The task of creating customized spoken dialog applications has traditionally been known to be expensive, requiring significant resources and certain level of expertise. This is clearly an obstacle in porting and scaling dialog systems. In this paper, we describe WebTalk, a system that automatically creates spoken and text-based dialog applications by mining and leveraging the vast amounts of information already built into companies websites. WebTalk has been used to create five dialog applications from different websites.
Spoken dialog services, webpage segmentation, website structure, information classification, structured task knowledge base
Spoken dialog systems provide individuals and companies with a cost effective
means of communicating with customers. Some examples of successfully deployed
spoken dialog systems include HMIHY[5], UBS Voice and United Airlines Automated
Voice Service. These systems operate in very specific domains, and require
extensive human knowledge and expertise for construction and maintenance. The
involved human efforts include collecting task data, designing task oriented
rules, and training task specific models for various components in a dialog
system. For these barriers, many companies are hesitant to peruse such a
cost saving service.
In this paper, we describe WebTalk -- a system for automating the creation of spoken dialog services using data on company websites. Almost every company has at least one website that outlines its products or services and provides online customer service. In order to have its customers get online information in a timely, effective and efficient way, months-long effort has been invested in analyzing the backend application database, extracting application logics, carefully designing the dynamic interactions in web environment and the screen presentation. Textual data on the web pertaining to a product or a service has been created to be in a human readable form. WebTalk is trying to absorb task knowledge from these resources and enable those companies, which have already set up their websites, to serve their customers with a spoken dialog interface either over the phone or through the Internet. Further, WebTalk is able to synchronize the spoken dialog service simultaneously with the updates on the website.
However, a website doesnt contain structured dialog-oriented task
representation, in-domain real conversation data, and in-domain speech data,
which are requisite for building an application-specific dialog system using our
current approaches. As a result, the goal of WebTalk brings new challenges for
our current dialog technology and web document processing. This paper will
discuss these challenges and our effort for solving them.
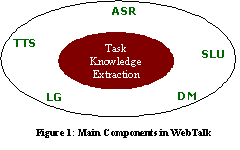
WebTalk follows a general paradigm for spoken dialog systems [8]. A typical spoken dialog system consists of five major components, namely, Automatic Speech Recognition (ASR) engine, Spoken Language Understanding (SLU) module, Dialog Manager (DM), Language Generation (LG), and the Text-To-Speech synthesizer (TTS). As figure 1 shows, WebTalk has a new component: Task Knowledge Extraction, which automatically learns dialog oriented task knowledge by exploiting the content & structure of the given website.
The input of this component is a list of html documents from a given website.
It outputs structured task information and a multi-level free text tree.
Extracting structured task information involves locating acronyms and their
definitions, extracting prepared questions and the associated precise answers,
identifying product and service names, determining their mutual relationship,
and collecting product & service attributes such as product description,
service definition, price, and how to buy. With this structured task knowledge
tree, WebTalk is able to efficiently provide help on a big part of users
common requests.
The multi-level free text tree is a container for free text chosen from the
website, excluding short non free text segments such as menus, page titles,
tabular data and copyright declarations. This tree includes three types of
nodes. Each leaf node corresponds to a textual information unit on one page. An
information unit is either a coherent topic area according to its content or a
coherent functional area according to its behavior. An information unit is also
often a visual block displayed in Internet browser. The last second level nodes
correspond to pages. Each of the rest nodes is associated with a website
directory such as www.att.com/local and
contains an alias and a summary passage of this directory. WebTalk uses this
tree to produce information retrieval dialog and help determine dialog context.
For instance, when a leaf node under product & service directory is
chosen to answer a users question, the system will decide this users
interest is related product or service category.
For implementing this complex task, WebTalk employs website structure analysis, web page structure analysis, and information extraction (IE). The website structure means how web documents are physically organized and their hyperlink relationship. For analyzing web pages, WebTalk applied SVM to segment a web page to smaller information units (IU), and then classify IUs in terms of their visual functions to 8 categories: page title, menu, web form, information list, database-like data area, topic, common information description and garages. In our preliminary experiments, 82% of IUs can be correctly separated from its environment. 96% of IUs can be correctly classified. These IUs are organized into the free text tree for producing information retrieval dialog. For extracting structured product & service information [6], we use multiple Information Extraction (IE) techniques including format description for structured text, Wrapper Induction for semi structured documents [7] and Pattern Learning methods for free text [4]. This task is still ongoing. Detailed experiments will be described in the future.
The speech recognizer we use in WebTalk is the AT&T Watson ASR engine [1]. The website-specific language model is built by combining task-related key terms extracted from the given website with a generalized language model for help-desk conversations. The challenge is how to build a task oriented ASR using only web data, how to compensate for the absence of real human-machine dialogs and learn a language model that reflects the characteristics of human machine interactions.
Dialog Manager (DM) is responsible for making decisions about how the system should reply to user input. DM is the center part of a dialog system and at the same time a component which requires the most handcrafted work including predicting all possible dialog states and designing associated actions and responses for each state. Inventing a web data driven DM framework applicable to various domains is a critical challenge for WebTalk. Our current applied approach to the DM of WebTalk is summarized as the following: (1) Decompose predictable dialog flows to sub dialogs, which are task independent and implemented previously by human. Sub dialogs need input parameters and often generate return values. (2) When interacting with a user, DM determines which sub dialog should be activated and feeds the sub dialog process with required parameters. These decisions rely on dialog context and the semantic interpretation from LU for the latest user request.
Traditionally, language understanding is a rule-based component that converts natural language sentences into a semantic representation. For a new application, the set of handcrafted rules needs to be rebuilt with special expertise and with sufficient task analysis. In WebTalk, language understanding is required to work automatically to fit various tasks, based on web data alone. Hence, a data-driven language understanding component is clearly needed. Currently this component has the following capabilities:
(1) Providing a semantic representation, when users input is independent of task or can be answered using structured task knowledge.
(2) Using an extended information retrieval (IR) engine to produce a ranked
list of IUs or help prompts relevant to users requests.
Language generation in the current WebTalk either uses sentence patterns to translate the feedback from DM to spoken natural language or simply reedits the returned passage by replacing or deleting words which are already written in natural language but only useful for GUI.
The synthesizer we use in WebTalk is the AT&T TTS system [2].
This paper describes WebTalk, a general framework for automatically building spoken dialog services from a given website. Its main components and fronting challenges have been discussed in this paper.