 W is a site if
#a1, a2
W is a site if
#a1, a2
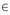 A,
URIauthority(a1) =
URIauthority(a2).
A,
URIauthority(a1) =
URIauthority(a2).The paper is devoted to the meaning and representation of space and time over the Web. While both concepts are interesting, the more difficult part is related to space. We cannot think of web space in terms of the measured space of the real world. The Web's spatiality is provided by (hyper)links, and thus the web space is given by a graph of pages and links between them. We describe spatial and temporal relations between Web pages using an XML-based language, called SpatioTemporal Relation Specification Language, that can be used for detecting, retrieving and synchronizing information on the Web.
Space, Time, Web, Sematic Web, XML, RDF.
An important problem of any distributed system and particularly the WWW is the representation of space and time. The Web connects a huge number of documents in a very complex structure; the complexity of this structure derives both from the quantity and the extreme dynamics that it presents.
There are many temporal formal models to capture different properties of distributed (real-time) systems [1]. It is still difficult to give a machineunderstandable description of these formal methods in order to implement different kinds of software applications for activities such as resource discovery and queries that involve time. Following a previous paper devoted to time [2], we develop a highlevel description of spatiotemporal relations between Web pages to capture the dynamics of the Web documents and the links between them, based on RDF and XML. We define a language called SpatioTemporal Relation Specification Language able to integrate both spatial and temporal relations.
The temporal structure introduced by Interval Temporal Logic (ITL) is a simple linear model of time. Given any two temporal intervals, there are thirteen mutually exclusive relationships. To model these relations, one primitive relation Meets is introduced. Intuitively, two periods m and n meet if and only if m precedes n, yet there is no time between m and n, and m and n do not overlap. Within this system, we can define the complete range of the thirteen intuitive relationships that could hold between time periods. A period can be classified by the relationships that it can have with other periods of time. A period that has no subperiods can be called a moment and a period that has subperiods, an interval. Also, we can define a notion of time point by a construction that specifies the beginning and ending of periods (moments and points are distinct). A discrete time model can be given, where periods map to pairs of integers <I, J>, where I < J. Moments correspond to pairs of the form <I, I + 1>, and points correspond to the integers themselves. A similar model built out of pairs of real numbers does not allow moments. The computational properties of the interval calculus and algorithms for maintaining networks of temporal constraints, as well as a formal representation of events and actions based on interval temporal logic are presented in [1].
The Web is rather goal-centered than space-centered,
that is why its most important component is the "hyperentity"
of link. Let us denote by W the universal set of the
Web, as the collection of all documents available online, referred
through their URIs. A site is a finite subset of W , for
which all documents' URIs have the same <authority>
component, i.e. a finite A
W is a site if
#a1, a2
A,
URIauthority(a1) =
URIauthority(a2).
We define the binary relation on W, called
points-to, by a → b if document a
contains a link to document b. We also define its inverse
is-pointed-by, ← = →−1. The set
of external and internal links for a
W are defined as
a+ = {p
W | a → p} and a−
= {p W | a
← p}. respectively. This extends naturally to sites.
For A W,
A+ = {p
W | 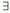 a
A : a →
p}, A− = {p
W |
a
A : a ←
p}.
a
A : a →
p}, A− = {p
W |
a
A : a ←
p}.
Inspired from [3], we take a closer look at three spatial relations established between Web documents: reaches (when a+ ∩ b− ≠ Ø), co-refer (when a+ ∩ b+ ≠ Ø) and co-referred (when a− ∩ b− ≠ Ø). Not all the links of a Web document have the same relevance. At the present time, the Web is not provided with a means to specify the different importance of links, for example HTML has no such syntactic method. We use a new primitive construct in our RDFbased language that can carry out that task and yield the information needed. Each link (e.g. specified by a <a href> HTML tag) has an attached score ranging from 1 to 100, with 50 by default.
Considering a, b
W such as a → b, the score relevance of
link a → b, denoted by
RelevanceScore(a,b), is defined as the integer
representing the parsed string value of attribute score of the
element Direct in the STRSLSchema defined in
Section 3, if exists, or 50 otherwise.
A trip from a to b is a sequence c =
[x1, x2, ...,
xn], where (x1,
x2, ..., xn)
Wn,
x1= a, xn= b and
xi → xi+1, 1
≤ i ≤ n−1. The length of this trip
is λ (c) = n−1, whereas its
value is υ(c) =
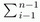 RelevanceScore(xi,
xi+1). The distance between
a and b is d(a, b)= min
{n | r= [x1, x2,
..., xn+1]}, or d(a,
b) = +∞ if there is no trip from a to
b.
RelevanceScore(xi,
xi+1). The distance between
a and b is d(a, b)= min
{n | r= [x1, x2,
..., xn+1]}, or d(a,
b) = +∞ if there is no trip from a to
b.
Proposition 1. 1. d is a quasi-pseudo-metric over W2.
2. for all a, b, c W , d(a, b)
= d(a, c) + d(c, b) iff c lies on a trip from a to b with minimum
length.
Considering a, b
W , the generalized distance between a and b
is d*(a, b) = min{d(a,
b), d(b, a)}. The generalized distance
transforms the Web into a metric space (W, d*). This
is an important feature that we intend to use as a starting point
in further development of other formal and practical approaches
regarding spatiality on the Web.
The model provides a means for the automatic processing of the description. Regular search engines execute a full width search of the web, based on pattern matching and document indexing. A search engine based on our model is capable of a more indepth search and of eliminating the irrelevant search branches. A simple idea is that during its travel from document a to b along trip c, it computes relevance scores as the average of link scores: RSc (a, b) = υ(c) / λ(c). A limit for the distance from the current document, e.g. λ(c) ≤ d(a, ·) < n, can be included; also, one may not follow trips further on which the relevance score RS goes below a threshold, or a lower bound could be imposed on individual links scores.
Searching in the web space can be improved by making the relationships between nodes as explicit as possible. The Web navigation process is based on a cognitive map based on a mental representation of the environment. During the web navigation process, the user's cardinal directions are given by the perceived information indicating the content of the web site behind each link. This is not a quantitative measure as a link score. It provides a more human-centric approach, defining a qualitative framework. Systems managing these types of qualitative notions of space (and time) can behave more intelligently than the traditional ones. The qualitative framework can be translated into a relational algebra and so, we can handle it within the context of decidability and computation.
The logical dependencies between spatiotemporal relations holding among entities may be stated in terms of a first order logic. If we consider relation algebras and weak representations, accord ing to the previous steps, we should characterize a subclass of for malisms for which the weak interpretation can be related in a canonical way to a structure based on a total ordering. For a specific class of formalisms based on linear orderings (in the sense that each for malism is concerned with sequences in linear orderings) including generalized intervals or cardinal directions, the associated first or der theory has the property that all countable models are isomorphic. It can be proved that these formalisms are complete and, as a consequence, they are decidable.
This kind of result could provide a theoretical starting approach in defining a good notion of space over the web, and efficient navigation agents. Finally, this could help getting closer to one of the main goals of semantic Web: efficient global knowledge exchange through a better retrieval of information available online. For in stance, it would be possible to formulate more complex queries for retrieving certain pages based on the link structure: ask for Ghandi's pictures reachable from the root of the BBC web site within no more than 4 links, and locate the pages with a relevance score greater than 65.
The intuitive properties of link directions could be translated in the form of an algebra with two operations applicable to direction symbols: the reversing of the direction (inverse), and the composition of the direction of two consecutive segments of a path (composition). The operational meaning of link directions is captured by a set of formal axioms. These axioms describe the desired properties of link directions and are similar to a relation algebra. Relation algebras were introduced by Tarski in order to axiomatize the structural properties of binary relation algebras whose elements are binary relations, with transposition, binary relation composition and the identity relation as a neutral element. In fact, relation algebras give an integrating and unifying framework. Both the link direction algebra and Allen relation algebra are binary relation algebras.
To express different spatial and temporal relations as RDF as sertions, we define an XMLbased language called SpatioTemporal Relation Specification Language (STRSL). The language will be able to express the relations co-refer and co-referred, as well as to distinguish among the links based on their relevance with respect to the document. In this way it can help search engines in faster dis covering of more relevant documents, because it provides a way for making justified choices during the search.
It can also express the relations Before, Meets, Overlaps, Starts, During, and Finishes that can be established between two fragments of Web sites or between two different Web sites. These temporal relationships can be used to determine the dynamics of that Web sites' content and can help, among others, the Web robots or agents in mirroring/searching activities. The updating or querying actions can depend on the temporal relations that can be expressed by STRSL and RDF constructs. In order to express a more general time model, the STRSL language will allow intervals of time (beginning and ending of periods) and, of course, moments.
We define the t XML namespace for all STRSL elements and attributes to avoid ambiguities. For each time relation, STRSL offers an element that corresponds to a specific relation (e.g. <Meets> element for Meets relation). The beginning and ending of time periods are denoted by begin and end attributes, respectively, inspired by SMIL. The attribute score is used to specify the relevance of a link. The source and destination (operands) of a spatial or temporal relation can be expressed by RDF constructs.
Some of the ideas of this paper follow concepts and results first introduced in [2], especially those dedicated to time, as well as the first version of the specification language. Others started from previous approaches on time and space, such as those authored by M.J. Egenhofer in [3] and other papers.
We intend to explore the perspectives opened by regarding the Web as a metric space. A better integration of space and time notions and models is needed; a software approach suggests that both aspects work better together.
We have defined a high-level RDF-based description of the spatiotemporal relations between Web pages. This approach can be used to capture the dynamics of the Web documents and links between them. To express these spatiotemporal relations, an XML-based language called SpatioTemporal Relation Specification Language was defined, which can help obtaining better results in searching the Web.
The presented model is to be enriched with more complex RDF assertions regarding spatiotemporal events and actions that follow the theoretical approach described by Allen. An extension can be carried out towards using the elements and attributes for sharing integrated (timed) functional-logic knowledge bases as XML documents, as presented in Relational-Functional Markup Language.