1. Introduction
In this paper we revisit a simple idea for further improving Web
performance, namely to "batch-transmit" a web page and all of its
related objects (such as embedded images, scripts, style sheets, applets, etc.)
within a single exchange of request and response. This idea seems quite
natural, is not new, and keeps occurring from both research literature and
informal discussion occasions (for references see [1,2]). But as we’ve learned,
the problem is actually more complicated than it may have seemed, involving
many fundamental issues of the current HTTP and posing interesting questions as
well as difficulties for investigation. The purpose of this paper is to try to
understand an appropriate way to construct a comprehensive batch model that is
not limited to special uses.
|
Copyright is held by the author/owner(s). WWW 2003, May 20-24,
2003, Budapest, Hungary. ACM xxx. |
The data retrieval model used by HTTP is known to be a “one request for
one resource” model, which may seem inefficient and inappropriate for Web
content distribution as a Web page usually consists of multiple resources (or
called embedded objects). This model can be particularly awkward when applied
to revalidate retrieval (“reload”) of Web pages. One may argue that in an
imagined optimal model, one request and one response should be sufficient for
the exchange of necessary metainformation details, and the revalidation of all
static contents should cause no actual message passing. But this problem is
related to an inherent conflict between batch-transmission and partial updating
of aggregate resources, which seems insurmountable within the framework of
HTTP.
According to Mogul [3], “Many of the problems with HTTP can be traced to
unfortunate choices about fundamental definitions and models.” In particular, “HTTP
lacks a clear and consistent data type model”. As we understand, the “structured
hypertext nature” of Web pages presents us a new data model of HTTP that is
applicable to the batch-transmission issue, as well as a SOAP/1.1 like HTTP
binding scheme to apply the model.
2. The “Structured HTML” Description
A major problem with HTML is that it serves as a resource transfer
control method by HTTP. HTTP relies heavily on the utility of URIs (Uniform
Resource Identifiers). URI is intended to tag individual resources on the Web.
But in the context of HTTP, a URI of a “hypertexted” (HTML) Web page actually
identifies a set of aggregate resources (with their own URIs), and access to
such a URI usually involves multiple resources transmission. This complexity
may cause a semantic and operational gap between the HTML description of Web
resources and a URI-based transmission or caching control model. We thus may
regard this inconsistency as an implication that HTML is not an optimal
description of Web pages from the perspective of efficient data transmission. A
Web page presented by HTML is not well structured in that metainformation of
the related individual resources cannot be effectively presented and used. In
general HTML per se is too primitive to be best suitable for the efficient control
of resource transmission. Thus a higher-level abstraction may well be useful.
The metainformation of a Web page and its related resources can be
formulated as a tree structure. Each tree node, as a resource (or according to
Mogul’s clarified model, an instance of a resource), has its detailed metainformation,
such as information of the size, position offset, time of creation and
modification, entity tag (ETag), cache control info, etc of each resource.
Appending these metainformation descriptions on the nodes, the Web page would
be represented by a well-formed tree (or an XML document).
If the server and the client could exchange such a well-structured metainformation
for each Web page, the optimal transmission of Web pages would be possible. One
possible implementation of this metainformation structuring is to extend HTML,
for example, by appending such information to relevant HTML tags or even
inserting specific comment blocks (of some clever marks) into HTML documents.
The advantage and disadvantage of this approach are obvious: no separate description
method is needed; but HTML specification needs to be extended, and existing Web
pages to be rewritten (and of course, both the server and client need to be
updated).
The other one, which we choose, is to define a separate, specific,
XML-based language, with the sole purpose for efficient resource transmission,
which should be a very simple markup language (as simple as possible). In the
following we shall call this language the STML (short for “Structured HTML”),
and a URI described in detail by STML an “STML document”.
STML documents follow the standard style of XML documents, consisting of
a head-part (the <head> tag) and an optional body-part (<body>).
Roughly speaking, an STML document is a "hypertext of hypertexts",
that is, a set of hypertexts related to the same root hypertext. (The set may
or may not be "closed" or complete with respect to the closure of object
embedding.) An optimized batch-transmission model would thus be a protocol for
the efficient transmission of such hypermedia sets. Here is an example of a
simple STML document:
<?xml
version="1.0" encoding="UTF-8" ?>
<stml
xmlns="http://xmlsd.sttp.org/stml/v0.9" />
<head> <root>
<object
Name="/index.html" Content-Type="text/html" ETag=
"0-54e-383712c4" Offset-Size= "239/15572" Embedded="-text/html,
+*/*, local-only"
/> </root>
<object
Name= "../img/logo.jpg" Content-Type= "image/jpeg"
Content-Encoding= "czip" ETag= "0-b7f-39e37ad2" Offset-Size="15627/10796" />
<link
href="http://wss.wss.org" /> </head> <body>
<object
Name= "/index.html">
...content (uncompressed)...
</object>
<object
Name= "/logo.bmp">
...content (compressed)...
</object> </body> </stml>
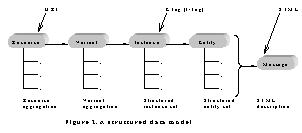
3. A Data Model for Batch-Transmission
Having designed a method to represent the structured metainformation of
resources associated with a URI, we now try to establish a data model for
solving the problem of efficient batch-transmission. The following figure
depicts the model, which is an adaptation of Mogul’s model [3] to the
batch-transmission situation. For individual resources, the data types and
operation pipelines are the same, up to the entity phase, except that the
various sets of data objects related to a root resource (URI) are tree
structured and processed in a “batch manner” (operating on the tree
structures). The only significant difference is at the message (transmission)
phase, where in this model, entities related to a Web page are structured into
an STML document before they go through the last operation phase (transfer
encoding) and network transmission. The whole resource (instance) tree needs an
independent “global ETag”, which is that would appear in a generated response
message.
4. Binding to HTTP
As an example of combining the above STML descriptions with the HTTP
messages, here we discuss a binding scheme that is borrowed from the HTTP
binding defined in SOAP/1.1 (but not SOAP/1.2, whose HTTP binding uses a
Content-Type mechanism). We shall call the resulted extension the “Structured
HTTP”, or STTP for short. (Of course, other binding schemes can also be
possible but will not be discussed here.)
We use a special header, ATTP-Action, to do the binding. As an example:
GET /index.xxp HTTP/1.1
Host: wss.wss.org
Content-Type = text/xml;
charset="utf-8"
Content-Length: ###
STTP-Action: STML-Compare
If-None-Match:
0-85f-724334c4 // global
ETag
<?xml version="1.0"
encoding="UTF-8" ?>
<stml
xmlns="http://xmlsd.sttp.org/stml/v0.9" />
<head> <root>
<object Name= "/index.xxp"
Content-Type="text/html" Offset-Size= "502/27371" ETag=
"0-54e-383712c4" Linked-Object="-text/html, +*/*"> </root>
<object Name="/logo.jpg"
Content-Type="image/*" Offset-Size= "27960/66808" ETag=
"0-23f-626854c4" />
<object Name= "/menu.js"
Content-Type="text/*" Offset-Size="94920/8033"
ETag="0-31d-652413c4" />
</head> </stml>
In principal, the STTP-Action can be used with various HTTP requests,
assigning the uniform semantics that the client expects an STML response from
the server. For example, the extended HTTP GET messages correspond to 3 kinds
of STTP actions: STML-All, STML-Head and STML-Compare. There are three general
rules for using STTP-Comparer requests: (1) a newly added object causes ETag
changes of both <root> and the STML document; (2) if an <object>
listed in the request is not actually related the current <root>, the
server ignores it; (3) if the server did not add a required object into the
STML description, the client will use the conventional HTTP GET to retrieve it.
The binding of HTTP response messages is relatively simple, namely the
server directly return the requested STML description in the response body (as
a usual entity). The HTTP status code is used in a way similar to the SAOP
binding. The following is a response example:
HTTP/1.1 200 OK
Content-Type = text/xml;
charset="utf-8"
Content-Length: ###
STTP-Action: STML-All
ETag: 0-85f-724334c4 // ETag of
the whole STML document
<?xml
version="1.0" encoding="UTF-8" ?>
<stml
xmlns="http://xmlsd.sttp.org/stml/v0.9" />
<head> ... </head> <body> ... </body> </stml>
5. An Optimized Batch-Transmission Model
Based
on the above scheme, an optimized batch-transmission model can now be established
in the form of two general rules:
(1)
In the first-time retrieval, the client
first gets the STML description of the attempted URI by sending a “description
request”, whose response is then used for selecting interesting contents from
the resource set via a successive “content request”; To avoid the unnecessary
successive request when the target resource has actually no interesting
embedded objects (e.g., when the URI is a text file), the server may indicate
so by adding the requested contents into the response to make a complete STML
document.
(2)
In subsequent revalidate retrieval, the
client only needs to send an STML-Compare action request, listing the
meta-information of the interesting objects (including the page itself), such that
the sever will have sufficient information for constructing an efficient
response.
In
transaction (1), when the URI is actually not a resource aggregation, the
successive request is a risk of adding an extra cost. Since this is assumed to be the first-time retrieval, it is
up to the server to make a right decision to avoid the risk. One may further
attempt to optimize transaction (1) by simply sending an STML-All request. The
result will, of course, be correct, with a possible risk to re-transmit cached
objects (e.g., images or style sheets). This further optimization can be useful
only for rarely (re)visited Web sites, as the local cache can be assumed with a
high probability to have been emptied. Note that in this model, the message
numbers of the two STTP transactions are constants: (1) requires two rounds of
interaction with 4 messages, and (2) need only one round of 2 messages. By
contrast, for a typical Web page with 20 related objects, there are 21 requests
and 21 responses (totally 42) between an HTTP client and server. Though request
pipelining can help reduce network bandwidth use (in addition to causing other
problems, though), as we see from our comparison experiments [1,2], the other
“stupid” 40 revalidate messages may lead to considerable network latency and
large packet numbers.
6. Structured Caching and Other Issues
The data model also suggests a new way of organizing cache contents,
namely, when a root (HTML) page is cached, the tree structure of
metainformation of all its associated components and their cachability
properties should also be stored together with it. This tree structure of cache
(with STML descriptions) can be very useful for fast construction of
STML-Compare requests in later revalidations. Using STML metainformation trees
to structure cache contents also has a benefit in maintaining cache
consistency. Compared to URI-based caching, tree-based caching can have a
comprehensive knowledge of the interrelations among the entries (such as the invalidity
relationships), and hence can performed and be controlled more efficiently.
Actual cache trees of Web pages are highly coupled, and the whole cache would
have a network structure. Under each URI there is a cache tree.
If STTP and other “higher-level” application protocols such as SAOP are bound
to the same HTTP message, then an STTP server would consider the STTP binding
first. This is because STTP is intended to be a more “bottom” mechanism for
resource transmission. But carefully designed constraint rules have to be
introduced into STTP in order to preserve SOAP compatibility and in particular,
to avoid possible conflicts with the contents of SOAP message bodies. E.g., if
SOAP is bound to an HTTP GET request, then all the request STTP actions
(STML-All, STML-Head, STML-Compare) are applicable; both STML-All and STML-Head
can be applied to any HTTP request messages.
Comparison of related work and some experiment results can be found in
[1,2]. We found that STTP outperformed HTTP under all circumstances tested. The model may be regarded as near-optimal
in that a batch transmission approach with comprehensive caching and partial
updating support is actually possible for HTTP. STTP is still a relatively simple
and effective mechanism, and fully compatible with HTTP. We would like to
further investigate the consequences of this model, including both the benefits
and costs, and possible impact on related aspects of the Internet.
The author thanks the beneficial discussions and generous help from his
colleagues. This work is supported by the
863
Program under the project No. 2001AA112081.
7. References
[1]
Swen, Bing. An Overview of the Web++ Framework. In Proc.
of International Conferences on Info-tech & Info-net (ICII2001), Conference
E (Information Network), E-13 (Web Technology). Beijing, Oct.29 - Nov.1, 2001.
[2]
Swen, Bing. A Brief Introduction of the Web++ Framework. In WWW2002
Conference Proceedings, Posters Session. Honolulu, Hawaii, USA. 7-11 May 2002.
[3]
J. Mogul. Clarifying the
Fundamentals of HTTP. WWW2002, May 7-11, 2002, Honolulu, Hawaii, USA.