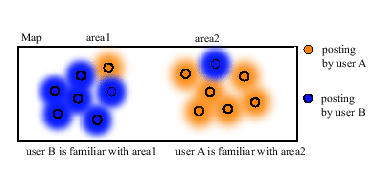
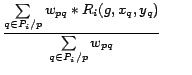Generally speaking, information which has high credibility is posted by the users who have much knowledge about certain areas. The user's expertise was estimated based on the credibility of past posting information in existing methods. However, even if the knowledge of a specific genre can be estimated using existing methods, knowledge in the region can't be estimated.
Our goal is to develop an information recommendation system
using posted information with the method for estimating the
credibility of posted information based on their regional
characteristics.
Our system assigns initial credibility to posted information
if it is the user's first posting, as
![]() .
.
![]() is a default
value determined in advance. If a new posting, which is located
at
is a default
value determined in advance. If a new posting, which is located
at ![]() and whose genre is
and whose genre is
![]() , is posted, then
, is posted, then
![]() is determined
by distance between
is determined
by distance between ![]() and
the location
and
the location ![]() of past
postings as the formula (1) and (2).
of past
postings as the formula (1) and (2). ![]() is the set of posted information by user
is the set of posted information by user ![]() .
.
After a user browses posted information, he can vote for it. When the user votes, he chooses his rating for posting (helpful, moderate, not helpful). In case of ``helpful'', credibility of the voted information increases.
When user ![]() votes for user
votes for user
![]() 's information
's information ![]() , the system updates
credibility of information
, the system updates
credibility of information ![]() by
following formula (3).
by
following formula (3).
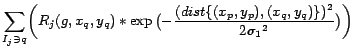 |
(3) |
![]() is sigmoid
function.
is sigmoid
function.
| (4) |
This function is used to control increment of gradient when
![]() is updated.
Gradient is obtained using
is updated.
Gradient is obtained using ![]() , when value of
, when value of
![]() is equal to
is equal to
![]() .
. ![]() is the gain of
sigmoid function. Increasing this value, gradient becomes
steeply.
is the gain of
sigmoid function. Increasing this value, gradient becomes
steeply.
We defined ![]() , which
effects credibility of user
, which
effects credibility of user ![]() ' s
posting
' s
posting ![]() , based on user
, based on user
![]() 's geographical posting
tendency.
's geographical posting
tendency.
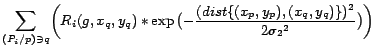 |
(5) | ||
| (6) |
Procedure of our method is summarized as follows. We define either new posting or vote as one step.

We asked 20 students to register their profile, and to post
the information about 4 areas around Tokyo(Shibuya, O-okayama,
Machida, Aobadai), Japan, using our system. We asked them not
only to post the information but also to browse and vote for
other user's information. We set parameters
![]() ,
,
![]() , and
considering scale of 4 areas, we used
, and
considering scale of 4 areas, we used
![]() and
and
![]() at
distance function. As a result, 134 posts and 412 votes are
collected. Among them, 179 votes are ``helpful'', 193 votes are
``moderate'', and 40 are ``not helpful''.
at
distance function. As a result, 134 posts and 412 votes are
collected. Among them, 179 votes are ``helpful'', 193 votes are
``moderate'', and 40 are ``not helpful''.
As the next step, we asked 15 students to assign the rate of credibility to each posted information from rating scale of 1(unreliable) to 7(reliable). We performed the rating experiments for the following three cases.
Therefore, if subject's rating differs by cases, and if credibility calculated by our model can be approximate to rating by human at case 3, then we can say our system determines credibility as substitute for users.
| Coorelation coefficient | Rank correlation coefficient | |||
| Case 1 | 0.430 | 0.403 | ||
| Case 2 | 0.509 | 0.549 | ||
| Case 3 | 0.731 | 0.780 |
Table 1 shows results. We examined correlation coefficient and rank correlation coefficient between subject's rating and credibility which was calculated by our method. Both of them, correlation of case 3 is the highest. Consequently, we consider that subjects imagined what kind of person is the posting user from his posting, and their rating got closer to the model. In conclusion, rating by subjects is different according to the situation, and this model is effective and able to consider the change in human psychology, and to calculate close credibility to rating by human.
Having generality not depending on contents of information,
our method is applicable to various communities.
[1] Michael Pazzani: A Framework for Collaborative, Content-Based and Demographic Filtering. Artificial Intelligence Review, pp. 393-408, 1999.
[2] M. G. Vozalis and K. G. Margaritis: Collaborative Filtering enhanced by Demographic Correlation", AIAI Symposium on Professional Practice in AI, of the 18th World Computer Congress, 2004.
[3]G. Zacharia, A. Moukas, P. Maes: Collaborative Reputation Mechanisms in Electronic Marketplaces, Proceedings of the 32nd Hawaii International Conference on System Sciences, 1999.