Overview of CAM
Consider a user who is worried about a hurricane in progress and
wants to keep abreast of the hurricane-related updates. To achieve
this, he poses a continuous m-keyword query
q = {w1,
w2,...wm}. In this
section, we present an overview of the major ingredients of the CAM
approach.
Each query is submitted to a Web search engine which returns a set
of pages relevant to the queries. The returned URLs determine the
domain of pages which we will monitor. Continuing our earlier
example, we may find, say, that the National Hurricane
Center, National Weather Organization, and other
tropical cyclone sites as well as news sites are relevant. The
relevance of a page to a query can be measured by standard IR
techniques based on the vector-space model (see Appendix B for
details).
By visiting each relevant page (identified via a search engine) at
frequent intervals during a tracking period, changes to these pages
are tracked, update statistics collected, and the relevance of the
changes, vis-a-vis the queries, is assessed. This data is used to
build a statistical model of the changes to the pages relevant to a
set of queries. These statistics include page update instances,
page change frequency, and relevance of the changes to the pages
for current queries.
Let Q denote the set of all
queries submitted in the system and
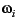 denote
the importance of
ith query. These are
input to the system. Let P denote
the set of web pages relevant to the continuous queries, Qpi be the set of queries for
which ith page is found
to be relevant, and ri,
j be the estimated relevance of ith page for jth query. It is positive for
all queries q
denote
the importance of
ith query. These are
input to the system. Let P denote
the set of web pages relevant to the continuous queries, Qpi be the set of queries for
which ith page is found
to be relevant, and ri,
j be the estimated relevance of ith page for jth query. It is positive for
all queries q
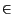 Qpi and zero for all
q Q -
Qpi. These relevance measures are
initially calculated during the tracking period (and get updated
continually, as explained later).
Qpi and zero for all
q Q -
Qpi. These relevance measures are
initially calculated during the tracking period (and get updated
continually, as explained later).
It is clear that not all pages will be equally important for
each query in the system. So we rank the pages by assigning a
weight to each page using its relevance for queries. The
weight of a page, computed as
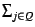 (
(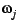 ri, j), denotes
the value of current version of the page. If the page gets updated
before its current version is monitored, we assume that we
incur a loss of Wi.
ri, j), denotes
the value of current version of the page. If the page gets updated
before its current version is monitored, we assume that we
incur a loss of Wi.
CAM does its monitoring in epochs. Each
epoch has duration T. The purpose
of resource allocation is to decide how
to allocate a limited number of monitoring tasks for an epoch and
the goal of scheduling is to decide
when each allocated task should
execute, given the resource allocation decisions. Monitoring is
done by a monitoring task which fetches a specified page from its
source, determines if it has changed and, if so, propagates the
effects of these changes to responses of affected queries.
Let C denote the total number
of monitoring tasks that can be employed in a single
monitoring epoch. C is derived as
an aggregation of the resources needed for monitoring, including
CPU cycles, communication bandwidth, and memory. E.g., Heydon and
Najork [9] report that with two 533MHz
Alpha processors, 2GB of RAM, 118GB of local disk, a 100Mbit/sec
FDDI connection to the Internet, their crawler (Mercator)
downloaded 112 documents/sec and 1,682 KB/sec (on an average).
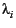 is the
estimated number of changes that occur in page i in T
time units. Henceforth we will call it the change
frequency for page i.
Suppose Ui denotes the
sequence of time instances
ui, 1, ui,
2,..., ui, pi at which the tracking
phase determines that possible updates occur to page i. We assume
0
is the
estimated number of changes that occur in page i in T
time units. Henceforth we will call it the change
frequency for page i.
Suppose Ui denotes the
sequence of time instances
ui, 1, ui,
2,..., ui, pi at which the tracking
phase determines that possible updates occur to page i. We assume
0 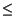 ui, 1
ui, 2
... ui,
pi T,
ui, 0 = 0, and
ui, pi = T.
pi is the total number
of update instances for ith page during T, i.e., cardinality of sequence Ui (pi=|
Ui|).
ui, 1
ui, 2
... ui,
pi T,
ui, 0 = 0, and
ui, pi = T.
pi is the total number
of update instances for ith page during T, i.e., cardinality of sequence Ui (pi=|
Ui|).
Note that a page may not be updated at these time instances and
so there is a probability
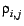 associated with each time instance ui, j that denotes the
chances of
ith page being updated
at the
jth instance. The
overall goal of the resource allocation and scheduling phases is to
monitor in such a way that the monitoring events occur just after
updates are expected to take place. The number of missed updates is
an indication of the amount of lost information and minimizing this
is the goal of the system.
associated with each time instance ui, j that denotes the
chances of
ith page being updated
at the
jth instance. The
overall goal of the resource allocation and scheduling phases is to
monitor in such a way that the monitoring events occur just after
updates are expected to take place. The number of missed updates is
an indication of the amount of lost information and minimizing this
is the goal of the system.
With these considerations in mind, decisions are made about the
allocation of a given number of monitoring tasks among a set of
relevant pages while also deciding the best instant when these
allocated tasks should occur within an epoch. The basic idea is
that these monitoring epochs of length T repeat every T units of time and we will make
decisions pertaining to the monitoring tasks to be carried out in
one monitoring epoch using both new data and the results from the
previous epochs.
It should be clear that if we decide to monitor at some instant,
then it should be at the potential update time instant only because
there is no reason to delay it beyond when a update might occur. If
the number of monitoring tasks allocated for a page is equal to the
number of update instants, then we can always maintain a fresh
version of this page by monitoring at all possible update instants.
But in practice, we will not be able to perform as many monitoring
tasks as the number of update instants. So we need to pick a set of
update instants at which the page is to be monitored and not at
others. Hence with every update time instant, we associate a
variable yi, j where
yi, j = 1 if the
ith page is monitored
at time ui, j, and
0 otherwise. If we monitor the
ith page xi times, then
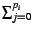 yi, j =
xi. The resource allocation phase decides
yi.j values, that is,
the time instants at which monitoring should be done given that the
tracking phase has identified the time instants when changes may
occur.
In the scheduling phase, we take the yi, j values as inputs and
prepare a feasible schedule to meet our optimization measures. In
practice, we have a set of M
parallel monitoring processes which continuously perform these
monitoring tasks. Now our goal is to map a monitoring task
to one of these M parallel
monitoring processes and determine its time of invocation. While
determining any schedule, our aim is to minimize the total delay
occurring between the ideal time instants and the actual scheduled
time instants. The scheduling step involves taking the ideal
timings for the monitoring of each page and obtaining an optimal
achievable schedule out of it. We map this problem to
flow-shop scheduling problem [15]
with the goal of minimizing the average completion time.
Next we monitor these pages according to the designed schedule and,
at the end of the current monitoring epoch, update the statistics
of these pages on the basis of the observations made during the
current epoch. In general, based on the results of monitoring tasks
of an epoch, scheduling, resource allocations, change statistic
computations, and page relevance can all be revisited. These, as
mentioned earlier, correspond to the arcs going from the monitoring
phase to the earlier phases of Figure 1.
Sandeep Pandey 2003-03-05
yi, j =
xi. The resource allocation phase decides
yi.j values, that is,
the time instants at which monitoring should be done given that the
tracking phase has identified the time instants when changes may
occur.
In the scheduling phase, we take the yi, j values as inputs and
prepare a feasible schedule to meet our optimization measures. In
practice, we have a set of M
parallel monitoring processes which continuously perform these
monitoring tasks. Now our goal is to map a monitoring task
to one of these M parallel
monitoring processes and determine its time of invocation. While
determining any schedule, our aim is to minimize the total delay
occurring between the ideal time instants and the actual scheduled
time instants. The scheduling step involves taking the ideal
timings for the monitoring of each page and obtaining an optimal
achievable schedule out of it. We map this problem to
flow-shop scheduling problem [15]
with the goal of minimizing the average completion time.
Next we monitor these pages according to the designed schedule and,
at the end of the current monitoring epoch, update the statistics
of these pages on the basis of the observations made during the
current epoch. In general, based on the results of monitoring tasks
of an epoch, scheduling, resource allocations, change statistic
computations, and page relevance can all be revisited. These, as
mentioned earlier, correspond to the arcs going from the monitoring
phase to the earlier phases of Figure 1.
Sandeep Pandey 2003-03-05