This paper proposes an evolutionary algorithm that evolves a population of finite state automata to exploit user navigational path behavior to predict, in real-time, future requests. Predicting user next requests is useful not only for document caching/prefetching, it is also suitable for quick dynamic adaptation to user behavior.
Web request prediction, Evolutionary Algorithm, User modeling.
The Internet provides a rich interactive environment to an increasingly expanding number of users. In attempting to improve navigation experience over the Internet, several optimization techniques may benefit from the availability of reliable prediction systems, able to foresee the next action of web users. One possible application for predicting user actions is to enable effective caching algorithms and prefetching techniques. Another interesting application of prediction systems is in the currently expanding field of web intelligence, for instance in dynamic site adaptation to users or dynamic customization; in this case user actions are monitored to restructure pages in a web site in order to reduce the time needed by users to reach useful information.
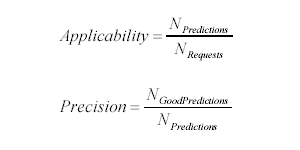
There has been an increasing amount of work on prediction models: web log based inference has been focused on prediction models that make best guesses on the user’s next action using information about their previous ones. Recommendation systems rely on a prediction model that infers user’s interest and make recommendations using the extracted information. Two figures of merit are usually adopted: the frequency with which the system is able to yield a prediction (applicability) and the frequency with which these predictions are correct (precision).
Existing prediction models can be either “point-based” or “path-based”. “Point-based” prediction models use frequency measures to predict next requests. The best results obtained show a prediction precision measure of over 50% and predictions applicability around 30% [3].
“Path-based” models are built on the user’s previous navigation path, they leverage a statistical analysis of user’s actions and can achieve good precision with moderately high applicability using large enough web logs (60% precision and 40% applicability using a 3gram model)[1,2].
Previous approaches are able to predict user actions in statistically stationary environments, only, i.e., when the statistical characteristics of user actions are constant or slowly evolving. In this paper we propose a new approach to evolve reliable predictions in real-time, to be able to react quickly to changes in user habits or in site structure.
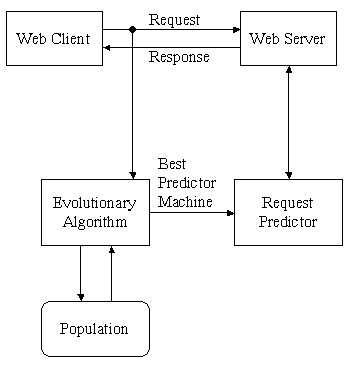
The prediction system (Fig. 1) we propose is designed to provide relatively good predictions without accessing large amounts of user requests, and rather representing them implicitly via prediction machines. It is also able to continuously operate using real time extracted information without saving historical information gathered from user sessions. The approach is based on an evolutionary strategy for evolving optimal prediction machines. Evolutionary strategies are used to reach an optimal solution for some complex optimization process, described by a group of parameters that can be used to assess the solution effectiveness. The fitness function definition in most applications is fixed and well known. In the prediction problem instead the evaluating function (fitness) is variable and defined (in our approach) as the weighted sum of applicability and precision.
The optimum solution is obtained by making a number of good predictions equal to the number of user's requests. The unpredictability of user actions is the great problem to deal with.
Traditionally proposed solutions are typically based on a statistical analysis of users requests on a long time period supposing that the general user behavior doesn’t vary too much in reasonably small time intervals. This assumption is not true in e-commerce, news and e-learning sites were users behavior is often influenced by external events that can lead to radical changes in users habits. The key difference between our approach and the previous ones is the real time operation capability without storing sessions and without web server log mining.
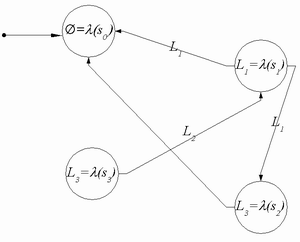
We designed a general model representing users next requests as a Finite State Machine, called a Prediction Machine, with a higher expressive power than N-grams [1]. Each state of the automaton represents a prediction, while transitions represent user requests.
Prediction Machines (Fig.2) are defined over a set of states S, a set of transitions T between states, and an alphabet L. The machine accepts the alphabet L and generates an alphabet L∪{∅}. States are labeled with a symbol from L∪{∅} , and transitions are labeled with a symbol from L. All self-loop transitions may be omitted, and are implicitly executed (i.e., whenever a state receives a symbol not corresponding to any of its outgoing transitions, it silently executes a self-loop). Prediction machine inputs are user requests, and outputs are predictions about the next request (or the absence of any prediction, when the state is labeled with ∅). The alphabet L corresponds to all possible user requests, and new symbols are added as soon as they are seen in the request stream.
The initial state represents the first prediction, corresponding to the first request of a session. All requests in the same session are passed to the prediction machine, and let it evolve through successive states. In each successive state the machine may yield a prediction about the next action.
All machines provide predictions for each user request in a session, the evolutionary algorithm is charged to evolve and select good ones while destroying the others.
The evolutionary algorithm goal is to evolve a population of
prediction machines using genetic operators like mutation and
recombination. The population is common to all users. When a new
session starts, the highest fitness machine is copied and used for
predicting each request in that session. We use a steady state
evolutionary paradigm E(μ+λ), thus at each generation the population is
composed of a mix of μ old and λ new machines. When a user session ends, λ
machines are selected for mutation, the resulting μ+λ population is evaluated
and the best μ individuals are extracted, while remaining elements
are destroyed. The fitness function f(m) of a machine
m is computed from applicability and precision. Function
f(m) is time-dependent since the evolutionary
algorithm must implement a real-time strategy. A partial fitness
value fP on a session s is:
The total fitness is computed as a weighted average of past
total fitness with the partial fitness contribution coming from the
last analyzed session.
The prediction system has been developed using the Java language, and we performed some initial evaluation experiments to assess the quality of the predictions and the effectiveness of the evolutionary algorithm. We chose a steady state E(100+20) evolution strategy for the algorithm. Predicting machine size was not a critical design factor and was only limited by the maximum memory allocation allowed to the prediction process (100 states for the initial evaluation). Evolutionary operators can be applied to the selected machine a random number of times.
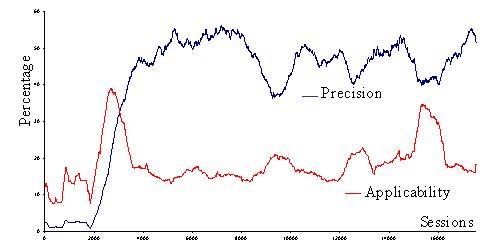
The initial population of prediction machines is composed of 100 randomly generated FSMs and preliminary results (Fig. 3) on a real-scale test case from a small e-commerce site are promising, and show that our approach is able to reach prediction quality comparable to that of point-based systems [3] (we reach an applicability maximum of 40% and a precision maximum of 55%), without requiring costly off-line analysis. In the near future we plan to do some further algorithm optimizations in order to obtain better performances.
The memory occupation of a single automaton ranges from 50K to 100K bytes, and the whole evolutionary algorithm requires about 10 MB of memory to operate. The CPU time required to evolve the entire automata population is relatively small, about 20 ms per session on a consumer PC.
In this paper we proposed an evolutionary approach for user requests prediction. Our work aims at showing that this new approach can be as effective as the ones currently under development (point-based, path-based), and at same time can dynamically adapt, in real-time, to changing user habits or site structure.