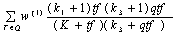 (1)
(1)This paper describes a new document-frequency-related query term weighting schema in Web information retrieval using HTML structure information. Firstly, the concept of the Primary Feature Space has been proposed, which is composed of the more informative field in HTML documents, such as emphasized bold words. Secondly, a new PF query term weighting schema has been proposed which takes logarithm of DF into accounts instead of general IDF factor. Finally, a combination strategy of term weighting on both Primary Feature Field and general body text is given. The consistent great improvement of performance verifies the reliability and effectiveness of the PF term weighting schema.
Web IR, HTML structure, term weighting, document frequency, inverse document frequency
One of the key differences between the documents in web environment and those in traditional IR systems is the structure of HTML documents, which is embodied in HTML tags. Intuitively, terms appearing in different fields may have different importance in retrieval.
Several search engines already use HTML fields to improve ranking. AltaVista[1] and Yahoo[2] score a document higher if query words or phrases are found in the title of a web page. Lycos[3] uses position information on query term occurrence (title, body, heading) in the rank function.
The other usage of HTML structure is to give different weights to terms in different fields. A comprehensive study on using HTML structure to enhance retrieval performance by giving higher term frequency weight has been made by Cutler on 1997[4]. Their conclusion is that anchor texts and STRONG class should carry more weight. In TREC9, the Information Space system focused on the use of title and h1-h3 head tags in HTML documents [5].
In all the previous work, weights of the query terms have been computed concerning the two traditional points: term frequency (TF) and inverse document frequency (IDF). For general body text, this idea of IDF represents the essential of the term significance in terms of distinguishing the document from the others. For special fields of HTML documents such as title and emphasized bold words etc, however, the situation changes. This paper takes these special HTML fields as the Primary Feature Fields of the document, and extends the term weighting notion based on the DF of the term occurred in the primary feature fields.
In traditional vector space model, the commonly used formula for computing the weight of t in d is TF·IDF.
In the well-known probabilistic model proposed by Robertson and Sparck Jones[6], the similarity score of one document and the given query can be shown in Eq.(1).
(1)Where w(1) is the query term weight. It is generally called Robertson/Sparck Jones weight for a term, which is of the form:
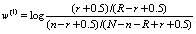 (2)
(2)where N is the number of documents in the collection, n is the number of documents containing the term, R is the number of documents relevant to a specific topic; and r is the number of relevant documents containing the term.
Note that in the absence of relevant information (R = r = 0), this term weight defaults to a collection-frequency weight, which is similar to the IDF factor in vector space model.
Considering the different importance of HTML fields, a combined weight of the query terms can be used, which is more flexible:
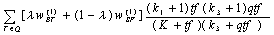 (3)
(3)As known, terms appear in the title, heading or emphasized fields in the text are more generally important for retrieval than the other body text. They represented the notion of the web pages' authors on the main content of the page. We take these special fields as Primary Feature Fields (PFF). Terms in the primary feature fields in the entire collection construct a Primary Feature Space (PFS). This space is not of uniform distribution. Therefore, terms with higher density in the space should be more significant as features. Generally, the density of the feature dimension can be represented by the term frequency in the primary feature space:
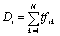 (4)
(4)Where tfik is occurrence frequency of term i in PFF of document k, and N is the total number of documents in the collection.
Since web pages are built by different authors with different backgrounds and writing habits, the description of the field may not be canonical. To reduce the influence of the information leak caused by different author, it's better to limit the same terms from one page contributing to the feature density only once. i.e.
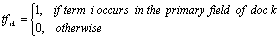
Therefore the density of the feature dimension is be simplified to:
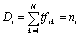 (5)
(5)Where ni is the number of documents which contains term i in its primary feature space in the collection. Then the term weight in the primary feature space can be represented by:
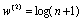 (6)
(6)Where tfi and ni are simplified as tf and n respectively.
By doing so, in HTML documents collection, the weight of a term in the query is composed of the weights in PFS and in body text. Therefore the new similarity scoring function can be presented as:
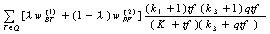 (7)
(7)where 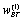 is the
Robertson/Sparck Jones weight for a term according to body text,
is the
Robertson/Sparck Jones weight for a term according to body text, 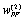 is the weight in terms of
primary feature field, λ is the impact factor of the body text. When
λ =1, the scoring function is same as traditional Robertson/Sparck
Jones probabilistic model.
is the weight in terms of
primary feature field, λ is the impact factor of the body text. When
λ =1, the scoring function is same as traditional Robertson/Sparck
Jones probabilistic model.
The test collection used in our experiments is ten-gigabyte WT10g web data. The test query we used is TREC9 and TREC10 100 topics number 450-550. For each topic, top 100 retrieved documents judging by the system as relevant are returned.
We made a comparative study on the schema of Robertson/Sparck Jones weight (see Eq.3, referred as RS weighting) and our new proposed DF-related primary feature space weighting schema (see Eq.7, referred as PF weighting).
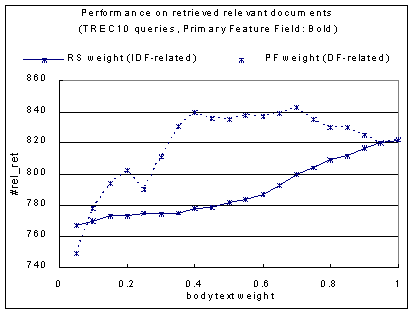
Figure 1 and Figure 2 show the average performance of using bold character as Primary Feature Field on TREC10 fifty test topics, in terms of the number of relevant documents returned (describing the recall of the system in top 100 documents) and 11-point average precision, respectively. In figure1, with proper body text impact weight (λ in Eq.7), our PF weighting schema returns much more relevant documents in top 100 results than the traditional RS weighting does. When λ is not less than 0.3, the recall of PF weighting is higher than the best result got by RS weighting.
In figure2, the effect of PF weighting on 11-point average precision is similar to that shown in Figure 1. Therefore experimental results show the ability of better system performance in terms of both precision and recall which verify the reasonability of using PF weight of the Primary Feature Space in HTML documents.
Results of TREC9 topics are all the similar to that of TREC10.

In this paper, we described a new document-frequency-related query term weighting schema in Web information retrieval using HTML structure information. Comparative studies indicate that the new DF-related PF term weighting made consistent and great improvement in retrieval performance.
This work was supported by the Chinese National Key Foundation Research & Development Plan (Grant G1998030509), Natural Science Foundation No.60223004, and National 863 High Technology Project No. 2001AA114082.