We propose using the document structures of Web pages to identify keywords representing the topic of each page returned by a search. The topics of the pages are represented by the positions of the keywords on the pages, and these "topic structures" are used for a more specific search. We developed a system that automatically formulates multiple queries by incorporating different topic structures into the user's input keywords, finds queries that yield the most different search results, and displays the results to the user for comparison. This helps users structure queries with topic structures appropriate for their information needs. We also developed a method for identifying keywords that represent the subject by statistically comparing the frequencies of keywords in sets of Web pages with different topic structures. This enables users to formulate more detailed queries according to their interest.
Web search, Topic structure, Query structuring, Web mining
Keywords on different parts of a Web page generally play different roles in describing the topic. Keywords in the title likely represent the overall subject, while those in the body likely describe the subject in detail. Web pages that have the same keywords, e.g., ![]() and
and ![]() , but in different positions, should be treated differently based on this difference.
, but in different positions, should be treated differently based on this difference.
Web pages written in HTML have document structures, and several search engines provide functions for using these structures in a Web search. Google[1], for example, provides several operators for modifying a search. We can make different queries from the same keywords by using these operators. For example, consider two keywords, ![]() and
and ![]() . The query
. The query
![]() looks for
looks for ![]() in the title and
in the title and ![]() in the body, and the query
in the body, and the query
![]() looks for
looks for ![]() in the title and
in the title and ![]() in the body.
in the body.
Queries with different structures often yield different search results. When we enter
![]() and
and
![]() (original keywords are Japanese), both queries result in dozens of URLs, none of which appears in both sets. The results of the two queries not only have different URLs but also different topics. When "plastic" is required in the title, many pages for environmentally friendly products, such as decomposable plastic, are retrieved. On the other hand, when "environmental protection" is required in the title, pages arguing the use of plastic from the point of view of environmental protection are returned.
(original keywords are Japanese), both queries result in dozens of URLs, none of which appears in both sets. The results of the two queries not only have different URLs but also different topics. When "plastic" is required in the title, many pages for environmentally friendly products, such as decomposable plastic, are retrieved. On the other hand, when "environmental protection" is required in the title, pages arguing the use of plastic from the point of view of environmental protection are returned.
Based on these observations, we propose representing topic structures by specifying the positions of keywords on the page and using these structures to search the Web.
If queries with different structures yield different search results, displaying these results for comparison can help users select appropriate queries. We developed a system that automatically generates multiple queries from the user's input and finds those that yield the most different search results.
The system works as follows:
1. The user inputs a bag of keywords, e.g.,
![]() .
.
2. The system composes queries with different structures,
![]() , by specifying the positions of the keywords.
, by specifying the positions of the keywords.
3. The system submits each query, ![]() , to a search engine and for each query obtains
, to a search engine and for each query obtains ![]() , which shows the URLs of the top
, which shows the URLs of the top ![]() results for that query.
results for that query.
4. The system selects ![]() URL lists that minimize
URL lists that minimize
![]() and satisfy
and satisfy
![]() , where
, where ![]() and
and ![]() are the parameters and
are the parameters and
![]() .
.
5. The system displays the URL lists and corresponding queries to the user for comparison.
Our system divides Web pages containing the same keywords among different topic structures, which helps the user find information of interest from the search results. This is a kind of query structuring. While existing research on query structuring has dealt with the problem of searching Web databases[2], our system is aimed at supporting general Web searches.
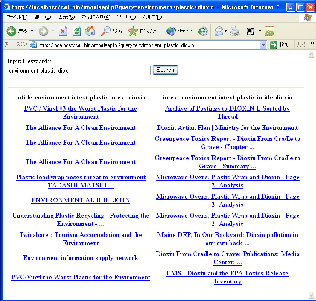
Figure 1 presents a sample screen of a prototype of our comparative topic presentation system. The system formulates queries by dividing the user's input between the title and the text and obtains the URLs by using Google Web APIs[3]. The results of the two queries yielding the most different results are shown to the user.
Many pages on the Web deal with the same subject but have slightly different descriptions. A search engine will usually return a long list of these similar pages. It can be a tedious and time-consuming task for the user to examine these pages one by one. If the system presented keywords detailing the subject, the user could more readily grasp the topics of the pages and use them for a more detailed search. Thus, rather than looking for merely "related" keywords, we look for keywords that can be used for "detailing" the current subject. To identify such keywords, we need a criterion for distinguishing keywords that detail the current topic from keywords that broaden the topic. We use document structures to form this criterion.
Given Web pages that contain keyword ![]() in the title, keywords that frequently appear on these pages are probably used for describing the subject
in the title, keywords that frequently appear on these pages are probably used for describing the subject ![]() . Here we compare two types of co-occurrence rates:
. Here we compare two types of co-occurrence rates:
- The rate of pages containing keyword ![]() among pages containing keyword
among pages containing keyword ![]() .
.
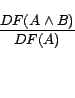
|
(1) |
- The rate of pages containing keyword ![]() among pages containing keyword
among pages containing keyword ![]() in the title.
in the title.
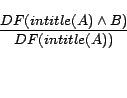
|
(2) |
Table 1 shows keywords for detailing "hungary" (The original keywords are Japanese). We submitted the query
![]() to Google and downloaded the first 50 pages. We extracted nouns from these pages using a Japanese morphological analysis system, ChaSen[5]. We compared the values of rates (1) and (2) by submitting queries
to Google and downloaded the first 50 pages. We extracted nouns from these pages using a Japanese morphological analysis system, ChaSen[5]. We compared the values of rates (1) and (2) by submitting queries
![]() and
and
![]() to Google through Web APIs. We found words used for describing Hungary, such as the name of the currency, the ethnic name of the Hungarian people, and places in Hungary. The results indicate the effectiveness of using document structures to identify keywords that detail the given subject.
to Google through Web APIs. We found words used for describing Hungary, such as the name of the currency, the ethnic name of the Hungarian people, and places in Hungary. The results indicate the effectiveness of using document structures to identify keywords that detail the given subject.
| B |
|
|
| budapest | 0.263172 | 0.119802 |
| danube | 0.110484 | 0.055941 |
| forint | 0.086828 | 0.015545 |
| buda | 0.059409 | 0.013069 |
| palace | 0.058065 | 0.029307 |
| magyar | 0.043011 | 0.018713 |
| matyas | 0.026075 | 0.009822 |
| foundation | 0.025806 | 0.020099 |
| night view | 0.023387 | 0.017327 |
| plain | 0.019355 | 0.012277 |
| A=hungary | ||
We propose representing topic structures by specifying the positions of keywords on the page and using these structures for searching the Web. Our system helps a user find queries appropriate for his/her information needs by displaying the structured queries that yield the most different search results. Moreover, keywords detailing the given topic can be identified by statistically comparing the frequencies of keywords in sets of Web pages with different topic structures. The user can then formulate more detailed queries using these keywords.
We plan to develop a faster algorithm for finding queries yielding the most different search results. We will also experimentally compare our method with other approaches [6][7] to deriving term hierarchies.
This research was partly supported by Grants-in-Aid for Scientific Research (14019048 and 14208036) from the Ministry of Education, Culture, Sports, Science and Technology of Japan, by a grant from the New Energy and Industrial Technology Development Organization (NEDO), and by the 21st Century COE Program at the Graduate School of Informatics, Kyoto University.