solution, like the one we describe.
From a technical point of view, it is of interest to note that
there are two very different ways in which one can hide the
contents of a cache. According to a first approach, one makes it
impossible to find references in the cache to a visited site,
while according to a second approach, the cache is intentionally
polluted with references to all sites of some class,
thereby hiding the actual references to the visited sites among
these. Our solution uses a combination of these two approaches:
it makes it impossible to find references to all internal
URLs (as well as all bookmarked URLs), while causing pollution of
entrance URLs. Here, we use these terms to mean that an
entrance URL corresponds to a URL a person would typically
type to start accessing a site, while an internal URL is
one that is accessed from an entrance URL by logging in,
searching, or following links. For example, the URL
http://test-run.com is an entrance URL since visitors
are most likely to load that URL by typing it in or following a
link from some other web site. The URL
http://test-run.com/logout.jsp, however, is
internal. This URL is far more interesting to a phisher
than the entrance URL; knowing that a client ![]() has been to this internal
URL suggests that
has been to this internal
URL suggests that ![]() logged
out of the web site -- and thus must have logged in. Our
solution will make it infeasible for an attacker to guess the
internal URLs while also providing some obscurity for the
entrance URLs.
logged
out of the web site -- and thus must have logged in. Our
solution will make it infeasible for an attacker to guess the
internal URLs while also providing some obscurity for the
entrance URLs.
Preliminary numbers support our claims that the solution results in only a minimal overhead on the server side, and an almost unnoticeable overhead on the client side. Here, the former overhead is associated with computing one one-way function per client and session, and with a repeated mapping of URLs in all pages served. The latter overhead stems from a small number of ``unnecessary'' cache misses that may occur at the beginning of a new session. We provide evidence that our test implementation would scale well to large systems without resulting in a bottleneck - whether it is used as a server-side or proxy-side solution.
Felten and Schneider [2] described a timing-based attack that made it possible to determine (with some statistically quantifiable certainty) whether a given user had visited a given site or not - simply by determining the retrieval times of consecutive URL calls in a segment of HTTP code.
Securiteam [8] showed a history attack analogous to the timing attack described by Felten and Schneider. The history attack uses Cascading Style Sheets (CSS) to infer whether there is evidence of a given user having visited a given site or not. This is done by utilizing the :visited pseudoclass to determine whether a given site has been visited or not, and later to communicate this information by invoking calls to URLs associated with the different sites being detected; the data corresponding to these URLs is hosted by a computer controlled by the attacker, thereby allowing the attacker to determine whether a given site was visited or not. We note that it is not the domain that is detected, but whether the user has been to a given page or not; this has to match the queried site verbatim in order for a hit to occur. The same attack was recently re-crafted by Jakobsson et al. to show the impact of this vulnerability on phishing attacks; a demo is maintained at [4]. This demo illustrates how simple the attack is to perform and sniffs visitors' history in order to display one of the visitor's recently visited U.S. banking web sites.
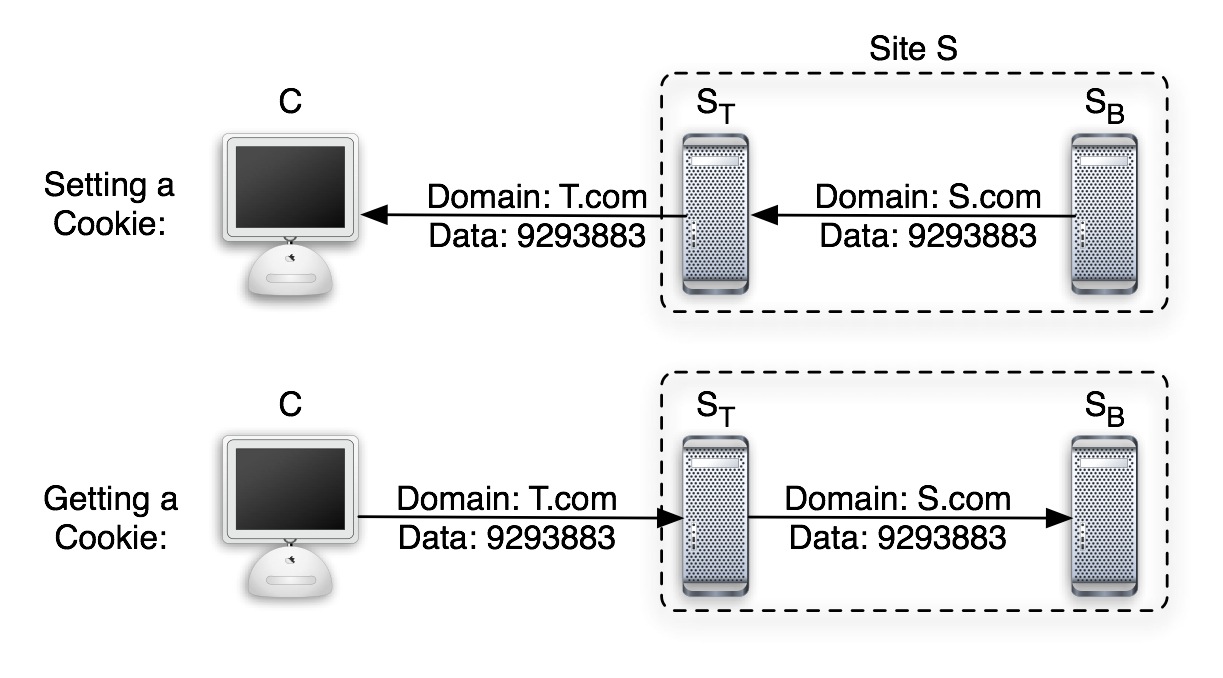
Our implementation may rely on either browser cookies or an
HTTP header called referer (sic). Cookies are small
amounts of data that a server can store on a client. These bits
of data are sent from the server to client in HTTP headers -
content that is not displayed. When a client requests a document
from a server ![]() , it sends along
with the request any information stored in cookies by
, it sends along
with the request any information stored in cookies by ![]() . This transfer is
automatic, and so using cookies has negligible overhead. The
HTTP-Referer header is an optional piece of information sent to a
server by a client's browser. The value (if any) indicates where
the client obtained the address for the requested document. In
essence it is the location of the link that the client clicked.
If a client either types in a URL or uses a bookmark, no value
for HTTP-Referer is sent.
. This transfer is
automatic, and so using cookies has negligible overhead. The
HTTP-Referer header is an optional piece of information sent to a
server by a client's browser. The value (if any) indicates where
the client obtained the address for the requested document. In
essence it is the location of the link that the client clicked.
If a client either types in a URL or uses a bookmark, no value
for HTTP-Referer is sent.
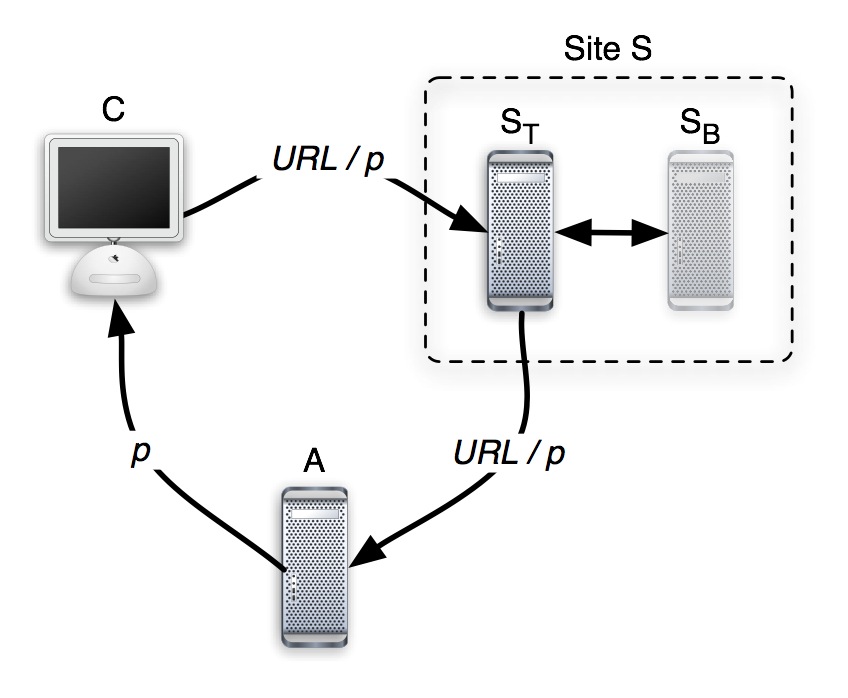
One particularly aggressive attack (depicted in Figure 1) that we need to be concerned with is one in which the attacker obtains a valid pseudonym from the server, and then tricks a victim to use this pseudonym (e.g., by posing as the service provider in question.) Thus, the attacker would potentially know the pseudonym extension of URLs for his victim, and would therefore also be able to query the browser of the victim for what it has downloaded.
|
|
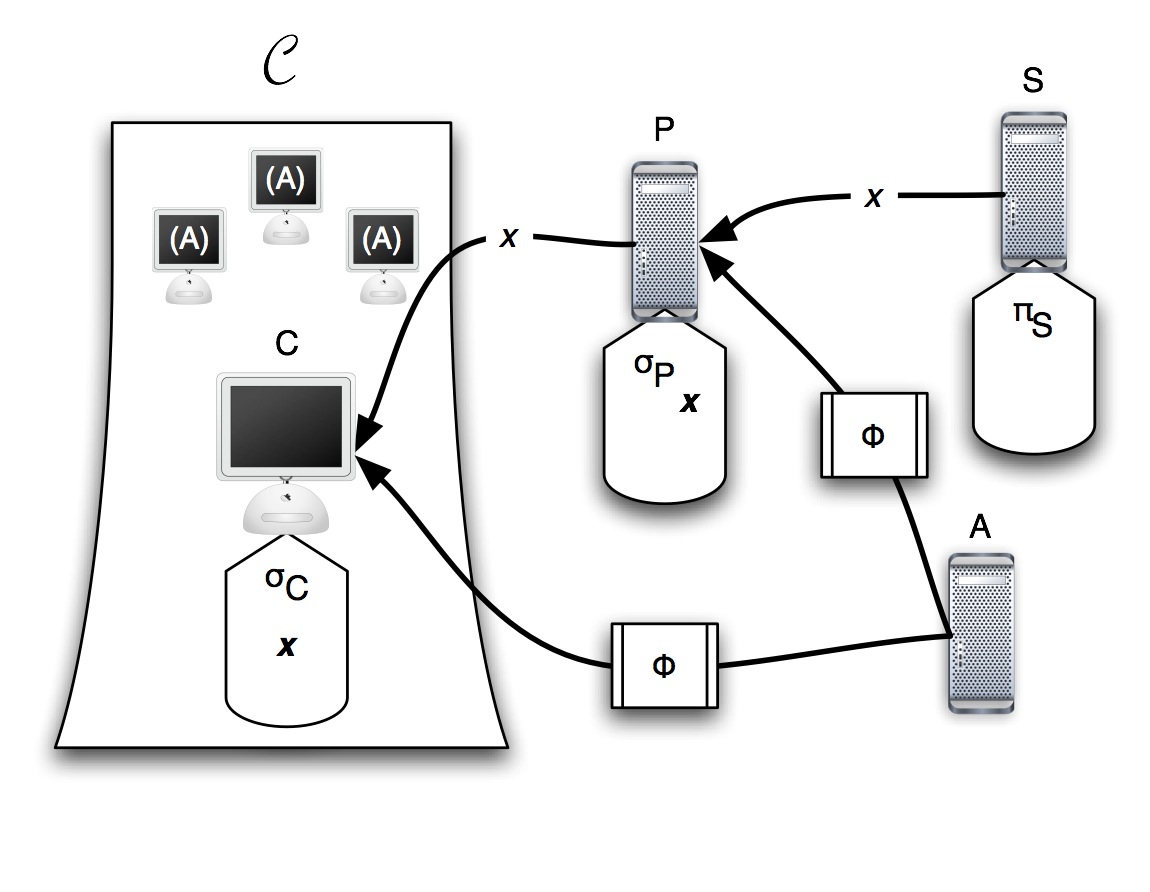
We let ![]() be an adversary
controlling any member of
be an adversary
controlling any member of ![]() but
but ![]() , and
interacting with both
, and
interacting with both ![]() and
and
![]() some polynomial number of
times in the length of a security parameter
some polynomial number of
times in the length of a security parameter ![]() . When interacting with
. When interacting with
![]() ,
, ![]() may post arbitrary requests
may post arbitrary requests ![]() and observe the responses; when interacting with
and observe the responses; when interacting with
![]() , it may send any document
, it may send any document
![]() to
to ![]() , forcing
, forcing ![]() to attempt to resolve this
by performing the associated queries. Here,
to attempt to resolve this
by performing the associated queries. Here, ![]() may contain any
polynomial number of URLs
may contain any
polynomial number of URLs ![]() of
of ![]() 's choice. A first goal of
's choice. A first goal of
![]() is to output a pair
is to output a pair
![]() such that
such that ![]() is true, and where
is true, and where
![]() and
and ![]() are associated. A second
goal of
are associated. A second
goal of ![]() is to output a pair
is to output a pair
![]() such that
such that ![]() is true, and where
is true, and where
![]() is
is ![]() -indicated by
-indicated by ![]() .
.
We say that ![]() is
perfectly privacy-preserving if
is
perfectly privacy-preserving if ![]() will not attain the first goal but with a negligible
probability in the length of the security parameter
will not attain the first goal but with a negligible
probability in the length of the security parameter ![]() ; the probability is taken
over the random coin tosses made by
; the probability is taken
over the random coin tosses made by ![]() ,
, ![]() ,
, ![]() and
and ![]() . Similarly, we say that
. Similarly, we say that
![]() is
is ![]() privacy-preserving if
privacy-preserving if
![]() will not attain the second
goal but with a negligible probability.
will not attain the second
goal but with a negligible probability.
Furthermore, we let ![]() be a
search engine; this is allowed to interact with
be a
search engine; this is allowed to interact with ![]() some polynomial number of
times in
some polynomial number of
times in ![]() . For each
interaction,
. For each
interaction, ![]() may post an
arbitrary request
may post an
arbitrary request ![]() and
observe the response. The strategy used by
and
observe the response. The strategy used by ![]() is independent of
is independent of
![]() , i.e.,
, i.e., ![]() is oblivious of the
policy used by
is oblivious of the
policy used by ![]() to respond to
requests. Thereafter,
to respond to
requests. Thereafter, ![]() receives a
query
receives a
query ![]() from
from ![]() , and has to output a
response. We say that
, and has to output a
response. We say that ![]() is
searchable if and only if
is
searchable if and only if ![]() can generate a valid response
can generate a valid response ![]() to the query, where
to the query, where ![]() is considered valid if and only if it can be
successfully resolved by
is considered valid if and only if it can be
successfully resolved by ![]() .
.
In the next section, we describe a solution that corresponds
to a policy ![]() that is
searchable, and which is perfectly privacy-preserving with
respect to internal URLs and bookmarked URLs, and
that is
searchable, and which is perfectly privacy-preserving with
respect to internal URLs and bookmarked URLs, and ![]() -privacy-preserving with
respect to entrance URLs, for a value
-privacy-preserving with
respect to entrance URLs, for a value ![]() corresponding to the maximum anonymity set of the
service offered.
corresponding to the maximum anonymity set of the
service offered.
At the heart of our solution is a filter associated with a server whose resources and users are to be protected. Similar to how middleware is used to filter calls between application layer and lower-level layers, our proposed filter modifies communication between users/browsers and servers - whether the servers are the actual originators of information, or simply act on behalf of these, as is the case for network proxies.
When interacting with a client (in the form of a web browser), the filter customizes the names of all files (and the corresponding links) in a manner that is unique for the session, and which cannot be anticipated by a third party. Thus, such a third party is unable to verify the contents of the cache/history of a chosen victim; this can only be done by somebody with knowledge of the name of the visited pages.
Pseudonyms and temporary pseudonyms are selected from a sufficiently large space, e.g., of 64-128 bits length. Temporary pseudonyms includes redundancy, allowing verification of validity by parties who know the appropriate secret key; pseudonyms do not need such redundancy, but can be verified to be valid using techniques to be detailed below.
Pseudonyms are generated pseudorandomly each time any visitor starts browsing at a web site. Once a pseudonym has been established, the requested page is sent to the client using the translation methods described next.
HTTP-Referer is an optional header field. Most modern browsers
provide it (IE, Mozilla, Firefox, Safari) but it will not
necessarily be present in case of a bookmark or manually typed in
link. This means that the referer will be within server
![]() 's domain if the link that
was clicked appeared on an one of the pages served by
's domain if the link that
was clicked appeared on an one of the pages served by ![]() . This lets us determine
whether we can skip the pseudonym generation phase. Thus, one
approach to determine the validity of a pseudonym may be as
follows:
. This lets us determine
whether we can skip the pseudonym generation phase. Thus, one
approach to determine the validity of a pseudonym may be as
follows:
Namely, one could - using a whitelist approach - allow certain types of robot processes to obtain data that is not pseudonymized; an example of a process with such permission would be a crawler for a search engine. As an alternative, any search engine may be served data that is customized using temporary pseudonyms - these will be replaced with a fresh pseudonym each time they are accessed. All other processes are served URLs with pseudo-randomly chosen (and then static) pseudonym, where the exact choice of pseudonym is not possible to anticipate for a third party.
More in particular, if there is a privacy agreement between
the server ![]() and the search engine
and the search engine
![]() , then
, then ![]() may allow
may allow ![]() to index its site in a
non-customized state; upon generating responses to queries,
to index its site in a
non-customized state; upon generating responses to queries,
![]() would customize the
corresponding URLs using pseudo-randomly selected pseudonyms.
These can be selected in a manner that allows
would customize the
corresponding URLs using pseudo-randomly selected pseudonyms.
These can be selected in a manner that allows ![]() to detect that they were
externally generated, allowing
to detect that they were
externally generated, allowing ![]() to
immediately replace them with freshly generated pseudonyms. In
the absence of such arrangements, the indexed site may serve the
search engine URLs with temporary pseudonyms (generated and
authenticated by itself) instead of non-customized URLs or URLs
with (non-temporary) pseudonyms. Note that in this case we have
that all users receiving a URL with a temporary pseudonym from
the search engine would receive the same pseudonym. This
corresponds to a degradation of privacy in comparison to the
situation in which there is an arrangement between the search
engine and the indexed site, but an improvement compared to a
situation in which non-customized URLs are served by the search
engine. We note that in either case, we have that the search
engine does is unable to determine what internal pages on an
indexed site a referred user has visited.
to
immediately replace them with freshly generated pseudonyms. In
the absence of such arrangements, the indexed site may serve the
search engine URLs with temporary pseudonyms (generated and
authenticated by itself) instead of non-customized URLs or URLs
with (non-temporary) pseudonyms. Note that in this case we have
that all users receiving a URL with a temporary pseudonym from
the search engine would receive the same pseudonym. This
corresponds to a degradation of privacy in comparison to the
situation in which there is an arrangement between the search
engine and the indexed site, but an improvement compared to a
situation in which non-customized URLs are served by the search
engine. We note that in either case, we have that the search
engine does is unable to determine what internal pages on an
indexed site a referred user has visited.
The case in which a client-side robot is accessing data corresponds to another interesting situation. Such a robot will not alter the browser history of the client (assuming it is not part of the browser), but will impact the client cache. Thus, such robots should be not be excepted from customization, and should be treated in the same way as search engines without privacy arrangements, as described above.
In the implementation section, we describe these (server-side) policies in greater detail. We also note that these issues are orthogonal to the issue of how robots are handled on a given site, were our security enhancement not to be deployed. In other words, at some sites, where robots are not permitted whatsoever, the issue of when to perform personalization (and when not to) becomes moot.
When ![]() 's cache is polluted,
the entries must be either chosen at random or be a list sites
that all provide the same pollutants. Say when Alice accesses
's cache is polluted,
the entries must be either chosen at random or be a list sites
that all provide the same pollutants. Say when Alice accesses
![]() , her cache is polluted
with sites
, her cache is polluted
with sites ![]() ,
, ![]() , and
, and ![]() . If these are the chosen
pollutants each time, the presence of these three sites in
Alice's cache is enough to determine that she has visited
. If these are the chosen
pollutants each time, the presence of these three sites in
Alice's cache is enough to determine that she has visited
![]() . However, if all four
sites
. However, if all four
sites ![]() ,
, ![]() ,
, ![]() , and
, and ![]() pollute with the same
list of sites, no such determination can be made.
pollute with the same
list of sites, no such determination can be made.
If ![]() cannot guarantee that all
of the sites in its pollutants list will provide the same list,
it must randomize which pollutants it provides. Taken from a
large list of valid sites, a random set of pollutants essentially
acts as a bulky pseudonym that preserves the privacy of
cannot guarantee that all
of the sites in its pollutants list will provide the same list,
it must randomize which pollutants it provides. Taken from a
large list of valid sites, a random set of pollutants essentially
acts as a bulky pseudonym that preserves the privacy of
![]() - which of these randomly
provided sites was actually targeted cannot be determined by an
attacker.
- which of these randomly
provided sites was actually targeted cannot be determined by an
attacker.
It is important to note that the translator should not ever translate pages off-site pages; this could cause the translator software to start acting as an open proxy. The external URLs that it is allowed to serve should be a small number to prevent this.
Redirection may not be necessary, depending on the trust
relationships between the external sites and the protected
server, although for optimal privacy either redirection should be
implemented or off-site images and URLs should be removed from
internal pages. Assuming that redirection is implemented,
the translator has to modify off-site URLs to redirect through
itself, except in cases in which two domains collaborate and
agree to pseudonyms set by the other, in which case we may
consider them the same domain, for the purposes considered
herein. This allows the opportunity to put a pseudonym in URLs
that point to off-site data. This is also more work for the
translator and could lead to serving unnecessary pages. Because
of this, it is up to the administrator of the translator (and
probably the owner of the server) to set a policy of what should
be directed through the translator ![]() . We refer to this as an off-site redirection
policy. It is worth noting that many sites with a potential
interest in our proposed measure (such as financial institutions)
may never access external pages unless these belong to partners;
such sites would therefore not require off-site redirection
policies.
. We refer to this as an off-site redirection
policy. It is worth noting that many sites with a potential
interest in our proposed measure (such as financial institutions)
may never access external pages unless these belong to partners;
such sites would therefore not require off-site redirection
policies.
Similarly, a policy must be set to determine what types of
files get translated by ![]() .
The scanned types should be set by an administrator and is called
the data replacement policy.
.
The scanned types should be set by an administrator and is called
the data replacement policy.
The translator notices the pseudonym on the end of the request, so it removes it, verifies that it is valid (e.g., using cookies or HTTP Referer), and then forwards the request to the server. When a response is given by the server, the translator re-translates the page (using the steps mentioned above) using the same pseudonym, which is obtained from the request.
Distinguishing safe from unsafe sites can be difficult
depending on the content and structure of the server's web site.
Redirecting all URLs that are referenced from the domain of
![]() will ensure good privacy,
but this places a larger burden on the translator. Servers that
do not reference offsite URLs from ``sensitive'' portions of
their site could minimize redirections while those that do should
rely on the translator to privatize the clients' URLs.
will ensure good privacy,
but this places a larger burden on the translator. Servers that
do not reference offsite URLs from ``sensitive'' portions of
their site could minimize redirections while those that do should
rely on the translator to privatize the clients' URLs.
Since the types of data served by the back-end server
![]() are controlled by its
administrators (who are in charge of
are controlled by its
administrators (who are in charge of ![]() as well), the data types that are translated can
easily be set. The people in charge of
as well), the data types that are translated can
easily be set. The people in charge of ![]() 's content can ensure that sensitive URLs are only placed
in certain types of files (such as HTML and CSS) - then the
translator only has to process those files.
's content can ensure that sensitive URLs are only placed
in certain types of files (such as HTML and CSS) - then the
translator only has to process those files.
Herein, we argue why our proposed solution satisfies the previously stated security requirements. This analysis is rather straight-forward, and only involves a few cases.
It is worth noting that while clients can easily manipulate the pseudonyms, there is no benefit associated with doing this, and what is more, it may have detrimental effects on the security of the client. Thus, we do not need to worry about such modifications since they are irrational.
We implemented a rough prototype translator to estimate ease
of use as well as determine approximate efficiency and accuracy.
Our translator was written as a Java application that sat between
a client ![]() and protected site
and protected site
![]() . The translator performed
user-agent detection (for identifying robots); pseudonym
generation and assignment; translation (as described in Section
4.2); and redirection of external
(off-site) URLs. We placed the translator on a separate machine
from
. The translator performed
user-agent detection (for identifying robots); pseudonym
generation and assignment; translation (as described in Section
4.2); and redirection of external
(off-site) URLs. We placed the translator on a separate machine
from ![]() in order to get an idea of
the worst-case timing and interaction requirements, although they
were on the same local network. The remote client was set up on
the Internet outside that local network.
in order to get an idea of
the worst-case timing and interaction requirements, although they
were on the same local network. The remote client was set up on
the Internet outside that local network.
In an ideal situation, a web site could be augmented with a translator easily: the software serving the site is changed to serve data on the computer's loopback interface (127.0.0.1) instead of through the external network interface. Second, the translator is installed and listens on the external network interface and forwards to the server on the loopback interface. It seems to the outside world that nothing has changed: the translator now listens closest to the clients at the same address where the server listened before. Additionally, extensions to a web server may make implementing a translator very easy.3
A client sent requests to our prototype and the URL was scanned for an instance of the pseudonym. If the pseudonym was not present, it was generated for the client as described and then stored only until the response from the server was translated and sent back to the client.
Most of the parsing was done in the header of the HTTP requests and responses. We implemented a simple data replacement policy for our prototype: any value for User-Agent that was not ``robot'' or ``wget'' was assumed to be a human client. This allowed us to easily write a script using the command-line wget tool in order to pretend to be a robot. Any content would simply be served in basic proxy mode if the User-Agent was identified as one of these two.
Additionally, if the content type was not text/html, then the associated data in the data stream was simply forwarded back and forth between client and server in a basic proxy fashion. HTML data was intercepted and parsed to replace URLs in common context locations:
|
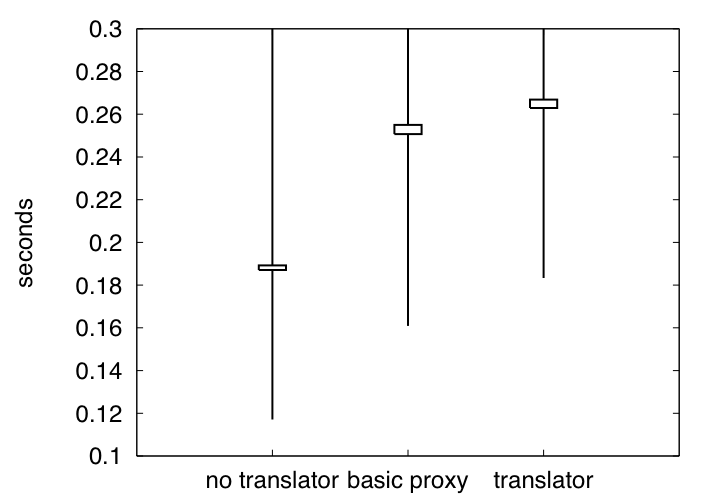
We measured the amount of time it took to completely send the client's request and receive the entire response. This was measured for eight differently sized HTML documents 1000 times each. We set up the client to only load single HTML pages as a conservative estimate - in reality fewer pages will be translated since many requests for images will be sent through the translator. Because of this we can conclude that the actual impact of the translator on a robust web-site will be less significant than our findings.
|
|
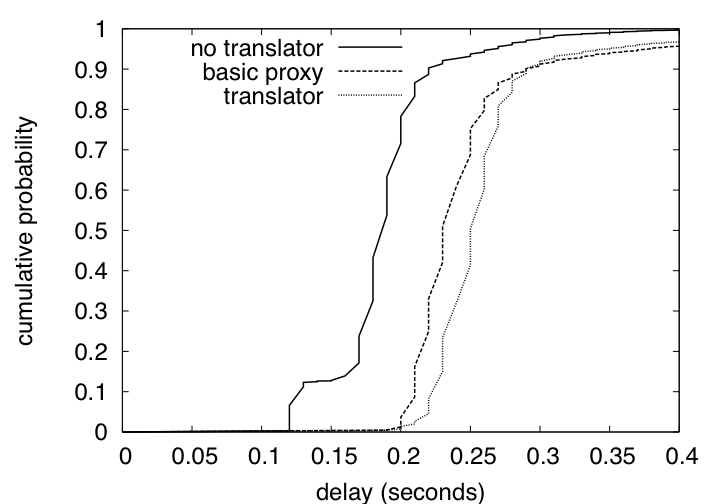
Our data (Figures 4 and 5) shows that the translation of pages does not create noticeable overhead on top of what it takes for the translator to act as a basic proxy. Moreover, acting as a basic proxy creates so little overhead that delays in transmission via the Internet completely shadow any performance hit caused by our translator (Table 1)5. We conclude that the use of a translator in the fashion we describe will not cause a major performance hit on a web site.
Cookies that are set or retrieved by external sites (not the translated server) will not be translated by the translator. This is because the translator in effect only represents its server and not any external sites.
[1] C. Jackson, A. Bortz, D. Boneh, J. C. Mitchell, ``Web Privacy Attacks on a Unified Same-Origin Browser,'' in submission.
[2] E. W. Felten and M. A. Schneider, ``Timing Attacks on Web Privacy,'' In Jajodia, S. and Samarati, P., editors, 7th ACM Conference in Computer and Communication Security 2000, pp. 25-32.
[3]T. Jagatic, N. Johnson, M. Jakobsson, F. Menczer: Social Phishing. 2006
[4] M. Jakobsson, T. Jagatic, S. Stamm, ``Phishing for Clues,'' www.browser-recon.info
[5] M. Jakobsson ``Modeling and Preventing Phishing Attacks.'' Phishing Panel in Financial Cryptography '05. 2005.
[6] B. Grow, ``Spear-Phishers are Sneaking in.'' BusinessWeek, July 11 2005. No. 3942, P. 13
[7] M. Jakobsson and S. Myers, ``Phishing and Counter-Measures : Understanding the Increasing Problem of Electronic Identity Theft.'' Wiley-Interscience (July 7, 2006), ISBN 0-4717-8245-9.