1. INTRODUCTION
An important issue arising from Peer-to-Peer (P2P) applications is how to efficiently process top-K join queries with the minimum transmission cost.
Example 1. Figure 1 is an example of top-K join queries, where data from ISI Web of Knowledge (ISI) and Journal Citation Reports (JCR) are located at different peers. The query to retrieve the top 100 papers most frequently cited and published at the highest impact journals can be represented as:
SELECT Title, Author, Journal, Times Cited, Impact Factor
FROM ISI, JCR
WHERE ISI. Journal=JCR. Journal
ORDER BY f(TimesCited, ImpactFactor)
STOP AFTER 100
The ORDER BY statement defines a monotonic increasing rank function, which takes attributes TimesCited and ImpactFactor as parameters to calculate the weighted rank value of paper citation and journal impact in the join results. The STOP AFTER clause sets the number of ordered results as 100.
To answer this query, a straightforward way is to join all the data from ISI with JCR, and then to select the top 100 papers with the maximum rank value. However, this approach suffers from a great consumption of bandwidth while generating the whole join results.
To reduce the number of data that must be actually involved in the join process, this paper proposes a semantic link network to answer top-K join queries in P2P networks.
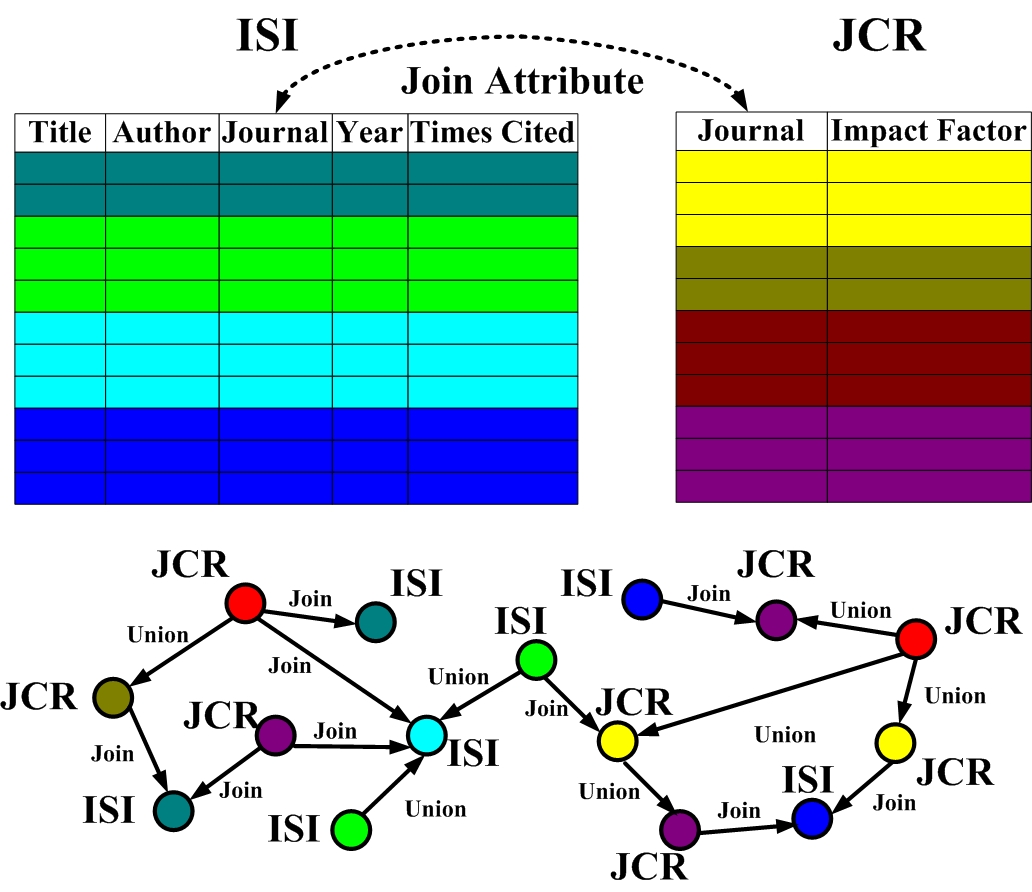
Figure 1. An example of top-K join queries in P2P networks.
2.RELATED WORK
A ranking algebra for ranking computation makes a first step towards a completely decentralized P2P search engine that offers meaningful and efficient rankings [1]. An algorithm for supporting ranked join queries in P2P networks introduced in [3]produces the top-K join results by multicasting the original query together with a lower bound of the rank value. However, the multicast approach in [3] forwards the query to all the neighbors of the current peer, which results in heavy traffic and poor scalability.
To efficiently support top-K join queries in P2P networks, this paper extends our previous work in [4] by establishing semantic links to denote the semantic relationship between peers’data schemas.
3.SEMANTIC LINK MODEL
Let Schema (Pi) and Schema (Pj) be the data schemas of peer Pi and peer Pj. A Semantic Link between Pi and Pj is a pointer with a type ![]() directed from the predecessor Pi to its successor Pj, and
directed from the predecessor Pi to its successor Pj, and ![]() can be one of the followings:
can be one of the followings:
(1) Union Link, Pi-Union->Pj, indicates Schema (Pi)=Schema (Pj), i.e., data in Pi and Pj satisfy a union condition in SQL.
(2) Inclusion Link, Pi-Inclusion->Pj, indicates Schema (Pi)![]() Schema (Pj), i.e., the attribute set of Pj is included in Pi’s attribute set.
Schema (Pj), i.e., the attribute set of Pj is included in Pi’s attribute set.
(3) Extension Link, Pi-Extension->Pj, indicates Schema (Pi)![]() Schema (Pj).
Schema (Pj).
(4) Overlap Link, Pi-Overlap->Pj, indicates Schema(Pi)![]() Schema(Pj)
Schema(Pj)![]() NULL and Schema(Pi)
NULL and Schema(Pi)![]() Schema(Pj) and Schema(Pj)
Schema(Pj) and Schema(Pj)![]() Schema(Pi).
Schema(Pi).
(5) Join Link, Pi-Join(![]() )->Pj, indicates that Schema (Pi) and Schema (Pj) satisfy a join condition in SQL, and
)->Pj, indicates that Schema (Pi) and Schema (Pj) satisfy a join condition in SQL, and ![]() is the join selectivity factor, i.e., the ratio of the number of answers in Pi participating in the join operation to the total number of answers in the Cartesian product of Pi and Pj
[2].
is the join selectivity factor, i.e., the ratio of the number of answers in Pi participating in the join operation to the total number of answers in the Cartesian product of Pi and Pj
[2].
(6) Empty Link, Pi-![]() ->Pj, indicates that there is no semantic relationship between Schema (Pi) and Schema (Pj).
->Pj, indicates that there is no semantic relationship between Schema (Pi) and Schema (Pj).
When a peer Pi joins a P2P network, it will randomly take a peer Pj as one of its neighbors and then send a SOAP message to get Schema (Pj). By checking the semantic relationship between Schema (Pi) and Schema (Pj), the semantic links between Pi and Pj can be established. Semantic links between Pi and other peers can be derived according to the heuristic reasoning rules [4].
4.GENERAL ARCHITECTURE
Let R and S be two relations scattered in P2P networks, a top-K join query can be denoted as Top-K (R![]() S), where r(a), s(b) are the join attributes satisfying a join condition r(a)
S), where r(a), s(b) are the join attributes satisfying a join condition r(a)![]() s(b). Let f(r(p), s(q))
s(b). Let f(r(p), s(q))![]() [0, 1] be a predefined monotonic increasing rank function, where r(p) and s(q) are the rank attributes of R and S. The top-K join query returns the first K answers ordered by the rank value calculated by the rank function f.
The general architecture of semantic-link-based top-K join queries is shown in Figure 2.
[0, 1] be a predefined monotonic increasing rank function, where r(p) and s(q) are the rank attributes of R and S. The top-K join query returns the first K answers ordered by the rank value calculated by the rank function f.
The general architecture of semantic-link-based top-K join queries is shown in Figure 2.
Upon receiving a Top-K (R![]() S) query, peer Pi performs the following steps to get the answers:
S) query, peer Pi performs the following steps to get the answers:
(1)Query Processing — Pi will first parse the query and get the parameters of the Select-List, the join condition r(a)![]() s(b), and the number of ordered results K.
s(b), and the number of ordered results K.
(2)Set the Lower Bound T — Pi will then get the K join results and set the lower bound T of the rank function f by sampling approach as proposed in
[3].
(3)Select Peers Storing Relation R — Pi will then send a SOAP message Top-K (Select-List, r(a)![]() s(b), f(r(p), s(q)), T, K) to its neighbors Pj (j=1…m). If r (p)
s(b), f(r(p), s(q)), T, K) to its neighbors Pj (j=1…m). If r (p)![]() Schema (Pj), r (a)
Schema (Pj), r (a)![]() Schema (Pj), and Schema (Pj)
Schema (Pj), and Schema (Pj)![]() Select-List
Select-List![]() NULL, then Pj is selected as one of the join candidates. After that, Pj will sort on the rank attribute r (p) and calculate the maximum max (Pj. r (p)). To prune irrelevant join data with a rank value below T, Pj then estimates the possible maximum rank value of the join results produced by Pj and its neighbor Pk by f(max (Pj. r(p)), 1), where the second parameter in rank function f is set with the maximum value 1.
NULL, then Pj is selected as one of the join candidates. After that, Pj will sort on the rank attribute r (p) and calculate the maximum max (Pj. r (p)). To prune irrelevant join data with a rank value below T, Pj then estimates the possible maximum rank value of the join results produced by Pj and its neighbor Pk by f(max (Pj. r(p)), 1), where the second parameter in rank function f is set with the maximum value 1.
(4)Select Peers Storing Relation S to be joined with R—If f (max (Pj. r(p)), 1) is greater than the lower bound T, Pj will then forward the query Top-K (Select-List, r(a)![]() s(b), f(max (Pj. r(p)), s(q)), T, K) to its neighbors Pk (k=1…n) through Join semantic links. Pk will calculate the rank function by f(max (Pj. r(p)), Pk. s(q)) and return data satisfying f(max (Pj. r(p)), Pk. s(q))>T to Pj.
s(b), f(max (Pj. r(p)), s(q)), T, K) to its neighbors Pk (k=1…n) through Join semantic links. Pk will calculate the rank function by f(max (Pj. r(p)), Pk. s(q)) and return data satisfying f(max (Pj. r(p)), Pk. s(q))>T to Pj.
(5)Local Top-K Ranking — After receiving data from Pk, Pj will do join operation in its local repository, and sort on the rank function f to get the local top-K rank value.
(6)Global Top-K Ranking — After a predefined TTL (Time-to-Live), Pj (j=1…m) will send local top-K rank value to Pi, who will then sort on all the returned rank value and send the final lower bound to Pj (j=1…m). Finally, join results in Pj (j=1…m) with a rank value greater than the lower bound will be sent to Pi to produce the global top-K answers.
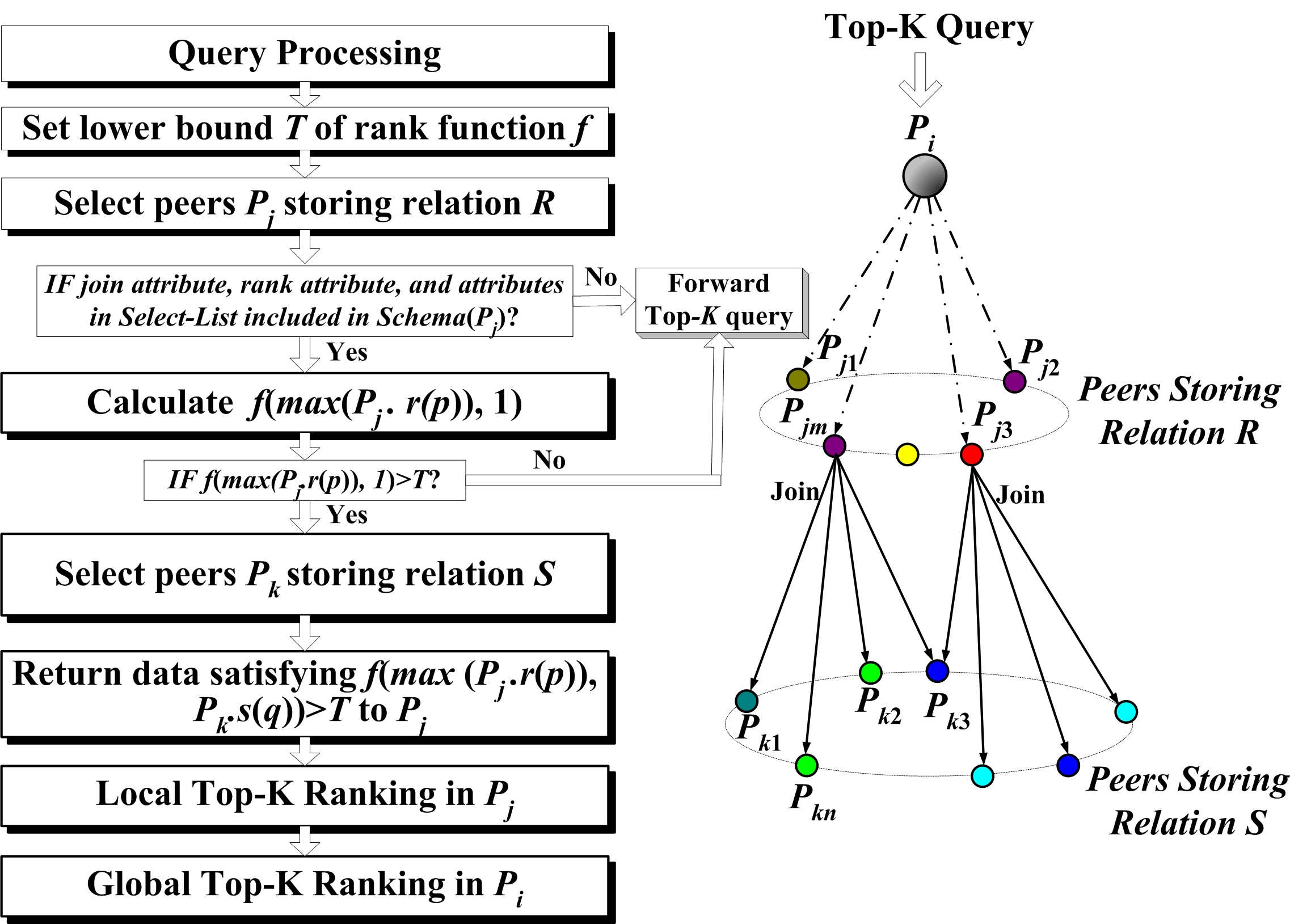
Figure 2. General architecture of semantic-link-based top-K join queries in P2P networks.
5.OPTIMIZATION STRATEGIES
As indicated in [2], the join selectivity factor is an important factor in the cost of performing join operation, and a higher selectivity factor requires a larger number of data comparisons. To reduce the total amount of transmitted data, optimization strategies are implemented in the semantic link network overlay. If the join selectivity factor is high, the nested-loop method is used to produce the join results; otherwise, the sort-merge method should be used. The neighbor with a higher join selectivity factor has the priority to be selected as a join candidate.
6.CONCLUSION
The contribution of this paper is the semantic-link-based infrastructure for efficient processing of top-K join queries. It can be used to construct the semantic overlay of the Knowledge Grid [5, 6] and support advanced applications.
7.ACKNOWLEDGEMENTS
The research work is supported by the National Science Foundation of China (No. 60503047) and the National Basic Research Program of China (No. 2003CB317000).