Next: About this document ... Up: Monitoring the Dynamic Web Previous: Proportional vs. Uniform policy
Given a n-word document
a = {w1,
w2,...wn} and a set of
n recognized words, one can
represent q and a each as a vector of word frequencies
![]() and
and ![]() . A common measure of
similarity between two word frequency vectors
. A common measure of
similarity between two word frequency vectors ![]() and
and ![]() weighted by inverse
document frequency (idf) is the
cosine distance between them:
weighted by inverse
document frequency (idf) is the
cosine distance between them:
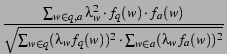 ,
,