|
| Figure 1: A graphical representation of the layered presentation architecture |
What should a presentation architecture for a learning environment that offers a throughout individualization look like such that server load and hence response times remain within reasonable settings? To that extent, we have analyzed and structured the presentation process, and developed a general architecture for the generation of individualized web pages, targeted to the needs of educational domains. In short, we divided the presentation process in several separated stages, where each stage adds distinct individual information. This allows caching in several places.
Learning Environment, Presentation, Individualization, Learning Objects
Effective education requires individualization. The advantages of individually and dynamically generated courses over static scripts are numerous. For instance, providing the student with a course that contains content at his individual knowledge level increases motivation significantly. However, a learning environment that makes such an individualisation possible requires an appropriate course generation architecture. ActiveMath [3] for example, composes courses from single (XML) learning objects. For each user, the system chooses the appropriate objects (e.g., neither too easy nor too difficult exercises), and composes them to form a course. The question we cover in this article is what should a presentation architecture that transforms the learning objects into the required output format (HTML, PDF) look like such that server load and hence response times remain within reasonable settings.
To that extent, we have analyzed and structured the presentation process, and, building on this analysis, developed a general architecture for the generation of individualized web pages, targeted to the needs of educational domains. In short, we divided the presentation process in several separated stages, where each stage adds distinct individual information. This allows caching in several places.
Our first, non-layered presentation engine generates the pages in the desired output format by retrieving the learning objects from a database and assembling them to a page. The resulting XML-document is pre-processed (adding of server specific information) and transformed via XSLT, directly producing the (or PDF) page (annotated with additional individual information). This one-step transformation is repeated at every page request and consequently leads to severe performance problems and slow response times.
Caching complete pages or single fragments without restructuring the transformation process would not alleviate the problem, as the complete pages as well as the single fragments differ depending on the user.
We therefore performed an analysis of the data that is processed or added during the presentation process to determine to which extent the process could be optimized. We identified the following kinds:
Content. The presented content forms the major and most important type of data. Content is static in the sense that the containing text does not change. However, the overall content of a course is individual, as for different students different content is selected.
Server-Specific Information. This subsumes data added by the current server, such as the address of the server, links, or resource descriptions for interactive exercises.
Presentation Information. This data specifies how the learning objects are to be rendered (represented in XSLT-stylesheets).
Personal Information. While the individual learning materials that are presented to an user are covered by the above content type, personal information is additional individual data added on top of the content. An example is a red icon that appears next to a learning object the user has insufficient knowledge of.
|
|
| Figure 1: A graphical representation of the layered presentation architecture |
Following this analysis we split the presentation process in several layers, with each layer adding/transforming a specific kind of data. Figure 1 provides a graphical representation of the new architecture. The layers are the following:
Pre-Processing. Inserts server-specific information into the XML content. For instance, if the content is contained in several distributed knowledge bases, this step changes the ids of the learning objects to avoid duplicated ids.
Transformation. Performs a first transformation to the desired output format by the application of an XSLT-stylesheet to the document. The output of this stage are or LaTeX-fragments.
Assembly. Joins the fragments together to form the requested pages.
Personalization. Uses personal information to add individually different ``beautifications'' to the document, such as the red icon mentioned above, and for the generation the user name in the HTTP-links and the used CSS-stylesheet, for LaTeX the used macro-packages.
The diagram in Figure 1 indicates two points where caching can take place:
After Transformation. Applying XSLT-transformations requires a lot of resources. Therefore we decided to cache the individual learning objects after their transformation. A drawback is the additional memory consumption: For every output format, a proper cache is required. In addition, personalization data has to be separated out of the presentation data and added after the transformation. For , this can be achieved using another XSLT-transformation and/or JavaScript, for LaTeX, macros are used.
After Personalization. Caching a complete page speeds up access of often visited pages and going back/forward within a site. This cache is usually provided by the browser cache, but in an educational setting, this decision can only be taken by the learning environment itself, as more often than not, whether a specific page changes does not depend on the time passed since the last visit but on the actions taken by the user. Such a server side cache adds unrealistic memory requirements if an unlimited amount of users are working with the system. In an educational setting with a limited number of students participating in a course however, caching complete pages is feasible.
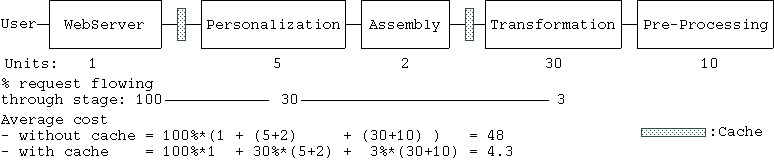
Figure 1 includes a first theoretical estimation of the costs of the old and new architecture based on our current experiences. The transformation and preprocessing costs units are weighted higher than other stages as they take the most resources. In the old architecture, the complete process is repeated for each request, yielding a total cost of 48. With the restructured presentation process and the caches that then are possible, only a very limited number of request make it to the transformation stage, thereby requiring an average cost of 4.3, about a tenth of the old cost.
Another advantage of the layered architecture is the personalization of third-party content not available in the underlying XML-representation. A lot of authors don't feel comfortable changing from their preferred content format to a new one, as the change requires new tools and adapting to the tools.
Performing the personalization in its own stage allows to personalize content not generated by the presentation process itself. These external documents definitely have to follow certain conventions; it is certainly not possible to personalize arbitrary documents (for instance, offers manifold ways to obtain a paragraph). Then, as a first compromise towards completely switching to a more advanced (XML) representation, authors can adapt their old content manually with following the conventions, e.g., representing a paragraph with the div tag, and adding an id attribute. Thereby, some personalization can be performed on this content, e.g., adding knowledge indicators.
Script-in-page approaches, such as Java Server Pages, that most web-based learning environments use, are not sufficient for the scope of individualization as targeted in this article. Two systems that provide more advanced individualization are [2] and [4]. Sadly, they do not provide details regarding technical aspects.
A general, very powerful presentation architecture is the Cocoon Publishing Framework [1]. It offers XSLT processing and caching at all levels. The Cocoon framework is very flexible, but consequently relatively complicated. Furthermore, it is hard to debug because of its purely stream-based processing (streams being either byte-streams or, most frequently, XML-parse-tree events). In comparison, our presentation architecture based on an in-memory XML-representation provides more expressive accessors and manipulations adapted to the specific XML encoding. This supports authors to detect and resolve presentation errors. Furthermore, integrating external documents is not easily possible.
We proposed a layered presentation architecture that divides the page generation in several stages, where each stage adds distinct information. Thereby, more elaborate caching strategies are possible than in an one-step generation.
This approach is applicable if more elaborate individualization takes place than simply inserting a user name. In scenarios where the content presented to the user is composed of parts that are retrieved from a knowledge base, depending on individual properties, the layered architecture can very well be applied and leads to noticeable performance increases.
The implementation of the layered presentation architecture is currently underway. We will then conduct exhaustive run-time analyses of the performance.