The idea of using hyperlink mining algorithms in Web search
engines appears since the beginning of the success of Google's
PageRank [24].
Hyperlink based methods are based on the assumption that a
hyperlink ![]() implies that page
implies that page ![]() votes for
votes for
![]() as
a quality page. In this paper we address the computational
issues [13,17,11,12] of
personalized PageRank [24] and SimRank [16].
as
a quality page. In this paper we address the computational
issues [13,17,11,12] of
personalized PageRank [24] and SimRank [16].
Personalized PageRank (PPR) [24] enters user preferences by assigning more importance to the neighborhood of pages at the user's selection. Jeh and Widom [16] introduced SimRank, the multi-step link-based similarity function with the recursive idea that two pages are similar if pointed to by similar pages. Notice that both measures are hard to compute over massive graphs: naive personalization would require on the fly power iteration over the entire graph for a user query; naive SimRank computation would require power iteration over all pairs of vertices.
We give algorithms with provable performance guarantees based on computation with sketches [7] as well as simple deterministic summaries; see Table 1 for a comparison of our methods with previous approaches. We may personalize to any single page from which arbitrary page set personalization follows by linearity [13]. Similarly, by our SimRank algorithm we may compute the similarity of any two pages or the similarity top list of any single page. Motivated by search engine applications, we give two-phase algorithms that first compute a compact database from which value or top list queries can be answered with a low number of accesses. Our key results are summarized as follows:
Table 1: Comparison of personalized
PageRank algorithms for graphs of ![]() vertices, additive error
vertices, additive error ![]() and
error probability
and
error probability ![]() .
.
![\begin{table}%[ht!] \begin{tabularx}{\linewidth}{\vert p{2.6cm}\vert X\vert p{1... ...arx}$*$\ optimal for top queries \ $**$\ optimal for value queries \end{table}](fp3041-sarlos-img16.png) |
The scalable computation of personalized PageRank was addressed by several papers [13,18,17] that gradually increase the choice for personalization. By Haveliwala's method [13] we may personalize to the combination of 16 topics extracted from the Open Directory Project. The BlockRank algorithm of Kamvar et al. [18] speeds up personalization to the combination of hosts. The state of the art Hub Decomposition algorithm of Jeh and Widom [17] computed and encoded personalization vectors for approximately 100K personalization pages.
To the best of our knowledge, the only scalable personalized
PageRank algorithm that supports the unrestricted choice of the
teleportation vector is the Monte Carlo method of [11]. This algorithm samples the
personalized PageRank distribution of each page simultaneously
during the precomputation phase, and estimates the personalized
PageRank scores from the samples at query time. The drawback of
the sampling approach is that approximate scores are returned,
where the error of approximation depends on the random choice. In
addition the bounds involve the unknown variance, which can in
theory be as large as ![]() , and hence we need
, and hence we need
![]() random samples. Indeed a matching sampling complexity lower bound
for telling binomial distributions with means
random samples. Indeed a matching sampling complexity lower bound
for telling binomial distributions with means
![]() apart [1] indicates that
one can not reduce the number of samples when approximating
personalized PageRank. Similar findings of the superiority of
summarization or sketching over sampling is described in
[5]. The
algorithms presented in Section 2
outperform the Monte Carlo method by significantly reducing the
error.
apart [1] indicates that
one can not reduce the number of samples when approximating
personalized PageRank. Similar findings of the superiority of
summarization or sketching over sampling is described in
[5]. The
algorithms presented in Section 2
outperform the Monte Carlo method by significantly reducing the
error.
We also address the computational issues of SimRank, a link-based similarity function introduced by Jeh and Widom [16]. The power iteration SimRank algorithm of [16] is not scalable since it iterates on a quadratic number of values, one for each pair of Web pages; in [16] experiments on graphs with no more than 300K vertices are reported. Analogously to personalized PageRank, the scalable computation of SimRank was first achieved by sampling [12]. Our new SimRank approximation algorithms presented in Section 3 improve the precision of computation.
The key idea of our algorithms is that we use lossy representation of large vectors either by rounding or sketching. Sketches are compact randomized data structures that enable approximate computation in low dimension. To be more precise, we adapt the Count-Min Sketch of Cormode and Muthukrishnan [7], which was primarily introduced for data stream computation. We use sketches for small space computation; in the same spirit Palmer et al. [25] apply probabilistic counting sketches to approximate the sizes of neighborhoods of vertices in large graphs. Further sketching techniques for data streams are surveyed in [23]. Lastly we mention that Count-Min Sketch and the historically first sketch, the Bloom filter [2] stem from the same idea; we refer to the detailed survey [4] for further variations and applications.
Surprisingly, it turns out that sketches do not help if the
top ![]() highest ranked or most similar nodes are queried; the
deterministic version of our algorithms show the same performance
as the randomized without even allowing a small probability of
returning a value beyond the error bound. Here the novelty is the
optimal performance of the deterministic method; the top
highest ranked or most similar nodes are queried; the
deterministic version of our algorithms show the same performance
as the randomized without even allowing a small probability of
returning a value beyond the error bound. Here the novelty is the
optimal performance of the deterministic method; the top
![]() problem is known to cause difficulties in sketch-based methods
and always increases sketch sizes by a factor of
problem is known to cause difficulties in sketch-based methods
and always increases sketch sizes by a factor of
![]() . By using
. By using
![]() times larger space we may use a
binary search structure or we may use
times larger space we may use a
binary search structure or we may use ![]() sketches accessed
sketches accessed
![]() times per query [7]. Note that
times per query [7]. Note that ![]() queries
require an error probability of
queries
require an error probability of
![]() that again increase sketch sizes by
a factor of
that again increase sketch sizes by
a factor of
![]() .
.
In Section 4 we show that our algorithms build optimal sized databases. To obtain lower bounds on the database size, we apply communication complexity techniques that are commonly used for space lower bounds [21]. Our reductions are somewhat analogous to those applied by Henzinger et al. [14] for space lower bounds on stream graph computation.
We briefly introduce notation, and recall definitions and basic facts about PageRank, SimRank and the Count-Min sketch.
Let us consider the web as a graph. Let ![]() denote the number
of vertices and
denote the number
of vertices and ![]() the number edges. Let
the number edges. Let ![]() and
and
![]() denote the number of edges leaving and
entering
denote the number of edges leaving and
entering ![]() , respectively. Details of handling nodes with
, respectively. Details of handling nodes with
![]() and
and
![]() are omitted.
are omitted.
In [24] the
PageRank vector ![]() , ...,
, ...,
![]() is defined as the solution of the following equation
is defined as the solution of the following equation
![]() ,
where
,
where
![]() , ...,
, ..., ![]() is the
teleportation vector and
is the
teleportation vector and ![]() is the
teleportation probability with a typical value of
is the
teleportation probability with a typical value of
![]() . If
. If ![]() is uniform, i.e.
is uniform, i.e.
![]() for all
for all ![]() , then
, then ![]() is the PageRank.
For non-uniform
is the PageRank.
For non-uniform ![]() the solution
the solution ![]() is called
personalized PageRank; we denote it
by
PPR
is called
personalized PageRank; we denote it
by
PPR![]() .
Since
PPR
.
Since
PPR![]() is
linear in
is
linear in ![]() [13,17], it can be computed
by linear combination of personalization to single points
[13,17], it can be computed
by linear combination of personalization to single points
![]() ,
i.e. to vectors
,
i.e. to vectors
![]() consisting of all 0 except for node
consisting of all 0 except for node
![]() where
where
![]() . Let
PPR
. Let
PPR![]() PPR
PPR![]() .
.
An alternative characterization of
PPR![]() [10,17] is based on the
probability that a length
[10,17] is based on the
probability that a length ![]() random walk
starting at node
random walk
starting at node ![]() ends in node
ends in node ![]() . We obtain
PPR
. We obtain
PPR![]() by choosing
by choosing ![]() random according to the geometric
distribution:
random according to the geometric
distribution:
Jeh and Widom [16] define SimRank by the
following equation very similar to the PageRank power iteration
such that
Sim![]() and
and
The Count-Min Sketch [7] is a compact randomized
approximate representation of non-negative vector ![]() , ...,
, ...,
![]() such that a single value
such that a single value ![]() can be queried
with a fixed additive error
can be queried
with a fixed additive error
![]() and a probability
and a probability ![]() of
returning a value out of this bound. The representation is a
table of depth
of
returning a value out of this bound. The representation is a
table of depth
![]() and width
and width
![]() . One row
. One row ![]() of the table is
computed with a random hash function
of the table is
computed with a random hash function
![]() . The
. The
![]() th entry of the row
th entry of the row ![]() is defined as
is defined as
![]() . Then the Count-Min
sketch table of
. Then the Count-Min
sketch table of ![]() consists of
consists of ![]() such rows with
hash functions chosen uniformly at random from a
pairwise-independent family.
such rows with
hash functions chosen uniformly at random from a
pairwise-independent family.
Count-Min sketches are based on the principle that any
randomized approximate computation with one sided error and bias
![]() can be turned into an algorithm that has
guaranteed error at most
can be turned into an algorithm that has
guaranteed error at most
![]() with probability
with probability ![]() by running
by running
![]() parallel copies and taking the
minimum. The proof simply follows from Markov's inequality and is
described for the special cases of sketch value and inner product
in the proofs of Theorems 1 and 2 of [7], respectively.
parallel copies and taking the
minimum. The proof simply follows from Markov's inequality and is
described for the special cases of sketch value and inner product
in the proofs of Theorems 1 and 2 of [7], respectively.
We give two efficient realizations of the dynamic programming
algorithm of Jeh and Widom [17]. Our algorithms are
based on the idea that if we use an approximation for the partial
values in certain iteration, the error will not aggregate when
summing over out-edges, instead the error of previous iterations
will decay with the power of ![]() . Our first
algorithm in Section 2.1 uses
certain deterministic rounding optimized for smallest runtime for
a given error, while our second algorithm in Section 2.2 is based on Count-Min sketches
[7].
. Our first
algorithm in Section 2.1 uses
certain deterministic rounding optimized for smallest runtime for
a given error, while our second algorithm in Section 2.2 is based on Count-Min sketches
[7].
The original implementation of dynamic programming [17] relies on the
observation that in the first ![]() iterations of
dynamic programming only vertices within distance
iterations of
dynamic programming only vertices within distance ![]() have non-zero
value. However, the rapid expansion of the
have non-zero
value. However, the rapid expansion of the ![]() -neighborhoods
increases disk requirement close to
-neighborhoods
increases disk requirement close to ![]() after a few
iterations, which limits the usability of this approach2. Furthermore, an external memory
implementation would require significant additional disk
space.
after a few
iterations, which limits the usability of this approach2. Furthermore, an external memory
implementation would require significant additional disk
space.
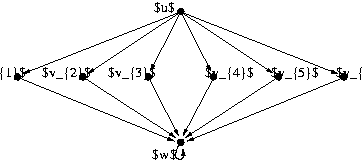
Figure 1: A simple example showing the superiority of dynamic programming over power iterations for small space computations.
We may justify why dynamic programming is the right choice for
small-space computation by comparing dynamic programming to power
iteration over the graph of Fig. 1.
When computing
PPR![]() , power iteration moves top-down, starting
at
, power iteration moves top-down, starting
at ![]() ,
stepping into its neighbors
,
stepping into its neighbors
![]() and finally adding up all their
values at
and finally adding up all their
values at ![]() . Hence when approximating, we accumulate all
error when entering the large in-degree node
. Hence when approximating, we accumulate all
error when entering the large in-degree node ![]() and in particular
we must compute
PPR
and in particular
we must compute
PPR![]() values fairly exact. Dynamic programming,
in contrast, moves bottom up by computing the trivial
PPR
values fairly exact. Dynamic programming,
in contrast, moves bottom up by computing the trivial
PPR![]() vector, then all the
PPR
vector, then all the
PPR![]() , then finally averages all of them into
PPR
, then finally averages all of them into
PPR![]() .
Because of averaging we do not amplify error at large in-degrees;
even better by looking at (4) we notice
that the effect of earlier steps diminishes exponentially in
.
Because of averaging we do not amplify error at large in-degrees;
even better by looking at (4) we notice
that the effect of earlier steps diminishes exponentially in
![]() . In particular even if there are edges
entering
. In particular even if there are edges
entering ![]() from further nodes, we may safely discard all
the small
PPR
from further nodes, we may safely discard all
the small
PPR![]() values for further computations, thus
saving space over power iteration where we require the majority
of these values in order to compute
PPR
values for further computations, thus
saving space over power iteration where we require the majority
of these values in order to compute
PPR![]() with little error.
with little error.
We measure the performance of our algorithms in the sense of
intermediate disk space usage. Notice that our algorithms are
two-phase in that they preprocess the
graph to a compact database from which value and top list queries
can be served real-time; preprocessing space and time is hence
crucial for a search engine application. Surprisingly, in this
sense rounding in itself yields an optimal algorithm for top list
queries as shown by giving a matching lower bound in Section
4. The sketching algorithm further
improves space usage by a factor of ![]() and is hence
optimal for single value queries. For finding top lists, however,
we need additional techniques such as binary searching as in
[7] that loose the
and is hence
optimal for single value queries. For finding top lists, however,
we need additional techniques such as binary searching as in
[7] that loose the
![]() factor gain and use asymptotically the same
amount of space as the deterministic algorithm. Since the
deterministic rounding involves no probability of giving an
incorrect answer, that algorithm is superior for top list
queries.
factor gain and use asymptotically the same
amount of space as the deterministic algorithm. Since the
deterministic rounding involves no probability of giving an
incorrect answer, that algorithm is superior for top list
queries.
The key to the efficiency of our algorithms is the use of
small size approximate
![]() values obtained
either by rounding and handling sparse vectors or by computing
over sketches. In order to perform the update step of Algorithm
1 we must access all
values obtained
either by rounding and handling sparse vectors or by computing
over sketches. In order to perform the update step of Algorithm
1 we must access all
![]() vectors; the algorithm
proceeds as if we were multiplying the weighted adjacency matrix
vectors; the algorithm
proceeds as if we were multiplying the weighted adjacency matrix
![]() for
for
![]() with the vector
with the vector
![]() parallel
for all values of
parallel
for all values of ![]() . We may use (semi)external memory algorithms
[27]; efficiency
will depend on the size of the description of the vectors.
. We may use (semi)external memory algorithms
[27]; efficiency
will depend on the size of the description of the vectors.
The original algorithm of Jeh and Widom defined by equation (4) uses two vectors in the implementation. We remark that a single vector suffices since by using updated values within an iteration we only speed convergence up. A similar argument is given by McSherry [22] for the power iteration, however there the resulting sequential update procedure still requires two vectors.
In Algorithm 1 we compute the steps
of the dynamic programming personalized PageRank algorithm
(4) by rounding all values down to a
multiple of the prescribed error value ![]() . As the sum
of
PPR
. As the sum
of
PPR![]() for all
for all ![]() equals one, the rounded non-zeroes can be stored
in small space since there may be at most
equals one, the rounded non-zeroes can be stored
in small space since there may be at most
![]() of them.
of them.
We improve on the trivial observation that there are at most
![]() rounded non-zero values in two ways as
described in the next two theorems. First, we observe that the
effect of early iterations decays as the power of
rounded non-zero values in two ways as
described in the next two theorems. First, we observe that the
effect of early iterations decays as the power of ![]() in the
iterations, allowing us to similarly increase the approximation
error
in the
iterations, allowing us to similarly increase the approximation
error
![]() for early iterations
for early iterations ![]() . We prove
correctness in Theorem 2; later in
Theorem 4 it turns out that this
choice also weakens the dependency of the running time on the
number of iterations. Second, we show that the size of the
non-zeroes can be efficiently bit-encoded in small space; while
this observation is less relevant for a practical implementation,
this is key in giving an algorithm that matches the lower bound
of Section 4.
. We prove
correctness in Theorem 2; later in
Theorem 4 it turns out that this
choice also weakens the dependency of the running time on the
number of iterations. Second, we show that the size of the
non-zeroes can be efficiently bit-encoded in small space; while
this observation is less relevant for a practical implementation,
this is key in giving an algorithm that matches the lower bound
of Section 4.
Since we use a single vector in the implementation, we may
update a value by values that have themselves already been
updated in iteration ![]() . Nevertheless since
. Nevertheless since
![]() and
hence decreases in
and
hence decreases in ![]() , values that have earlier been updated in
the current iteration in fact incur an error smaller than
required on the right hand side of the update step of Algorithm
1. In order to distinguish values
before and after a single step of the update, let us use
, values that have earlier been updated in
the current iteration in fact incur an error smaller than
required on the right hand side of the update step of Algorithm
1. In order to distinguish values
before and after a single step of the update, let us use
![]() to denote values on the
right hand side. To prove, notice that by the Decomposition
Theorem (3)
to denote values on the
right hand side. To prove, notice that by the Decomposition
Theorem (3)
PPR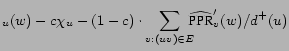 |
|||
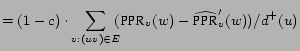 |
 |
Next we show that multiples of ![]() that sum up
to 1 can be stored in
that sum up
to 1 can be stored in
![]() bit space. For the exact result we need
to select careful but simple encoding methods given in the
trivial lemma below.
bit space. For the exact result we need
to select careful but simple encoding methods given in the
trivial lemma below.
Next we give a sketch version of Algorithm 1 that improves the space requirement of the
rounding based version by a factor of ![]() , thus
matches the lower bound of Section 4
for value queries. First we give a basic algorithm that uses
uniform error bound
, thus
matches the lower bound of Section 4
for value queries. First we give a basic algorithm that uses
uniform error bound ![]() in all iterations and is not optimized
for storage size in bits. Then we show how to gradually decrease
approximation error to speed up earlier iterations with less
effect on final error; finally we obtain the space optimal
algorithm by the bit encoding of Lemma 3.
in all iterations and is not optimized
for storage size in bits. Then we show how to gradually decrease
approximation error to speed up earlier iterations with less
effect on final error; finally we obtain the space optimal
algorithm by the bit encoding of Lemma 3.
The key idea is that we replace each
PPR![]() vector with its constant size Count-Min
sketch in the dynamic programming iteration (4). Let
vector with its constant size Count-Min
sketch in the dynamic programming iteration (4). Let ![]() denote the sketching operator that replaces
a vector by the
denote the sketching operator that replaces
a vector by the
![]() table as in Section 1.2 and let us perform the iterations of
(4) with
SPPR
table as in Section 1.2 and let us perform the iterations of
(4) with
SPPR![]() and
and
![]() . Since the sketching operator is
trivially linear, in iteration
. Since the sketching operator is
trivially linear, in iteration ![]() we obtain the
sketch of the next temporary vector
SPPR
we obtain the
sketch of the next temporary vector
SPPR![]() from the sketches
SPPR
from the sketches
SPPR![]() .
.
To illustrate the main ingredients, we give the simplest form
of a sketch-based algorithm with error, space and time analysis.
Let us perform the iterations of (4) with
![]() wide and
wide and
![]() deep sketches
deep sketches
![]() times; then by
Theorem 1 and the linearity of
sketching we can estimate
PPR
times; then by
Theorem 1 and the linearity of
sketching we can estimate
PPR![]() for all
for all ![]() from
SPPR
from
SPPR![]() with additive error
with additive error
![]() and error probability
and error probability ![]() . The
personalized PageRank database consists of sketch tables
SPPR
. The
personalized PageRank database consists of sketch tables
SPPR![]() for all
for all ![]() . The data occupies
. The data occupies
![]() machine
words, since we have to store
machine
words, since we have to store ![]() tables of reals. An
update for node
tables of reals. An
update for node ![]() takes
takes
![]() time
by averaging
time
by averaging ![]() tables of
tables of
![]() size and
adding
size and
adding
![]() , each in
, each in
![]() time. Altogether the required
time. Altogether the required
![]() iterations run in
iterations run in
![]() time.
time.
Next we weaken the dependence of the running time on the
number of iterations by gradually decreasing error
![]() as in Section 2.1. When decreasing the error in sketches,
we face the problem of increasing hash table sizes as the
iterations proceed. Since there is no way to efficiently rehash
data into larger tables, we approximate personalized PageRank
slightly differently by representing the end distribution of
length
as in Section 2.1. When decreasing the error in sketches,
we face the problem of increasing hash table sizes as the
iterations proceed. Since there is no way to efficiently rehash
data into larger tables, we approximate personalized PageRank
slightly differently by representing the end distribution of
length ![]() walks,
PPR
walks,
PPR![]() , with their rounded sketches
, with their rounded sketches
![]() in the path-summing
formula (2):
in the path-summing
formula (2):
We err for three reasons: we do not run the iteration
infinitely; in iteration ![]() we round values
down by at most
we round values
down by at most
![]() , causing a deterministic
negative error; and finally the Count-Min Sketch uses hashing,
causing a random positive error. For bounding these errors,
imagine running iteration (7)
without the rounding function
, causing a deterministic
negative error; and finally the Count-Min Sketch uses hashing,
causing a random positive error. For bounding these errors,
imagine running iteration (7)
without the rounding function ![]() but still
with
but still
with
![]() wide and
wide and
![]() deep sketches and denote its
results by
SPPR
deep sketches and denote its
results by
SPPR![]() and define
and define
![$\displaystyle \widetilde{\mbox{PPR}}_u(v)=\min_{i=1\ldots\ln{1\over\delta}} \Big(\sum_{k=0}^{k_{\max}}c(1-c)^{k}\mbox{SPPR}^{[k]}_u(i,h^i_k(v))\Big).$](/www2006/fp3041-sarlos-img184.png) |
Finally we lower bound
![]() ; the bound is
deterministic. The
; the bound is
deterministic. The
![]() loss due to rounding down in
iteration
loss due to rounding down in
iteration ![]() affects all subsequent iterations, and
hence
affects all subsequent iterations, and
hence
 |
In this section first we give a simpler algorithm for serving SimRank value and top-list queries that combines rounding with the empirical fact that there are relatively few large values in the similarity matrix. Then in Section 3.1 we give an algorithm for SimRank values that uses optimal storage in the sense of the lower bounds of Section 4. Of independent interest is the main component of the algorithm that reduces SimRank to the computation of values similar to personalized PageRank.
SimRank and personalized PageRank are similar in that they
both fill an ![]() matrix when the exact values are
computed. Another similarity is that practical queries may ask
for the maximal elements within a row. Unlike personalized
PageRank however, when rows can be easily sketched and
iteratively computed over approximate values, the
matrix when the exact values are
computed. Another similarity is that practical queries may ask
for the maximal elements within a row. Unlike personalized
PageRank however, when rows can be easily sketched and
iteratively computed over approximate values, the ![]() matrix
structure is lost within the iterations for
Sim
matrix
structure is lost within the iterations for
Sim![]() as we may have to access values of
arbitrary
Sim
as we may have to access values of
arbitrary
Sim![]() . Even worse
. Even worse
![]() PPR
PPR![]() while
while
In practice ![]() is expected be a reasonable constant times
is expected be a reasonable constant times
![]() .
Hence first we present a simple direct algorithm that finds the
largest values within the entire
Sim
.
Hence first we present a simple direct algorithm that finds the
largest values within the entire
Sim![]() table. In order to give a rounded
implementation of the iterative SimRank equation (5), we need to give an efficient algorithm to
compute a single iteration. The naive implementation requires
table. In order to give a rounded
implementation of the iterative SimRank equation (5), we need to give an efficient algorithm to
compute a single iteration. The naive implementation requires
![]() time for each edge pair with a common
source vertex that may add up to
time for each edge pair with a common
source vertex that may add up to
![]() . Instead for
. Instead for
![]() we will compute the next iteration
with the help of an intermediate step when edges out of only one
of the two vertices are considered:
we will compute the next iteration
with the help of an intermediate step when edges out of only one
of the two vertices are considered:
Along the same line as the proof of Theorems 2 we prove that (i) by rounding values in
iterations (8-9) we approximate values with small additive
error; (ii) the output of the algorithm occupies small space; and
(iii) approximate top lists can be efficiently answered from the
output. The proof is omitted due to space limitations. We remark
here that (8-9) can be implemented by 4 external memory
sorts per iteration, in two of which the internal space usage can
in theory grow arbitrary large even compared to ![]() . This is due to
the fact that we may round only once after each iteration; hence
if for some large out-degree node
. This is due to
the fact that we may round only once after each iteration; hence
if for some large out-degree node ![]() a value
Sim
a value
Sim![]() is above the rounding threshold
or
ASim
is above the rounding threshold
or
ASim![]() becomes positive, then we have to
temporarily store positive values for all out-neighbors, most of
which will be discarded when rounding.
becomes positive, then we have to
temporarily store positive values for all out-neighbors, most of
which will be discarded when rounding.
Now we describe a SimRank algorithm that uses a database of
size matching the corresponding lower bound of Section 4 by taking advantage of the fact that large
values of similarity appear in blocks of the ![]() similarity table. The blocking nature can be captured by
observing the similarity of
Sim
similarity table. The blocking nature can be captured by
observing the similarity of
Sim![]() to the product
PPR
to the product
PPR![]() PPR
PPR![]() of vectors
PPR
of vectors
PPR![]() and
PPR
and
PPR![]() .
.
We use the independent result of [10,17,16] that PageRank type values can be expressed by summing over endpoints of walks as in equation (1). First we express SimRank by walk pair sums, then we show how SimRank can be reduced to personalized PageRank by considering pairs of walks as products. Finally we give sketching and rounding algorithms for value and top queries based on this reduction.
In order to capture pairs of walks of equal length we define
``reversed'' PPR by using walks of length exactly ![]() by modifying
(1):
by modifying
(1):
Next we formalize the relation and give an efficient algorithm that reduces SimRank to PPR on the reversed graph. As a ``step 0 try'' we consider
In order to exclude pairs of walks that meet before ending, we
use the principle of inclusion and exclusion. We count pairs of
walks that have at least ![]() meeting points
after start as follows. Since after their first meeting point
meeting points
after start as follows. Since after their first meeting point
![]() the
walks proceed as if computing the similarity of
the
walks proceed as if computing the similarity of ![]() to itself, we
introduce a self-similarity measure by counting weighted pairs of
walks that start at
to itself, we
introduce a self-similarity measure by counting weighted pairs of
walks that start at ![]() and terminate at the same vertex
and terminate at the same vertex ![]() by extending
(12):
by extending
(12):
| SSim |
(13) |
The proof of the main theorems below are omitted due to space
limitations.
In this section we
will prove lower bounds on the database size of approximate PPR
algorithms that achieve personalization over a subset of
![]() vertices. More precisely we will consider two-phase algorithms: in the first phase the
algorithm has access to the edge set of the graph and has to
compute a database; in the second phase the algorithm gets a
query and has to answer by accessing the database, i.e. the
algorithm cannot access the graph during query-time. A
vertices. More precisely we will consider two-phase algorithms: in the first phase the
algorithm has access to the edge set of the graph and has to
compute a database; in the second phase the algorithm gets a
query and has to answer by accessing the database, i.e. the
algorithm cannot access the graph during query-time. A
![]() worst case lower bound on the
database size holds, if for any two-phase algorithm there exists
a personalization input such that a database of size
worst case lower bound on the
database size holds, if for any two-phase algorithm there exists
a personalization input such that a database of size ![]() bits is built
in the first phase.
bits is built
in the first phase.
We will consider the following queries for
![]() :
:
|
|
|||
|
|
As Theorem 6 of [11]
shows, any two-phase PPR algorithm solving the exact (
![]() ) PPR value problem requires an
) PPR value problem requires an
![]() bit
database. Our tool towards the lower bounds will be the
asymmetric communication complexity game bit-vector probing [14]: there are two
players
bit
database. Our tool towards the lower bounds will be the
asymmetric communication complexity game bit-vector probing [14]: there are two
players ![]() and
and ![]() ; player
; player ![]() has a vector
has a vector
![]() of
of
![]() bits; player
bits; player ![]() has a number
has a number
![]() ; and they have to compute
the function
; and they have to compute
the function
![]() , i.e., the output is the
, i.e., the output is the ![]() th bit
of the input vector
th bit
of the input vector ![]() . To compute the proper output they have to
communicate, and communication is restricted in the direction
. To compute the proper output they have to
communicate, and communication is restricted in the direction
![]() . The one-way
communication complexity [21] of this function
is the number of transferred bits in the worst case by the best
protocol.
. The one-way
communication complexity [21] of this function
is the number of transferred bits in the worst case by the best
protocol.
Now we are ready to state and prove our lower bounds, which match the performance of the algorithms presented in Sections 2 and 3.1, hence showing that they are space optimal.
Given a vector ![]() of
of
![]() bits,
bits, ![]() constructs the ``bipartite'' graph with vertex
set
constructs the ``bipartite'' graph with vertex
set
![]() For the edge set,
For the edge set, ![]() is partitioned into
is partitioned into
![]() blocks, where each block
blocks, where each block ![]() contains
contains
![]() bits for
bits for
![]() ,
,
![]() . Notice that
each
. Notice that
each ![]() can be regarded as a binary encoded
number with
can be regarded as a binary encoded
number with
![]() . To encode
. To encode
![]() into the graph,
into the graph, ![]() adds an edge
adds an edge
![]() iff
iff ![]() ,
and also attaches a self-loop to each
,
and also attaches a self-loop to each ![]() . Thus
the
. Thus
the
![]() edges outgoing from
edges outgoing from
![]() represent the blocks
represent the blocks
![]() .
.
After constructing the graph ![]() computes an
computes an
![]() -
-![]() approximation PPR database with personalization available on
approximation PPR database with personalization available on
![]() , and sends the
database to
, and sends the
database to ![]() , who computes the
, who computes the ![]() th bit
th bit ![]() as
follows. Since
as
follows. Since ![]() knows which of the blocks contains
knows which of the blocks contains
![]() it is enough to compute
it is enough to compute ![]() for
suitably chosen
for
suitably chosen ![]() . The key property of the graph construction
is that
. The key property of the graph construction
is that
![]() iff
iff ![]() otherwise
otherwise
![]() . Thus
. Thus
![]() computes
computes
![]() for
for
![]() by the second
phase of the
by the second
phase of the ![]() -
-![]() approximation algorithm. If all
approximation algorithm. If all
![]() are computed with
are computed with
![]() ,
then
,
then ![]() containing
containing ![]() will be
calculated correctly. By the union bound the probability of
miscalculating any of
will be
calculated correctly. By the union bound the probability of
miscalculating any of
![]() is at most
is at most
![]() .
.
![]()
Let
![]() and
and
![]() and the
graph have nodes
and the
graph have nodes
![]() (with
(with ![]() ). By the assumptions on the
vertex count,
). By the assumptions on the
vertex count,
![]() and
and
![]() .
.
Let the size of the bit-vector probing problem's input be
![]() . Assign
each of the
. Assign
each of the
![]() sized blocks to a vertex
sized blocks to a vertex
![]() and fix a code which encodes these bits into
and fix a code which encodes these bits into
![]() -sized subsets of the vertices
-sized subsets of the vertices ![]() . This
is possible, as the number of subsets is
. This
is possible, as the number of subsets is
![]() .
These mappings are known to both parties
.
These mappings are known to both parties ![]() and
and
![]() .
Note that due to the constraints on
.
Note that due to the constraints on ![]() and
and ![]() we have
we have
![]() .
.
Given an input bit-vector of ![]() , for each
vertex
, for each
vertex ![]() take its block of bits and compute the
corresponding subset of vertices
take its block of bits and compute the
corresponding subset of vertices ![]() according
to the fixed code. Let
according
to the fixed code. Let ![]() have an arc
into these vertices. Let all vertices
have an arc
into these vertices. Let all vertices ![]() have a
self-loop. Now
have a
self-loop. Now ![]() runs the first phase of the PPR algorithm and
transfers the resulting database to
runs the first phase of the PPR algorithm and
transfers the resulting database to ![]() .
.
Given a bit index ![]() , player
, player ![]() determines its
block, and issues a top query on the representative vertex,
determines its
block, and issues a top query on the representative vertex,
![]() . As each of the out-neighbors
. As each of the out-neighbors ![]() of
of
![]() has
has
![]() ,
and all other nodes
,
and all other nodes ![]() have
have
![]() , the
resulting set will be the set of out-neighbors of
, the
resulting set will be the set of out-neighbors of ![]() , with
probability
, with
probability ![]() . Applying the inverse of the subset
encoding, we get the bits of the original input vector, thus
the correct answer to the bit-vector probing problem. Setting
. Applying the inverse of the subset
encoding, we get the bits of the original input vector, thus
the correct answer to the bit-vector probing problem. Setting
![]() we get that the number
of bits transmitted, thus the size of the database was at least
we get that the number
of bits transmitted, thus the size of the database was at least
![]() .
.
![]()
We remark that using the graph construction in the full
version of [12] it is
straightforward to modify Theorems 10 and 11
to obtain the same space lower bounds for SimRank as well.
Moreover, it is easy to see that Theorem 11 holds for the analogous problem of
approximately reporting the top ![]() number
vertices with the highest PageRank or SimRank scores
respectively.
number
vertices with the highest PageRank or SimRank scores
respectively.
With the graph construction of Theorem 10 at hand, it is possible to bypass the bit-vector probing problem and reduce the approximate personalized PageRank value query to similar lower bounds for the Bloom filter [4] or to a weaker form for the Count-Min sketch [8]. However, to the best of our knowledge, we are unaware of previous results similar to Theorem 11 for the top query.
This section presents our personalized PageRank experiments on 80M pages of the 2001 Stanford WebBase crawl [15]. The following questions are addressed by our experiments:
We compare our approximate PPR scores to exact PPR scores
computed by the personalized PageRank algorithm of Jeh and Widom
[17] with a
precision of ![]() in
in ![]() norm. In the
experiments we set teleportation constant
norm. In the
experiments we set teleportation constant ![]() to its usual value
to its usual value
![]() , and personalize on a single page
, and personalize on a single page
![]() chosen uniformly at random from all vertices. The experiments
were carried out with 1000 independently chosen personalization
node
chosen uniformly at random from all vertices. The experiments
were carried out with 1000 independently chosen personalization
node ![]() , and the results were averaged.
, and the results were averaged.
To compare the exact and approximate PPR scores personalized
to page ![]() , we measure the difference between top score
lists of exact
, we measure the difference between top score
lists of exact
![]() and approximate
and approximate
![]() vectors. The
length
vectors. The
length ![]() of the compared top lists is in the range 5 to
1000, which is the usual maximum length of the results returned
by search engines.
of the compared top lists is in the range 5 to
1000, which is the usual maximum length of the results returned
by search engines.
The comparison of top lists is key in measuring the goodness
of a ranking method [9, and the
references therein] or the distortion of a PageRank encoding
[13].
Let
![]() denote the set of pages having
the
denote the set of pages having
the ![]() highest personalized PageRank values in the vector
PPR
highest personalized PageRank values in the vector
PPR![]() personalized to a single page
personalized to a single page ![]() . We approximate
this set by
. We approximate
this set by
![]() , the set of pages
having the
, the set of pages
having the ![]() highest approximated scores in vector
highest approximated scores in vector
![]() . We will apply
the following three measures to compare the exact and approximate
rankings of
. We will apply
the following three measures to compare the exact and approximate
rankings of
![]() and
and
![]() . The first two
measures will determine the overall quality of the approximated
top-
. The first two
measures will determine the overall quality of the approximated
top-![]() set
set
![]() , as they will be
insensitive to the ranking of the elements within
, as they will be
insensitive to the ranking of the elements within
![]() .
.
Relative aggregated goodness
[26]
measures how well the approximate top-![]() set performs in
finding a set of pages with high total personalized PageRank. It
calculates the sum of exact PPR values in the approximate set
compared to the maximum value achievable (by using the exact
top-
set performs in
finding a set of pages with high total personalized PageRank. It
calculates the sum of exact PPR values in the approximate set
compared to the maximum value achievable (by using the exact
top-![]() set
set
![]() ):
):
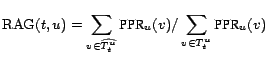
We also measure the precision of
returning the top-![]() set (note that as the sizes of the sets are
fixed, precision coincides with recall). If all exact PPR scores were different
we could simply define precision as
set (note that as the sizes of the sets are
fixed, precision coincides with recall). If all exact PPR scores were different
we could simply define precision as
![]() .
Treating nodes with equal exact PPR scores in a more liberal way
we define precision as
.
Treating nodes with equal exact PPR scores in a more liberal way
we define precision as
The third measure, Kendall's ![]() compares the exact ranking with the approximate ranking in the
top-
compares the exact ranking with the approximate ranking in the
top-![]() set.
Note that the exact PPR list of nodes with a small neighborhood
or the tail of approximate PPR ranking may contain a large number
of ties (nodes with equal scores) that may have a significant
effect on rank comparison. Versions of Kendall's
set.
Note that the exact PPR list of nodes with a small neighborhood
or the tail of approximate PPR ranking may contain a large number
of ties (nodes with equal scores) that may have a significant
effect on rank comparison. Versions of Kendall's ![]() with different
tie breaking rules appear in the literature, we use the original
definition as e.g. in [19]. Ignoring ties for the
ease of presentation, the rank correlation Kendall's
with different
tie breaking rules appear in the literature, we use the original
definition as e.g. in [19]. Ignoring ties for the
ease of presentation, the rank correlation Kendall's ![]() compares the
number of pairs ordered the same way in both rankings to the
number of reversed pairs; its range is
compares the
number of pairs ordered the same way in both rankings to the
number of reversed pairs; its range is ![]() , where
, where
![]() expresses complete disagreement,
expresses complete disagreement, ![]() represents a
perfect agreement. To restrict the computation to the top
represents a
perfect agreement. To restrict the computation to the top
![]() elements, we took the union of the exact and approximated
top-
elements, we took the union of the exact and approximated
top-![]() sets
sets
![]() .
For each ordering, all nodes that were outside the orderings'
top-
.
For each ordering, all nodes that were outside the orderings'
top-![]() set
were considered to be tied and ranked strictly smaller than any
node contained in its top-
set
were considered to be tied and ranked strictly smaller than any
node contained in its top-![]() set.
set.
One of our baselines in our experiments is a heuristically modified power iteration algorithm. While the example of Figure 1 shows that we may get large error even by discarding very small intermediate values, a heuristic that delays the expansion of nodes with small current PageRank values [17,22,6] still achieves good results on real world data.
When personalizing to node ![]() , let us start from
, let us start from
![]() and keep a dedicated list of the non-zero
entries, which we expand breadth first. This allows us to perform
one iteration quickly as long as these lists are not too long; we
cease the expansion if we have reached the value
and keep a dedicated list of the non-zero
entries, which we expand breadth first. This allows us to perform
one iteration quickly as long as these lists are not too long; we
cease the expansion if we have reached the value ![]() . Moreover we skip
the expansion originating from a node if its current PageRank
divided by the outdegree is below a given threshold
. Moreover we skip
the expansion originating from a node if its current PageRank
divided by the outdegree is below a given threshold ![]() . Finally we never
let the number of iteration exceed the predetermined value
. Finally we never
let the number of iteration exceed the predetermined value
![]() .
We experimented with a variant of McSherry's state of the art
update iteration [22], as well as a scheme
to reuse the previous node's result, but neither of them produced better
approximation within the same running time, hence we do not
report these results.
.
We experimented with a variant of McSherry's state of the art
update iteration [22], as well as a scheme
to reuse the previous node's result, but neither of them produced better
approximation within the same running time, hence we do not
report these results.
We conducted our experiments on a single AMD Opteron 2.0 GHz
machine with 4 GB of RAM under Linux OS. We used a semi-external
memory implementation for rounded dynamic programming,
partitioning the intermediate
![]() vectors along the
coordinate
vectors along the
coordinate ![]() . Using a single vector allowed us to halve the
memory requirements by storing the intermediate results in a FIFO
like large array, moving the
. Using a single vector allowed us to halve the
memory requirements by storing the intermediate results in a FIFO
like large array, moving the
![]() being updated from
the head of the queue to its tail. We stored the PageRank values
as multiples of the rounding error
being updated from
the head of the queue to its tail. We stored the PageRank values
as multiples of the rounding error ![]() using a
simple but fast variable length byte-level encoding. We did not
partition the vector
using a
simple but fast variable length byte-level encoding. We did not
partition the vector
![]() into predefined
subsets of
into predefined
subsets of ![]() ; instead as the algorithm ran out of memory, it
split the current set of
; instead as the algorithm ran out of memory, it
split the current set of ![]() and checkpointed
one half to disk. Once the calculation in the first half was
finished, it resumed in the second half, resulting in a Depth
First Search like traversal of subsets of
and checkpointed
one half to disk. Once the calculation in the first half was
finished, it resumed in the second half, resulting in a Depth
First Search like traversal of subsets of ![]() . Since dynamic
programming accesses the edges of the graph sequentially, we
could overlay the preloading of the next batch of edges with the
calculations in the current batch using either asynchronous I/O
or a preloader thread. This way we got the graph I/O almost for
free. It is conceivable that reiterations [22] or the compression of
vertex identifiers [3] could
further speed up the computation. For implementations on a larger
scale one may use external memory sorting with the two vector
dynamic programming variant. Or, in a distributed environment, we
may partition the graph vertices among the cluster nodes, run a
semi-external memory implementation on each node and exchange the
intermediate results over the network as required. To minimize
network load, a partition that respects the locality of links
(e.g. hostname based) is advisable.
. Since dynamic
programming accesses the edges of the graph sequentially, we
could overlay the preloading of the next batch of edges with the
calculations in the current batch using either asynchronous I/O
or a preloader thread. This way we got the graph I/O almost for
free. It is conceivable that reiterations [22] or the compression of
vertex identifiers [3] could
further speed up the computation. For implementations on a larger
scale one may use external memory sorting with the two vector
dynamic programming variant. Or, in a distributed environment, we
may partition the graph vertices among the cluster nodes, run a
semi-external memory implementation on each node and exchange the
intermediate results over the network as required. To minimize
network load, a partition that respects the locality of links
(e.g. hostname based) is advisable.
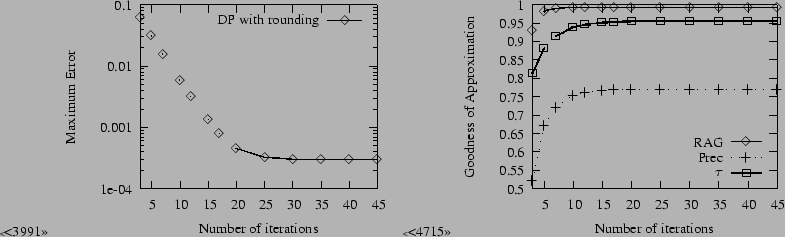
In our first experiment we demonstrate the convergence of
rounded dynamic programming measured by the maximum error as the
number of iterations increases whilst keeping ![]() fixed at a
modest
fixed at a
modest ![]() in all iterations. On Figure 2, left, it can be clearly seen that the
underlying exact dynamic programming converges in far fewer
iterations than its worst case bound of
in all iterations. On Figure 2, left, it can be clearly seen that the
underlying exact dynamic programming converges in far fewer
iterations than its worst case bound of
![]() and that the maximum error
due to rounding is roughly one half of the bound
and that the maximum error
due to rounding is roughly one half of the bound
![]() provable for the
simplified algorithm that rounds to fixed
provable for the
simplified algorithm that rounds to fixed ![]() in all
iterations. On Figure 2, right we see
the goodness of the approximate ranking improving the same way as
maximum error drops. This is theoretically clear since at maximum
one-sided error of
in all
iterations. On Figure 2, right we see
the goodness of the approximate ranking improving the same way as
maximum error drops. This is theoretically clear since at maximum
one-sided error of ![]() we never swap pairs in the approximate
rankings with exact PageRank values at least
we never swap pairs in the approximate
rankings with exact PageRank values at least ![]() apart. In
the chart we set the top set size
apart. In
the chart we set the top set size ![]() to 200.
to 200.
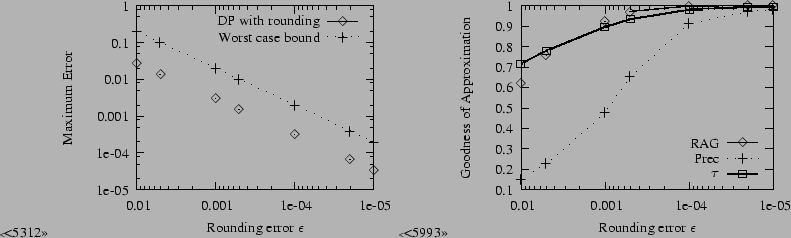
Based on the experiences of Figure 2 we set the number of iterations
![]() to a conservative
to a conservative ![]() and investigated
the effects of the error
and investigated
the effects of the error ![]() , using
rounding to varying
, using
rounding to varying
![]() as in Algorithm 1. The straight line on Figure 3, left clearly indicates that rounding
errors do not accumulate and the maximum error decreases linearly
with the rounding error as in Theorem 2. Additionally the error is much smaller
than the worst case bound4, for
example at
as in Algorithm 1. The straight line on Figure 3, left clearly indicates that rounding
errors do not accumulate and the maximum error decreases linearly
with the rounding error as in Theorem 2. Additionally the error is much smaller
than the worst case bound4, for
example at
![]() it is
it is
![]() vs.
vs.
![]() . The running time scales
sublinearly in
. The running time scales
sublinearly in
![]() (e.g. from 3.5 hours to 14 hours when
moving from
(e.g. from 3.5 hours to 14 hours when
moving from
![]() to
to
![]() ) as it is governed by the
actual average number of
PPR
) as it is governed by the
actual average number of
PPR![]() entries being above
entries being above ![]() and not the worst case upper estimate
and not the worst case upper estimate
![]() . The same observation applies to the
database size, which requires 201 GB for
. The same observation applies to the
database size, which requires 201 GB for
![]() . The right panel of Figure
3 demonstrates that the
approximate ranking improves accordingly as we move to smaller
and smaller
. The right panel of Figure
3 demonstrates that the
approximate ranking improves accordingly as we move to smaller
and smaller ![]() (we set the top set size
(we set the top set size ![]() to 100).
to 100).
We now turn to the experimental comparison of personalized PageRank approximation algorithms summarized in Table 2. For the BFS heuristic and the Monte Carlo method we used an elementary compression (much simpler and faster than [3]) to store the Stanford WebBase graph in 1.6 GB of main memory, hence the semi-external dynamic programming started with a handicap. Finally we mention that we did not apply rounding to the sketches.
It is possible to enhance the precision of most of the above algorithms by applying the neighbor averaging formula (4) over the approximate values once at query time. We applied this trick to all algorithms, except for the sketches (where it does not make a difference), which resulted in slightly higher absolute numbers for larger top lists at a price of a tiny drop for very short top lists, but did not affect the shape or the ordering of the curves. Due to the lack of space, we report neighbor averaged results only.
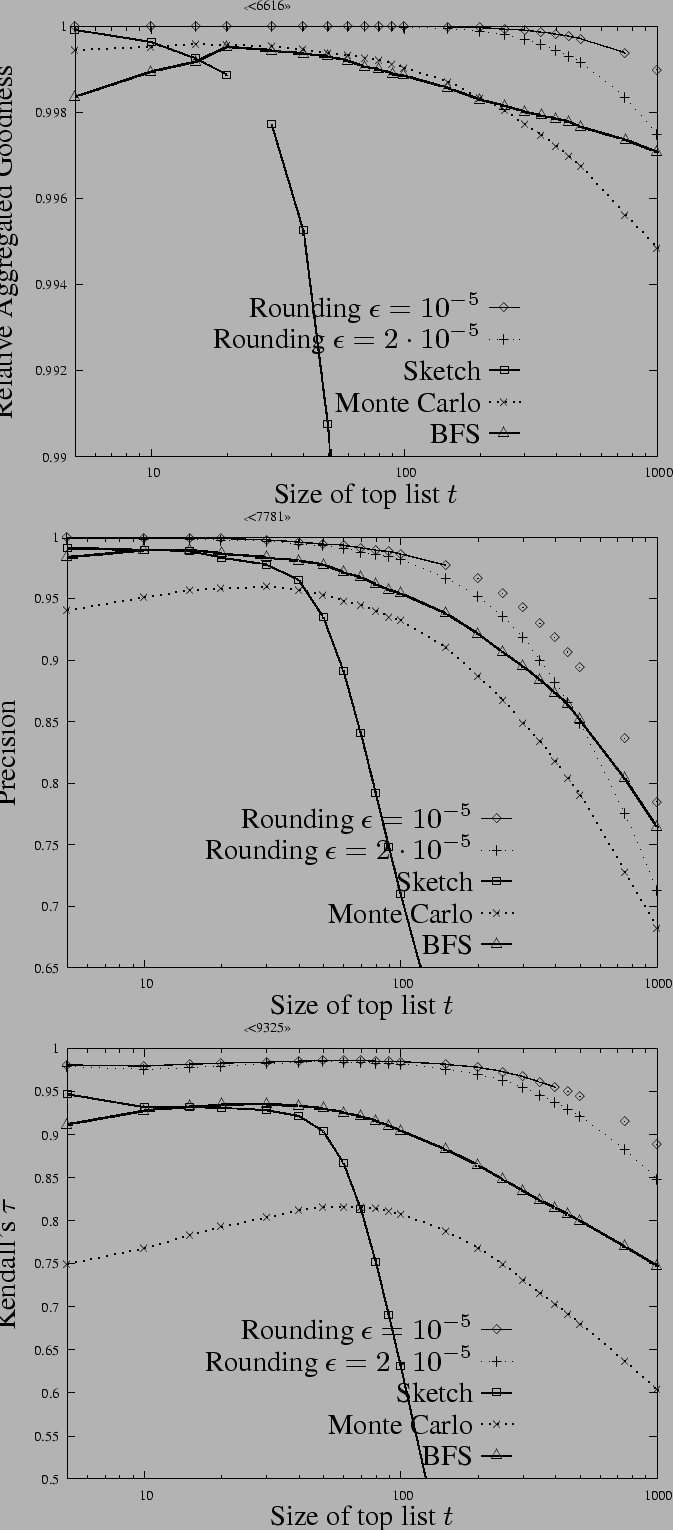
Figure: Empirical comparison of
approximate personalized PageRank algorithms according to
three measures of goodness and varying top set size
![]() without (left) and with (right) neighbor
averaging.
without (left) and with (right) neighbor
averaging.
All three measures of Figure 4
indicate that as the top list size increases, the task of
approximating the top-![]() set becomes more and more difficult. This is
mainly due to the fact that among lower ranked pages the
personalized PageRank difference is smaller and hence harder to
capture using approximation methods. As expected, RAG scores are
the highest, and the strictest Kendall's
set becomes more and more difficult. This is
mainly due to the fact that among lower ranked pages the
personalized PageRank difference is smaller and hence harder to
capture using approximation methods. As expected, RAG scores are
the highest, and the strictest Kendall's ![]() scores are the
smallest with precision values being somewhat higher than
Kendall's
scores are the
smallest with precision values being somewhat higher than
Kendall's ![]() .
.
Secondly, the ordering of the algorithms with respect to the
quality of their approximate top lists is fairly consistent among
Relative Aggregated Goodness, Precision and Kendall's
![]() . Rounded dynamic programming performs
definitely the best, moreover its running times are the lowest
among the candidates. The runner up Breadth-First Search
heuristic and Monte Carlo sampling seem to perform similarly with
respect to Relative Aggregated Goodness with Monte Carlo sampling
underperforming in the precision and Kendall's
. Rounded dynamic programming performs
definitely the best, moreover its running times are the lowest
among the candidates. The runner up Breadth-First Search
heuristic and Monte Carlo sampling seem to perform similarly with
respect to Relative Aggregated Goodness with Monte Carlo sampling
underperforming in the precision and Kendall's ![]() measures.
Although sketching is quite accurate for single value queries
with an average additive error of
, its top list curve drops sharply at size
measures.
Although sketching is quite accurate for single value queries
with an average additive error of
, its top list curve drops sharply at size ![]() around . This is
due to the fact that
and hence a large number of significantly overestimated vertices
crowd out the true top list. Based on these findings, for
practical applications we recommend rounded dynamic programming
with neighbor averaging , which achieves solid precision and rank
correlation (at or above ) over the top pages with reasonable
resource consumption.
around . This is
due to the fact that
and hence a large number of significantly overestimated vertices
crowd out the true top list. Based on these findings, for
practical applications we recommend rounded dynamic programming
with neighbor averaging , which achieves solid precision and rank
correlation (at or above ) over the top pages with reasonable
resource consumption.
Lastly we remark that preliminary SimRank experiments over the same WebBase graph indicate that Algorithm 2 outperforms iterations (8-9) when using an equal amount of computation. Additionally SimRank scores computed by Algorithm 2 achieve marginally weaker agreement (Kruskal-Goodman ) with the Open Directory Project (http://http://dmoz.orghttp://dmoz.org) as Monte Carlo sampling ( ) [12] but with higher recall.
We presented algorithms for the personalized PageRank and SimRank problems that give provable guarantees of approximation and build space optimal data structures to answer arbitrary on-line user queries. Experiments over 80M pages showed that for the personalized PageRank problem rounded dynamic programming performs remarkably well in practice both in terms of precomputation time, database size and the quality of approximation.
An interesting open question is whether our techniques can be extended to approximate other properties of Markov chains over massive graphs, e.g. the hitting time. Another important area of future work is to thoroughly evaluate the quality of the SimRank approximation algorithms. Finally we leave the existence of theoretically optimal algorithms for SimRank value and top list queries with parameter open.
[1] Z. Bar-Yossef, R. Kumar, and D. Sivakumar. Sampling algorithms: Lower bounds and applications. Proc. of 33rd STOC, 2001.
[2] B. H. Bloom. Space/time trade-offs in hash coding with allowable errors. Commun. ACM, 13(7):422-426, 1970.
[3] P. Boldi and S. Vigna. The webgraph framework I: Compression techniques. Proc. of 13th WWW, pp. 595-602, 2004.
[4] A. Z. Broder and M. Mitzenmacher. Network applications of Bloom filters: A survey. Internet Mathematics, 1(4):485-509, 2005.
[5] M. Charikar, K. Chen, and M. Farach-Colton. Finding frequent items in data streams. Proc. of 29th ICALP, pp. 693-703, 2002.
[6] Y.-Y. Chen, Q. Gan, and T. Suel. Local methods for estimating PageRank values. Proc. of 12th CIKM, pp. 381-389, 2004.
[7] G. Cormode and S. Muthukrishnan. An improved data stream summary: The Count-Min sketch and its applications. Journal of Algorithms, 55(1):58-75, 2005.
[8] G. Cormode and S. Muthukrishnan. Summarizing and mining skewed data streams. Proc. of 5th SIAM Intl. Conf. on Data Mining, 2005.
[9] R. Fagin, R. Kumar, M. Mahdian, D. Sivakumar, and E. Vee. Comparing and aggregating rankings with ties. Proc. of 23rd PODS, 2004.
[10] D. Fogaras. Where to start browsing the web? Proc. of 3rd I2CS, Springer LNCS vol. 2877, pp. 65-79, 2003.
[11] D. Fogaras and B. R´cz. Towards scaling fully personalized PageRank. Proc. of 3rd WAW, pp. 105-117, 2004. Full version to appear in Internet Mathematics.
[12] D. Fogaras and B. Rácz. Scaling link-based similarity search. Proc. of 14th WWW, pp. 641-650, 2005. Full version available at www.ilab.sztaki.hu/websearch/Publications/.
[13] T. H. Haveliwala. Topic-sensitive PageRank: A context-sensitive ranking algorithm for web search. IEEE Transactions on Knowledge and Data Engineering, 15(4):784-796, 2003.
[14] M. R. Henzinger, P. Raghavan, and S. Rajagopalan. Computing on data streams. In External Memory Algorithms, DIMACS Book Series vol. 50., pp. 107-118. American Mathematical Society, 1999.
[15] J. Hirai, S. Raghavan, H. Garcia-Molina, and A. Paepcke. WebBase: A repository of web pages. Proc. of 9th WWW, pp. 277-293, 2000.
[16] G. Jeh and J. Widom. SimRank: A measure of structural-context similarity. Proc. of 8th SIGKDD, pp. 538-543, 2002.
[17] G. Jeh and J. Widom. Scaling personalized web search. Proc. of 12th WWW, pp. 271-279, 2003.
[18] S. Kamvar, T. H. Haveliwala, C. Manning, and G. Golub. Exploiting the block structure of the web for computing PageRank. Technical Report 2003-17, Stanford University, 2003.
[19] M. G. Kendall. Rank Correlation Methods. Hafner Publishing Co., New York, 1955.
[20] J. Kleinberg. Authoritative sources in a hyperlinked environment. Journal of the ACM, 46(5):604-632, 1999.
[21] E. Kushilevitz and N. Nisan. Communication Complexity. Cambridge University Press, 1997.
[22] F. McSherry. A uniform approach to accelerated PageRank computation. Proc. of 14th WWW, pp. 575-582, 2005.
[23] S. Muthukrishnan. Data streams: Algorithms and applications. Foundations and Trends in Theoretical Comp. Sci., 1(2), 2005.
[24] L. Page, S. Brin, R. Motwani, and T. Winograd. The PageRank citation ranking: Bringing order to the web. Technical Report 1999-66, Stanford University, 1998.
[25] C. R. Palmer, P. B. Gibbons, and C. Faloutsos. ANF: A fast and scalable tool for data mining in massive graphs. Proc. of 8th SIGKDD, pp. 81-90, 2002.
[26] P. K. C. Singitham, M. S. Mahabhashyam, and P. Raghavan. Efficiency-quality tradeoffs for vector score aggregation. Proc. of 30th VLDB, pp. 624-635, 2004.
[27] J. S. Vitter. External memory algorithms and data structures: Dealing with massive data. ACM Computing Surveys, 33(2):209-271, 2001.
 PPR
PPR PPR
PPR PPR
PPR
![\begin{algorithm} % latex2html id marker 1010 [t] \small \caption{PageRank by ... ...\mbox{PPR}}_v/d^+ (u)\Big) $ \ENDFOR \ENDFOR \end{algorithmic}\end{algorithm}](fp3041-sarlos-img107.png)
![$\displaystyle \widehat{\mbox{PPR}}_u(v)=\min_{i=1\ldots\ln{1\over\delta}} \Big(\sum_{k=0}^{k_{\max}}c(1-c)^{k}\widehat{\mbox{SPPR}}^{[k]}_u(i,h^i_k(v))\Big)$](/www2006/fp3041-sarlos-img166.png)
![$\displaystyle \widehat{\mbox{SPPR}}^{[k]}_u \leftarrow \psi_{k_{\max} - k} \Big... ... (uv) \in E}\hspace{-.3cm} \widehat{\mbox{SPPR}}^{[k-1]}_v /d^+ (u) \Big) \Big)$](/www2006/fp3041-sarlos-img172.png)
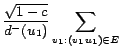 Sim
Sim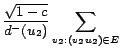 ASim
ASim![\begin{algorithm} % latex2html id marker 1608 [t] \small \caption{SimRank by r... ...}}(v)$\ to multiples of $\epsilon$. } \ENDFOR \end{algorithmic}\end{algorithm}](fp3041-sarlos-img250.png)