In this paper, we present a new strategy for information retrieval over peer-to-peer (P2P) network. First, we propose a method for clustering peers that share similar properties together, thus, data inside the P2P network are organized in a fashion similar to a Yellow Pages. In order to make use of our clustered P2P network efficiently, we also propose a new intelligent query routing strategy, the Firework Query Model, which aims to route the query intelligently according to the content of query to reduce the network traffic. We demonstrate its scalability and efficiency through simulation.
Peer-to-Peer (P2P) Application, Content-based Query Routing, Multimedia Clustering, Information Retrieval
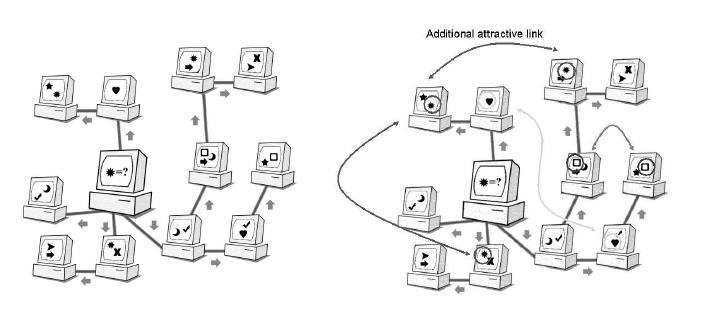
The appearance of Peer-to-Peer (P2P) applications such as Gnutella [1] and Napster [2] have demonstrated the significance of distributed information sharing systems. These systems offers advantages of resource utilization, increased reliability and comprehensiveness of information. Figure 1a shows an example of a P2P network that different information are shared by different peers. When a peer initiates a search, it broadcasts a query request to its connecting peers. Its peers then propagate the request to their own peers and this process continues. Messages are sent over multiple hops from one peer to another while each peer responds to queries for information it shares locally.
Although P2P network has many advantages as aforementioned, it still encounters limitations like the scalability problems. Flooding of message is one of the main problem. Each peer is also forced to waste resources in handling irrelevant query. In order to improve the efficiency, our proposed strategy first clusters peers of similar properties together, just like the organization in a Yellow Pages, which makes query more systematic. Besides, our intelligent Firework Query Model will help in reducing network traffic by forwarding query selectively rather than the original Brute-Force-Search (BFS) broadcasting. In our model, the query message first walks around the network, once it reaches the target cluster, the query message is broadcasted inside the cluster much like an exploding firework [3].
In our proposed network, there are two types of connections, namely random and attractive as shown in Figure 1b. Random connections are the original connections used in the current P2P network. Attractive connections are newly introduced to link peers sharing similar data together. Table 1 shows the notation used to describe our proposed P2P network.
The algorithm of Peer Clustering illustrated in Algorithm 1 consists of three main steps:
1. Signature Value Calculation -- Processes its shared data collection, uses a clustering algorithm, e.g.k-means, to divide the data into sub-clusters and calculates a set of signature values SIGv to characterize them.
2. Neighborhood Discovery -- Broadcasts a signature query message to reveal the data characteristic of its neighborhood. This task repeats every certain interval to maintain the latest information of other peers.
3. Attractive Connection Establishment -- Acquires the signature values of other peers, make an attractive connection to the peer with highest data affinity (similarity) to link them up. When an existing attractive connection breaks, it should check its cache of signature values and reestablish the connection.

Here, we introduce the algorithm to determine when and how a query message is propagated through attractive links and explode like a firework in Algorithm 2. it consists of two main steps:
1. Shared File Look Up -- The peer looks up its shared information for those matched with the query. If any shared information within the matching criteria of the query, the peer will reply the requester.
2. Route Selection -- The peer calculates the distance between the query and each signature value of its local clusters, SIGv. If one or more Dq(SIGv ,q) is within the threshold, it implies the query has reached its target cluster. Therefore, the query will be broadcasted through corresponding attractive connections while the TTL will be decremented by a probability called CTS (Chance To Survive), otherwise, it is propagated through random connections.

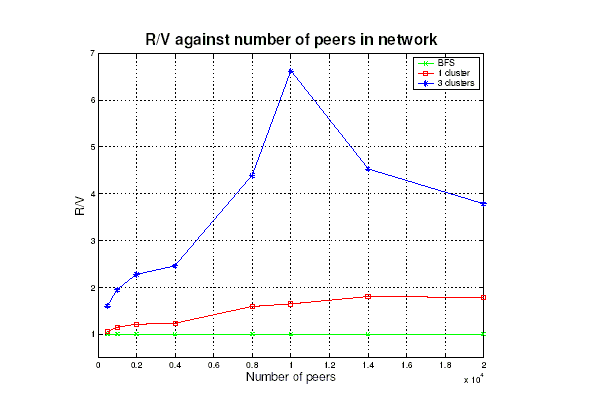
Two main goals of routing algorithm in P2P network are to increase the percentage of desired result retrieved (Recall - R) and decrease the percentage of peers visited (Visited - V) for a query. Therefore, we define the query efficiency as R/V and measure it against different number of peers using different methods: (1) Brute Force Search (BFS), (2) FQM with 1 signature value per peer, (3) FQM with 3 signature values per peer. In the simulation, we generate a certain number of peers and randomly assign different classes of data points to each of them. Then, We initiate a query starting from a randomly selected peer and the retrieved data point is treated as desired result if it belongs to the same class as the query point. As seen in Figure 2, FQM outperforms BFS algorithm and it can perform even better if an appropriate number of signature values per peer is used.
In this paper, we propose a peer clustering and content-based routing strategy to retrieve information based on their content efficiently over the P2P network. We verify our proposed strategy by simulations and show that our strategy outperforms the BFS method in both network traffic cost and query efficiency measure.