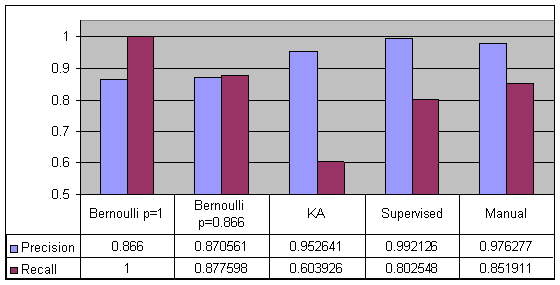
Figure 1 - Precision and Recall for Madonna
The Web today contains a treasure trove of information about subjects such as people, companies, organizations, products, etc. that may be of wide interest. A first step toward any Web-based text mining effort would be to collect a significant number of Web mentions of a subject. However, due to the infamous ambiguity of natural language, many subjects have several meanings. This is particularly true for brand names, which often derive their name from the real word. Thus, the challenge becomes not only to find all the subject occurrences, but also to filter out just those that have the desired meaning. Consider the following excerpt from the documentation of the dispute known as Madonna Ciccone, p/k/a Madonna v. Dan Parisi and Madonna.com. (http://arbiter.wipo.int/domains/decisions/html/2000/d2000-0847.html). The challenge is to distinguish which of these refers to the singer and which refers to the other entities also named Madonna: The web site featured sexually explicit photographs and text, and contained a notice stating "Madonna.com is not affiliated or endorsed by the Catholic Church, Madonna College, Madonna Hospital or Madonna the singer." By March 4, 1999, it appears that Respondent...
The ambiguity of natural language terms is a well-recognized challenge in both Information retrieval (IR) and Natural Language Processing (NLP). A large body of work in these fields can be seen as directly or indirectly related to this problem (e.g. [2][3]). In this paper we present a fully functional system that separates the on-topic occurrences and filters them from the potential multitude of references to unrelated entities. For the example above, the system would ideally be able to find occurrences of Madonna only when they refer to Madonna the singer.
Our disambiguation system is based on the classical idea that disambiguation can be achieved by relying on the presence or absence of additional terms that appear in the context of a subject. The basic premise is that the user is interested in a particular domain, which may be identified by a particular vocabulary of on-topic terms and off-topic terms. We use three different types of terms, including single words, multiple word phrases and lexical affinities (LAs) ([4]), which are pairs of terms that appear together within a fixed-size window of words, in any order.
Disambiguation is done on a particular data-set, which consists of a set of source Web-pages, a set of subjects and a set of on/off topic terms for disambiguation. Data-sets can be defined at varying granularity levels, ranging from the very narrow, e.g. a particular product or brand, to the very wide, e.g. a whole industry or set of industry-related topics. Once a data-set is defined, first a Spotter module searches for subject and on/off-topic term occurrences and tags them. Then, a Disambiguator module determines which terms appear in both the local and global contexts surrounding each occurrence of a subject. The Disambiguator scores these occurrences based on a tf*idf measure, and then determines which occurrences are on topic and which are not, using a threshold-based computation with several additional heuristics. The algorithm is implemented as part of a full application which allows easy set-up, viewing the results and fine-tuning.
Our disambiguation procedure depends on a set of high-quality on/off-topic terms. We've experimented with three methods of acquiring such terms, requiring different levels of user interaction: Knowledge Agents (KA) ([1]), supervised learning, and manual training. The KA system collects a set of domain-related pages, and extracts the terms with top tf*idf scores. We took the top LAs extracted by the KA as on-topic terms. For supervised learning, we asked a human judge to traverse a collection of 1000 contexts and tag them as being on-topic or off-topic. We then profiled the tagged contexts and extracted on-topic terms from the on-topic contexts and off-topic terms from the off-topic contexts. We also built a manual setup interface that allows experts to provide their own list of terms. Several top terms of the Madonna data-set are shown in Table 1. LAs are denoted by the pair of their constituents, separated by a *.
|
Source |
On Topic Terms |
Off Topic Terms |
|
KA |
madonna*fan, madonna*song, madonna*lyric |
|
|
Supervised |
gives*birth, music*review, exclusive, video, ciccone, vocal |
vasaris, easter*traveller, church*doors, grieving |
|
Manual |
guy ritchie, like a virgin, veronica, ciccone |
jesus, hospital, university |
Table 1 On/off topic Terms for Madonna
The Spotter is a general purpose miner for identifying occurrences of arbitrary terms or phrases within documents. The logical split between the Spotter and the Disambiguator allows the Spotter to quickly traverse the content of the repository pages and identify term occurrences. The Spotter is given a list of terms to seek and it tags the documents that contain them with tokens specifying where the terms appear in the document.
We use the Spotter to search both for subjects and for disambiguation (on/off topic) terms. Subject terms are grouped into synonym sets, for instance, when searching for the subject Madonna, the user can configure the Spotter to also look for her real name, Louise Veronica Ciccone. The rationale is that when doing analytics on occurrences of a subject, we wish to count all the different variations on a subject name together. We refer to subject occurrences identified by the Spotter as spots.
The Disambiguator traverses spotted pages. For each spot, it computes a score for a local context (LC) surrounding the spot (by default a window spanning 10 words in each direction), and a global context (GC) (by default spanning the whole page). For each context, we compute the sum of term weights over all the terms that appear in it, where the weight is a combination of the terms tf*idf, its type (single term, LA, or phrase) and whether it is on-topic or off-topic (which determines the sign). If the GC score passes a threshold, this indicates that the whole page is on-topic. Otherwise we check whether the combined LC and GC score passes another threshold to determine whether the particular spot is on-topic. This gives the Disambiguator high resolution allowing it to distinguish between different spots appearing on the same page, while also taking into account information that appears outside the immediate context. In addition, the Disambiguator uses a set of heuristics, including the ability to manually specify that certain subjects are always on topic, the ability to set certain terms as having more influence than others, and majority voting if a special majority of the spots are determined to be on (off) topic then the whole page is determined to be on (off) topic. The Disambiguator tags each spot as being on topic or off topic, which is then used both to feed further processing stages, and displayed to the user together with the context and the evidence that led to the decision.
To evaluate our system, we used three different data-sets, all related to the music industry: a Madonna data-set, for which most spots are expected to be on topic. Pink (a lesser known singer), for which most spots are expected to be off-topic, and Bands, a random collection of highly ambiguous band names including: 187, Babel Fish, Binocular, Camus, Ivy, The Doors, The Hives, and Train.
We automatically evaluated accuracy by comparing the Disambiguator's results to a manually determined gold set standard of 1000 spots per topic. We use the standard Precision and Recall measures: Precision denotes the ratio of spots correctly identified by the Disambiguator as on topic out of all the spots reported as being on topic. Recall denotes the ratio of spots correctly identified as on topic out of all the spots that actually are on topic. In general, we prefer high precision over high recall. In other words, we prefer to miss a few occurrences than to incorrectly include wrongly identified subjects. As a baseline for comparison, we use a Bernoulli decision process that with probability p (1-p) determines the spot as being on (off) topic.
Figure 1 - Precision and Recall for Madonna
Results for Madonna are shown in Figure 1. Based on our gold-set, we estimate the a-priori probability for a spot of the subject Madonna being on topic at 0.866. Consequently, even a simple-minded always say yes strategy (Bernoulli p=1) does well on Madonna. The KA yields a precision of over 95%, but at a very low recall. This is due to the fact that we only took LAs from the KA. Both the supervised learning and the manual approaches show extremely high precision: 97-99%. This comes at a recall level of 80-85%. Results for Pink are shown in Figure 2. The percentage of on-topic occurrences in our gold data-set was 0.267. Intuitively, this makes Pink a tougher case to disambiguate, as shown by the baselines poor performance.

Figure 2 Precision and Recall for Pink
Results for Bands are shown in Figure 3. Since this data-set combines does not form a coherent set, we were unable to create a relevant KA for it. For the gold set, the ratio of on-topic hits was 0.141.

Figure 3 Precision and Recall for Bands
Our experiments show that the basic premise of locating on/off topic terms in the context of spotted subjects is extremely helpful for disambiguation. As we have seen, this approach is able to achieve high levels of accuracy with limited training. Thus, the main challenge lies in generating highly accurately discriminating terms. All the techniques we have experimented with require some amount of training or teaching from the user. There is a trade-off between the amount of labour required and the degree of accuracy required. It is possible, and indeed may be worthwhile to fine-tune a set of disambiguation terms until results are extremely accurate. Our system provides a convenient method for doing so. More automated techniques tend to introduce considerable noise, and thus cannot be used in isolation.