Taher H. Haveliwala2
|
Aristides Gionis3
|
Dan Klein4
|
Piotr Indyk
|
Copyright is held by the author/owner(s). WWW2002, May 7-11, 2002, Honolulu, Hawaii, USA. ACM 1-58113-449-5/02/0005.
H.3.3 [Information Storage and Retrieval]: Information Search and Retrieval - clustering, search process; H.3.1 [Information Storage and Retrieval]: Content Analysis and Indexing - indexing methods, linguistic processing
Algorithms, Measurement, Performance, Experimentation
related pages, similarity search, search, evaluation, Open Directory Project
The goal of Web-page similarity search is to allow users to find Web pages similar to a query page [12]. In particular, given a query document, a similarity-search algorithm should provide a ranked listing of documents similar to that document.
Given a small number of similarity-search strategies, one might imagine comparing their relative quality with user feedback. However, user studies can have significant cost in both time and resources. Moreover, if, instead of comparing a small number of options, we are interested in comparing parametrized methods with large parameter spaces, the number of strategies can quickly exceed what can be evaluated using user studies. In this situation, it is extremely desirable to automate strategy comparisons and parameter selection.
The ``best'' parameters are those that result in the most accurate ranked similarity listings for arbitrary query documents. In this paper, we develop an automated evaluation methodology to determine the optimal document representation strategy. In particular, we view manually constructed directories such as Yahoo! [26] and the Open Directory Project (ODP) [21] as a kind of precompiled user study. Our evaluation methodology uses the notion of document similarity that is implicitly encoded in these hierarchical directories to induce ``correct'', ground truth orderings of documents by similarity, given some query document. Then, using a statistical measure ([13]), we compare similarity rankings obtained from different parameter settings of our algorithm to the correct rankings. Our underlying assumption is that parameter settings that yield higher values of this measure correspond to parameters that will produce better results.
To demonstrate our evaluation methodology, we applied it to a reasonably sized set of parameter settings (including choices for document representation and term weighting schemes) and determined which of them is most effective for similarity search on the Web.
There are many possible ways to represent a document for the purpose of supporting effective similarity search. The following briefly describes the representation axes we considered for use with the evaluation methodology just described.
Three approaches to selecting the terms to include in the vector
(or equivalently, multiset) representing a Web page ![]() follow:
follow:
The usual content-based approach ignores the available hyperlink data and is susceptible to spam. In particular, it relies solely on the information provided by the page's author, ignoring the opinions of the authors of other Web pages [3]. The link-based approach, investigated in [12], suffers from the shortcoming that pages with few inlinks will not have sufficient citation data, either to be allowed in queries or to appear as results of queries. This problem is especially pronounced when attempting to discover similarity relations for new pages that have not yet been cited sufficiently. As we will see in Section 5, under a link-based approach, the vectors for most documents (even related ones) are in fact orthogonal to each other.
The third approach, which relies on text near anchors, referred to as the anchor-window [9], appears most useful for the Web similarity-search task. Indeed, the use of anchor-windows has been previously considered for a variety of other Web IR tasks [2,1,9,11]. The anchor-window often constitutes a hand-built summary of the target document [1], collecting both explicit hand-summarization and implicit hand-classification present in referring documents.
We expect that when aggregating over all inlinks, the frequency of relevant terms will dominate the frequency of irrelevant ones. Thus, the resulting distribution is expected to be a signature that is a reliable, concise representation of the document. Because each anchor-window contributes several terms, the anchor-based strategy requires fewer citations than the link-based strategy to prevent interdocument orthogonality. However, as a result of reducing orthogonality, the anchor-based strategy is nontrivial to implement efficiently [14]. We discuss later how a previously established high-dimensional similarity-search technique based on hashing can be used to efficiently implement the anchor-based strategy.
These three general strategies for document representation involve additional specific considerations, such as term weighting and width of anchor-windows, which we discuss further in Section 3.
Note that there are many additional parameters that could be considered, such as weighting schemes for font sizes, font types, titles, etc. Our goal was not to search the parameter space exhaustively. Rather, we chose a reasonable set of parameters to present our evaluation methodology and to obtain insight into the qualitative effects of these basic parameters.
Once the best parameters, including choice of document representation and term weighting schemes, have been determined using the evaluation methodology, we must scale the similarity measure to build a similarity index for the Web as a whole. We develop an indexing approach relying on the Min-hashing technique [10,5] and construct a similarity-search index for roughly 75 million urls to demonstrate the scalability of our approach. Because each stage of our algorithm is trivially parallelizable, our indexing approach can scale to the few billion accessible documents currently on the Web.5
The quality of the rankings returned by our system is determined by the similarity metric and document features used. Previous work [12] has relied on user studies to assess query response quality. However, user studies are time-consuming, costly, and not well-suited to research that involves the comparison of many parameters. We instead use an automated method of evaluation that uses the orderings implicit in human-built hierarchical directories to improve the quality of our system's rankings.
In the clustering literature, numerous methods of automatic evaluation have been proposed [17]. Steinback et al. [25] divide these methods into two broad classes. Internal quality measures, such as average pairwise document similarity, indicate the quality of a proposed cluster set based purely on the internal cluster geometry and statistics, without reference to any ground truth. External quality measures, such as entropy measures, test the accordance of a cluster set with a ground truth. As we are primarily investigating various feature selection methods and similarity metrics themselves in our work, we restrict our attention to external measures.
The overall outline of our evaluation method is as follows. We use a hierarchical directory to induce sets of correct, ground truth similarity orderings. Then, we compare the orderings produced by a similarity measure using a particular set of parameters to these correct partial orderings, using a statistical measure outlined below. We claim that parameter settings for our similarity measure that yield higher values of this statistical measure correspond to parameters that will produce better results from the standpoint of a user of the system.
Unfortunately, there is no available ground truth in the form of either exact document-document similarity values or correct similarity search results.
There is a great deal of ordering information implicit in the
hierarchical Web directories mentioned above. For example, a
document in the recreation/aviation/un-powered class
is on average more similar to other documents in that same class
than those outside of that class. Furthermore, that document is
likely to be more similar to other documents in other
recreation/aviation classes than those entirely
outside of that region of the tree. Intuitively, the most similar
documents to that source are the other documents in the source's
class, followed by those in sibling classes, and so on.
There are certainly cases where location in the hierarchy does
not accurately reflect document similarity. Consider documents in
recreation/autos, which are almost certainly more
similar to those in shopping/autos than to those in
recreation/smoking. In our sample, these cases do not
affect our evaluation criteria since we average over the statistics
of many documents.
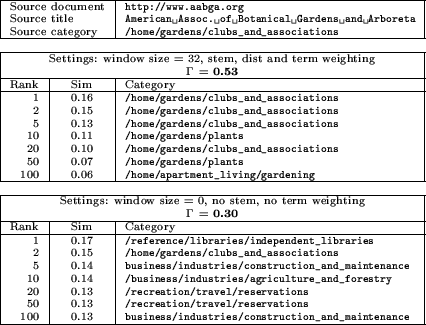
To formalize the notion of distance from a source document to another document in the hierarchy we define familial distance.
In our system, however, we have collapsed the directory below a fixed depth of three and ignored the (relatively few) documents above that depth. Therefore, there are only four possible values for familial distance, as depicted in Figure 1. We name these distances as follows:
Given a source document, we wish to use familial distances to other documents to construct a partial similarity ordering over those documents. Our general principle is:
On average, the true similarity of documents to a source document decreases monotonically with the familial distance from that document.
Given this principle, and our definition of familial distance, for any source document in a hierarchical directory we can derive a partial ordering of all other documents in the directory. Note that we do not give any numerical interpretation to these familial distance values. We only depend on the above stated monotonicity principle: a source document is on average more similar to a same-class document than to a sibling-class document, and is on average more similar to a sibling-class document than a cousin-class document, and so on.
This ordering is very weak in that for a given source, most pairs of documents are not comparable. The majority of the distinctions that are made, however, are among documents that are very similar to the source and documents that are much less similar. The very notion of a correct total similarity ordering is somewhat suspect, as beyond a certain point, pages are simply unrelated. Our familial ordering makes no distinctions between the documents in the most distant category, which forms the bulk of the documents in the repository.
Of course our principle that true similarity decreases monotonically with familial distance does not always hold. However it is reasonable to expect that, on average, a ranking system7 that accords better with familial ordering will be better than one that accords less closely.
Intuitively, there are a certain number of document pairs, and a
given ordering only makes judgments about some of those pairs. When
comparing two orderings, we look only at the pairs of documents
that both orderings make a judgment about. A value of 1 is perfect
accord, 0 is the expected value of a random ordering, and -1
indicates perfect reversed accord. We claim that if two rankings
![]() and
and ![]() differ in their
differ in their ![]() values with respect to a
ground truth
values with respect to a
ground truth ![]() , then the ordering with the higher
, then the ordering with the higher ![]() will be the better
ranking.
will be the better
ranking.
Thus, given a directory, a query document ![]() , and a similarity measure
, and a similarity measure ![]() , we can construct two
orderings (over documents in the directory): the ground truth
familial ordering
, we can construct two
orderings (over documents in the directory): the ground truth
familial ordering
![]() , and
the ordering induced by our similarity measure
, and
the ordering induced by our similarity measure
![]() . We can
then calculate the corresponding
. We can
then calculate the corresponding ![]() value. This value gives us a measure of
the quality of the ranking for that query document with respect to
that similarity measure and directory. However, we need to give a
sense of how good our rankings are across all query documents. In
principle, we can directly extend the
value. This value gives us a measure of
the quality of the ranking for that query document with respect to
that similarity measure and directory. However, we need to give a
sense of how good our rankings are across all query documents. In
principle, we can directly extend the ![]() statistic as follows. We iterate
statistic as follows. We iterate ![]() over all documents, aggregating
all the concordant and discordant pairs, and dividing by the total
number of pairs.
over all documents, aggregating
all the concordant and discordant pairs, and dividing by the total
number of pairs.
In order to more precisely evaluate our results, however, we
calculated three partial-![]() values that emphasized different regions
of the ordering. Each partial-
values that emphasized different regions
of the ordering. Each partial-![]() is based on the fraction of correct
comparable pairs of a certain type. Our types are:
is based on the fraction of correct
comparable pairs of a certain type. Our types are:
|
These partial-![]() values allowed us to inspect how various similarity measures
performed on various regions of the rankings. For example,
sibling-
values allowed us to inspect how various similarity measures
performed on various regions of the rankings. For example,
sibling-![]() performance indicates how well fine distinctions are being made
near the top of the familial ranking, while unrelated-
performance indicates how well fine distinctions are being made
near the top of the familial ranking, while unrelated-![]() performance measures how
well coarser distinctions are being made. Unrelated-
performance measures how
well coarser distinctions are being made. Unrelated-![]() being unusually low in
relation to sibling-
being unusually low in
relation to sibling-![]() is also a good indicator of situations when the top of the list is
high-quality from a precision standpoint but many similar documents
have been ranked very low and therefore omitted from the top of the
list (almost always because the features were too sparse, and
documents that were actually similar appeared to be
orthogonal).
is also a good indicator of situations when the top of the list is
high-quality from a precision standpoint but many similar documents
have been ranked very low and therefore omitted from the top of the
list (almost always because the features were too sparse, and
documents that were actually similar appeared to be
orthogonal).
In Figure 2, we show an
example that reflects our assumption that larger values of the
![]() statistic
correspond to parameter settings that yield better results.
statistic
correspond to parameter settings that yield better results.
In this section we will discuss the specific document
representation and term weighting options we chose to evaluate
using the technique outlined above. Let the Web document ![]() be represented by a bag
be represented by a bag
For both the content and anchor-based approaches, we chose to
remove all HTML comments, Javascript code, tags (except
'alt' text), and non-alphabetic characters. A stopword
list containing roughly 800 terms was also applied.
For the anchor-based approach, we must also decide how many
words to the left and right of an anchor ![]() (the anchor linking from page
(the anchor linking from page ![]() to page
to page ![]() ) should be included in
) should be included in ![]() . We experimented with three strategies for
this decision. In all cases, the anchor-text itself of
. We experimented with three strategies for
this decision. In all cases, the anchor-text itself of ![]() is included, as well as
the title of document
is included, as well as
the title of document ![]() . The three strategies follow:
. The three strategies follow:
We explored the effect of three different stemming variations:
A further consideration in generating document bags is how a term's frequency should be scaled. A clear benefit of the TF.IDF family of weighting functions is that they attenuate the weight of terms with high document frequency. These monotonic term weighting schemes, however, amplify the weight of terms with very low document frequency. This amplification is in fact good for ad-hoc queries, where a rare term in the query should be given the most importance. In the case where we are judging document similarities, rare terms are much less useful as they are often typos, rare names, or other nontopical terms that adversely affect the similarity measure. Therefore, we also experimented with nonmonotonic term-weighting schemes that attenuate both high and low document-frequency terms. The idea that mid-frequency terms have the greatest ``resolving power'' is not new [23,20]. We call such schemes nonmonotonic document frequency (NMDF) functions.
Another component of term weighting that we consider, and which
has a substantial impact on our quality metric, is distance
weighting. When using an anchor-based approach of a given
window size, instead of treating all terms near an anchor ![]() equally, we can weight
them based on their distance from the anchor (with anchor-words
themselves given distance 0). As we will see in Section 5, the use of a distance-based
attenuation function in conjunction with large anchor-windows
significantly improves results under our evaluation measure.
equally, we can weight
them based on their distance from the anchor (with anchor-words
themselves given distance 0). As we will see in Section 5, the use of a distance-based
attenuation function in conjunction with large anchor-windows
significantly improves results under our evaluation measure.
The metric we use for measuring the similarity of document bags
is the Jaccard coefficient. The Jaccard coefficient of two
sets ![]() and
and ![]() is defined as
is defined as
The reasons that we focus on the Jaccard measure rather than the classical cosine measure are mainly scalability considerations. For scaling our similarity-search technique to massive document datasets we rely on the Min-Hashing technique. The main idea here is to hash the Web documents such that the documents that are similar, according to our similarity measure, are mapped to the same bucket with a probability equal to the similarity between them. Creating such a hash function for the cosine measure is to our knowledge an open problem. On the other hand, creating such hashes is possible for the Jaccard measure (see [5]).
We used our evaluation methodology to verify that the Jaccard coefficient and the cosine measure yield comparable results.10Further evidence for the intuitive appeal of our measure is provided in [19], where the Jaccard coefficient outperforms all competitor measures for the task of defining similarities between words. Note that the bulk of the work presented here does not depend on whether Jaccard or cosine is used; only in Section 7 do we require the use of the Jaccard coefficient.
For evaluating the various strategies discussed in Section 3, we employ the methodology described in Section 2. We sampled Open Directory [21] to get 300 pairs of clusters from the third level in the hierarchy, as depicted previously in Figure 1.11 As our source of data, we used a Web crawl from the Stanford WebBase containing 42 million pages [15]. Of the urls in the sample clusters, 51,469 of them were linked to by some document in our crawl, and could thus be used by our anchor-based approaches. These test-set urls were linked to by close to 1 million pages in our repository, all of which were used to support the anchor based strategy we studied.12This section describes the evaluation of the strategies suggested in Section 3.
We verified that all three of our ![]() measures yield, with very few exceptions,
the same relative order of parameter settings. In a sense, this
agreement is an indication of the robustness of our
measures yield, with very few exceptions,
the same relative order of parameter settings. In a sense, this
agreement is an indication of the robustness of our ![]() measures. Here we report
the results only for the sibling-
measures. Here we report
the results only for the sibling-![]() statistic. The graphs for the
cousins-
statistic. The graphs for the
cousins-![]() and unrelated-
and unrelated-![]() measures behave similarly.
measures behave similarly.
For some of the graphs shown in this section the difference of
![]() scores between
different parameter settings might seem quite small, i.e. second
decimal digit. Notice, however, that in each graph we explore the
effect of a single ``parameter dimension'' independently, so when
we add up the effect on all ``parameter dimensions'' the difference
becomes substantial.
scores between
different parameter settings might seem quite small, i.e. second
decimal digit. Notice, however, that in each graph we explore the
effect of a single ``parameter dimension'' independently, so when
we add up the effect on all ``parameter dimensions'' the difference
becomes substantial.
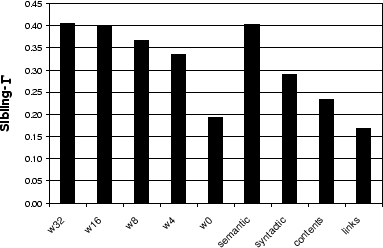
Sibling-![]() values when bags are generated using various anchor-window sizes,
using TOPICAL and SYNTACTIC window
bounding, using purely links, and using purely page contents, are
given in Figure 3.
values when bags are generated using various anchor-window sizes,
using TOPICAL and SYNTACTIC window
bounding, using purely links, and using purely page contents, are
given in Figure 3.
|
|
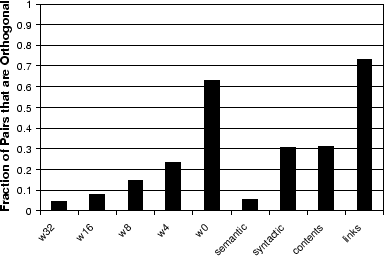
The results for an anchor-based approach using large windows provides the best results according to our evaluation criteria. This may seem counterintuitive; by taking small windows around the anchor, we would expect fewer spurious words to be present in a document's bag, providing a more concise representation. Further experiments revealed why, in fact, larger windows provide benefit. Figure 4 shows the fraction of document pairs within the same Open Directory cluster that are orthogonal (i.e., no common words) under a given representation. We see that with smaller window sizes, many documents that should be considered similar are in fact orthogonal. In this case, no amount of reweighting or scaling can improve results; the representations simply do not provide enough accessible similarity information about these orthogonal pairs. We also see that, under the content and link approaches, documents in the same cluster are largely orthogonal. Under the link-based approach, most of the documents within a cluster are pairwise orthogonal, revealing a serious limitation of a purely link-based approach. Incoming links can be thought of as being opaque descriptors. If two pages have many inlinks, but the intersection of their inlinks is empty, we can say very little about these two pages.13 It may be that they discuss the same topic, but because they are new, they are never cocited. In the case of the anchor-window-based approach, the chance that the bags for the two pages are orthogonal is much lower. Each inlink, instead of being represented by a single opaque url, is represented by the descriptive terms that are the constituents of the inlink. Note that the pure link based approach shown is very similar to the Cocitation Algorithm of [12].14
We also experimented with dynamically sized
SYNTACTIC and TOPICAL windows, as
described in Section 3.
These window types behave roughly according to their average window
size, both in ![]() values and orthogonality. Surprisingly, although the dynamic-window
heuristics appeared to be effective in isolating the desired
regions, any increase in region quality was overwhelmed by the
trend of larger windows providing better results.15
values and orthogonality. Surprisingly, although the dynamic-window
heuristics appeared to be effective in isolating the desired
regions, any increase in region quality was overwhelmed by the
trend of larger windows providing better results.15
|
In addition to varying window size, we can also choose to
include terms of multiple types (anchor, content, or links, as
described in Section 3) in
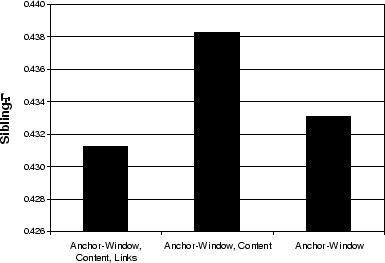
our document representation. Figure 5 shows that by combining content
and anchor-based bags, we can improve the sibling-![]() score.16 The intuition for this
variation is that if a particular document has very few incoming
links then the document's contents will dominate the bags.
Otherwise, if the document has many incoming links the
anchor-window-based terms will dominate. In this way, the
document's bag will automatically depend on as much information as
is available.
score.16 The intuition for this
variation is that if a particular document has very few incoming
links then the document's contents will dominate the bags.
Otherwise, if the document has many incoming links the
anchor-window-based terms will dominate. In this way, the
document's bag will automatically depend on as much information as
is available.
In the previous section, we saw that the anchor-based approach
with large windows performs the best. Our initial intuition,
however, that smaller windows would provide a more concise
representation is not completely without merit. In fact, we can
improve performance substantially under our evaluation criteria by
weighting terms based on their distance from the anchor. We prevent
ourselves from falling into the trap of making similar documents
appear orthogonal (small windows), while at the same time, not
giving spurious terms too much weight (large windows).
Figure 6 shows the
results when term weights are scaled by
![]() .
.
|
|
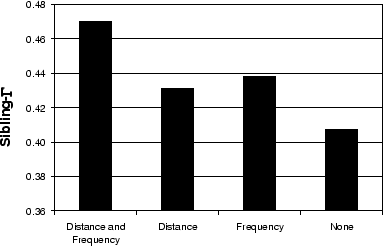
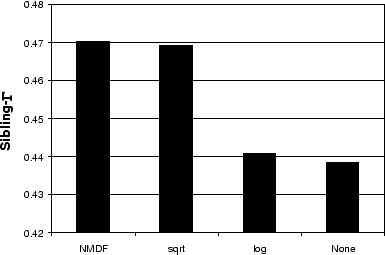
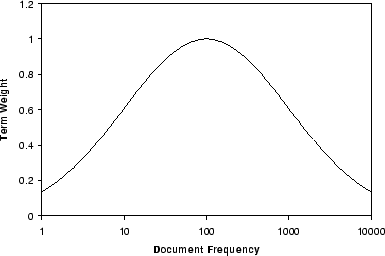
The results for frequency based weighting, shown in
Figure 7, suggest that
attenuating terms with low document frequency, in addition to
attenuating terms with high document frequency (as is usually
done), can increase performance. Let ![]() be a term's frequency in the bag, and
be a term's frequency in the bag, and ![]() be the term's overall
document frequency. Then in Figure 7, log refers to
weighting with
be the term's overall
document frequency. Then in Figure 7, log refers to
weighting with
![]() . sqrt refers to
weighting with
. sqrt refers to
weighting with
![]() .
NMDF refers to weighting with the log-scale gaussian
.
NMDF refers to weighting with the log-scale gaussian
![]() (see Figure 8).
(see Figure 8).
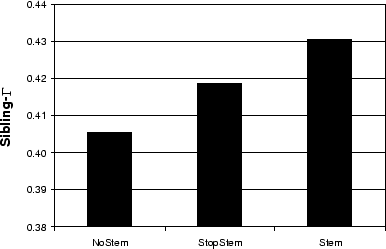
We now investigate the effects of our three stemming approaches.
Figure 9 shows the
sibling-![]() values for the NOSTEM, STOPSTEM, and
STEM parameter settings. We see that
STOPSTEM improves the
values for the NOSTEM, STOPSTEM, and
STEM parameter settings. We see that
STOPSTEM improves the ![]() value, and that STEM
provides an additional (although much less statistically
significant17)
improvement. As mentioned in Section 3.2, the effect of
STOPSTEM over NOSTEM is to increase
the effective reach of the stopword list. Words that are not
themselves detected as stopwords, yet share a stem with another
word that was detected as a stopword, will be removed. The small
additional impact of STEM over
STOPSTEM is due to collapsing word variants into a
single term.
value, and that STEM
provides an additional (although much less statistically
significant17)
improvement. As mentioned in Section 3.2, the effect of
STOPSTEM over NOSTEM is to increase
the effective reach of the stopword list. Words that are not
themselves detected as stopwords, yet share a stem with another
word that was detected as a stopword, will be removed. The small
additional impact of STEM over
STOPSTEM is due to collapsing word variants into a
single term.
We assume that we have selected the parameters that maximize the quality of our similarity measure as explained in Section 2. We now discuss how to efficiently find similar documents from the Web as a whole.
In tackling Problem 2, there is a tradeoff
between the work required during the preprocessing stage and the
work required at query time to find the documents ![]() -similar to
-similar to ![]() . We have explored two
approaches. Note that since
. We have explored two
approaches. Note that since ![]() is chosen from
is chosen from ![]() , all queries are known in advance. Using
this property, we showed in previous work ([14]) how to efficiently precompute and
store the answers for all possible queries. In this case, the
preprocessing stage is compute-intensive, while the query
processing is a trivial disk lookup. An alternative strategy, which
we discuss in detail in this section, builds a specialized index
during preprocessing, but delays the similarity computation until
query time. As we will describe, the index is compact, and can be
generated very efficiently, allowing us to scale to large
repositories with modest hardware resources. Furthermore, the
computation required at query time is reasonable.
, all queries are known in advance. Using
this property, we showed in previous work ([14]) how to efficiently precompute and
store the answers for all possible queries. In this case, the
preprocessing stage is compute-intensive, while the query
processing is a trivial disk lookup. An alternative strategy, which
we discuss in detail in this section, builds a specialized index
during preprocessing, but delays the similarity computation until
query time. As we will describe, the index is compact, and can be
generated very efficiently, allowing us to scale to large
repositories with modest hardware resources. Furthermore, the
computation required at query time is reasonable.
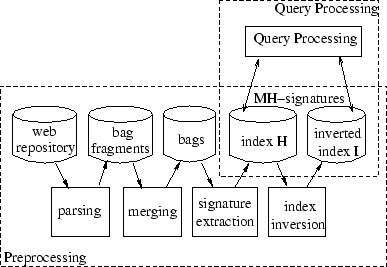
A schematic view of the INDEXALLSIMILAR algorithm is shown in Figure 10. In the next two sections, we explain INDEXALLSIMILAR as a two stage algorithm. In the first stage we generate bags for each Web document in the repository. In the second stage, we generate a vector of signatures, known as Min-hash signatures, for each bag, and index them to allow efficient retrieval both of document ids given signatures, and the signatures given document ids.
As we explained in the previous sections, the bag of each document contains words (i) from the content text of the document and (ii) from anchor-windows of other documents that point to it. Our bag generation algorithm scans through the Web repository and produces bag fragments for each document. For each document there is at most one content bag fragment and possibly many anchor bag fragments. After all bag fragments are generated, we sort and collapse them to form bags for the urls, apply our NMDF scaling as discussed in Section 3.3, and finally normalize the frequencies to sum to constant.
For the description of the Document Similarity Index (DSI)
generation algorithm, we assume that each document is represented
by a bag of words
![]() , where
, where
![]() are the words found
in the content and anchor text of the document, and
are the words found
in the content and anchor text of the document, and ![]() are the corresponding
normalized frequencies (after scaling with the NMDF function).
are the corresponding
normalized frequencies (after scaling with the NMDF function).
There exists a family ![]() of hash functions (see [7]) such that for each pair of documents
of hash functions (see [7]) such that for each pair of documents
![]() ,
, ![]() we have
we have
![]() , where the hash
function
, where the hash
function ![]() is
chosen at random from the family
is
chosen at random from the family ![]() and
and ![]() is the Jaccard similarity between the
two documents' bags. The family
is the Jaccard similarity between the
two documents' bags. The family ![]() is defined by imposing a random order on
the set of all words and then representing each url
is defined by imposing a random order on
the set of all words and then representing each url ![]() by the lowest rank (according
to that random order) element from
by the lowest rank (according
to that random order) element from ![]() . In practice, it is quite inefficient to
generate fully random permutation of all words. Therefore, Broder
et al. [7] use a family of
random linear functions of the form
. In practice, it is quite inefficient to
generate fully random permutation of all words. Therefore, Broder
et al. [7] use a family of
random linear functions of the form
![]() . We use the same
approach (see Broder et al. [6]
and Indyk [16] for the
theoretical background of this technique).
. We use the same
approach (see Broder et al. [6]
and Indyk [16] for the
theoretical background of this technique).
Based on the above property, we can compute for each bag a
vector of Min-hash signatures (MH-signatures) such that
the same value of the ![]() -th MH-signature of two documents indicates
similar documents. In particular, if we generate a vector
-th MH-signature of two documents indicates
similar documents. In particular, if we generate a vector ![]() of
of ![]() MH-signatures for each document
MH-signatures for each document ![]() , the expected fraction of the
positions in which the two documents share the same MH-signatures
is equal to the Jaccard similarity of the document bags.
, the expected fraction of the
positions in which the two documents share the same MH-signatures
is equal to the Jaccard similarity of the document bags.
We generate two data structures on disk. The first, ![]() , consecutively stores
, consecutively stores ![]() for each document
for each document ![]() (i.e., the
(i.e., the ![]() 4-byte MH-signatures for each
document). Since our document ids are consecutively assigned,
fetching these signatures for any document, given the document id,
requires exactly 1 disk seek to the appropriate offset in
4-byte MH-signatures for each
document). Since our document ids are consecutively assigned,
fetching these signatures for any document, given the document id,
requires exactly 1 disk seek to the appropriate offset in ![]() , followed by a sequential read
of
, followed by a sequential read
of ![]() 4-byte signatures.
The second structure,
4-byte signatures.
The second structure, ![]() , is generated by inverting the first. For each
position
, is generated by inverting the first. For each
position ![]() in
an MH-vector, and each MH-signature
in
an MH-vector, and each MH-signature ![]() that appears in position
that appears in position ![]() in some MH-vector,
in some MH-vector, ![]() is a list containing
id's for every document
is a list containing
id's for every document ![]() such that the
such that the ![]() . The algorithm for retrieving the
ranked list of documents
. The algorithm for retrieving the
ranked list of documents ![]() -similar to the query document
-similar to the query document ![]() , using the indexes
, using the indexes ![]() and
and ![]() , is given in Figure 11.
, is given in Figure 11.
When constructing the indexes ![]() and
and ![]() , the choice of
, the choice of ![]() needed to ensure w.h.p. that documents that are
needed to ensure w.h.p. that documents that are
![]() -similar to the
query document are retrieved by
PROCESSQUERY depends solely on
-similar to the
query document are retrieved by
PROCESSQUERY depends solely on ![]() ; in particular, it is
shown in [7] that the choice of
; in particular, it is
shown in [7] that the choice of
![]() is independent of
the number of documents, as well as the size of the lexicon. Since
we found in previous experiments that documents within an Open
Directory category have similarity of at least 0.15, we chose
is independent of
the number of documents, as well as the size of the lexicon. Since
we found in previous experiments that documents within an Open
Directory category have similarity of at least 0.15, we chose ![]() . We can safely
choose
. We can safely
choose ![]() for this value of
for this value of ![]() [10].18
[10].18
We employed the strategies that produced the best ![]() values (see
Section 5) in
conjunction with the scalable algorithm we described above (see
Section 6) to run an
experiment on a sizable web repository. In particular we used
size-32 anchor-windows with distance and frequency term weighting,
stemming, and with content terms included. We provide a description
of our dataset and the behavior of our algorithms, as well as a few
examples from the results we obtained.
values (see
Section 5) in
conjunction with the scalable algorithm we described above (see
Section 6) to run an
experiment on a sizable web repository. In particular we used
size-32 anchor-windows with distance and frequency term weighting,
stemming, and with content terms included. We provide a description
of our dataset and the behavior of our algorithms, as well as a few
examples from the results we obtained.
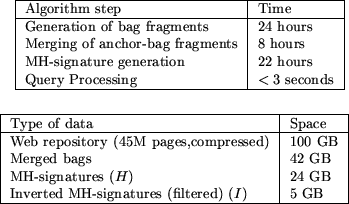
The latest Stanford WebBase repository contains roughly 120
million pages, from a crawl performed in January 2001. For our
large scale experiment, we used a 45 million page subset, which
generated bags for 75 million urls. After merging all bag
fragments, we generated 80 MH-signatures (![]() ) each 4 bytes long for each of the 75
million document bags.
) each 4 bytes long for each of the 75
million document bags.
Three machines, each AMD-K6 550MHz, were used to process the web
repository in parallel to produce the bag fragments. The subsequent
steps (merging of fragments, MH-signature generation, and query
processing) took place on a dual Pentium-III 933 MHz with 2 GB of
main memory. The timing results of the various stages and index
sizes are given in figure 12. The query processing step
is dominated by the cost of accessing ![]() , the smaller of the on-disk indexes. To improve
performance, we filtered
, the smaller of the on-disk indexes. To improve
performance, we filtered ![]() to remove urls of low indegree (3 or fewer
inlinks). Note that these urls remain in
to remove urls of low indegree (3 or fewer
inlinks). Note that these urls remain in ![]() , so that all urls can appear as queries; some
simply will not appear in results. Of course at a slight
increase in query time (or given more resources),
, so that all urls can appear as queries; some
simply will not appear in results. Of course at a slight
increase in query time (or given more resources), ![]() need not be filtered in this
way. Also note that if
need not be filtered in this
way. Also note that if ![]() is maintained wholly in main-memory (by
partitioning it across several machines, for instance), the query
processing time drops to a fraction of a second.
is maintained wholly in main-memory (by
partitioning it across several machines, for instance), the query
processing time drops to a fraction of a second.
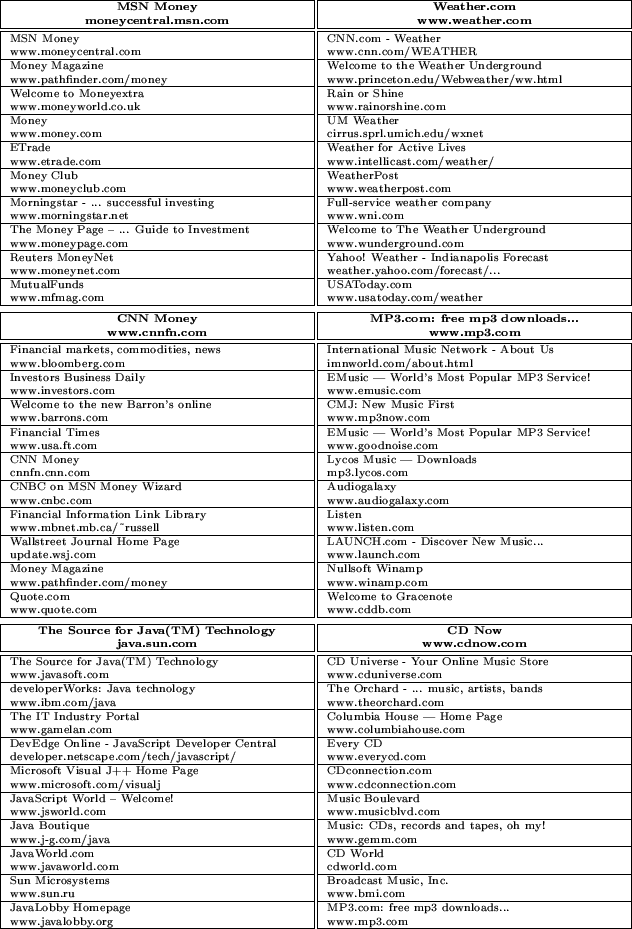
Accurate comparisons with existing search engines are difficult, since one needs to make sure both systems use the same web document collection. We have found however, that the ``Related Pages'' functionality of commercial search engines often return navigationally, as opposed to topically, similar results. For instance, www.msn.com is by some criteria similar to moneycentral.msn.com. They are both part of Microsoft MSN; however the former would not be a very useful result for someone looking for other financial sites. We claim that the use of our evaluation methodology has led us to the use of strategies that reflect the notion of ``similarity'' embodied in the popular ODP directory. For illustration, we have provided some sample queries in figure 13. In figure 14 we have given the top 10 words (by weight) in the bags for these query urls.19
Most relevant to our work are algorithms for the ``Related Pages'' functionality provided by several major search engines. Unfortunately, the details of these algorithms are not publicly available. Dean et al. [12] propose algorithms, which we discussed in Sections 1 and 5.1, for finding related pages based on the connectivity of the Web only and not on the text of pages. The idea of using hyperlink text for document representation has been exploited in the past to attack a variety of IR problems [1,3,8,9,11,18]. The novelty of our paper, however, consists in the fact that we do not make any a priori assumption about what are the best features for document representation. Rather, we develop an evaluation methodology that allows us to select the best features from among a set of different candidates. Approaches algorithmically related to the ones presented in Section 6 have been used in [7,4], although for the different problem of identifying mirror pages.
We would like to thank Professor Chris Manning, Professor Jeff Ullman, and Mayur Datar for their insights and invaluable feedback.
http://www.dmoz.com/.http://www.yahoo.com/.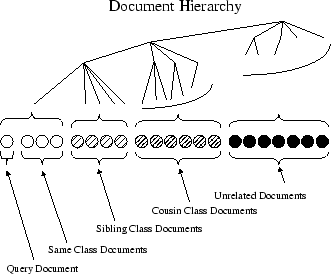
![\begin{figure}\begin{tabbing} llll\=llll\=llll\=llll\=llll\=llll\=llll\=llll\=ll... ...c_i, sim[doc_i]] \vert \frac{sim[doc_i]}{m} > \alpha\}$\end{tabbing}\end{figure}](../../CDROM/refereed/75/img166.png)