The information available in languages other than English on the World Wide Web is increasing significantly. To cross language boundaries between different languages, dictionaries are the most typical tools. However, the general-purpose dictionary is less sensitive in genre and domain and it is impractical to manually construct tailored bilingual dictionaries or sophisticated multilingual thesauri for large applications. Corpus-based approaches, which do not have the limitation of dictionaries, provide a statistical translation model to cross the language boundary. The objective of this research work is to mine English/Chinese parallel documents automatically from the World Wide Web and generate a cross-lingual concept space automatically for cross-lingual information retrieval. The alignment method is developed based on dynamic programming to identify the one-to-one Chinese and English title pairs for building parallel corpus. The Hopfield network is then employed to generate the cross-lingual concept space based on the statistical correlation analysis of the semantics (knowledge) embedded in the bilingual press release corpus. The research output consisted of a thesaurus-like, semantic network knowledge base, which can aid in semantics-based cross-lingual information management and retrieval.
alignment, corpus-based approach, covert translation, cross-lingual concept space, Hopfield network.
As the Web-based information systems emerge, searching information on the World Wide Web is on high demand, especially the demand of searching across language boundaries. This highlights the importance to develop a tool to refine a query in cross-lingual information retrieval. The major difficulties to retrieve relevant information are the lack of explicit semantic clustering of relevant information and the limits of conventional keyword-driven search techniques [1]. The traditional approaches normally require a document to share some keywords with the query. In reality, it is known that the users may use some keywords that are different from what used in the documents. There are then two different terms spaces, one for the users, and another for the documents. How to create relationships for the related terms between the two spaces is an important issue. The problem can be viewed as the creation of a concept space to cluster terms of similar concepts. The creation of such relationships would allow the system to match queries with relevant documents, even though they contain different terms.
In this paper, we present the construction of the Chinese-English cross-lingual concept space by using Hopfield network based on parallel corpora. Such concept space is important for solving vocabulary difference problem in cross-lingual information retrieval. Since our approach is developed based on the dynamic parallel corpora extracted from the World Wide Web and the information on the Web is frequently updated, the concept space generated can identify unknown terms that do not appear in dictionaries.
Parallel corpora can be generated using overt translation or covert translation. The overt translation [3] possesses a directional relationship between the pair of texts in two languages, which means texts in language A (source text) is translated into texts in language B (translated text) [9]. The covert translation [3] is non-directional. Multilingual documents expressing the same content in different languages are generated by the same source [2], e.g. press release from the government, commentaries on a sports event broadcast live in several languages by a broadcasting organization.
There are three major structures of parallel documents on the World Wide Web, parent page structure, sibling page structure, and monolingual sub-tree structure. The monolingual sub-tree structure contain a completely separate monolingual sub-tree for each language, with only the single top-level Web page pointing off to the root page of single-language version of the site [4]. Such structure is usually adopted by parallel corpora generated by covert translation. Press releases from the governments and organizations are generated in different languages for the same content independently using covert translation. As a result, the monolingual sub-tree structure is often used.
Alignment methods are required to map the parallel documents organized in monolingual sub-tree structure since links from the documents no longer provide any information of their counterparts. Length-based approach is typical for aligning bilingual documents. However, it is not practical for English/Chinese parallel documents since these languages are significantly different in grammar and structure. We have developed a text-based approach using the longest common subsequence (LCS) to optimize the alignment of English and Chinese titles [8]. Experiment results show that precision of 0.995 and recall of 0.8096 are achieved.
The automatic Chinese-English concept space generation system consists of three components: i) English phrase extraction, ii) Chinese phrase extraction, and iii) Hopfield network. The Chinese and English phrase extraction identifies important conceptual phrases in the corpora. The Hopfield network generates the cross-lingual concept space with the Chinese and English important conceptual phrases as input.
The English term segmentation is developed based on Salton [6] approach using stop-word, stemming and term-phrase formation. A stop-word list is used to remove non-semantic bearing words such as the, a, on, in, etc. The Chinese term segmentation is developed based on our previous developed technique, boundary detection [7], since there are not any natural delimiters in Chinese sentences to mark work boundaries.
After segmenting English and Chinese terms from the English and Chinese parallel corpus, only the most significant terms will be employed to form the concept space. The significant terms are selected based on the term weights, dij, computed by the term frequencies, inverse document frequencies and the length of terms. The term weight, dij, represents the relevance weight of term j in document i.
Given the English/Chinese parallel corpus, N pairs of English documents and Chinese documents, Ei and Ci (i = 1, 2, ..., N), are aligned. For each pair of English and Chinese documents, doc_pairi , the term weight for each extracted English term, termj , and each extracted Chinese term, termj* , are computed as follows:
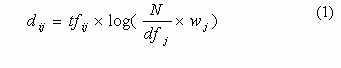
where dfj is the number of documents containing term j. wj is the length of term j. For an English term, the length of it is the number of words in it. For a Chinese term, the length of it is the number of characters in it.
Asymmetric co-occurrence function [1] is then used to evaluate the relevance weights among concepts. The co-occurrence weight is computed as follows:

The co-occurrence weight, dijk , is the weight between term j and term k that are both exist in document i . tfijk is the minimum between occurrence frequency of term j and that of term k in document i . The weight will be zero if neither term j or term k exists in the document.
The relevance weight is a measure of the association between two terms in a collection.
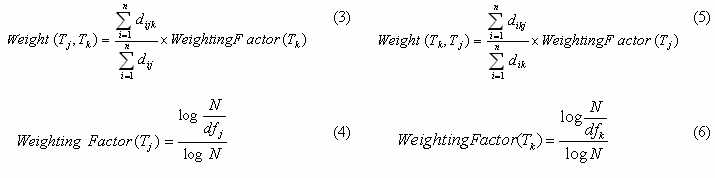
To generate the cross-lingual thesaurus, the Hopfield network is modeled as an associate network and transforms a noisy pattern into a stable state representation. The synaptic weights in the storage phase are generated by the co-occurrence analysis. In the canonical Hopfield Networks, if two nodes behave similarly in a sample pattern, the weight between these nodes is usually adjusted with a higher value. Similarly, the relevance weights that computed by Equation (3) and (5) are assigned as the synaptic weights since the relevance weights correspond to how these nodes are strongly associated. The higher the relevance weights between two terms, the stronger the corresponding nodes are associated. In the retrieval phase, a searcher starts with an English term. The Hopfield network spreading activation process will identify other relevant English term and gradually converge toward heavily linked Chinese term through association (or vice versa).
In our experiment, 4907 parallel documents were aligned from the press releases of the Hong Kong SAR government Web site. 10906 concepts were extracted from the parallel corpus. A user evaluation with 10 subjects was conducted. 50 test descriptors (25 English descriptors and 25 Chinese descriptors) were randomly selected from 10906 extracted concepts and presented to the subjects. In the recall phrase of the experiment, the subjects were asked to generate as many relevant terms as possible. In the recognition phrase, the test descriptors and the associated concepts generated by the Hopfield network were presented to the subjects. Noise terms are added in order to reduce the bias generated by the subjects on the concept space. The subjects were asked to determine if the associated concepts were relevant or irrelevant to the test descriptor. Measurement of concept precision and concept recall are utilized to assess the performance of the generated concept space. The precision is the number of retrieved relevant concepts judged as relevant by the subjects over the total number of retrieved concepts. The recall is the number of retrieved concepts judged as relevant by the subjects over the number of relevant concepts judged and suggested by the subjects. The overall concept precision and concept recall are 0.88 and 0.85 respectively. The concept precision and concept recall of the English concepts are 0.90 and 0.86, respectively. The concept precision and concept recall of the Chinese concepts are 0.89 and 0.87, respectively.
Cross-lingual information retrieval is important for Web searching as the Web pages in languages other English are growing significantly. In this work, we have developed an automatic generated concepts space to support cross-lingual information retrieval. Parallel corpora are automatically constructed from the World Wide Web. The associations between the extracted English and Chinese terms are determined statistically. The cross-lingual concept space is generated by the Hopfield network. The experiments show that high precision and recall is achieved.
This project was supported by the Direct Research Grant of the Chinese University of Hong Kong, 2050268, and the Earmarked Grant for Research by the Hong Kong Research Grant Council, 4335/02E.