In this paper, we propose a framework called CQ-Buddy, for supporting distributed continuous query (CQ) processing system based on Peer-to-Peer (P2P) technology. Working on the basis of peer heterogeneity, peers in a CQ-Buddy network "help" one another by sharing query workload and providing data. Our main contributions are as follows: first, CQ-Buddy introduces a novel class of queries, called pervasive continuous queries, for disconnected operations which are common in the peer-to-peer environment; second, the framework presents two strategies, SELF-HELP, and BUDDY-HELP, that allow for the grouping and sharing of multiple continuous queries amongst peers; third, by keeping peers that are processing the continuous queries in close proximity, the network bandwidth can be more effectively utilized. We conduct an extensive performance study to evaluate the proposed strategies, and our results show the effectiveness of the proposed schemes.
Peer-to-Peer, Continuous queries, Query sharing, Pervasive Continuous queries, Distributed Computing, CQ-Buddy.
Continuous queries (CQ) are queries that are executed for a potentially long period of time, and are used in the monitoring of data semantics in the underlying data streams to trigger user-defined actions. Continuous queries transform a passive networked structure into an active environment, and are particularly useful in distributed environments where huge volumes of information are updated frequently and remotely.
Most existing CQ systems are designed and implemented on a client-server architecture, and do not scale well in a distributed environment for these reasons: (i) the data provider may develop a bottleneck, (ii) there may be duplicate processing amongst nodes, and (iii) the heterogeneity of the nodes.
In this paper, we propose a novel distributed system that processes continuous queries using Peer-to-Peer technology, called CQ-Buddy. CQ-Buddy is able to provide significant performance gains by sharing continuous queries with other peers in an efficient and effective manner. CQ-Buddy is distributed and highly scalable as there is no single-point failure and single-source bottleneck. Peers in the CQ-Buddy network also turn their heterogeneity to their advantage, so that "weaker" peers (e.g., PDAs, mobile devices) are helped by "stronger" peers for complex queries processing.
We refer to a node in a distributed network as a peer. We address the problem in two different aspects. First, we study how similar queries can be grouped and shared amongst peers. Second, we introduce the notion of pervasive continuous queries and show how peers can benefit from the pervasiveness.
In the literature on continuous query systems (CQS) [3,6], one of the most frequently tackled issues is the need to handle a large number of queries effectively and efficiently. There is recognition in the literature that of the large number of continuous queries issued by users, many are similar. By detecting these similarities, the queries can be processed collectively. That in turn means a significant reduction in resources needed to process the queries.
Most of the existing work, however, focuses on the sharing of computation in a single CQS. To the best of our knowledge, there exists little work that studies the sharing of similar queries in a large network of peers. Yet compared with a single CQS, there are more opportunities for the sharing of computation for similar queries amongst peers.
In CQ-Buddy, similar queries (The definitions of similar query are omitted due to space constraints. It suffices to say here that there are predicate, projection and data sources similarities defined for our context) are grouped to be processed collectively either by the peer in which the query is issued or by other peers in the CQ-Buddy network. The peer then broadcasts a message to other peers in the CQ-network to identify buddy peers that can help in processing similar queries. It is important to note that the ability of a peer to help other peers is necessary and practical in a P2P environment.
In our work, we study two strategies in sharing computation. In the first strategy, which we refer to as SELF-HELP, a peer initiates a new processing task to handle a new query that it has received. In this manner, the peer is behaving exactly like a single CQS. In the second strategy, which we refer to as BUDDY-HELP, the peer asks its buddy peers for "help" in processing the query. The buddy peers then process the query on behalf of the peer, and provide the peer with the results of the continuous query.
In a heterogeneous operating environment, peers may be devices of different computing power, such as PDAs, desktops or notebooks. The basic idea is to allow a peer that is "weaker'' to ask its buddy peers for "help'' when processing continuous queries. For example, let us consider a business traveller with a PDA. Prior to boarding the plane, she issues a query using the peer software on her PDA. When she boards the plane, the PDA is disconnected from its network of peers. But before the disconnection, the PDA asks for "help" to perform the query amongst its buddy peers. When the traveller arrives at her destination, her PDA rejoins its network. Immediately, its buddy peers provide it with the information requested.
The above example, however, is an ideal situation. It is important to note that in existing continuous query systems, support for such disconnected query processing is not readily available. There is therefore room for a novel class of continuous queries that are processed by a peer on behalf of another peer, and which provide the requested information to be retrieved at a later time. We refer to these queries as pervasive continuous queries.
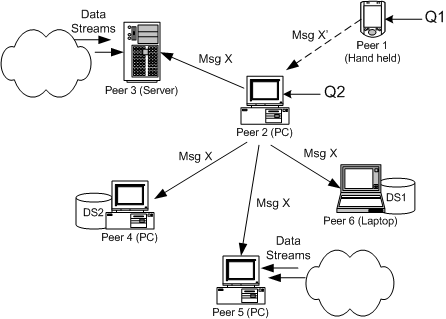
Figure 1: Overview of CQ-Buddy Network.
Figure 1 shows a CQ-Buddy network with several peers including a handheld device (Peer 1), laptop (Peer 6), PCs and a server-type peer. An incoming query Q2 = select *from nyse.stream where Stock.symbol ='MSN' or Stock.symbol ='ORA' is submitted to Peer 2. Peer 2 will then ask for help from the other peers in the CQ-Buddy network by sending the following message to those peers: Who can handle query select * from nyse.stream where Stock.symbol = X?. The objective is to locate peers which are processing similar queries (i.e., monitoring data source nyse.stream with projection attributes Stock.symbol). When the other peers receive the request, they may either handle the query if they have similar queries running in their local process pools, or drop the message otherwise.
Peers which are able to handle the query will send an acknowledgement directly to Peer 2 with its identity, BPID (CQ-Buddy is built on top of BestPeer, and BPID is a global identity used in BestPeer to uniquely identify different peers and their respective location in a dynamic network). Peer 2 keeps the BPIDs, which may be used for further reference, e.g., to remove the query. Peer 2 has no advance knowledge of the number of peers that will respond. Instead, it relies on a user-defined threshold on the number of peers which respond to the broadcasted message. Here, it is possible that there are no responses from the peers. The query will be processed by Peer 2, which possesses of CQ processing capabilities.

Figure 2: Architecture of CQ-Buddy.
Figure 2 depicts the architecture of an autonomous peer in CQ-Buddy.
CQ-Buddy is an extension of the BestPeer [5] platform that provides low-level
P2P facilities such as communication and search. Each peer in a CQ-Buddy network
is capable of supporting pervasive continuous queries. In our model, each CQ-Buddy
consists of two components: optimization (i.e. grouping of similar queries),
and evaluation. The core of a peer in CQ-Buddy is the CQ-Manager that
accepts user queries through a user interface and then invokes the underlying
execution engine. Each query is optimized by the Query/Group optimizer, where
it is integrated into a group of queries if it is similar to them. The queries
or grouped queries will then be used as input for the P2P search engine to locate
the peer that can handle the queries. The data manager in each peer monitors
the underlying data sources, which range from static data sources to data streams
from remote data sources. It is responsible for notifying the CQ-Manager of
any data modification. There are two possible actions when changes are detected.
First, CQ-Manager invokes the execution engine to evaluate the installed continuous
queries. Second, the CQ-Manager pushes the changed data to intermediate peers.
Due to space constraints, we present only the comparison between existing CQS and CQ-Buddy (full description can be found in [4]). For the purpose of comparison, we classify existing CQS into two categories. We refer to CQS where there is sharing of resources and computation amongst multiple queries[3,6] as GroupCQ. We refer to CQS where there is no sharing as TraditionalCQ. We have studied the performance of the two frameworks in three types of queries: Simple Selection Query, Range Selection Query, and Join Query. Figure 3 shows a comparison of the total costs of processing queries (i.e. CCQ) amongst the various CQS. The goal is to minimize CCQ.
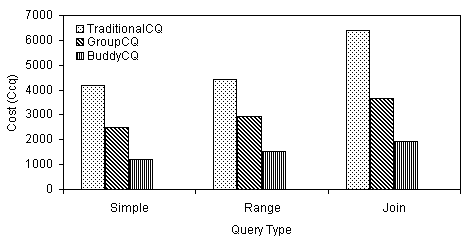
Figure 3: Comparison of CQ-Buddy vs. Existing CQS
In this paper, we have proposed a framework, CQ-Buddy, for continuous
query processing using Peer-to-Peer technology. We have also introduced the
notion of pervasive continuous queries, and shown how CQ-Buddy handles such
queries. We have further discussed how peers can collaborate in a CQ-Buddy network
through the sharing of query workload.
By distributing continuous query evaulation amongst peers, CQ-Buddy's design
allows it to be naturally extended to support progressive refinements of results
[1,2]. The progressive refinement can be achieved when each CQ-Buddy peers continually
provide partial result sets to the peer where the CQ is issued. We are currently
studying how such progressive refinements can be efficiently achieved in a large
network of CQ-Buddy peers.
Wee Siong Ng and Kian-Lee Tan are partially supported by the NSTB/MOE research grant RP960668.