Abstract
In this paper, we
focus on the development of a framework for automatic metadata generation. The
first step towards this framework is the definition of an Application Programmer
Interface (API), which we call the Simple Indexing Interface (SII). The second step is the definition of a framework
for implementation of the SII. Both steps are presented in some detail in this
paper. We also report on empirical evaluation of the metadata that the SII and supporting
framework generated in a real-life context.
1.
Introduction
One of the main concerns in
learning technology research is the problem of acquiring the critical mass to
establish real reuse. There are several aspects to the solution of this
problem. Many projects focus on the
creation of content and how this can be made easier, faster or cheaper [25, 14]. Other projects focus on interoperability aspects
[11]. The aspect we focus on in this
paper is the creation of metadata.
Without appropriate metadata no learning content will be really reusable
because it will be difficult or impossible to identify and retrieve it.
Learning object metadata has
been researched in several projects. One
great achievement was the development of the IEEE LOM standard [17], based on
the original ARIADNE pedagogical header definition, and adopted in the widely
deployed ADL SCORM reference model[1].
The creation of these metadata, however, currently turns out to be a
problem for most systems:
·
Most reuse initiatives are still struggling to achieve
critical mass,
·
Many learning objects only have a very limited set of
metadata associated to them [20].
We consider several reasons why
users often do not make the learning objects available for reuse or do not create
metadata for those objects (see also [12, 14]). Most importantly, the current
tools available for metadata creation are not user friendly. Most tools directly relate to some standard
and present that standard to the users.
The user has to fill in a substantial number of electronic forms. However,
the standards were not meant to be visible to end users. A direct representation of these standards on
forms makes it very difficult and time consuming to fill out the correct values
for the metadata in substantial quantities. The slogan that “electronic forms
must die” addresses this specific concern.
|
. |
A possible solution to this
problem is the automatic creation of learning object metadata. In this way, the users do not have to bother
with the metadata if they do not want to.
This can be compared with search engines on the web that index web pages
in the background without any intervention of the creator or the host of the
site. In our approach, if the user wants
to correct, add or delete metadata, he will still be able to do so, but most users
will not need to spend time on it.
In this paper, we introduce a
framework to set up an automatic metadata generation system as a web
service. This web service generates IEEE
Learning Object Metadata although in the future other metadata schemas should
be supported as well. Depending on the
type of learning object document, the created set can be rather small or more
extensive. We at least try to generate a
metadata set that contains all the mandatory elements defined in the ARIADNE
Application Profile [2].
2.
Automatic
Metadata Creation
2.1
Introduction
In many learning management
systems, metadata can be associated with learning objects manually, or they can
be generated partially by the system (see Figure
1). It is our
opinion that manual creation of metadata might be feasible in small deployments,
but that it is not an option for larger deployments where a considerable number
of learning objects are to be managed for each user. The system should offer functions comparable
to search engines and classifiers for the web (see also [21]). Search engines index web pages automatically
without manual intervention of the users or the creators of the pages.
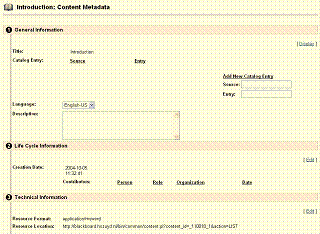
Figure 1: A combination of
manually and automatically filled in metadata in the Blackboard LMS
If learning management systems
can offer a similar functionality for learning objects, the users will provide
much more easily a great number of learning objects and real reuse will become feasible.
2.2
Metadata
sources
In [4] and [5], we already
introduced different methods for automatic metadata generation. Metadata can be extracted from different
sources that are available to the system.
We distinguish four main categories of metadata sources:
1.
Document content
analysis: One obvious source for metadata about an object is the object
itself. An object-based indexer
generates metadata using the object independent from any specific usage. Typical
content analyzers are keyword extractors, language analyzers for text documents
or pattern recognizers for images.
2.
Document context
analysis: When an object is used in a specific context and data about that
context are available, we can rely on the context to obtain information about
the object itself. One single learning object typically can be deployed in
several contexts which provide us with metadata about it. Section 2.3 provides
more details on this kind of metadata source.
3.
Document usage:
Real use of objects can provide us with more flexible and lively metadata than
the sometimes more “theoretical” values provided by other metadata sources, or
even by human indexers. Systems that track and log the real use of documents by
learners are therefore a valuable source. These logs for example store the time
spent reading a document or solving exercises. This metadata source category
could be considered as a “usage context”, and as such as a special case of
document context analysis.
4.
Composite documents structure: In some cases, learning
objects are parts of a whole but stored separately [5]. In such a case, the metadata available for
the whole is an interesting source for metadata about a component. Not only is the enclosing object a source,
also the sibling components can provide relevant metadata (also look at [29]). For example,
one slide in a slide show often gives relevant context about the content of the
next slide.
This could be
considered as a special case of document context, namely “aggregation related
context”. It also closely relates to the issue of “content packaging”. Therefore
in the future we will look at things like SCORM Content Packages and IMS
Content Packaging.
The first category is rather
straightforward to understand and does not need much further explanation. The third and fourth are not yet further
investigated by us. Therefore we will not elaborate on them here. We are however
in the process of also dealing with those kind of metadata sources in our
framework. The second category, the context analysers, is worth some more
explanation.
2.3
Context
analysers
Learning objects can be used in
several contexts; each context contains metadata that might be usable for the
automatic indexers. Some typical context
types we can observe are:
·
Creator profiles
In
[4], we classified this indexation as profile-based indexation. Every learning
object is authored by one or more people.
Quite often information about these people is available from different
sources. A creator or indexer profile groups this information, so that it can
be used when generating metadata for a document of that person.
Those
profiles can both be generated manually and automatically. In the manual case,
the user provides some pre-filled templates with information that is likely to
be correct for most of the learning objects.
The
profile can also be filled in (semi-)automatically. At the K.U.Leuven, for
example, course information for each teacher is available on websites and
personnel information is available in the administrative SAP backbone. Course information
includes metadata about the audience of the course, the language in which the
course is taught, the duration of the sessions, and so on.
·
Learning content management systems
If
learning objects are stored together with their metadata, available metadata
can be used as a source for newly introduced learning objects. This information is typically used if the new
object is related to another object already stored in the system (as a new
version of the existing one, for example) [3].
Moreover, similarity searches [4] can be used to search for similar
objects in the system, so that their existing metadata can be used to create
new metadata.
·
Learning management systems
Learning
management systems can provide rich contextual information, like the courses in
which the object is used, how many times the document was used or downloaded,
etc. As such, it actually does both document context analysis and document
usage analysis.
3.
Different
sources – different values
Relying on different sources of
metadata augments the process of generating metadata automatically. However, the sources may generate different
values for the same metadata element. In
this section, we present the options we have to overcome this problem. First we discuss the need for “correct”
metadata, without requiring a formal approved metadata set for each learning
object. Then we present four options in
solving conflicts between indexers.
3.1
Correctness
of metadata
In the first
implementation of the ARIADNE Knowledge Pool System, we used to distinguish
between validated and unvalidated pedagogical headers or metadata instances. A newly introduced metadata instance for a
learning object was given the status ‘unvalidated’ and only validators could
change the status to ‘validated’.
Validation was a process of checking the metadata values for their
correctness. If some of the values in
the metadata were incorrect, the validator could change those values or the
original indexer had to modify them. Note that the validation process did not
focus on the learning object, but rather on the metadata [10].
Quite quickly,
however, it became clear that this system did not work as expected. Only
validated learning objects could be used in the ARIADNE system, other objects
would not be included in the results to queries. So, any user that introduced
new material had to wait until validation before it could be deployed in a
course. A certain pressure was put on
the validators to do their job quickly, but probably also inaccurately.
The same problem arises
in other systems, even if those systems spend a lot of effort on the validation
process. For example, the Merlot [18]
system uses peer review for their contents, but only about ten percent has been
reviewed: in the Science and Technology category 465 of 4536 documents had a
peer review record associated in the database at the time of writing.
The question we ask
ourselves is whether metadata can be incorrect.
The difficulty is that we cannot define correctness in terms of right or
wrong in case of metadata – or at least not for all metadata elements. Of course some values may be “better” than
others, but that does not necessarily imply that the latter values should not be
used.
3.2
Conflicts
between indexers
The framework we present
in the next section uses different classes of indexers that can work in isolation from each other. Each indexer generates values for some
metadata elements, and as such a subset of a metadata set. These subsets have to be combined into one
resulting metadata record for the learning object.
The subsets of
metadata that different indexers generate can overlap. In this case, there may arise a conflict
between the indexers, that has to be solved.
There are several strategies to solve the conflicts; depending on the
element, one strategy might work better than another:
1.
Include all the generated values in the resulting
metadata set,
2.
Propose the options to the user and let him/her decide
which one to use,
3.
Try to find out which indexers are the most likely to
be correct and use their value in the result,
4.
Apply heuristics to decide on the value.
The first option –
including all the values in the resulting set – is the easiest to implement and
might be feasible for some metadata elements.
For example, a list of concepts could contain all the keywords extracted
by several indexers. In some systems, however,
the metadata set is strictly defined so we cannot implement this as an overall
strategy for all the elements.
The second option
could be used in a small system with only a low number of new entries per week
or month. In larger systems, however, we
would loose all the benefits of automatic indexing as the user has to spend
time on controlling all the values and decide which one to use.
In our opinion, the
third option is most interesting in many cases.
Every generated value will get an associated value which is the degree
of certainty of the indexer about that value. We call this value the confidence value in our framework. Every indexer determines such a value for the
metadata elements it generates. In case
of conflict, this strategy will prefer a value with a higher confidence value
over one with a lower value.
The fourth option
applies in certain cases if heuristics are known about the metadata
elements. In that case, the heuristic
will provide the solution about the conflict.
An example element for which heuristics can apply is the document
language. A lot of families of languages
exist and in those families the differences between languages might be very
small. For example Italian and Catalan
are closely related to each other but are different languages; the same applies
to Afrikaans and Dutch. If one indexer
decides the language is Catalan, the heuristic might say to use Italian. In either case, if the document is used in an
Italian or a Catalan environment, the users will understand the contents and
thus be able to use the object. Applying
Catalan for the document language however could be more precise but the value
Italian is not wrong.
4.
Automatic
Indexing Framework
The overall
structure of our framework is depicted in Figure
2. For now, the idea is that learning object metadata
can be derived from two different types of sources, which represent category 1
and 2 in section 2.2.[1] The first source
is the learning object itself; the second is the context in which the learning object is
used. Metadata derived from the object
itself is obtained by content analysis, such as keyword extraction, language classification
and so on. The contexts typically are
learning management systems in which the learning objects are deployed. A learning object context provides us with
extra information about the learning object that we can use to define the
metadata.
Following this idea, the framework consists of two major groups of classes that
generate the metadata, namely Object-based indexers and Context-based
indexers. The object-based indexers
generate metadata based on the learning object itself, isolated from any other
learning object or learning management system.
The second class of indexers uses a context to generate metadata. By working this way, the framework is easily
extensible for new learning object types and new contexts. To be complete, the framework also has some Extractors
that for example extract the text and properties from a PowerPoint-file, and a MetadataMerger
that can combine the results of the different indexers into one set of
metadata.
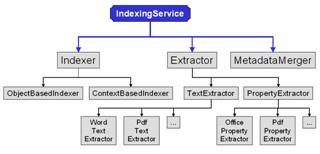
Figure 2: Overall Structure of the Automatic Indexing
Framework
Figure 3 and Figure
4 explain the hierarchies of the indexers more in
detail. Of course, these hierarchies are
extensible with other indexers.
4.1
ContextBasedIndexer
We
already explained the use of contexts for learning object indexing. There is, however, one subclass that needs
more explanation: FilesystemContextBasedIndexer. A learning object as a file is always stored
in some context of the operating system it belongs to. This class represents that file system and
contains metadata that the file system stores about the object. Depending on the file system, the metadata
attributes vary.
We
also implemented some specific LMS contexts. Currently we have classes that generate
metadata for a Blackboard document, or an OpenCourseWare object. Basically,
these classes mine the consistent context that courses in both environments
display. For example, Blackboard maintains information about the user logged in
(a reasonable candidate author of learning objects newly introduced), about the
domain that the course covers (a reasonable candidate for the domain of the
learning objects that the course includes), etc. Similarly, the OCW web site is
quite consistent in how it makes that kind of information available to end
users. Our indexer for OCW basically mines this consistent structure for
relevant metadata about the learning objects referenced in the course web site.
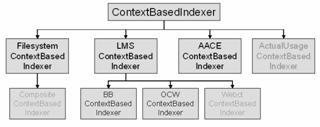
Figure 3: The Class Hierarchy of ContextBasedIndexer
4.2
ObjectBasedIndexer
These indexers often work
together with the Extractor classes, to generate metadata that is derivable
from the learning object contents.
Several specific learning object formats can be implemented as
subclasses of MimeBasedIndexer. These classes are able to deal with a
particular type of files like pdf documents.
Furthermore, there is a language
indexer, that can determine the language of a piece of text.
The ArchiveIndexer class is used
to handle bundled learning objects, such as different web pages with links
between them or pictures included.
In the future, this category of
indexers can be extended by using for example Artificial Intelligence
techniques. There exist libraries like iVia [27] that allow for things like keyword extraction,
automatic document summarization, etc. We should also look at the domain of
information retrieval to see what exists already in that domain.
The size of these classes may
vary. At the moment, most classes can
generate values for about 5 metadata elements.
Depending on the complexity to generate these values, the classes
contain only a few lines of code to several tens of lines.
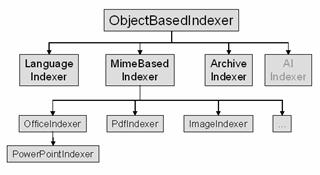
Figure 4: The Class Hierarchy of ObjectBasedIndexer
4.3
Implementing
Specific Indexers
Developers wanting to implement
their own indexer classes extend the above base classes. Indexers that handle documents or objects of a
specific type, e.g. Microsoft PowerPoint files, should extend the
ObjectBasedIndexer class. If a specific learning
object context like a specific learning management system, should be handled,
the ContextBasedIndexer is the appropriate super class. This is what we for
example did for the Blackboard LMS case, as explained in section 6. We now
briefly explain the interfaces that must be implemented to create these
specific indexers.
The overall interface Indexer
is only defined to have a general type for the different indexer classes. There are no methods defined in this
interface. It is extended by the
ObjectBasedIndexer and ContextBasedIndexer.
The method in the ObjectBasedIndexer
interface that has to be implemented is defined as follows:
public void addMetadata(
DataHandler
lo,
String
fileHandle, AriadneMetadataWithConfidenceValue metadata);
In our framework
implementation, this method is called by the indexing service which accepts a
learning object and calls the appropriate indexers to create metadata. The
first argument in the method is a reference to the learning object itself. The second argument is the file name for the
learning object, which is included as an auxiliary argument to make the
implementation easier. The last
parameter is the metadata object to which the new metadata will be added.
The class ContextBasedIndexer defines a similar method to create
metadata and another method to retrieve a reference to the learning object
within the context:
public void addMetadata(
AriadneMetadataWithConfidenceValue
metadata);
public DataHandler getDataHandler();
4.4
Using
the classes
We now briefly describe the use
of the above presented classes to generate metadata for a learning object in
some context(s). If someone wants to obtain metadata, some distinct steps have
to be followed:
1.
The user has to identify what are the object and the
contexts within which the object resides. To simplify this, we introduce a new
class, that identifies the learning object, or the context that a learning
object resides in, called a MetadatasourceId.
This top-level class is an abstract class which must be sub-classed by specific
classes for each context in which learning objects can be identified. Examples of MetadatasourceId classes are FileSystemMetadatasourceId,
BBMetadatasourceId and OCWMetadatasourceId. The last one for example identifies
the “OpenCourseWare” context of an OCW document. Concretely, this identifier is
nothing more than the URL location of the OCW document, as from that URL we can
fully identify the OCW document. The FileSystem context is the one we use to
identify the learning object in the context of the OS file system, and so in no
specific context of a LMS.
2.
The indentifying objects we just made, are then fed to
the system, which uses the identifiers to create the correct Indexer instances
for the metadata generation. The decision on which indexers are applicable for
the document is made based on the file type (for example MS PowerPoint) or
defined by the context that is provided.
3.
For each Indexer instance associated with the learning
object, the system sends a request to create metadata for that object.
4.
As described in section 3 we need conflict resolving
between different metadata instances. For now, we only implement strategy 3,
which comes down to working with degrees of certainty for generated metadata
values, and choosing the one(s) with the best confidence value. This is
implemented by the MetadataMerger and AriadneMetadataWithConfidenceValue
classes. The last one represents the metadata instance, with associated confidence
values for each metadata element. When adding an element to the instance, the
confidence values are checked. Only if the confidence value for the new element
is higher than the current one, the new one replaces the old one. Otherwise,
the old value is preserved. The MetadataMerger class can merge to existing
metadata instances into one, according to the same strategy. In next versions of the framework, we want to
make it more flexible, allowing other merging strategies as well.
5.
An
Automatic Indexing Service
We implemented the
above framework as a web service. We
briefly explain the methods of this service which we call the Simple Indexing Interface: in essence,
this is an application programmer’s interface to implement the services. This interface is being developed as a part
of our research on the development of a global framework for learning object web
services. The first initiative in this
context has led to the development of the Simple Query Interface standard [24],
a definition of web services that enable querying Learning Object Repositories in
a standardized way. Our specification
for the indexing interface closely relates to SQI and uses the same design
principles.
The different
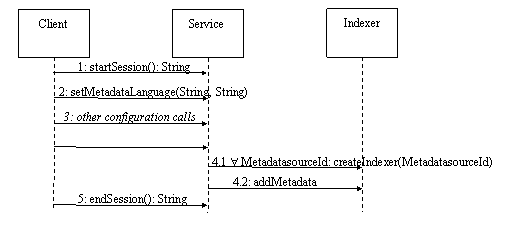
methods that should be implemented are given in Table 1. A typical
course of action is illustrated in Figure
5.
|
Session handling
methods |
|
startSession |
|
endSession |
|
Session
Configuration |
|
setMetadataLanguage |
|
setConflictHandlingMethod |
|
setMetadataFormat |
|
getSupportedConflictHandlingMethods |
|
getSupportedLanguages |
|
getSupportedMetadataFormats |
|
Learning Object
Indexing |
|
getMetadata |
|
getMetadataXML |
Table 1: Methods of the Simple Indexing Interface