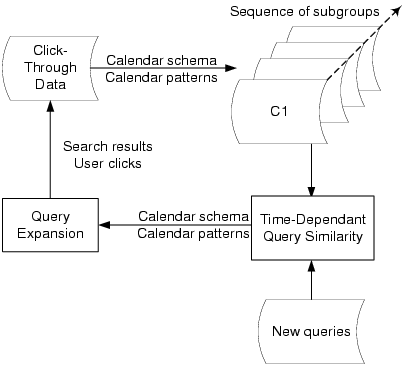
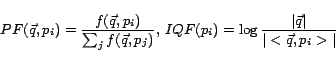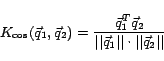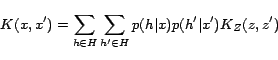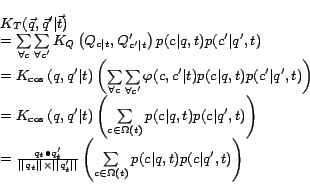With the above definitions, in general, given a collection of
click-through data, we can first partition the data into sequences
of CTSs based on the user-defined calendar pattern and the
corresponding timestamps. For example, given a weekly based
calendar schema  and a list of calendar patterns
and a list of calendar patterns 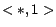 ,
, 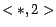 ,
,  ,
, 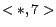 , the click-through data will be
partitioned into sequences of
, the click-through data will be
partitioned into sequences of 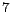 CTSs
CTSs 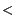
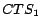 ,
, 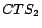 ,
,
,
, 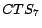
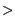 , where
, where 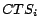 represents the group of
click-through data whose timestamps are contained in the
represents the group of
click-through data whose timestamps are contained in the 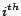 day of the week.
day of the week.
After that, the query similarities are computed within each
subgroup and are aligned into a sequence to show the patterns of
historical change. At the same time, a model is generated, with
which we can obtain the query similarities by inputting queries
and timestamps. Given the above example, we can obtain the query
similarity on each day of the week. Moreover, we can monitor how
the query similarity changes over time within each week in a daily
basis. Also, given two queries and the day of a week, the query
similarity can be returned. Then, the process iterates for
presenting the results and collecting the click-through data with
users interactions. Hereafter, we focus on how to construct the
time-dependent query similarity model based on sequences of
click-through subgroups.
In order to learn the implicit semantics embedded in the
click-through data, we first apply clustering techniques on the
data to find the cluster information in each click-through
subgroup. When the cluster results are obtained, we then formulate
our semantic similarity model by the marginalized kernel technique
that can unify both the explicit content similarity and the
implicit cluster semantics very effectively. Before the discussion
of our semantic similarity model, we first discuss how to cluster
the click-through data efficiently. Let us first give a
preliminary definition.
In the literature, some clustering methods have been proposed to
cluster Web pages in the click-through data using the query-page
relation and propagation of similarities between queries and
pages [3,21]. In [3], an agglomerative
clustering method is proposed. The basic idea is to merge the most
similar Web pages and queries iteratively. Originally,
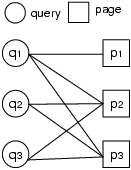
the similarity is defined based on the overlaps of
neighbors in the bipartite graph representation of the
click-through data as shown in Figure 3.
For the efficiency reason, we adopt the agglomerative clustering
method in [3]. In our clustering approach, neighbors in the
bipartite graph are assigned with different weights instead of being
taken as equal. The intuition is that the strength of the
correlation between two query-page pairs may be quite different. For
example, the strength of a query-page pair that co-occurs once
should not be as equal as a query-page pair that co-occurs thousands
of times. Hence, we represent the weights of the neighbors based on
the number of times the corresponding query-page pairs co-occur.
That is, the weight of a page for a given query is the number of
times that page was accessed against the total number of times the
corresponding query was issued. Similarly, the weight of a query for
a given page is the number of times the query was issued against the
total number of times the corresponding page was visited. Then each
query is represented as a vector of weighted pages, and each page is
represented as a vector of weighted queries. As a result,
similarities between pages or queries are calculated based on the
cosine similarity measure.
More details about the clustering algorithm can be found in
[3]. Note that the clustering algorithm is applied on each
of the click-through subgroups. Based on the clustering results,
we now introduce the marginalized kernel technique, which can
effectively explore the hidden information for similarity measure
in a probabilistic framework [11,15].
In the above definition, the terms 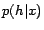 and
and 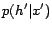 are
employed to describe the uncertainty of the hidden variables
are
employed to describe the uncertainty of the hidden variables 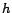 and
and 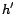 related to the visible variables
related to the visible variables 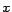 and
and 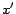 ,
respectively. The marginalized kernel models the probability of
similarity between two objects by exploiting the information with
the hidden representations. Given the above definition of the
marginalized kernel function, we employ it to formulate our
time-dependent kernel function for semantic similarity measure of
queries as follows.
,
respectively. The marginalized kernel models the probability of
similarity between two objects by exploiting the information with
the hidden representations. Given the above definition of the
marginalized kernel function, we employ it to formulate our
time-dependent kernel function for semantic similarity measure of
queries as follows.
In the above formulation, the joint kernel
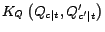 is defined on the two combined query
variables as follows:
is defined on the two combined query
variables as follows:
where
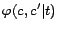 is a function to indicate whether
is a function to indicate whether 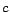 and
and
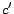 are the same cluster of click-through data, and
are the same cluster of click-through data, and
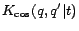 is a time-dependent joint cosine kernel on
the two time-dependent query vectors
is a time-dependent joint cosine kernel on
the two time-dependent query vectors
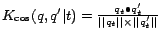 . Note
that the query vectors are only computed on the subgroup ,
to which the given timestamp
. Note
that the query vectors are only computed on the subgroup ,
to which the given timestamp 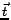 belongs.
belongs.
From the definition of time-dependent marginalized kernel, we can
observe that the semantic similarity between two queries given the
timestamp is determined by two factors. One is the
time-dependent content similarity measure between queries using
the cosine kernel function; another is the likelihood for two
queries to be grouped in a same cluster from the click-through
data given the timestamp.
In this section we conduct a set of empirical studies to
extensively evaluate the performance of our time-dependent query
semantic similarity model. In the rest of this section, we first
describe the dataset used in our evaluation and the experimental
setup in our experiments. Then, we show several empirical examples
to illustrate the real-world results using our time-dependent
framework. After that, we discuss the quality measure metric used
in our performance evaluation. Finally, the quality of the
time-dependent query similarity model is evaluated under different
scenarios.
A real click-through dataset collected from Microsoft MSN search
engine is used in our experiments. The click-through data contains
15 million records of query-page pairs over 32
days from June 16, 2005 to July 17, 2005. The size
of the raw data is more than 22 GB. Note that the
timestamps for each transaction is converted to the local time using
the information about the IP address. In the following experiments,
the entire click-through data is partitioned into subgroups based on
the user-defined calendar schema and calendar patterns. For
instance, given the calendar schema 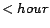 ,
, 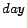 ,
, 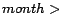 with
the calendar pattern
with
the calendar pattern
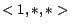 ,
,
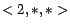 , ,
, ,
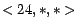 , the click-through data is partitioned into a
sequence of 24 subgroups, where each group consists of the
query-page pairs occurred during a specific hour of everyday. Then,
the average number of query-page pairs in each group is around
59,400,000.
, the click-through data is partitioned into a
sequence of 24 subgroups, where each group consists of the
query-page pairs occurred during a specific hour of everyday. Then,
the average number of query-page pairs in each group is around
59,400,000.
In this subsection, we present a set of examples of query term
similarity evolution over time extracted from the real
click-through data collected from MSN search engine. As there are
many different types of evolution patterns, here we present some
of the representatives.
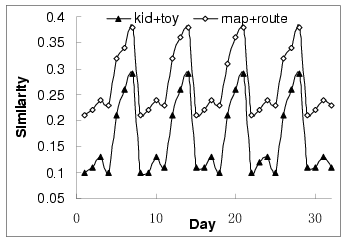
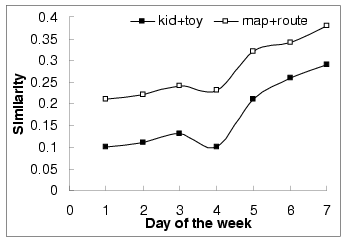
Figure 4 shows the similarities for two query pairs
(``kid", ``toy") and (``map", ``route") on a daily basis in the
32 days. We observe that the similarities changed
periodically in a weekly basis. That is, the similarities changed
repeatedly: starting low in the first few days of the week and
ending high in the weekend. To reflect such time-dependent
pattern, we apply our time-dependent query similarity model to the
two query pairs. Here the calendar schema and calendar patterns
used are , 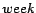 and
and 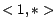 ,
, 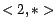 ,
,
,
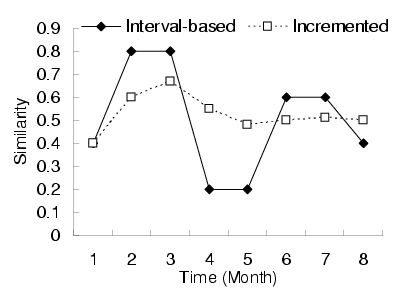
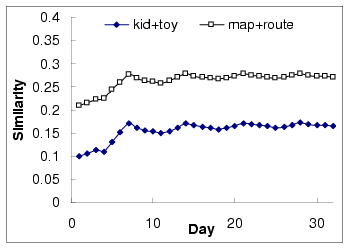
, 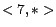 . Figure 5 shows the time-dependent
query similarity measurement for the two query pairs in
Figure 4. We can see that the time-dependent query
similarity model can efficiently summarize the dynamics of the
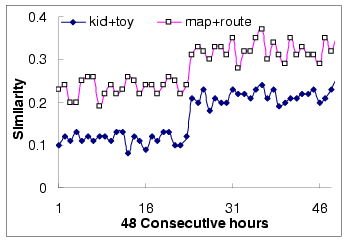
similarity over time on a weekly basis. However, as shown in
Figure 6, the incremented approach cannot
accurately reflect the highs and lows of the similarity values.
Note that the calendar schema and calendar patterns used in the
model are use-defined with related domain knowledge. With
inappropriate calendar schema and calendar patterns, we may not be
able to construct accurate time-dependent query similarity models.
For instance, for the same query pairs, if we use
. Figure 5 shows the time-dependent
query similarity measurement for the two query pairs in
Figure 4. We can see that the time-dependent query
similarity model can efficiently summarize the dynamics of the
similarity over time on a weekly basis. However, as shown in
Figure 6, the incremented approach cannot
accurately reflect the highs and lows of the similarity values.
Note that the calendar schema and calendar patterns used in the
model are use-defined with related domain knowledge. With
inappropriate calendar schema and calendar patterns, we may not be
able to construct accurate time-dependent query similarity models.
For instance, for the same query pairs, if we use 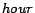 ,
and , , ,
,
and , , , 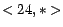 as
calendar schema and calendar patterns (shown in
Figure 7). We can see that there are no predictable
change patterns, hence there is no hour of the day based
time-dependent model that can accurately model the similarity.
as
calendar schema and calendar patterns (shown in
Figure 7). We can see that there are no predictable
change patterns, hence there is no hour of the day based
time-dependent model that can accurately model the similarity.
Figure 4:
Daily-based query similarity evolution
|
Figure 5:
Weekly-based time dependent query similarity model
|
Figure 6:
Query similarity with incremented approach
|
Figure 7:
Hourly-based query similarity evolution
|
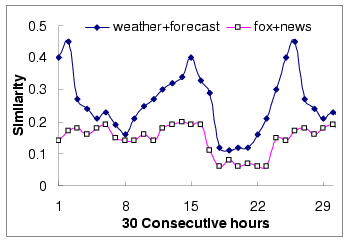
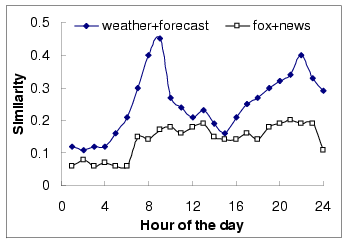
Figure 8 shows the similarity measurement for two
query pairs (``weather", ``forecast") and (``fox", ``news") over
one and a half day on hourly basis. We can see that box query
pairs have two peak values in every day and this pattern
repeatedly occur in the dataset. Based on this observation, we
propose to model their similarity using the time-dependent query
similarity model with a hourly based calendar patterns. That is,
the calendar schema and calendar patterns used are ,
with , , , .
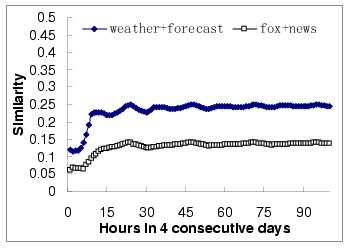
Figure 9 shows the time-dependent query similarity model.
Similarly, Figure 10 shows the similarity values
calculated using the incremented approach, which is
clearly not accurate compare to the time-dependent similarity
model.
Figure 8:
Hourly-based query similarity evolution
|
Figure 9:
Hourly-based time dependent query similarity model
|
Figure 10:
Query similarity with incremented approach
|
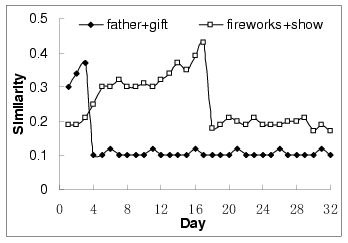
Figure 11:
Daily-based query similarity evolution
|
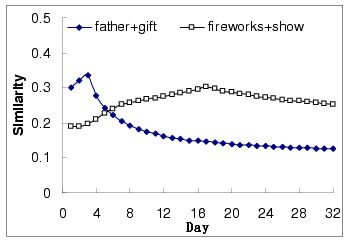
Figure 12:
Query similarity with incremented approach
|
Figure 11 shows the similarity measurement of two
query pairs (``father", ``gift") and (``firework", ``show") on a
daily basis. The corresponding similarity values extracted using
the incremented approach are shown in
Figure 12. We can see that the time-dependent model
cannot be constructed for the two sets of query pairs from the
data available in our collection. The reason is that to track
event-based query pairs' similarity, e.g., the ``father's day"
based query pairs' similarity, we need at least years' of
click-through data since such events happen only once every year.
Note that the previous examples, which can be modeled using the
time-dependent model, are within a time interval of 32
days such as weekly based and hour of the day based (our
click-through dataset only contains data for 32 days).
To evaluate the quality of the time-dependent query similarity
model, the dataset is partitioned into two parts. The first part
consists of a collection of click-through data in the first few
days, while the second part consists of the click-through data in
the rest of 32 days. Note that the timestamps of
click-through data in the first part must be earlier than the
timestamps of the click-through data in the second part. The
reason is that we will use the first part as training data to
construct the time-dependent query similarity model, while the
second part is used to evaluate the model. Moreover, partitioning
of the click-through dataset also depends on the user-defined
calendar schema and calendar patterns. For
example, to build a weekly based model, the training data should
at least cover a time duration of one week; a yearly based
time-dependent model cannot be constructed using click-through
data of a few days.
Once the time-dependent query similarity model is constructed,
given a query pair, the similarity can be obtained by matching the
corresponding calendar patterns in the model. For
example, with the weekly based query similarity model as shown in
Figure 5, the query similarity between ``kid" and ``toy"
can be derived based on the day of the week. We call the
similarity derived from the model as predicted
similarity.
Then, the predicted similarity value is compared with the exact
similarity value calculated using the actual dataset. For example,
with a weekly based similarity model constructed using the dataset
in the first two weeks, the query similarity on the third Monday
can be predicted, denoted as 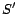 . Then, the exact
similarity is calculated with the dataset in the third Monday.
Given the predicted similarity value and the exact
similarity value
. Then, the exact
similarity is calculated with the dataset in the third Monday.
Given the predicted similarity value and the exact
similarity value 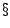 , the accuracy of the model is
defined as
, the accuracy of the model is
defined as
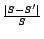 , where
, where 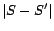 is the
absolute difference between the two values. Similarly, for the
incremented approach, the same definition of accuracy is used so
that we can compare the two approaches.
is the
absolute difference between the two values. Similarly, for the
incremented approach, the same definition of accuracy is used so
that we can compare the two approaches.
In the following experiments, a set of 1000
representative query pairs is selected from the query page pairs
that have similarities larger than 0.3 in the entire
click-through data. Some of them are the top queries in the week
or month, some are randomly selected, while others are selected
manually based on the related real world events such as ``father's
day" and ``hurricane". Note that the accuracy values shown below
are the average accuracy values of all the testing query pairs.
To evaluate the accuracy of the time-dependant query similarity
model, three sets of experiments have been done. Firstly, the
sizes of the data collections that are used to construct and
test the time-dependant query term similarity model are varied.
For example, we use the first twenty days as training data and use
the eleven days left as testing data or we use the first thirty days
as training data and use the last day left as testing data, etc.
Note that as the size of the testing data increases, the distance
between the training data and test data increases as well.
Secondly, only the size of the data collection that is used to
constructing the time-dependent model is varied. Whereas the
testing data is always the other day followed the dataset being
used. For example, we use the first twenty days as training data
and use data in the 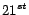 day as testing data. Thirdly, the
distance between the training data and testing data is
varied while the sizes of the training data and testing data are
fixed. Note that the distance between the two data
collections is the distance between the latest query-page pairs in
the two collections. For instance, we can use the first twenty
days as training data and use data in the 21
day as testing data. Thirdly, the
distance between the training data and testing data is
varied while the sizes of the training data and testing data are
fixed. Note that the distance between the two data
collections is the distance between the latest query-page pairs in
the two collections. For instance, we can use the first twenty
days as training data and use data in the 21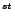 day as testing
data for the case where distance is 1. If the
distance is 2, then data in the
day as testing
data for the case where distance is 1. If the
distance is 2, then data in the 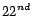 is
used for testing. Note that all possible combinations of training
and testing data that satisfy the distance constraint are used and
the average accuracy values are presented. In the following
experiments, if not specified, the calendar schema , ,
is used with the calendar pattern
,
, ,
.
is
used for testing. Note that all possible combinations of training
and testing data that satisfy the distance constraint are used and
the average accuracy values are presented. In the following
experiments, if not specified, the calendar schema , ,
is used with the calendar pattern
,
, ,
.
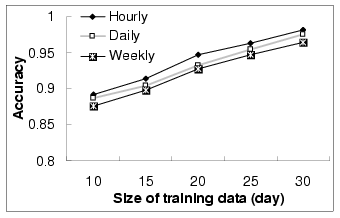
Table 2 shows the quality of the time-dependent query
similarity model by varying the sizes of data that are used for
constructing the model and testing the model. We can see that when
the size of the training data increases and size of the testing
data decreases, the accuracy of the time-dependent model increases
as well. When the sizes of the training and testing data are
similar, the accuracy can be as high as 87.3%. Note that here all
the click-through data in the 32 days are used. We use
the first part of the data as training data and the rest as
testing data. The reason behind may be that when the training is
not large enough to cover all the possible patterns, then the
time-dependent model may not be able to produce accurate results.
Table 2:
Quality of the Time-dependent model (1)
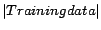 |
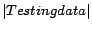 |
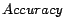 |
| 10 |
22 |
0.784 |
|
15 |
17 |
0.873 |
|
20 |
12 |
0.892 |
|
25 |
7 |
0.921 |
|
30 |
2 |
0.968 |
|
Figure 13 shows the quality of the time-dependent query
similarity model by varying the size of data that is used for
construction the model and fixing the size of data that is used
for testing to 1. Three different calendar schemas and
calendar patterns are used as well. We can see that when the size
of the training data increases, the accuracy of the time-dependent
model increases as well. This fact is just as we expected: as the
size of the training data increases, performance of the model is
expected to increase.
Figure 13:
Quality of the Time-dependent model (2)
|
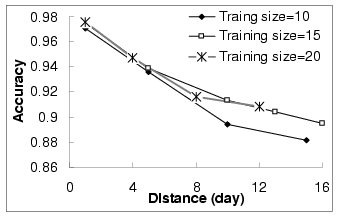
Figure 14 shows how the quality of the time-dependent
query similarity model changes by varying the time distance
between the data collection that is used for testing and the data
collection used for constructing the model. For example, when the
distance is 1 and the training data size is 10,
we summarize all the accuracy values that use the i to
10+i days as training and use the 10+1+i as
testing. We can see that when the distance increases, the accuracy
of the time-dependent model decreases. At the same time, when the
size of the training data increases, with the same distance, the
accuracy value may increase. The reason behind this set of data
shows that the time-dependent model is more accurate if the most
recent data is incorporated as the time-dependent model may be
modified.
Figure 14:
Quality of the Time-dependent model (3)
|
Moreover, we implemented an incremented query similarity model and
compare the prediction accuracy with the time-dependant approach.
Note that for the two approaches both the data that are used for
building the model and the data that are used for testing are the
same (The first part of the data is used for training and the rest
is used for testing). In the following experiments, three calendar
schema and calendar pattern pairs are used. The calendar schema
and calendar patterns are
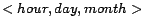 with
,
, ,
;
with
with
,
, ,
;
with
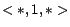 ,
,
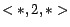 , ,
, ,
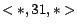 ; and
; and 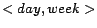 with , , , . We use the 1000 sampled
query pairs for performance evaluation.
with , , , . We use the 1000 sampled
query pairs for performance evaluation.
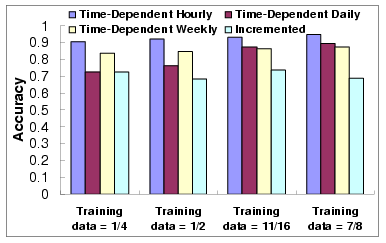
Figure 15 shows the comparison of quality about the
similarity values obtained using the incremented approach and the
time-dependent model. Note that the size of the training data is
varied from 1/4 of the dataset to 7/8 of the dataset as well,
while the rest is used for testing. We can see that when the
intervals in the calendar schema become larger, the quality of the
time-dependant model decreases. This is because we only use a
click-through data of 32 days, which can produce
satisfactory results with the hourly and daily based calendar
patterns. Yet, the quality of the time-dependent model is
generally better than the incremented approach. Moreover, we
observe that for some calendar schema based time-dependent query
similarity model, the accuracy of the model decreases dramatically
when the size of the training data decreases, especially for the
daily based calendar schema. The reason is that the size of our
data collection is not large enough, thus when the size of the
training data decreases it cannot cover every possible day in one
month (requires at least 31 days of training data).
Figure 15:
Quality of the Time-dependent model (4)
|
The experiments show that for most query pairs, the similarities
are time-dependent and the time-dependent model can produce more
accurate similarity values compared to the incremented approach.
Besides the time dimension that affects the similarities between
queries, there are other factors such as user groups, locations,
and topic context, etc. In this paper, we have focused on
incorporating the time dimension. In the future work, we will
incorporate other factors mentioned above into the query
similarity model. Two extended models are presented as follows.
Personalized time-dependent query similarity model: Beside the
time dimension, user groups play an important role in determining
the similarities between queries. This is based on the observation
that different users have different search habits and have
different query vocabularies [8]. For example, some users
search about news and business information in the morning and
entertainment information in the night, while others may have the
reverse habits. Also, to describe the same object or event, people
come from different background usually use different query terms.
The personalized time-dependent query similarity model is to
combine the user information together with the temporal
information to build an accurate query similarity model that can
be used for improving the personalized search experience.
Spatial-temporal-dependent query similarity model: Similar to the
user groups, the spatial location [17,18] of the
queries and Web pages may affect the similarities between queries.
For example, for the same object, users in the United States may
have different information need compared to users in Asia. Also,
contents of Web pages that are created by people in the United
States may use different vocabularies compared to those created by
people from Asia. By combining the spatial and temporal
information, a spatial-temporal-dependent query similarity model
can be constructed. As mentioned in [17], there are
different types of locations such as provider location,
content location, serving location, and
user location. With such information, we believe, the
spatial-temporal-dependent query similarity model can be used to
improve the search experience.
With the availability of massive amount of click-through data in
current commercial search engines, it becomes more and more
important to exploit the click-through data for improving the
performance of the search engines. This paper attempts to extract
the semantic similarity information between queries by exploring
the historical click-through data collected from the search
engine. We realize that the correlation between query terms
evolves from time to time in the click-through data, which is
ignored in the existing approaches. Different from the previous
work, we proposed a time-dependent semantic similarity model by
studying the temporal information associated with the query terms
in the click-through data. We formulated the time-dependent
semantic similarity model into the format of kernel functions
using the marginalized kernel technique, which can discover the
explicit and implicit semantic similarities effectively. We
conducted the experiments on the click-through data from a
real-world commercial search engine in which promising results
show that term similarity does evolve from time to time and our
semantic similarity model is effective in modelling the similarity
information between queries. Finally, we observed an interesting
finding that the evolution of query similarity from time to time
may reflect the evolution patterns and events happening in
different time periods.
The work described in this paper was partially supported by two
grants, one from the Shun Hing Institute of Advanced Engineering,
and the other from the Research Grants Council of Hong Kong
S.A.R., China (Project No. CUHK4205/04E).
- 1
-
R. Attar and A. S. Fraenkel.
Local feedback in full-text retrieval systems.
Journal of ACM, 24(3):397-417, 1977.
- 2
-
R. A. Baeza-Yates, R. Baeza-Yates, and B. Ribeiro-Neto.
Modern Information Retrieval.
Addison-Wesley Longman Publishing Co., Inc., 1999.
- 3
-
D. Beeferman and A. Berger.
Agglomerative clustering of a search engine query log.
In Proceedings of ACM SIGKDD international conference
on Knowledge discovery and data mining, pages 407-416, 2000.
- 4
-
S. M. Beitzel, E. C. Jensen, A. Chowdhury, D. Grossman, and
O. Frieder.
Hourly analysis of a very large topically categorized Web query log.
In Proceedings of the annual international ACM SIGIR
conference on Research and development in information retrieval, pages
321-328, 2004.
- 5
-
S. Chien and N. Immorlica.
Semantic similarity between search engine queries using temporal correlation.
In Proceedings of international World Wide Web conference, pages 2-11, 2005.
- 6
-
H. Cui, J.-R. Wen, J.-Y. Nie, and W.-Y. Ma.
Probabilistic query expansion using query logs.
In Proceedings of international World Wide Web conference, pages 325-332, 2002.
- 7
-
S. Deerwester, S.Dumais, G.Furnas, T.Landauer, and R. Harshman.
Indexing by latent semantic analysis.
Journal of the American Society for Information Science,
41:391-407, 1990.
- 8
-
T. Heath, E. Motta, and M. Dzbor.
Uses of contextual information to support online tasks.
In Proceedings of international World Wide Web conference,
pages 1102-1103, 2005.
- 9
-
T. Joachims.
Optimizing search engines using clickthrough data.
In Proceedings of ACM SIGKDD international conference
on Knowledge discovery and data mining, pages 133-142, 2002.
- 10
-
T. Joachims, L. Granka, B. Pan, H. Hembrooke, and G. Gay.
Accurately interpreting clickthrough data as implicit feedback.
In Proceedings of the annual international ACM SIGIR
conference on Research and development in information retrieval,
154-161, 2005.
- 11
-
H. Kashima, K. Tsuda, and A. Inokuchi.
Marginalized kernels between labeled graphs.
In Proceedings of International conference on Machine Learning,
pages 321-328, 2003.
- 12
-
F. Radlinski and T. Joachims.
Query chains: learning to rank from implicit feedback.
In Proceeding of ACM SIGKDD international conference
on Knowledge discovery and data mining, pages 239-248, 2005.
- 13
-
X. Shen, S. Dumais, and E. Horvitz.
Analysis of topic dynamics in Web search.
In Proceedings of the international conference on World Wide Web,
pages 1102-1103, 2005.
- 14
-
J. Sun, H.-J. Zeng, H. Liu, Y.-C. Lu, and Z. Chen.
Cubesvd: A novel approach to personalized Web search.
In Proceedings of the international conference on World Wide Web, 2005.
- 15
-
K. Tsuda, T. Kin, and K. Asai.
Marginalized kernels for biological sequences.
Bioinformatics, 18(1):268-275, 2002.
- 16
-
M. Vlachos, C. Meek, Z. Vagena, and D. Gunopulos.
Identifying similarities, periodicities and bursts for online search
queries.
In Proceedings of ACM SIGMOD conference, pages 131-142, 2004.
- 17
-
C. Wang, X. Xie, L. Wang, Y. Lu, and W.-Y. Ma.
Web resource geographic location classification and detection.
In Proceedings of international World Wide Web conference, pages 1138-1139, 2005.
- 18
-
L. Wang, C. Wang, X. Xie, J. Forman, Y. Lu, W.-Y. Ma, and Y. Li.
Detecting dominant locations from search queries.
In Proceedings of International conference on Machine Learning,
pages 321-328, 2003.
- 19
-
J.-R. Wen, J.-Y. Nie, and H.-J. Zhang.
Clustering user queries of a search engine.
In Proceedings of the international World Wide Web conference, pages 162-168, 2001.
- 20
-
J. Xu and W. B. Croft.
Improving the effectiveness of information retrieval with local
context analysis.
ACM Transaction on Information System, 18(1):79-112, 2000.
- 21
-
G.-R. Xue, H.-J. Zeng, Z. Chen, Y. Yu, W.-Y. Ma, W. Xi, and
W. Fan.
Optimizing Web search using Web click-through data.
In Proceedings of ACM CIKM conference, pages 118-126, 2004.