Ralf Klamma
RWTH Aachen, Informatik V
Ahornstr. 55
D-52056 Aachen, Germany
klamma@cs.rwth-aachen.de
Marc Spaniol
RWTH Aachen, Informatik V
Ahornstr. 55
D-52056 Aachen, Germany
mspaniol@cs.rwth-aachen.de
Matthias Jarke
Fraunhofer FIT
Schloss Birlinghoven
D-53754 Sankt Augustin, Germany
jarke@fit.fraunhofer.de
The design of knowledge management systems depends on a tight interplay between organization of digital media and communicative processes within communities of practice. In Germany's first interdisciplinary and collaborative research center on "Media and cultural communication" we are studying the impact of media theoretical concepts named transcription, localization, and (re-) addressing on the design of digital media knowledge management systems. Furthermore, we examine the opportunities given by new metadata standards like MPEG-7 for digital media management in terms of automated processing, evaluation and presentation of both community knowledge and communication processes. Exemplarily, we want to introduce our Virtual Entrepreneurship Lab (VEL) as an digital media knowledge management environment.
Knowledge and management do not fit prima facie. Management aims at goal-oriented action while in many sciences, especially in the humanities, knowledge and the creation of knowledge have a discursive nature. This process of knowledge creation, interpreting and discussing selected observed or postulated phenomena, is leading to some progress but hard to control. It is important to recognize that the process needs a tight interplay between communicative acts and the organization of knowledge. Furthermore, this can only happen in the context of certain media combinations. The key ability of computer science to re-combine digital media justifies why computer science deals with digital media management. The key point is simple: it is impossible to develop and debate concepts separately from the media through which they are communicated. This appears to argue strongly against the possibility of purely abstract conceptual modeling or ontology building, without explicit consideration how these ontologies are captured and communicated via media.
The first aspect of our conceptual framework are three knowledge operations on media called transcription, localization and (re-) addressing developed in the context of studying media operations from a cultural sciences perspective [2] which has applications in cooperative knowledge management (KM) [3]. For a short overview the operations are defined as follows:
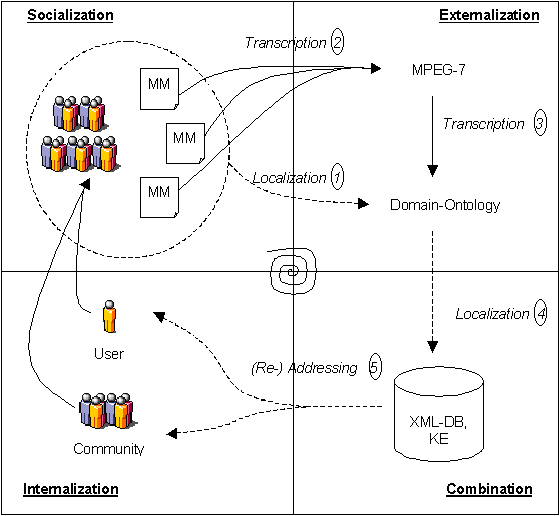
Second aspect of our conceptual framework is the well-known knowledge management approach of Nonaka and Takeuchi [5] developed to analyze the transformation of implicit and explicit knowledge. We have combined the knowledge transformation approach with the community of practice (CoP) approach by Wenger [6] to capture the discursive nature of knowledge creation and add the media specific operations to the new framework of digital media knowledge management (cf. figure 1).
Figure 1:
Digital media knowledge management in CoP
The diversity of media allows learners to select versatile information from various sources. Especially the usage of new media allows an even faster access and complex structuring of the information. Text and multimedia databases are approaches to handle these information sets in a more or less unstructured manner. Multimedia databases lack a structuring of information since documents are basically annotated for a subsequently retrieval. Ontology-based KM systems are often too restrictive and fail representing the discursive nature of knowledge. Therefore, we combine the benefits of both by simultaneously reducing their deficits.
The MPEG-7 standard [4], introduced by the moving pictures expert group (MPEG), specifies a set of descriptors and description schemes that permit the transcription of versatile multimedia information for a variety of web applications. The XML-based MPEG-7 standard allows (loose) categorization of new content from different sources and types. In contrast to strict classification of data in ontology-based systems, the idea of multimedia concepts is the more or less unclassified handling of information. Therefore, the metadata used for semantic enrichment of multimedia concepts is based on the fact that knowledge transfer has to be analyzed with respected to the medium. Based on a total view on all multimedia (MM) files to be covered a localized (1) ontology-like MPEG-7 schema is being developed (cf. figure 1). In contrast to structures of ontology-based systems the underlying ontology is being interpreted (transcribed (2)) with the graph description tools compatible to MPEG-7. Transcription (3) of MM files can be done straight forward in the range of MPEG-7 free text annotation tags. That allows us to combine the advantages of a loose categorization with the concepts of metadata annotations, as it is needed for the tight interplay between the organization of knowledge and communicative processes within the CoP. Thereafter, all information is stored localized (4) for the CoP in a XML database with respect to the domain ontology which can be conceptualized as the shared vocabulary of the CoP. It is accessible to all users in final (re-) addressing (5) processes for the CoP as a shared learning history or as identity building learning process [6].
The Virtual Entrepreneurship Lab (VEL) is a joint development of Lehrstuhl Informatik V and Fraunhofer FIT institute. It is based on a project called "`Berliner sehen"' [1] from the MIT (Massachusetts Institute of Technology) and transferred to entrepreneurship education. Starting from a constructivistic point of view, it represents an interactive learning environment combining the advantages of metadata standards as MPEG-7 and meta information languages as XML.
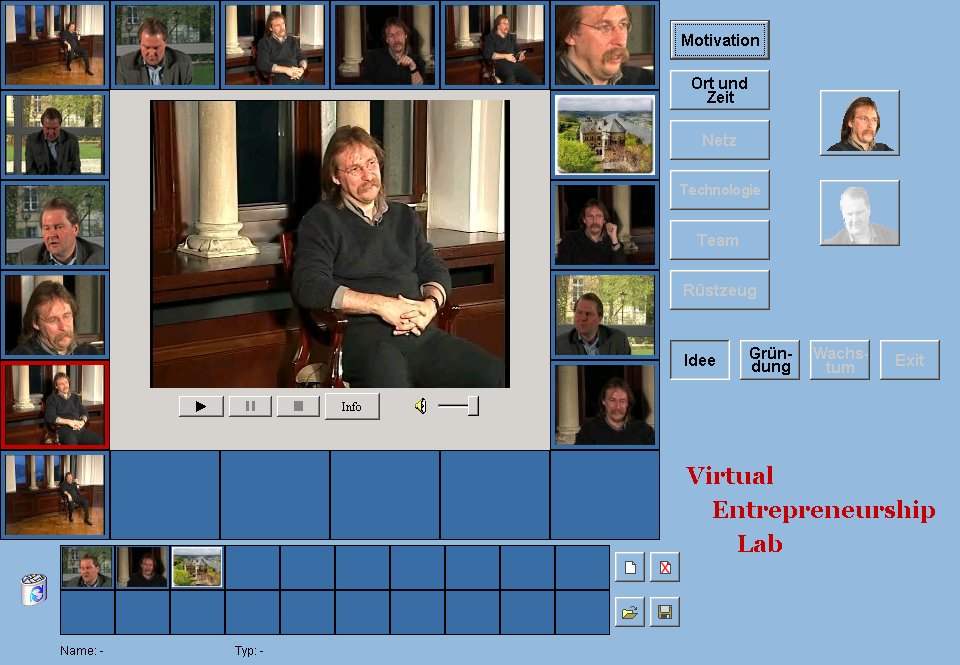
Figure 2: Entrepreneurship e-learning platform for CoP
The VEL represents a hyper dimensional multimedia knowledge management platform. To the right of figure 2 there is a three-dimensional categorization schema, which allows loose filtering of the presented content. The three dimensions are predefined and segregate the parameters time (the different phases of the founding process), person (selection of a specific person, who acts as a founder), and skills (browsing aspects of relevant founders' skills). The thumbnails in the circular overview vary related to the chosen category. Dragging them from its position and dropping them in the middle select them. In case of movie data the user can watch the video. Besides, all annotations concerning the media file are now accessible for a better understanding of the situational background. By highlighting the appropriate buttons depending on the context of the selected media, the user shall be encouraged to investigate other entrepreneurial aspects associated with the media file. At the bottom of the user interface there is a screen element where the user can maintain collections. Collections can be seen as an approach to focus on a certain aspect: combining and customizing media files and compounding this view on single media components with additional, issue-related information. On server-side we have set up an Apache web server situating an XML-database, that contains metadata compatible with MPEG-7 on the digital content and associated collections. By storing those data compatible with MPEG-7 our content can be easily transferred to and from other MPEG-7 based applications. Additionally, a description definition language provides a syntax to combine, express, extend and refine descriptors. Possible variations allow MPEG-7 based systems to be easily adapted for specific requirements. Especially, the modification of the nesting rules of arguments permits the creation of a tree-hierarchy similar to structures in ontology-based systems. Even more, user requests can be processed via the world wide web, e.g. by XQuery, since MPEG-7 is XML based. As a result of the user's request an XML-file containing the specific information is send to the client. It contains the concerning metadata of the digital content to be presented in the Java-based MPEG-7 player.
For best exploitation of metadata information in our software applications we are currently researching on accessorily options MPEG-7 offers. Therefore, an integration of the extensible style sheet language transformation (XSLT) in the VEL is currently being studied. Regarding the user's preferences and his history in the learning process it will become possible to present documents individually and to focus on the most improbable knowledge subject. Due to modifications done by XSLT, a personalized content presentation will be possible without any other manipulation in a transcribed MPEG-7 file. Generally spoken, the MPEG-7 metadata standard allows a comprehensive content description and a semantic coding of multimedia information. This is necessary, since efficient retrieval techniques for VEL like environments that integrate heterogeneous information are needed. However, annotation and handling of non-linear materials has still to be done manually to achieve a high quality of the multimedia content. In this aspect the domain knowledge about entrepreneurship education has strongly influenced the content editing.
In this poster we presented and discussed current approaches on digital media knowledge management realized with the MPEG-7 standard. The usage of XML and MPEG-7 supports the transcription processes in a transparent and flexible way. In making digital media compatible to the MPEG-7 standard, structural improvements can be accomplished in a convenient manner. Also the coupling of ontology-based information systems with metadata enriched multimedia files can be achieved and multimedia retrieval techniques can also be deployed. Further studies will be necessary to develop efficient retrieval techniques for both ontology-based data structures and metadata enriched multimedia concepts.
This work was supported by German National Science Foundation (DFG) within the collaborative research centers SFB/FK 427 "Media and cultural communication" and SFB 476 "IMPROVE".
1. K. Fendt. Contextualizing content. In M. Knecht and K. von Hammerstein, editors, Languages across the Curriculum, pages 201 – 223. National East Asian Languages Resource Center / Ohio State University, Columbus, 2000.
2. L. Jäger. Transkriptivität - Zur medialen Logik der kulturellen Semantik. In L. Jäger and G. Stanitzek, editors, Transkribieren - Medien/Lektüre, pages 19 – 41. Fink, München, 2002.
3. M. Jarke and R. Klamma. Metadata and cooperative knowledge management. In Proceedings of the 14th International Conference on Advanced Information Systems Engineering, May 27-31, 2002, Toronto, Ontario, Canada, Berlin-Heidelberg, 2002. Springer-Verlag.
4. B. S. Manjunath, P. Salembier, and T. Sikora, editors. Introduction to MPEG-7: Multimedia Content Description Interface. John Wiley & Sons, Chichester, 2002.
5. I. Nonaka and H. Takeuchi. The Knowledge-Creating Company. Oxford University Press, Oxford, 1995.
6. E. Wenger. Communities of Practice: Learning, Meaning, and Identity. Cambridge University Press, Cambridge, UK, 1998.