where j is the parent of i inside the site's tree.
In this work two distinct metrics are proposed, which aim to quantify the importance of a web page based on the visits it receives by the users and its location within the website. Subsequently, certain guidelines are presented, which can be used to reorganize the website, taking into account the optimization of these metrics. Finally we evaluate the proposed algorithms using real-world website data and verify that they exhibit more elaborate behavior than a related simpler technique.
Web Metrics, Web Organization, Log File Processing.
User visits' analysis is the first step in any kind of web site evaluation procedure; in order to assist in this, many commercial systems provide statistics about the most visited files and pages. However in [4] is shown that, the number of hits per page, calculated from log file processing, is an unreliable indicator of page popularity. Thus, a refined metric is proposed, which takes into account structural information, and, when using it, certain pages are reorganized leading to the overall improvement to site access. Other researchers have attempted to identify user behavior patterns, Chen et al [2], and to analyze the paths that users follow within a site, Berkhin et al [1]. A very influential recent work is that of Srikant and Yang, who furthermore suggest structural changes to the website, after having identified visit patterns that deviate from the site's initial organization. On the other hand, very little progress has been achieved in providing a software tool or even framework that would assist in automatically applying changes to the web site. Some early steps towards this direction can be found in [3].
This paper introduces two new popularity metrics. The first one differentiates between users coming from within the website and users coming from other websites, while the second one uses a probability model to reassess popularity. Key feature of the new metrics is the higher fidelity of the popularity estimates. We evaluate and examine these metrics by comparing them with the metrics introduced in [4].
The Absolute Accesses (AAi) to a specific page i of a site is not
a reliable metric to estimate page popularity. Thus, Garofalakis et. al. [4]
defined the refined metric Relative Access (RAi) as:
RAi = ai*AAi (1)
The RA of page i is a result of
the multiplication of AAi by a coefficient ai. The purpose of ai
is to skew AAi in a way that
better indicates a page's actual importance, incorporating topological
information, namely page depth within site di, the number of pages at
the same depth ni and the number of pages within site pointing to it ri. Thus ai =
di + ni/ri. This metric will be henceforth refered to as GKM.
.
It is crucial to observe that a web page is accessed in four different ways. Firstly it gets accesses within site, secondly directly via bookmarks, thirdly by incoming links from the outside world and finally by typing directly, its URL. Under this observation, we can decompose ai, into two factors, ai,in and ai,out. The first one, ai,in, reflects the ease of discovering page i , under the specific site organization. This factor is similar to [4], but significantly redefined. The new factor that we introduce, ai,out, designates the importance of a specific page for the outside world, i.e. pages that point to i from other domains and bookmarks to i. Subsequently, we discuss two approaches in defining ai,in and ai,out.
We define the following quantities: di is the tree depth of the page i and
ni denotes the outdegree of page
i. Thus ai,in is defined as:
![]() , (2)
, (2)
where j is the parent of i inside the site's tree.
Hence, ai,in depends on the depth of page i (the deeper i lies the more its discovery gets value), the number of i's siblings (many siblings raise the importance of the i's choice) and the number of other pages pointing to it (few ways to access i, so the access figures it gets shall be raised). Normalizing each influence factor, yields ai,in<=3.
In order to define ai,out we denote as Bi, the number of bookmarks for page i,
and as Li, the number of links from
other web pages to page i
. So:
,
 (3)
(3)
Equation 3 implies that ai,out depends on the number of both bookmarks and
links from outside to page i. Many bookmarks indicate high popularity
among the visitors of our site, which is exactly what we want to capture.
Moreover we include the factor di/dmax, weighing the number of bookmarks w.r.t. the
page's depth. The constant additive factor at the end, comes in order to make
ai,out<=3, just as with ai,in, so that they both have the same maximum
potential influence on
RAi (see Equation 4).
In order to apply our newly derived factors, we also separate 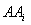 into two parts:
into two parts: 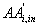 and
and 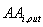 , that keep the accesses from inside the site, exclusively for
page i (and not for its children) and the accesses having an antecedent
from another domain, respectively. So the relative access for page i,
RAi
is:
, that keep the accesses from inside the site, exclusively for
page i (and not for its children) and the accesses having an antecedent
from another domain, respectively. So the relative access for page i,
RAi
is:
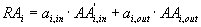 (4)
(4)
It is tempting to model traffic inside a site, using a random walk approach (e.g. like in [5]) but ai,in, models the ease (or difficulty) of access that a certain site infrastructure imposes to the user. Thus, a page's relative weight, should be increased inversely proportional to its access probability. We consider the site's structure as a directed acyclic graph (DAG), where vi denotes page i. A user starts at the root page vr, looking for an arbitrary site page vt and at each node vi he makes two kinds of decisions: either he stops browsing or he follows one of the out(vi) links to pages on the same site. If we consider each kind equally probable, the probability pi, of each decision is pi = (out(vi)+1)-1.
Considering a path Wj =
{vr,..., vt} and computing the routing probabilities at
each step, the probability of ending up to vt via Wj,
is:
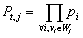
There may be more than one paths leading to t,
namely W1,
W2,..., Wk. Thus,
Dt , the overall probability of
discovering t ,
is:
 (6)
(6)
Considering page i as target, the higher
Di is the lower ai,in shall be, so we choose
ai,in to be, ai,in = 1 - Di.
We also let
ai,out=1 , considering each
external access as a path of length one. Thus we define
RAi
as:
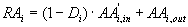 (7)
(7)
Our metrics will be refered to as
TOP and PROB, for short
In order to evaluate the results of the described algorithms we used the web server log from http://www.ceid.upatras.gr (Computer Engineering & Informatics Dept., University of Patras). We obtained a web log covering 44 days, including 1,320,819 records (hits) and 3596 unique visitors (Feb 2002 - March 2002). After having analyzed the site structure in order to recognize the pages of our interest, we identified a structure of 4 levels and 98 pages. We also implemented pre-processing, parsing, distilling and extracting procedures in order to filter out unwanted raw data from log files and focus only on entries corresponding to pure HTML pages. We implemented our proposed algorithms and metrics, the corresponding pre-processing procedures and the GKM algorithm and metric using the Mathworks Matlab v6.5 language.
The GKM metric provides a rough estimate of the multiplicative factor ai . As the latter is affected by the number of pages at the same level, the RAs computed for sites of large width are considerably larger than the ones stemming from our metrics. Another issue is that pages lying deep down the site hierarchy get overly benefited, because of the tree-like evolution of web sites. Both our approaches alleviate such phenomena, displaying a more balanced consideration of "node scoring". Considering the TOP metric, we normalize the influence of both depth and width to the RA score and we don't take into account every page at the same depth but only the siblings of a certain node. Our experimental results show that, figures computed by our metrics are, in about an order of magnitude, smaller than the respective ones of GKM, an indication that our techniques are more elaborate. Another advantage of our approaches is the incorporation of bookmarks, which are an important indicator of page quality.
This work aims to provide refined metrics, useful techniques and the fundamental basis for high fidelity website reorganization methods and applications. Future steps include the description of a framework that would evaluate the combination of reorganization metrics with different sets of redesign proposals. We also consider as an open issue the definition of an overall website grading method that would quantify the quality and visits of a given site before and after reorganization.