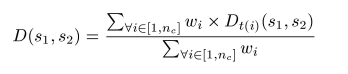
In this paper, we apply AntClust, an ant based clustering algorithm, to the Web usage-mining problem. We define a Web session as a weighted multi-modal vector and we propose an adapted similarity measure between two sessions. We show that our method finds non-noisy clusters that help the interpretation of the results when it is applied on real Web sessions coded as "hits by page" vectors.
Ant based clustering algorithm, Web usage mining.
As the usage and the content of the World Wide Web grow, it becomes a major issue to better appreciate how Web sites are visited. This knowledge can be useful in a number of applications: the dynamic reorganization of Web sites according to representative navigational patterns, the automatic prediction of interesting urls for Web users or the pre loading of Web pages in the Web servers' memory to speed up the connections' time.
The Web usage mining, as described by Cooley [1], mainly relies on the study of Web sessions that are extracted from Web server log files. A session reflects the activity of a user on a Web site for a given time. The sessions are generally very noisy, since users can't be clearly identified. Several approaches have been tested to extract knowledge from the sessions and to understand the navigational patterns of the Web users.
In [2], association and sequential rules
discover relationships between visited Web pages. Output rules are worthy
for cross marketing purposes, but cannot help understanding the motivations
of the users.
One solution may be to code Web sessions with more information and to use
clustering algorithm such as a "First Leader algorithm" [3] and a K-means-like approach, "Wavefront" [4].
Clustering algorithms should be able to group homogeneously the sessions of the users that share similar interests but they
generally only handle numerical data set and must be initialized with a number
of clusters. One may use more sophisticated heuristics such as ant-based clustering
algorithms to find automatically the best number of clusters. In [5], researchers
have modelled real ants abilities to sort their brood. In [6], the authors
developed AntClust. It can perform well on artificial and real data sets,
it doesn't need to be parameterised and can treat every types of data, if an
adapted similarity measure is available. In this paper, we propose a new
definition of the Web sessions with its associated similarity measure, and
we study the application of AntClust to real Web sessions.
This paper is organised as follows: section 2 introduces the main principles of AntClust. Section 3 describes our new Web sessions model and its associated similarity measure. Section 4 presents the Web site used for the experiments and the results. Section 5 concludes and discusses future work.
AntClust is inspired from the chemical recognition system of ants. It simulates meetings between artificial ants to solve the unsupervised clustering problem. AntClust only needs a similarity measure that inputs a couple of objects i and j, and outputs a real value Sim(i,j) between 0 and 1 (1 means that i and j are identical).
Real ants manage to identify intruders according to a colonial odor established through continuous chemical exchanges between nestmates ("Gestalt theory" [7]). AntClust models the main "parameters" of real ants such as their cuticular odour, their recognition template and their genome. AntClust associates one object of the data set to the genome of an artificial ant. It also mimics the acceptance scheme between 2 ants and reproduces behavioural rules that allow the algorithm to converge. The cuticular odor of each ant is coded as a number representative of its belonging nest. The behavioural rules modify the label of each ant until the ant finds a nest where it is well integrated.We use several features in our multi-modal session description.
Each feature is extracted from the Web server log file. Namely there are the
IP number, the user identity, the date and time of connection, the Web pages
history and the session's duration. We add several features to model a session:
a transaction vector that indicates for each page if it has been visited
during the session, a time vector that contains for each page, the estimated
time that the user spent, a date vector that lists for each page, the date
of their first access and finally, a vector that counts for each page, the
number of hits. We may add the user operating system or the user browser.
Each session si is described by
a vector of nc weighted features.
As each of these features may have a specific data type t(i), we express
the global similarity between two sessions s1 and
s2 as the weighted sum of the typed similarity measures, over the
nc features. Let Dt(i)(s1, s2),
be the similarity measure between the ith features of sessions
s1 and s2. The weight wi associated to each feature allows us to define the global similarity measure
D(s1, s2), between two sessions s1 and
s2, as follows:
The similarity between two transactions vectors is equal to the ratio of their identical elements. To compare two hits vectors, we use an Euclidian distance instead of a cosine based distance because it is not accurate enough for sparse hits vectors. To compute the similarity between two users' histories, we define the set of the n Web pages of the site as an alphabet. Each history is then defined as a word. Each word is represented by a transition matrix M [n x n] where M(i,j) is equal to the number of transitions between the ith and the jth "letter" in the "word". Finally, the similarity between two histories is equal to the ratio of similar components between their respective transaction matrices.
We evaluate AntClust on sessions extracted from the log file of a computer sciences courses Web site of the University of Tours. It contains 248 pages grouped in several courses ("Operating Systems", "Internet security", ...). We extract 1064 sessions from the log file. 667 sessions are unique (their IP number appears only once in the sessions set). With many pages and few sessions but also with few hyperlinks between the pages, we expect the output clusters to represent a minimum of courses, to be valuable and understandable. We test 3 sessions models.
First, with all the features,
AntClust finds 21 clusters. 2 of them represent the half of the sessions and
deal with an operating system. As all the features are equally weighted, the
output clusters are a little bit noisy.
Second, with only the transaction feature, AntClust generates 20 clusters.
3 clusters gather the half of the sessions. There are not enough details in
the expression of the sessions to differentiate the relative importance of
each visited page.
Third, with only the “hits by
page” feature, AntClust reveals 17 clusters. Clusters only reflect one user’s
interest exception made of the 2 largest groups that deal with 2 or 3 online
computer sciences courses. Results are better than in the previous experiments.
One may interpret that a majority of users visited the Web site with no specific goal and looked at several courses to evaluate the content of the diploma. Other clusters may represent student that searched for specific courses. This experiment shows that AntClust is able to generate a non-noisy partition from Web sessions, that can help understanding the Web users’ interests. AntClust spends approximately 1.33 minutes on a Celeron 650 Mhz processor to cluster the 1064 users sessions, which is an affordable time in this context.
In this paper, we present a new definition of the Web sessions as a multi-modal vector and propose an adapted similarity measure. We apply AntClust, an ant based clustering algorithm on the log file of a computer sciences courses Web site. AntClust manages to generate meaningful clusters from sessions coded with "hits by page", that help interpreting the interests of the users. We plan in the future to evaluate AntClust with larger data sets and with several Web sites to validate our approach.