2
John Debenham
Faculty of IT
University of Technology, Sydney
PO Box 123 Broadway, NSW 2007, Australia
Simeon Simoff
Faculty of IT
University of Technology, Sydney
PO Box 123 Broadway, NSW 2007, Australia
Date: 30 September 2005
H.5.1Information SystemsMultimedia Information SystemsH.4.mInformation SystemsMiscellaneousI.2.11Artificial IntelligenceDistributed Artificial IntelligenceI.2.mArtificial IntelligenceMiscellaneous
Market reliability
The data mining systems that have been developed for mining information both from the virtual institution and from general sources from the World Wide Web are described in Sec. 2.Intelligent agents that are built on an architecture designed specifically to handle real-time information flows are described in Sec. 3. Sec. 4 describes the work on virtual institutions -- this work has been carried out in collaboration with ``Institut d'Investigacio en Intel.ligencia Artificial2'', Spanish Scientific Research Council, UAB, Barcelona, Spain.Sec. 5 concludes.
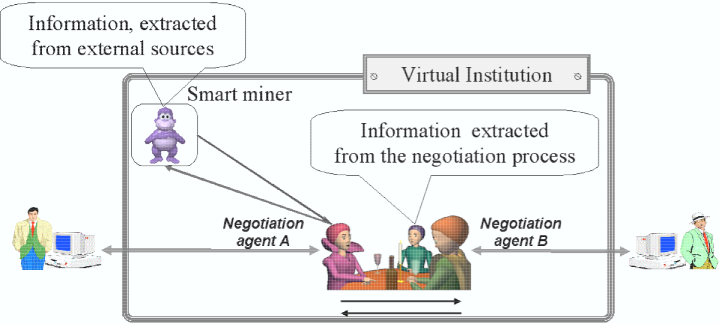
Real-time embedded data mining is an essential component of the proposed framework. In this framework the trading agents make their informed decisions, based on utilising two types of information (as illustrated in Figure 1):
The embedded data mining system provides the information extracted from the external sources. The system complements and services the information-based architecture developed in [5] and [11]. The information request and the information delivery format is defined by the interaction ontology. As these agents operate with negotiation parameters with a discrete set of feasible values, the information request is formulated in terms of these values. As agents proceed with negotiation they have a topic of negotiation and a shared ontology that describes that topic. For example, if the topic of negotiation is buying a number of digital cameras for a University, the shared ontology will include the product model of the camera, and some characteristics, like ``product reputation'' (which on their own can be a list of parameters), that are usually derived from additional sources (for example, from different opinions in a professional community of photographers or digital artists). As the information-based architecture assumes that negotiation parameters are discrete, the information request can be formulated as a subset of the range of values for a negotiation parameter. For example, if the negotiator is interested in cameras with 8 megapixel resolution, and the brand is a negotiation parameter, the information request can be formulated as a set of camera models, e.g. {``Canon Power Shot Pro 1'', ``Sony f828'', ``Nikon Coolpix 8400'', ``Olympus C-8080''} and a preference estimate based on the information in the different articles available. The collection of parameter sets of the negotiation topic constitutes the input to the data mining system. Continuous numerical values are replaced by finite number of ranges of interest.
The data mining system initially constructs data sets that are ``focused'' on requested information, as illustrated in Figure 2. From the vast amount of information available in electronic form, we need to filter the information that is relevant to the information request. In our example, this will be the news, opinions, comments, white papers related to the five models of digital cameras. Technically, the automatic retrieval of the information pieces utilises the universal news bot architecture presented in [13]. Developed originally for news sites only, the approach is currently being extended to discussion boards and company white papers.
The ``focused'' data set is dynamically constructed in an iterative process. The data mining agent constructs the news data set according to the concepts in the query. Each concept is represented as a cluster of key terms (a term can include one or more words), defined by the proximity position of the frequent key terms. On each iteration the most frequent (terms) from the retrieved data set are extracted and considered to be related to the same concept. The extracted keywords are resubmitted to the search engine. The process of query submission, data retrieval and keyword extraction is repeated until the search results start to derail from the given topic.
The set of topics in the original request is used as a set of class labels. In our example we are interested in the evidence in support of each particular model camera model. A simple solution is for each model to introduce two labels -- positive opinion and negative opinion, ending with ten labels. In the constructed ``focused'' data set, each news article is labelled with one of the values from this set of labels. An automated approach reported in [13] extends the tree-based approach proposed in [10].
The data sets required further automatic preprocessing, related to possible redundancies in the information encoded in the set that can bias the analysis algorithms. For example, identifying a set of opinions about the camera that most likely comes from the same author, though it has been retrieved from different ``opinion boards'' on the Internet.
Once the set is constructed, building the ``advising model'' is reduced to a classification data mining problem. As the model is communicated back to the information-based agent architecture, the classifier output should include all the possible class labels with an attached probability estimates for each class. Hence, we use probabilistic classifiers (e.g. Naïve Bayes, Bayesian Network classifiers) [9] without the min-max selection of the class output [e.g., in a classifier based on Naïve Bayes algorithm], we calculate the posterior probability ![]() of each class
of each class ![]() with respect to combinations of key terms and then return the tuples
with respect to combinations of key terms and then return the tuples ![]() for all classes, not just the one with maximum
for all classes, not just the one with maximum ![]() . In the case when we deal with range variables the data mining system returns the range within which is the estimated value. For example, the response to a request for an estimate of the rate of change between two currencies over specified period of time will be done in three steps: (i) the relative focused news data set will be updated for the specified period; (ii) the model that takes these news in account is updated, and; (iii) the output of the model is compared with requested ranges and the matching one is returned. The details of this part of the data mining system are presented in [14]. The currently used model is a modified linear model with an additional term that incorporates a news index Inews, which reflects the news effect on exchange rate. The current architecture of the data mining system in the e-market environment is shown in Figure 3. The
. In the case when we deal with range variables the data mining system returns the range within which is the estimated value. For example, the response to a request for an estimate of the rate of change between two currencies over specified period of time will be done in three steps: (i) the relative focused news data set will be updated for the specified period; (ii) the model that takes these news in account is updated, and; (iii) the output of the model is compared with requested ranges and the matching one is returned. The details of this part of the data mining system are presented in [14]. The currently used model is a modified linear model with an additional term that incorporates a news index Inews, which reflects the news effect on exchange rate. The current architecture of the data mining system in the e-market environment is shown in Figure 3. The ![]() denote the output of the system to the information-based agent architecture. In addition, the data mining system provides parameters that define the ``quality of the information'', including:
denote the output of the system to the information-based agent architecture. In addition, the data mining system provides parameters that define the ``quality of the information'', including:
Most of the work on multi-issue negotiation has focussed on one-to-one bargaining -- for example [6]. There has been rather less interest in one-to-many, multi-issue auctions -- [4] analyzes some possibilities -- despite the size of the e-procurement market which typically attempts to extend single-issue, reverse auctions to the multi-issue case by post-auction haggling. There has been even less interest in many-to-many, multi-issue exchanges.
The generic architecture of our ``information-based'' agents is presented in Sec. 3.1. The agent's reasoning employs entropy-based inference and is described in Sec. 3.2. The integrity of the agent's information is in a permanent state of decay, Sec. 3.3 describes the agent's machinery for managing this decay leading to a characterization of the ``value'' of information. Sec. 3.4 describes metrics that bring order and structure to the agent's information with the aim of supporting its management.
An agent called ![]() is the subject of this discussion.
is the subject of this discussion.![]() engages in multi-issue negotiation with a set of other agents:
engages in multi-issue negotiation with a set of other agents: ![]() .The foundation for
.The foundation for ![]() 's operation is the information that is generated both by and because of its negotiation exchanges. Any message from one agent to another reveals information about the sender.
's operation is the information that is generated both by and because of its negotiation exchanges. Any message from one agent to another reveals information about the sender.![]() also acquires information from the environment -- including general information sources --�to support its actions.
also acquires information from the environment -- including general information sources --�to support its actions. ![]() uses ideas from information theory to process and summarize its information.
uses ideas from information theory to process and summarize its information.![]() 's aim may not be ``utility optimization'' -- it may not be aware of a utility function.If
's aim may not be ``utility optimization'' -- it may not be aware of a utility function.If ![]() does know its utility function and if it aims to optimize its utility then
does know its utility function and if it aims to optimize its utility then ![]() may apply the principles of game theory to achieve its aim.The information-based approach does not to reject utility optimization -- in general, the selection of a goal and strategy is secondary to the processing and summarizing of the information.
may apply the principles of game theory to achieve its aim.The information-based approach does not to reject utility optimization -- in general, the selection of a goal and strategy is secondary to the processing and summarizing of the information.
In addition to the information derived from its opponents, ![]() has access to a set of information sources
has access to a set of information sources ![]() that may include the marketplace in which trading takes place, and general information sources such as news-feeds accessed via the Internet.Together,
that may include the marketplace in which trading takes place, and general information sources such as news-feeds accessed via the Internet.Together, ![]() ,
, ![]() and
and ![]() make up a multiagent system.The integrity of
make up a multiagent system.The integrity of ![]() 's information, including information extracted from the Internet, will decay in time. The way in which this decay occurs will depend on the type of information, and on the source from which it was drawn. Little appears to be known about how the integrity of real information, such as news-feeds, decays, although its validity can often be checked -- ``Is company X taking over company Y?'' -- by proactive action given a cooperative information source
's information, including information extracted from the Internet, will decay in time. The way in which this decay occurs will depend on the type of information, and on the source from which it was drawn. Little appears to be known about how the integrity of real information, such as news-feeds, decays, although its validity can often be checked -- ``Is company X taking over company Y?'' -- by proactive action given a cooperative information source ![]() . So
. So ![]() has to consider how and when to refresh its decaying information.
has to consider how and when to refresh its decaying information.
![]() has two languages:
has two languages: ![]() and
and ![]() .
. ![]() is an illocutionary-based language for communication.
is an illocutionary-based language for communication. ![]() is a first-order language for internal representation -- precisely it is a first-order language with sentence probabilities optionally attached to each sentence representing
is a first-order language for internal representation -- precisely it is a first-order language with sentence probabilities optionally attached to each sentence representing ![]() 's epistemic belief in the truth of that sentence. Fig. 4 shows a high-level view of how
's epistemic belief in the truth of that sentence. Fig. 4 shows a high-level view of how ![]() operates.Messages expressed in
operates.Messages expressed in ![]() from
from ![]() and
and ![]() are received, time-stamped, source-stamped and placed in an in-box
are received, time-stamped, source-stamped and placed in an in-box ![]() . The messages in
. The messages in ![]() are then translated using an import function
are then translated using an import function ![]() into sentences expressed in
into sentences expressed in ![]() that have integrity decay functions (usually of time) attached to each sentence, they are stored in a repository
that have integrity decay functions (usually of time) attached to each sentence, they are stored in a repository ![]() . And that is all that happens until
. And that is all that happens until ![]() triggers a goal.
triggers a goal.
![]() triggers a goal,
triggers a goal, ![]() , in two ways: first in response to a message received from an opponent
, in two ways: first in response to a message received from an opponent ![]() ``I offer you 1 in exchange for an apple'', and second in response to some need,
``I offer you 1 in exchange for an apple'', and second in response to some need, ![]() , ``goodness, we've run out of coffee''. In either case,
, ``goodness, we've run out of coffee''. In either case, ![]() is motivated by a need -- either a need to strike a deal with a particular feature (such as acquiring coffee) or a general need to trade.
is motivated by a need -- either a need to strike a deal with a particular feature (such as acquiring coffee) or a general need to trade. ![]() 's goals could be short-term such as obtaining some information ``what is the time?'', medium-term such as striking a deal with one of its opponents, or, rather longer-term such as building a (business) relationship with one of its opponents. So
's goals could be short-term such as obtaining some information ``what is the time?'', medium-term such as striking a deal with one of its opponents, or, rather longer-term such as building a (business) relationship with one of its opponents. So ![]() has a trigger mechanism
has a trigger mechanism ![]() where:
where: ![]() .
.
For each goal that ![]() commits to, it has a mechanism,
commits to, it has a mechanism, ![]() , for selecting a strategy to achieve it where
, for selecting a strategy to achieve it where ![]() where
where ![]() is the strategy library. A strategy
is the strategy library. A strategy ![]() maps an information base into an action,
maps an information base into an action, ![]() . Given a goal,
. Given a goal, ![]() , and the current state of the social model
, and the current state of the social model ![]() , a strategy:
, a strategy: ![]() . Each strategy,
. Each strategy, ![]() , consists of a plan,
, consists of a plan, ![]() and a world model (construction and revision) function,
and a world model (construction and revision) function, ![]() , that constructs, and maintains the currency of, the strategy's world model
, that constructs, and maintains the currency of, the strategy's world model ![]() that consists of a set of probability distributions.A plan derives the agent's next action,
that consists of a set of probability distributions.A plan derives the agent's next action, ![]() , on the basis of the agent's world model for that strategy and the current state of the social model:
, on the basis of the agent's world model for that strategy and the current state of the social model: ![]() , and
, and ![]() .
. ![]() employs two forms of entropy-based inference:
employs two forms of entropy-based inference:
Let ![]() be the set of all positive ground literals that can be constructed using
be the set of all positive ground literals that can be constructed using ![]() 's language
's language ![]() .A possible world,
.A possible world, ![]() , is a valuation function:
, is a valuation function: ![]() .
. ![]() is the set of all possible worlds that are consistent with
is the set of all possible worlds that are consistent with ![]() 's knowledge base
's knowledge base ![]() that contains statements which
that contains statements which ![]() believes are true.A random world for
believes are true.A random world for ![]() ,
, ![]() is a probability distribution over
is a probability distribution over ![]() , where
, where ![]() expresses
expresses ![]() 's degree of belief that each of the possible worlds,
's degree of belief that each of the possible worlds, ![]() , is the actual world. The derived sentence probability of any
, is the actual world. The derived sentence probability of any ![]() , with respect to a random world
, with respect to a random world ![]() is:
is:
Given a prior probability distribution ![]() and a set of constraints
and a set of constraints ![]() , the principle of minimum relative entropy chooses the posterior probability distribution
, the principle of minimum relative entropy chooses the posterior probability distribution ![]() that has the least relative entropy3 with respect to
that has the least relative entropy3 with respect to ![]() :
:

The only restriction on incoming ![]() is that it is expressed in terms of the ontology -- this is very general. However, the way in which
is that it is expressed in terms of the ontology -- this is very general. However, the way in which ![]() is used is completely specific -- it will be represented as a set of linear constraints on one or more probability distributions. A chunk of
is used is completely specific -- it will be represented as a set of linear constraints on one or more probability distributions. A chunk of ![]() may not be directly related to one of
may not be directly related to one of ![]() 's chosen distributions or may not be expressed naturally as constraints, and so some inference machinery is required to derive these constraints -- this inference is performed by model building functions,
's chosen distributions or may not be expressed naturally as constraints, and so some inference machinery is required to derive these constraints -- this inference is performed by model building functions, ![]() , that have been activated by a plan
, that have been activated by a plan ![]() chosen by
chosen by ![]() .
. ![]() denotes the set of constraints on distribution
denotes the set of constraints on distribution ![]() derived by
derived by ![]() from
from ![]() .
.
An agent may have models of integrity decay for some particular distributions, but general models of integrity decay for, say, a chunk of information taken at random from the World Wide Web are generally unknown. However the values to which decaying integrity should tend in time are often known. For example, a prior value for the truth of the proposition that a ``22 year-old male will default on credit card repayment'' is well known to banks. If ![]() attaches such prior values to a distribution
attaches such prior values to a distribution ![]() they are called the decay limit distribution for
they are called the decay limit distribution for ![]() ,
, ![]() . No matter how integrity of
. No matter how integrity of ![]() decays, in the absence of any other relevant information it should decay to the decay limit distribution. If a distribution with
decays, in the absence of any other relevant information it should decay to the decay limit distribution. If a distribution with ![]() values has no decay limit distribution then integrity decays to the maximum entropy value
values has no decay limit distribution then integrity decays to the maximum entropy value ![]() . In other words, the maximum entropy distribution is the default decay limit distribution.
. In other words, the maximum entropy distribution is the default decay limit distribution.
In the absence of new ![]() the integrity of distributions decays. If
the integrity of distributions decays. If ![]() then we use a geometric model of decay:
then we use a geometric model of decay:
We now describe how new ![]() is imported to the distributions. A single chunk of
is imported to the distributions. A single chunk of ![]() may effect a number of distributions. Suppose that a chunk of
may effect a number of distributions. Suppose that a chunk of ![]() is received from
is received from ![]() and that
and that ![]() attaches the epistemic belief probability
attaches the epistemic belief probability ![]() to it. Each distribution models a facet of the world. Given a distribution
to it. Each distribution models a facet of the world. Given a distribution ![]() ,
, ![]() is the probability that the possible world
is the probability that the possible world ![]() for
for ![]() is the true world for
is the true world for ![]() . The effect that a chunk
. The effect that a chunk ![]() has on distribution
has on distribution ![]() is to enforce the set of linear constraints on
is to enforce the set of linear constraints on ![]() ,
, ![]() . If the constraints
. If the constraints ![]() are taken by
are taken by ![]() as valid then
as valid then ![]() could update
could update ![]() to the posterior distribution
to the posterior distribution ![]() that is the distribution with least relative entropy with respect to
that is the distribution with least relative entropy with respect to ![]() satisfying the constraint:
satisfying the constraint:
 |
The idea of Eqn. 6, is that the current value of ![]() should be such that, on average,
should be such that, on average, ![]() will be seen to be ``close to''
will be seen to be ``close to'' ![]() when we eventually discover
when we eventually discover ![]() -- no matter whether or not
-- no matter whether or not ![]() was used to update
was used to update ![]() , as determined by the acceptability test in Eqn. 7 at time
, as determined by the acceptability test in Eqn. 7 at time ![]() . That is, given
. That is, given ![]() ,
, ![]() and the prior
and the prior ![]() , calculate
, calculate ![]() and
and ![]() using Eqn. 5.Then the observed reliability for distribution
using Eqn. 5.Then the observed reliability for distribution ![]() ,
, ![]() , on the basis of the verification of
, on the basis of the verification of ![]() with
with ![]() is the value of
is the value of ![]() that minimises the Kullback-Leibler distance between
that minimises the Kullback-Leibler distance between ![]() and
and ![]() :
:
![$\displaystyle \arg\min_{r}\sum_{i=1}^{n}(r\cdot p_{i}^{[\textit{info}]} + (1-r)......\cdot p_{i}^{[\textit{info}]} + (1-r)\cdot q_{i}^{s}}{p^{[\textit{fact}]}_{i}}$](/fp1008-debenham-img132.png)
![\begin{displaymath}\begin{split}R&^{t+1}(\Pi,\Omega,o_{j})=\\ & (1-\rho)\times R......mid[\textit{fact}])}\times\mathrm{Sem}(o_{j},o_{k}) \end{split}\end{displaymath}](/fp1008-debenham-img137.png) |
 |
Virtual Institutions are electronic environments designed to meet the following requirements towards their inhabitants:
The second requirement is supported to some extent by the distributed 3D Virtual Worlds technology. Emulating and extending the physical world in which we live, Virtual Worlds offer rich environment for a variety of human activities and multi-mode interaction. Both humans and software agents are embedded and visualised in such 3D environments as avatars, through which they communicate. The inhabitants of virtual worlds are aware of where they are and who is there -- elements of the presence that are excluded from the current paradigm of e-Commerce environments. Following the metaphor of the physical world, these environments do not impose any regulations (in terms of language) on the interactions and any restrictions (in terms of norms of behaviour). When this encourages the social aspect of interactions and establishment of networks, these environments do not provide means for enabling some behavioural norms, for example, fulfilling commitments, penalisation for misbehaviour and others.
Virtual Institutions addressed both requirements, retaining the features and advantages of the above discussed approaches, as illustrated in Figure 5. They can be seen as the logical evolution and merger of the two streams of development of environments that can host electronic markets as mixed societies of humans and software agents.
Technologically, Virtual Institutions are implemented following a three-layered framework, which provides deep integration of Electronic Institution technology and Virtual Worlds technology [3]. The framework is illustrated in Figure 6. The Electronic Institution Layer hosts the environments that support the Electronic Institutions technological component: the graphical EI specification designer ISLANDER and the runtime component AMELI [1]. At runtime, the Electronic Institution layer loads the institution specification and mediates agents interactions while enforcing institutional rules and norms.
The Communication Layer connects causally the Electronic Institutions layer with the 3D representation of the institution, which resides in the Social layer. The causal connection is the integrator. It enables the Electronic Institution layer to respond to changes in the 3D representation (for example, to respond to the human activities there), and passes back the response of the Electronic Institution layer in order to modify the corresponding 3D environment and maintain the consistency of the Virtual Institution. Virtual Institution representation is a graph and its topology can structure the space of the virtual environment in different ways. This is the responsibility of the Social layer. In this implementation the layer is represented in terms of a 3D Virtual World technology, structured around rooms, avatars, doors (for transitions) and other graphical elements. Technically, the Social layer is currently utilising Adobe Atmosphere virtual world technology. The design of the 3D World of the Virtual Institution is developed with the Annotation Editor, which ideally should take as an input a specification of the Electronic Institution layer and produce an initial layout of the 3D space. Currently, part of the work is done manually by a designer.
The core technology -- the Causal Connection Server -- enables the Communication Layer to act in two directions. Technically, in direction from the Electronic Institution layer, messages uttered by an agent have immediate impact in the Social layer. Transition of the agent between scenes in the Electronic Institution layer, for example, must let the corresponding avatar move within the Virtual World space accordingly. In the other direction, events caused by the actions of the human avatar in the Virtual World are transferred to the Electronic Institution layer and passed to an agent. This implies that actions forbidden to the agent by the norms of the institution (encoded in the Electronic Institution layer), cannot be performed by the human. For example, if a human needs to register first before leaving for the auction space, the corresponding agent is not allowed to leave the registration scene. Consequently, the avatar is not permitted to open the corresponding door to the auction (see [3] for technical details of the implementation of the Causal Connection Server).
Virtual Institutions are immersive environments and as such go beyond the catalogue-style markets with form-based interaction approaches currently dominating the World Wide Web. Embedding traders (whether humans or software agents) as avatars in the electronic market space on the Web positions them literally ``in'' the World Wide Web rather than ``on'' it.


![\includegraphics[width=2.2in]{agarch}](/fp1008-debenham-img10.png)




