C.2.1 [Computer-Communication Networks]: Network Architecture and Design – network communications; C.2.4 [Computer-Communication Networks]: Distributed Systems – distributed applications; D.4.5 [Operating Systems]: Reliability – fault tolerance; D.4.7 [Operating Systems]: Organization and Design – distributed systems;.
Management, Design, Reliability, Experimentation
With the integration of web services in complex, federated activities there is a strong need to ensure the reliability of the distributed operations. To provide advanced guarantees, the web-services architectures can draw from the experiences of two decades of building advanced middleware systems, which had similar reliability goals, albeit at a smaller scale and in less heterogeneous settings.
Some first steps in providing an interoperable framework for distributed services have been set with the security, routing, coordination and transaction specifications [2,3]. Together with the upcoming reliable messaging specification these will provide the first building blocks for constructing simple forms of federated web-services based activities. Although these specifications do an excellent job in laying the ground work for the interaction between the various services and the guarantees that can be achieved by making all of the distributed operations explicit, they are remarkably vague with respect to failure scenarios and failure handling.
Failure management is essential for building reliable distributed systems [1]. Tracking which services are participating in a business activity and what their status is drives the progress of the activity. Long running activities need to deal with more complex failure scenarios than those that can be implemented using simple atomic transactions. For example a failure of a crucial service may need to be compensated by trying to use an alternative supplier or a replica service, before deciding on the rollback of the overall activity.
To assist in the distributed management of activities based on web-services, we have developed ws-membership, a coordination protocol that fits into the ws-coordination [3] framework and provides cooperating web-services and activity monitors with a unified approach for tracking registered services and for presenting membership updates to monitors. We foresee different implementations of membership engines depending on the emerging failure management needs of web-services based activities, and as such we have decoupled the ws-membership basic interface from the implementation of our prototypes.
A Membership Service has two components: failure detection and membership information dissemination. A variety of algorithms has developed over the years especially for research systems, while industrial systems in general have resorted to simple heartbeat, time-out and flooding schemes [4,6,8,9,10,13,14,15]. The prototype of the membership engine developed for this project is based on epidemic techniques, which is extremely well suited for cases where robustness is important. The a-synchronous and autonomous properties of this service make it simple to implement and operate.
Failure detection can also be used as the building block to simplify the implementation of other essential distributed systems services such as consensus [5]. Consensus is used when a set of processes need to agree upon the outcome of an operation. Many consensus protocols require knowledge about which processes are involved in the execution of the protocol to establish a notion of majority, quorums, etc. Even though some protocols such as Paxos [11,12] do not use failure detectors in their specification, the implementation of these protocols is greatly simplified by their use.
This paper is organized as follows: section 2 provides a brief overview of the research context in which these services are being developed. In section 3 the membership framework and the interface are describe, while section 4 gives the details on the Epidemic Membership Service. Section 5 contains some performance numbers and thoughts on future work.
In the ObduroProject we are applying our experiences in building reliable distributed systems to the web-services architectures. The web-service architecture provides us with an opportunity to design robust distributed systems that are highly scalable. We have long been arguing that the scalability of distributed systems has been severely hindered by hiding the distributed aspects of the services behind a transparent single address-space interface. The “software as a distributed service” approach will allows us to build distributed systems more reliably than in the past [18].
In the recent years we have mainly shifted our focus to the reliability problems caused by the increasing scale of distributed systems and the failure of traditional systems to provide robust operation under influence of scale. In the Obduro project we will continue to exploit technologies such as epidemic communication and state-management to provide frameworks for building scalable, autonomous web-services in federated setting.
The project will focus on deliverables in 4 areas:
The work described in this paper comes out of the first area. A membership service is and essential tool in managing service availability and is a building block for other, more complex distributed services.
Based on our experiences with building a variety of distributed systems and applications, we realize that there is no single membership service implementation that serves the needs of all (reliable) distributed systems. Some may require high accuracy while others needs aggressive fail-over, where again others may require distributed agreement before failures are reported. World wide failure detection requires different protocols than clustered systems in a datacenter. In the Obduro project we may implement a number of prototypes that target different deployments, beyond the Epidemic Membership Service described in this paper.
These different membership implementations do have a single membership service interface in common which services use to register and monitors can use to track the registered member services. Additionally the Membership Framework that is part of the Obduro Coordination Toolkit provides the membership developer with some basic classes that abstract the interaction of the membership service with member services and proxies.
The Membership Interface is designed according the Activation/Registration pattern prescribed by the ws-coordination specification. The main task for the Coordination Service in this setting is to route the activation and registration requests to the appropriate protocol factory or instance multiplexer based on CoordinationType and CoordinationContext specified as parameters in the service requests
There are five roles modeled in the membership service.
The process of activation and registration will make the relation between these roles clearer.
The Coordination Service provides a 2-step access to membership service. In the first step a participant in the activity, such as a member service or a activity monitor, activates the protocols by sending a CreateCoordinationContext request to the Coordination service with the CoordinationType set to the following uri:
http://ws.cs.cornell.edu/schemas/2002/11/wsms
This will instantiate a Membership Service at the coordination site using optional configuration parameters to the extensibility elements in the request. The operation will return a CoordinationContext to the requestor which includes information for other Membership Service instances to join in the protocol.
If the activation is requested with an existing CoordinationContext as a parameter, the Coordination Service actives the Membership Service, which joins the other Membership Service instances activated with the same context. For example the Epidemic Membership Services uses the information in the context to contact an already activated Membership Service instance to bootstrap the current membership list. The new instance will add information about itself to the context, such that future activations at other coordinators have alternative Membership Services to bootstrap from.
When the Membership Service instances are activated at the Coordinators, the set of Coordinators is established that will track each other. However if no registration request reaches a particular Membership Service instance within the time-to-live period specified in the context, that instance will de-activate and will voluntarily leave the membership. The service membership list remains empty until Member Service instances are registered.
A service instance will request to be added to the membership through the RequestMemberService action. Parameters to the request include a URI uniquely identifying the Member Service instance, a CoordinationContext that represents the set of Membership Services collaborating in the membership tracking and a port-reference on which the service is willing to accept MemberProbe interrogation messages. In the response to the request the service will receive a port-reference at the membership service to which it can send its MemberAlive interrogation responses and the MemberLeaves notification when the service wants to exit the membership gracefully.
A second possibility for a service to be added to the membership is through the interposing a Membership Proxy. As described earlier such a proxy can be a dedicated software module that uses specialized techniques to monitor the service. Also a generic membership proxy is interposed by a Coordination service in response to a RequestMemberService request when no Membership Service was previously activated at this Coordinator for the specified CoordinationContext.
Proxies register with a Membership Service instance through the RegisterMembershipProxy request which contains a port-reference at the proxy to which ProxyProbe interrogation messages will be send and the unique id the service provided to the proxy. A proxy can register itself multiple times for different services using the same port reference. The response to the proxy contains the port-reference at the membership service to which the proxy can send its ProxyAlive message as well as MemberLeaves and MemberFailed messages when a Member Service connected to a proxy fails. The proxy interrogation sequence is used to keep track of the health of the proxy service, if the proxy is determined to have failed; all associated services will be marked failed in the membership. How a dedicated proxy determines the health of a service is outside of the scope of this paper, but the generic proxy uses the regular MemberProbe/MemberAlive interrogation sequence.
A Membership Monitor registers using the RegisterMembershipMonitor request, which includes a port-reference on which the monitor wants to receive the MembershipUpdate messages. A membership update includes at minimum a list of the currently active Member Services, but can be extended with information on Members Services that have left gracefully or recently joined, that have failed or are suspected to have failed.
To ensure that no false information is spread about the health of the Member Services, the Membership Service, proxies, members and monitors all need to use the ws-security services to sign their messages.
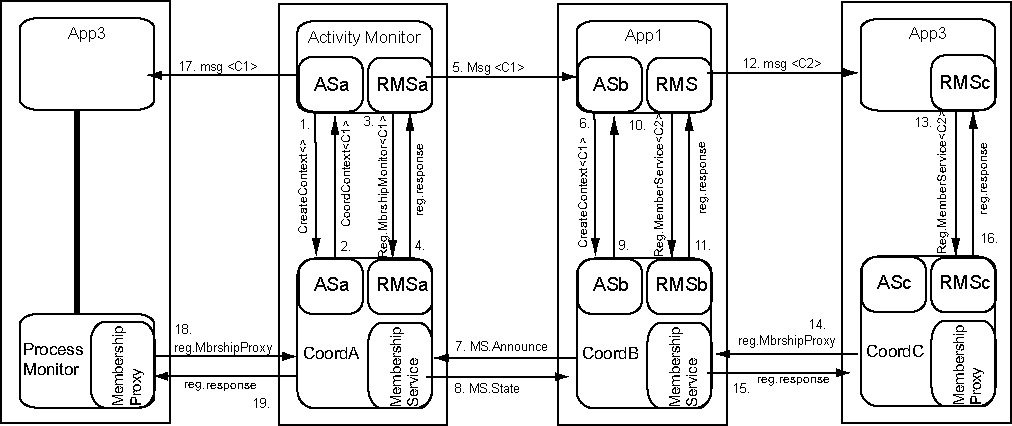
Figure 1. An example scenario of the activation/registration sequence. In this particular case the sequence is initiated by an activity monitor in steps 1 though 4. The Activity Monitor send the CoordinationContext C1, to App1 which uses it activate an instance of the membership service and register itself. Steps 7 and 8 are dependent on the particular implementation of the membership protocol and are here for illustration only. App1 sends the new context to App2 which uses it to register without going through activation first. This setups up a generic proxy that registers itself with the Membership Service specified in Context C2. The Activity Monitor also sends the C1 context to App3, which uses a local mechanism to connect to a process monitor that implements the Membership Proxy service.
The basic membership engine implemented for the Obduro Project is based on a gossip-style failure detector, which was first described in [13]. This probabilistic approach to failure detection was the basis for the design of the membership services in the Galaxy federated cluster management system [16] and in Astrolabe [14] which is an ultra-scalable state maintenance system. This prototype is based on experiences with the failure detection modules in those systems.
The membership service is based on epidemic state maintenance techniques which provide an excellent foundation for constructing loosely coupled, a-synchronous, autonomous distributed components. The guarantees offered by the service are of the ‘eventual consistency’ category. For a membership service this means that if at any given moment one takes a snapshot of the overall system not all participants may have an identical membership list, but that eventually, if no other external events happen (members join, leave of fail), all participants will have the same state.
Additional advantages of using epidemic techniques for the membership service are
These robustness and scalability properties make this approach to failure detection and membership management attractive to use in a large federated environments.
There are some disadvantages to using epidemic failure detection. The protocol in itself can become inefficient, as the size of the messages exchanged grows with the number of participants. A number of optimizations have been developed using adaptive and hierarchical techniques, allowing the protocol to scale better. This prototype implementation targets small to medium membership sizes up to 50 – 100 participants, for which it is not necessary to implement these optimizations. A second disadvantage is that the protocol does not deal very well with massive concurrent participant failures, which temporarily influences the accuracy of the detection mechanisms, although we have not seen any other light-weight membership modules that do much better.
The detection of failed participants is very accurate, but is often configured rather conservative. In other settings where we have used epidemic membership management and where a more aggressive approach was needed we added a layer of interrogation style probing modules to enabling early suspicions of failures.
The Epidemic Membership Service (EMS) is based on the principles developed in the context of the Xerox Clearinghouse project [7]. In epidemic protocols a participant forwards its local information to randomly chosen participants. In Clearinghouse this protocol was used to resolve inconsistencies between distributed directories, in EMS the protocol is used to find out which participants are still ‘gossiping’.
The basic operation of the protocol is rather simple: each participant maintains a list of known peers, including itself, with each entry at least holding the identification of the remote participant, a timestamp and a single integer dubbed the heartbeat counter. Periodically, based on protocol configuration, the participant will increment its own heartbeat counter and randomly select a peer from the membership list to send a message containing the all the <address, heartbeat> tuples it has in its membership list. Upon receipt of a message, a participant will merge the information from the message with its local membership list by adapting those tuples that have the highest heartbeat counter values. For each member for which it adopted a new heartbeat value, it will update the timestamp value in the entry. See Figure 2 for an example.
If a participant’s entry has not been updated based on the configured failure period, it is declared to have failed and associated monitors are notified. The failure period is selected such that the probability of an erroneous detection is below a certain threshold, and is directly related to the gossip communication interval. For a detailed analysis of the failure detection protocol and the relation between the probability of a mistake and the detection time see [13].
The EMS prototype departs from the original model by implementing a push-pull model for its communication instead of the push used in the original design. In this model the receiving participant will, if it detects that is has entries in its membership table that are newer (e.g. have higher heartbeat counter values), send a message back to the original sender with those tuples for which it has newer values. The push-pull model has a dramatically better dissemination performance than the push model, especially in those cases where the local state at the participants change frequently, which is the case in our system. See figure 3 for an example of a push-pull operation.

Figure 2. Example heartbeat counter state merge

Figure 3. Example push-pull style epidemic exchange of the heartbeat counters. Node-A gossips to Node-B a digest of its membership state. Node B, after merging the update with its local state returns a message to Node-A with the state that it knows is newer.
The membership protocol operates between instances of the Membership Service, and the failure detection described in the previous section detects failures of other Membership Service instances. The membership however describes Member Services, and multiple such services can be registered with a single Membership Service instance.
To implement the Member Service membership, the membership list is extended to include a list of Member Services registered with each Membership Service instance, and this information is included in the gossip messages between the Membership Services. Each Membership Services instance can thus construct the complete list of all Member Services associated with the CoordinationContext. If a Membership Service instance fails, all the associated Member Services are marked as failed.
If a Membership Service determines that a Member Service has failed, either through the repeated failure of an interrogation sequence or through the MemberFailed indication of a Membership Proxy, the service is marked as failed in the membership list. Other instances will receive this information through the epidemic spread of the membership information.
The information per participant send in the gossip messages is organized in five sets of Member Services:
The implementation of the Epidemic Membership Services optimizes the case of multiple activations of the protocol. If multiple protocol instances are created at a Coordination Service instance (e.g. they have a different CoordinationContext), and there is an overlap between the participants in the protocol, the different instances will share a common epidemic communication engine. This will ensure that no unnecessary communication will take place, by avoiding duplicate gossiping. It also allows smaller member groups to benefit from the increased robustness of using a larger number of epidemic communication engines.
A second optimization implemented for tracking large but stable service groups is to gossip only a digest of the membership information instead of the complete membership lists. In this case a participant will only gossip about last logical timestamp the Members list was updated. If a participant receives a message with a newer logical timestamp, it can request a full membership from the sender of the gossip message or from the participant for which the updated timestamp was received.
The Coordination and Membership Frameworks, and the Epidemic Membership Service are implemented using functionality from Base Obduro Toolkit which in its part is based on the Microsoft WSDK. The MS-WSDK is used for the basic data-structures and the security and routing filters, but the referral management and transport mapping is implemented by classes in the Obduro toolkit. A simple process monitor implementing the Membership Proxy protocol has also been implemented.
The Membership Service deploys 3 types of failure detection:
It is a best practice to run as few remote Member and Proxy probes as possible. Running an instance of the Membership Service on the same node as the Member Services or the Proxy Service will allow the probe protocols not to be subjected to network message loss, avoiding the need for a reliable transport, which improves the efficiency and accuracy of the probe protocol. The robustness of the inter-Membership Service failure is not impacted by moderate message loss rate or even transient high loss rates.
In general a membership service will use a separate dissemination channel to send membership updates to other participant in the membership protocol. In the case of the Epidemic Membership Service we have chosen to include this information in the gossip messages. The advantages of this choice are that there is no need for additional communication primitives which in general needs to be a form of a reliable multicast protocol, or a brute force flooding technique. Adding a scalable reliable multicast would increase the complexity of the system while reliable flooding has scalability limitations. The epidemic dissemination of the membership information has the best of both worlds, it provide a flooding of the information, but in a very scalable, robust manner.
A disadvantage of the choice to piggy back the information on the gossiping of the heartbeats is that it disseminates rather slowly throughout the network. As can be seen in figure 4, in a setup with 64 instances of the Membership Service it takes more than 4 seconds for the information to spread to all the nodes if these nodes only gossip once per second.
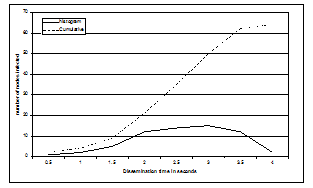
Figure 4. Dissemination of membership information using epidemic techniques with 64 nodes with a 1 second gossip interval.
We are not aware of any membership service or interface, in research or production, which particularly targets long running business activities based on web-services. We are also not aware of any public implementation of the Coordination Framework that allows for dynamic management of new Coordination types.
There is a large body of work on failure detectors for different types of distributed systems, from reliable process group communication to large scale grids and from real-time factory floor settings to multi-level failure detection for clusters [4,6,8,9,10,13,14,15,19]. We expect that some of those implementations will also find their application in the web-services world and we hope that our Coordination and Membership Frameworks can be used to simplify the implementation and use of those systems.
This is only the first step in the development of a range of technologies as noted in section 2. One of the first follow-up tasks is to investigate how we can integrate the membership service into the execution environment of system that use BPEL4WS as a driver. Other near-term use of the membership service will be in the development of one of more consensus protocols.
The software distribution of the Obduro Toolkit, the Coordination and Membership Framework and the Epidemic Membership Service is also slated in the near future.
This work is supported by a grant from Microsoft Research and by funding from DARPA under AFRL contract F30602-99-1-0532 and AFOSR/MURI contract F49620-02-1-0233.
[1] Birman, K., and van Renesse, R., Software for reliable networks. Scientific American 274, 5, pp. 64-69, May 1996. (With R. van Renesse.)
[2] Cabrera, F., Copeland, G.,Cox, B., Freund, T., Klein, J., Storey, T., Thatte, S., “Web Services Transaction (ws-transaction)”, 2002, http://www.ibm.com/developerworks/library/ws-transpec/
[3] Cabrera, F., Copeland, Freund, T., Klein, J.,Langworthy, D., Orchard, D., Shewchuk, J., and Storey, T., “Web Services Coordination (ws-coordination)”, 2002, http://www.ibm.com/developerworks/library/ws-coor/
[4] Chandra T.D. and Toueg S., Unreliable failure detectors for reliable distributed systems. Journal of the ACM , 43(2), pp:225--267, March 1996.
[5] Chandra, T.D., Hadzilacos, V., and Toueg, S., “The Weakest Failure Detector for Solving Consensus” in Proceedings pf the. 11th annual ACM Symposium on Principles of Distributed Computing, pages 147--158, 1992
[6] Das, A., Gupta, I., Motivala, A., "SWIM: Scalable Weakly-consistent Infection-style Process Group Membership Protocol", in Proceedings. of The International Conference on Dependable Systems and Networks (DSN 02), Washington DC, pp. 303-312, June, 2002
[7] Demers, D. Greene, C. Hauser, W. Irish, and J. Larson. “Epidemic algorithms for replicated database maintenance”. in Proceedings. 6th Annual ACM Symp. Principles of Distributed Computing (PODC '87), pages 1--12, 1987
[8] Felber, P., D´efago, X., Guerraoui, R., and Oser, P., “Failure detectors as first class objects”, In Proceedings. of the 9th IEEE Int’l Symp. on Distributed Objects and Applications(DOA’99), pages 132–141, Sep. 1999.
[9] Fetzer, C., Raynal, M., and Tronel, F., “An adaptive failure detection protocol”, in Proceedings. of the 8th IEEE Pacific Rim Symp. on Dependable Computing(PRDC-8), 2001.
[10] Gupta, I., Chandra, T.D., and Goldszmidt, G., "On Scalable and Efficient Distributed Failure Detectors", in Proceedings of the 20th Symposium on Principles of Distributed Computing (PODC 2001), Newport, RI, August, 2001.
[11] Lamport, L., “The Part-Time Parliament”, ACM Transactions on Computer Systems 16, 2 (May 1998), 133-169.
[12] Lampson B.W., “How to build a highly available system using consensus”, in Proceedings of 10th Int. Workshop on Distributed Algorithms, pp:9--11, Bologna, Italy, (October 1996).
[13] Renesse, van R. Minsky, Y., and Hayden, M., “A gossip-style failure detection service”, in Proceedingc. of Middleware’98, pages 55–70. IFIP, September 1998.
[14] Renesse, van R. Birman, K., and Vogels, W., “Astrolabe”, to appear in ACM Tranactions on Computer Systems, 2003.
[15] Stelling, P., Foster, I., Kesselman, C., Lee, C., and von Laszewski, G., “A fault detection service for wide area distributed computations”, In Proceedings. of the 7th IEEE Symp. On High Performance Distributed Computing, pages 268–278, July 1998.
[16] Vogels W., and Dumitriu, D., “An Overview of the Galaxy Management Framework for Scalable Enterprise Cluster Computing”, in the Proceedings of the IEEE International Conference on Cluster Computing: Cluster-2000, Chemnitz, Germany, December 2000
[17] Vogels, W., “Technology Challenges for the Global Real-Time Enterprise”, in the Proceedings of the International Workshop on Future Directions in Distributed Computing, Bertinoro, Italy, June 2002.
[18] Vogels, W., van Renesse R., and Birman, K., “Six Misconceptions about Reliable Distributed Computing”, Proceedings of the 8th ACM SIGOPS European Workshop, Sintra, Portugal, September 1998.
[19] Vogels, W., World-Wide Failures, in the Proceedings of the 1996 ACM SIGOPS Workshop, Connemora, Ireland, September 1996.