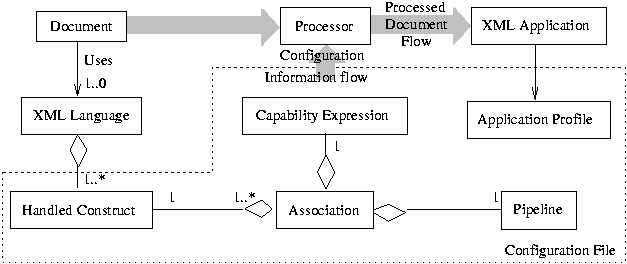
Figure 1: Information Flow
XML languages are increasingly used for representations aimed to XML applications running on a variety of platforms. We have developed an architecture that automatically constructs combinations of XML processing pipelines that produce device specific representations. This is achieved by associating sets of elements and attributes of XML languages to processing pipelines according to platform capabilities.
XML Processing, pipelines, XSL-T, heterogeneous documents
XML is increasingly used for independent development of XML languages, where their semantics are enforced by the XML applications that process the corresponding documents. Using XML as a universal means of exchanging information requires a generic way to combine several independently developed XML languages and processing modules for presentation on heterogeneous platforms.
A significant XML processing phase is the document transformation to a data set tailored for a specific XML application. Currently, transformations are often associated with XML documents[1]. However, if transformations are viewed as processes corresponding to the meaning of XML languages[3], they can be associated with the qualified name of the document element. We use an even more fine grained approach, where transformations are associated with a set of qualified element and attribute names which we call a handled construct.
We have developed an architecture based on handling associations, between handled constructs and transformation pipelines, that are characterized by platform capability expressions. For each XML application we define a corresponding application profile that is a set of statements on the supported XML languages and the platform capabilities. A capability expression can be evaluated, for an application profile, to identify the optimal processing of a handled construct for an XML application. A transformation pipeline is constructed from simpler ones by sequential, selection (based on the application profile) and dynamic (dynamic construction of the transformation) composition. The simplest (i.e. indivisible) pipeline is a single transformation step which can be directly instantiated by a Java class or an XSL-T transformation.
For a given an application profile, adequate handling associations and a document, a combination of transformation pipelines is constructed that converts the document to a data set tailored for an XML application. There are several other approaches that address the individual issues of transformation pipelines, transformation associations and capability expressions[1, 2, 4]. However, addressing all these within a unified architecture allows a generic way to process heterogeneous documents for different platforms.
A top level diagram of the information flow is represented in Figure 1. The "Processor" is responsible for transforming the input document according to an application profile. Specifically, for each instance of a handled construct in the XML document, the processor tries to find the most appropriate processing pipeline. This is achieved by evaluating the capability expressions for each of the pipeline associations and choosing the one that yields the best match (if there is no match, the document cannot be processed). This process is repeated until all the constructs in the transformed document are supported by the specified application profile. All the information required for this processing is included in a single, XML based, configuration file. The issues raised by such a processing approach are considered in the following sections.
Figure 1: Information Flow
A generic way to allow integration of XML languages within
a document and interoperation of the
respective handlers is an important and unsolved problem.
Nevertheless, our architecture can provide a sufficiently
generic integration approach, since, it only acts as a transformation step
and important problems (such as the generic interoperation
of presentational handlers) are left to the end XML application.
To achieve this, we separate XML languages to content oriented
languages (COL), such as XHTML and SMIL, and functionality
oriented ones (FOL), such as XML Links and XML Include.
On the syntax level, FOL constructs can occur at any
place in an XML document
(as far as the document remains well formed)
while COL constructs occur only
at places where content is "expected". The latter is
enforced by constraints such as the XML Schema's
<any> type.
Since languages and their transformers are generally independently developed, we cannot except transformers to interoperate. Consequently, transformations simply copy any unrecognized content found in places where COL constructs are expected. Handled constructs are processed in a depth first manner, so that any unknown content copied by a transformer will be a fully processed sub-tree.
A preprocessing phase accommodates FOL constructs that do not appear as "leaf" subtrees in a document. The handlers of their enclosing constructs might not copy them, since they can occur at any place in a document. In the preprocessing phase, any FOL constructs which are flagged as prioritized are handled.
Approaches such as XPipe[2] provide versatile transformation pipeline construction schemes. Our pipeline construction contains only the most usual cases of transformation pipelines as we do not aim to address transformation language shortcomings by a more expressive higher layer.
Transformation pipelines
are constructed from simpler pipelines of the types
illustrated in Figure 2. The atomic construction block is the
SimpleTransform which is instantiated by a Java class
and may have an XML document as a parameter
(e.g. so that an XSL-T Transformer (XSLTTransformer) can
use a stylesheet as a parameter). The SequenceTransform
sequentially arranges simple pipelines so that each
of them processes the output of the previous one.
DynamicTransform allows the "optional" XML
parameter of a SimpleTransform to be
constructed by the output of another pipeline.
Finally, the SelectionTransform is essentially
a "case" construct that allows different pipelines to
be applied according to the specified application profile.
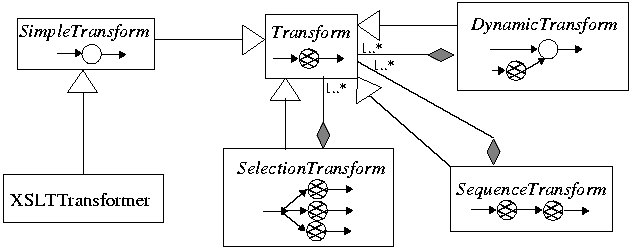
Figure 2: Transformation pipelines
The associations of handled constructs and processing pipelines tie everything together and allow device neutral XML processing. We have already described the application profiles as sets of statements. Each of these statements has a corresponding term and a value. The terms are URI qualified names (to ensure uniqueness) that can be defined in the configuration file. Each association can have a corresponding set of capabilities expressions which are used to identify the optimal processing for each application profile.
Each expression uses exactly one term
and evaluates to a number in [0, 1] where 1 represents
a "perfect match", 0 a "mismatch" and any other
value a "partial match". For instance, the expression:
tests if the application profile (the predefined term
"supports") supports XHTML 1.0. A more interesting
example is:
<expr ns="uri:ukc.ac.uk/~mp49/xml/terms/"
name="supports">
<contains>
<termVal>
<val>http://www.w3.org/1999/xhtml</val>
</contains>
</expr>
which is equivalent to (x - 400)/624 which
is a measure for the screen width (1024 is optimal,
400 and less are not accepted). When more than one
expressions exist, their values are simply summed up
to produce the matching measure for an association.
If ei(x) is the value of an expression for the
application profile x, and if
<expr ns="uri:ukc.ac.uk/~mp49/xml/terms"
name="screenWidth">
<div>
<sub><termVal><val>400</val></sub>
<val>624</val>
</div>
</expr>
![eval(y)=0 for y in [0,1], 0 for y less than 0 and 1 for y more than 1](./p108-Pediaditakis-fig3.gif) then
then 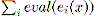 is the matching factor for the profile x.
The association that produces the greatest sum is selected.
We do not need a weighted average because we can
only have one term per expression and we can assume
that terms are equivalent (since they are not
predefined). Selection of a reasonable set of expressions
will ensure that the
most specific association is chosen.
is the matching factor for the profile x.
The association that produces the greatest sum is selected.
We do not need a weighted average because we can
only have one term per expression and we can assume
that terms are equivalent (since they are not
predefined). Selection of a reasonable set of expressions
will ensure that the
most specific association is chosen.
Summarizing, our architecture uses capability expression based associations of handled constructs and processing pipelines to transform documents to their optimal final form representation for a platform. There is a number of important benefits. Firstly, we have straightforward handling of heterogeneous XML documents due to the transformation design guideline (to copy unrecognized content), the preprocessing step and the association of processing with handled constructs instead of document instances. Moreover, the use of pipelines allows component reuse and declarative construction of pipelines that were typically described using scripting languages. Additionally, the capability expressions allow automatic customized processing for a specific platform. Lastly, the final user is not aware of either the document structure or the associated semantics. As far as there is enough information in the configuration file, the user only specifies the device capabilities and the final form representation is produced.
We are currently implementing this architecture and the results from a preliminary experimental implementation are encouraging. We successfully achieved the processing of a document (which used three separate XML languages for the text, graphics and content inclusion) for two significantly different devices: a desktop browser and a WAP phone supporting only WML 1.0 and WBMP. We expect to have a public release soon, as well as, more information on the implementation issues.