The appearance of Peer-to-Peer (P2P) applications in recent years have demonstrated the significance of distributed information sharing systems. Regarding to the web-based multimedia retrieval systems, we envisage the potential use of distributed computation power in addition to data storage in P2P network to support enormous multimedia data without installing high-end database and hardware for the web server. However, current P2P applications require installing special purpose software and proprietary protocols for information retrieval, which limit the number of audience. To make use of the WWW to increase popularity of P2P, we propose to bridge the two different worlds, P2P and WWW. Thus, we distribute the workload and storage among peers to achieve a higher throughput while keep its accessibility through the web.
peer-to-peer; content-based multimedia retrieval; web integration;
In early web-based multimedia retrieval system, it requires human annotation and classification on the multimedia data, the query is thus performed using text-based information retrieval method. However, human interventions, non-standard description and linguistic barriers are the limitations for such implementation. In order to solve these problems, content-based multimedia retrieval system, like MARS [2], is proposed to pass such tedious task to computer. However, one of the shortcomings of this system is that the feature extraction, indexing and also the query processing are all done in a centralized fashion which is computationally intensive and difficult to scale up. One of the promising future trends in multimedia retrieval system includes the distribution of data collection, data processing and information retrieval. By extending the centralized web server model, we greatly increase the storage size of multimedia collections and overcome the scalability bottleneck problem by distributing the computationally intensive tasks.
P2P network is a recently evolved paradigm for distributed computing. With the emerging P2P networks and various implementations, they offer the advantages of distributed resource, increased reliability and comprehensiveness of information. Unlike the client-server architecture of the web, the P2P network aims at allowing individual computer to share information directly with each other without the help of dedicated servers. To address the desirabilities of P2P application raised above, we purpose the DIStributed COntent-based Visual Information Retrieval system (DISCOVIR) [1] which demonstrates the possibility to migrate the traditional web-based multimedia retrieval system to a P2P environment and purpose the DISCOVIR Everywhere which provides an interface to bridge P2P and WWW.
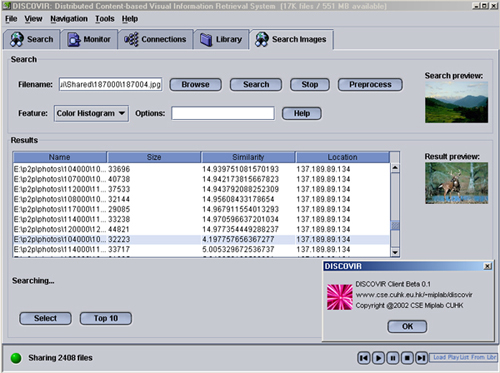
DISCOVIR, as shown in Fig. 1, is a software package which extends current centralized retrieval system to enable individuals to search for and share multimedia files based on their contents among others through the P2P network. Unlike other P2P applications, like Napster and Gnutella, the queries in DISCOVIR are no longer limited to simple filename or meta-data but on the visual properties (such as color, texture, and shape). The query accuracy no longer depends on subjective perception of keywords because the need for annotating shared files is waived.
Figure 2 depicts the key components and their interactions in the architecture of a DISCOVIR client. Connection Manager, Packet Router and HTTP Agent are responsible for managing the connection and packets routing in the P2P network. They are modified according to the FQM [3] query mechanism to improve the query efficiency used in the original P2P network. Some components are introduced to support multimedia processing and retrieval tasks. Plug-in Manager coordinates the communications between different feature extraction modules and their interaction with Feature Extractor and Indexer. Feature Extractor perform various feature extraction on the shared multimedia data, such as text, audio and images. For example, BibTeX and PDF Feature Extractors are developed to support complicated text searching. Other image feature extractors are developed to support query based on the color, texture and shape of the images. Indexer then indexes the extracted features and carry out clustering to speed up the retrieval process.

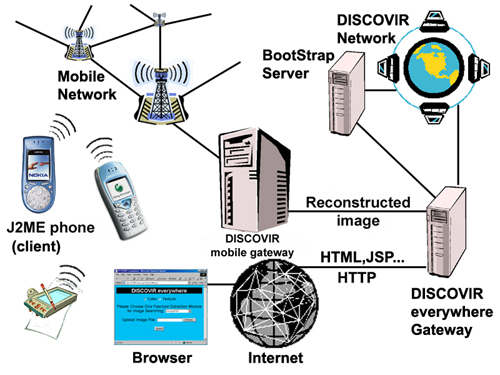
Although migrating multimedia retrieval system to P2P network has many advantages as aforementioned, DISCOVIR still encounters limitations like the requirement of installing client software and the low accessibility compared to WWW. For this reason, DISCOVIR Everywhere is developed. Unlike other existed web-based P2P applications, like AsiaYeah, the web server does not act like a peer in the P2P network. Instead, it acts as a matchmaker to coordinate the communications between web clients and peers.
Referring to Fig. 3, we identify two main components in its design, they are DISCOVIR Bootstrap Server and DISCOVIR Everywhere Gateway. DISCOVIR Bootstrap Server is the host cache of P2P network. In addition, it is responsible for maintaining an updated list of accessible DISCOVIR peers and their availability for providing HTTP access. DISCOVIR Everywhere Gateway is a server providing users with web-based searching interface and redirects query to different peers. For the mobile users, as mobile phones do not have permanent storage, they need to sketch a drawing and send this data to DISCOVIR mobile gateway. The mobile gateway then use these data to reconstruct an image and post the query to the DISCOVIR Everywhere Gateway.
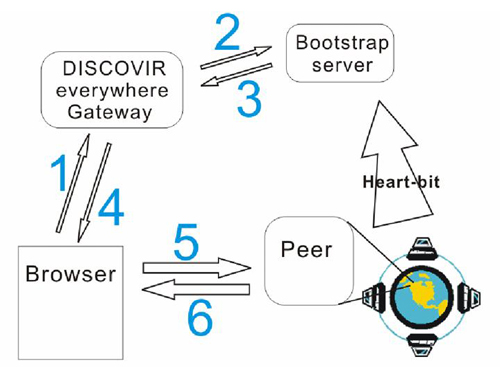
The procedures of query are shown in Fig. 4, it consists of six main steps:
Step 1-2: A web client user initiates a query request through the web interface provided by DISCOVIR Everywhere Gateway. The Gateway receives the request and inquire the bootstrap server about the IP address and port number of a DISCOVIR peer capable of handling this query.
Step 3-4: Upon receiving the inquiry from the Gateway, the DISCOVIR Bootstrap Server picks one of the available peers in a round robin manner in order to distribute the workload evenly. Once knowing the IP address of peer capable of handling the query, the Gateway generates a HTML page instantly for user to submit his query to the selected peer using standard HTML POST protocol.
Step 5-6: The web client user submits the query to selected DISCOVIR peer through a HTTP POST request. The selected peer then helps to assemble the query message and broadcast it in the P2P network. This HTTP connection is kept to open until results return from this selected peer. Once the selected peer accumulates up to a certain number of results or reaches a time limit, it packages the result in HTML format and sends back to web client user.
In this paper, we illustrate the design and implementation of DISCOVIR, which enable users to search multimedia data, like image and bibtex file, based on the content itself in the P2P network. We also illustrate how its accessibility can be improved through the design of DISCOVIR Everywhere.