 (1)
(1)For the TREC-style questions, the query terms we get from the original questions are either too brief or often do not contain much relevant information in the corpus. It will be very difficult to find an exact answer in a large corpus because of the surface string mismatch. In order to solve this problem, we present a question answering system called QUALIFIER, which employs a novel approach to structurally model the external knowledge from the Web and other resource for Event-based question answering. The results obtained on TREC-11 QA corpus demonstrate that the approach is effective.
Question answering, web knowledge modeling, query formulation, semantic grouping
Open Domain Question Answering (QA) is an information retrieval (IR) paradigm. Modern QA systems [1, 2] combine the strengths of traditional IR, natural language processing and information extraction to provide an appropriate way to retrieve concise answers to open-domain natural language questions against the QA corpus. Most of the QA system employ a framework containing question analysis, query formulation, document retrieval, answer extraction and validation modules. Because of the abundance of information on the Web, researchers [1, 3, 5, 6] started to seek quick answers on the Web for simple, factoid questions. Apart from those Web-based QA systems who find answers from the Web directly, we use the Web as an external knowledge base to help query formulation and locate the answers in the QA corpus. In TREC-11 [7], our group employed an innovative approach to model the lexical and world knowledge from the Web and WordNet to support effective QA. This paper investigates the integration and structured use of both world and linguistic knowledge for QA. In particular, we describe a high performance question answering system called QUALIFIER (QUestion Answering by LexIcal FabrIc and External Resources) and analyze its effectiveness by using the TREC-11 benchmark.
We propose a novel way to investigate the QA problem and find the solution, which we called Event-based Question Answering . The world consists of two basic types of things: entities("anything having existence (living or nonliving)") and events ("something that happens at a given place and time") and people often ask questions about them. If we apply this taxonomy to TREC-style QA task, questions can be considered as "enquiries about either entities or events". Generally, questions often show great interests in several aspects or elements of QA events, namely Location, Time, Subject, Object, Quantity, Description and Action, etc. Table 1 shows the correspondences of the most common WH-question classes and the QA event elements.
Table 1: Correspondence of WH-Questions & Event Elements
|
WH-Question |
QA Event Elements |
|
Who/Whose/Whom |
Subject, Object |
|
Where |
Location |
|
When |
Time |
|
What |
Subject, Object, Description, Action |
|
Which |
Subject, Object, |
|
How |
Quantity, Description |
Our main observation is that a QA event shows great cohesive affinity to all its elements and the elements are likely to be closely coupled by this event. Normally, the question itself provides some known elements and asks for the unknown element(s). However, for most of the cases, it is difficult to find a correct answer, i.e., the correct unknown element(s). To solve the problems of insufficient known elements and inexact known elements, we model the Web and linguistic knowledge to perform effective QA.
As the Web is the most rapidly growing and complete knowledge resource in the world, QUALIFIER uses it as an external knowledge resource to solve the problem of insufficient known elements. The terms in the relevant web documents are likely to be similar to or even the same as those in the QA corpus since they both contain the same information about natural facts (QA Entity) or the current or historical events (QA Event).
QUALIFIER stores the original content words in q(0) to retrieve the top Nw documents in the Web search engine (E.g. Google) and then extract the terms in those documents that are highly correlated with the original query terms. That is, for "qi(0)Îq(0), it extracts the list of nearby non-trivial words, wi, that are in the same sentence or snippet as qi(0). We compute the weights for all terms tikÎwi as:
(1)
Finally, QUALIFIER merges all wi to form Cqfor q(0). It then uses WordNet as a filter to adjust the term weights. The final weight of each term is normalized and the top m terms above the cut-off threshold σ are selected to expand the original query:
q(1)= q(0)+{top m termsÎCq with weights greater than σ} (2)
where m is initially set to 20 in our experiments.The expanded query should contain more known elements of the QA event. If we classify the terms in q(1), they are actually corresponding to one or more of the QA event elements we discussed in Section 2. We explore the use of semantic grouping to structurally utilize the external knowledge extracted from the Web. Given any two distinct terms ti, tj, we compute their:
| Rl(ti, tj) = |
|
1, if ti and tjÎ same synset; |
| 0, otherwise. | (3) |
 (4)
(4)
 (5)
(5)
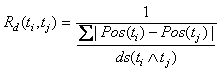 (6)
(6)
We then cluster the terms into different semantic groups using a modified version of the algorithm outlined in [4]. We believe that the knowledge embedded in the Web about this QA Event can be modeled and represented by the semantic groups. From the semantic groups derived, we form a structured query by selecting key terms from the semantic groups. The structured query is then passed to the document retrieval and answer selection engines to extract the exact answers from the top returned documents. For example, for the question "What Spanish explorer discovered the Mississippi River?", the semantic groups we obtained after performing the knowledge modeling and clustering are illustrated in Figure 1. The figure clearly shows that we are able to extract different aspects (or elements) of the QA event, such as the time (1541), the name of the river (Mississippi), the name of the explorer (Hernando De Soto), the nationality of the explorer (Spanish or French) and other descriptions(First, River, European). One promising advantage of our approach is that we can answer any factual questions about the elements in this QA event. For instance, "When was Mississippi River discovered?" and "Which river was discovered by Hernando De Soto?" etc.
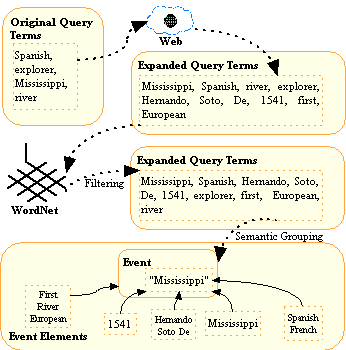
Figure 1: Example for Structured Query Formulation
For the NIST human assessment on the 500 questions of TREC-11 QA track. QUALIFIER answers 290 questions correctly with confidence weighted score of 0.610, which places us as one of the top three performing systems. Table 2 gives the statistics of our system and Table 3 compares the performance between our system and other Web-based QA systems in TREC-11 [7].
Table 2: Performance over TREC-11 500 Questions
|
#
right |
290 |
Precision
|
0.580 |
|
#
unsupported |
18 |
Confidence-weight
score |
0.610 |
|
#
inexact |
17 |
Precision
of recognizing NIL |
0.241 |
|
#
wrong |
175 |
Recall
of recognizing NIL |
0.891 |
Table 3: Comparison with other Web-based QA systems in TREC-11
|
Runs |
Precision |
Confidence-weighted score |
|
nsirgn (Radev et al, U. Michigan) |
0.178 |
0.283 |
|
aranea02a (Lin et al, MIT) |
0.304 |
0.433 |
|
uwmtB3 (Clarke et al , U. Waterloo) |
0.368 |
0.512 |
|
pris2002 (QUALIFIER) |
0.580 |
0.610 |
For Web search, we adopt Google as the search engine and examine snippets instead of looking at full web pages as reported in [8, 9]. We study the performance of QUALIFIER by varying the number of top ranked web pages returned Nw, and the cut-off threshold σ (see Eqn 2) for selecting the terms in Cq. Table 4 summarizes the effects of these variations on the performance of TREC-11 questions by showing the precision, which is the ratio of correct answers returned by QUALIFIER. From the results, we can see that the best result is obtained when Nw = 75 and σ = 0.2.
Table 4: The Precision Score of 25 Web Runs
|
σ\
Nw |
10 |
25 |
50 |
75 |
100 |
|
0.1 |
0.492 |
0.492 |
0.494 |
0.500 |
0.504 |
|
0.2 |
0.536 |
0.536 |
0.538 |
0.548 |
0.544 |
|
0.3 |
0.506 |
0.506 |
0.512 |
0.512 |
0.512 |
|
0.4 |
0.426 |
0.426 |
0.430 |
0.432 |
0.428 |
|
0.5 |
0.398 |
0.398 |
0.412 |
0.418 |
0.412 |
We conducted several tests on modeling the knowledge to perform event-based QA. For each run, we compute P, the precision, and CWS, the confidence-weighted score. Table 5 summarizes the test results:
Table 5: Results of Different Query Formulation Methods
|
Method |
P |
CWS |
|
a) Baseline |
0.438 |
0.640 |
|
b) Baseline + Web |
0.548 |
0.754 |
|
c) Baseline + Web + WordNet
|
0.588 |
0.795 |
|
d) Baseline + Web + WordNet + semantic
grouping |
0.634 |
0.824 |
Here we can draw the following observations:
Other researchers have recently looked to the web as a resource for question answering. The Mulder system illustrated by Kwok et al [5] submits multiple queries for one question to a web search engine and analyzes the results. Mulder performs sophisticated parsing of query and full-text of retrieved pages in order to locate the answsers. However, they did not test their system using the TREC queries. Brill et al [1] and Clarke et al [2] investigated the importance of redundancy in their question answering systems. Clarke et al use web data to reinforce the scores of promising candidate answers by providing additional redundancy from the auxiliary web corpus and global term weighting. Brill et al [1] use the search engine summary as the primary source of redundancy, and operate the system without a full-text index of documents or a database of global term weights. Similar to Mulder, they extract the answers from the Web directly. Radev et al [6] describe a number of probabilistic approaches to passage extraction, phrase extraction, and answer ranking modules employed in the typical QA systems.
In constrast, our approach differs from existing approaches on the use of the Web in one or more of the following aspects. First, our system focus on the use of web to support query formulation, instead of using the Web as the primary source of answers. Second, we fuse the knowledge from both the Web and WordNet. Third and most distinctively, we perform structured modeling of the Web and WordNet knowledge to extract most event elements and support event-based QA.
We have presented the techniques used in the QUALIFIER system, which employs a novel approach to Event-based QA with the modeling of the Web knowledge. Using the structured query formulation, we can achieve an answer accuracy of 0.63 and CWS of 0.82, which showed the effectiveness of our approach.