Figure 1.
Marek Hatala
|
Steven Forth
|
In this paper, we describe a system that generates suggested values for metadata elements. The system significantly increases the productivity of metadata creators as well as the quality of the metadata. Instead of aiming for automated metadata generation we have developed a mechanism for suggesting the most relevant values for a particular metadata field. The suggested values are generated using a combination of four methods: inheritance, aggregation, content-based similarity and ontology-based similarity. The main strength of the system is that it provides a generic solution independent of the metadata schema and application domain. In addition to generating metadata from standard sources such as object content and user profiles, the system benefits from considering metadata record assemblies, metadata repositories, explicit domain ontologies and inference rules as prime sources for metadata generations.
Metadata systems, Metadata generation, Ontologies, Knowledge-based systems, Semantic web, IEEE LTSC LOM, SCORM
One of the main obstacles to the widespread adoption of systems which make intensive use of metadata (MD) is the time and effort required to apply MD to multiple resources and the inconsistencies and idiosyncrasies in interpretation that arise when this is a purely human activity. A typical three-hour course may be composed of several dozen content objects each of which may have several included media elements. When applying current MD standards, the MD creator has to fill anywhere from 1,000 to 5,000 separate MD values for a three hour course [1].
This problem is not limited to learning resources. Recent studies [2] show increased awareness of the importance of creating MD for objects even in industrial settings, despite worries about the quality of the MD [3]. As number of elements and requirements for richly structured MD sets increase the need for systems that support MD generation and management will grow. The system presented in this paper helps MD creators to create high quality MD by allowing them to select values from generated sets of suggested values (SSV) for MD fields.
Our system for suggesting MD values considers different types of MD records and MD element types. We recognize the following sources of MD records.
The elements of MD schemas can hold different types of values. We consider the following types:
The work presented here concentrates on generating sets of suggested values (SSV) for MD elements in records representing objects in assemblies and repositories, i.e. suggesting values for MD elements from the 'similar' objects. The four methods described below use four different notions of similarity. Each particular method can be applied only to those MD elements which exhibit the corresponding notion of similarity. The classification of elements for IEEE LOM standard into four categories is reported in elsewhere.
Inheritance. This method is applicable to the MD records of objects organized into assemblies and aggregations. The SSV for the MD element consists of the values from the same MD element in the predecessor records in the hierarchy. For assets in the aggregations, a SSV generated through the inheritance is a union of SSVs for their aggregate and MD values of the particular element for the aggregate object.
Accumulation. This method works uniformly through assemblies and aggregations. The SSV for MD element is an accumulation of values from the subordinate records in the hierarchy.
Content Similarity. The content similarity method makes use of all accessible MD records in the repository. A SSV for the elements exhibiting this property is calculated as the union of element values from MD records of objects exhibiting content similarity with the object under consideration.
|
|
Figure 1. |
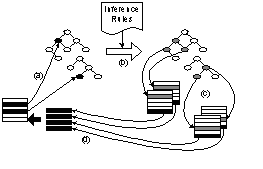
Semantically Defined Similarity. Semantically defined similarity is the most powerful and complex of the methods presented. This method operates purely on MD records in the repository and takes into consideration both MD element values of finalized records as well as the values in the record being created. Figure 1 demonstrates the main principle. Based on already filled values (mapped to ontology) in the MD elements in the current record (a) one or more of the inference rules are triggered (b). The inference rules calculate the values for a set of MD elements which characterize similar records (c). The similar records are retrieved and a SSV for another element(s) is generated as a union of values from the similar records (d).
This method is most suitable for elements which use vocabularies derived from formal ontologies. The set of inference rules then operates on the ontologies and uses powerful inference techniques such as forward chaining or constraint satisfaction. This method is most suitable for customized MD systems (MD profiles) as standards typically provide vocabularies in only a limited form. Customized MD systems can add elements significant for a particular domain and define domain ontologies and domain specific inference rules.
Combination of SSVs. The four methods above generate four SSVs. The final set of suggested values is a combination of all four sets. It is possible, that not all components in the formula above will be present for each element. If more than one set is present, it would be desirable to consider a weighting of values originating from different sets.
In the current version, we have implemented only three of the above methods of generating MD: inheritance, accumulation and semantic similarity. The implementation of inheritance and accumulation method was fairly straightforward. We have based the implementation of the semantic similarity method on DAML+OIL ontologies and used a set of publicly available tools: ontology editor OilEd and DAMLJessKB inference engine and rules. We have found the use of a forward-chaining inference engine favorable over backward-chaining as it allowed us to do the required inference offline and store the results in the lookup table used during the generation tasks.
Our work continues in several directions. We are in the process of plugging in a content similarity component. We are also experimenting with the data mining and machine learning techniques to discover the rules to be used by for the semantic similarity method.