Marcel-Catalin RosuIBM T.J. Watson Research Center,NY, USArosu@us.ibm.com |
Daniela RosuIBM T.J. Watson Research Center, NY, USAdrosu@us.ibm.com |
Copyright is held by the author/owner(s).
WWW2002, May 7-11, 2002, Honolulu, Hawaii, USA.
ACM 1-58113-449-5/02/0005.
ABSTRACT
This study is the first to evaluate the performance benefits of using the recently proposed TCP Splice kernel service
in Web proxy servers. Previous studies show that splicing
client and server TCP connections in the IP layer improves
the throughput of proxy servers like firewalls and content
routers by reducing the data transfer overheads. In a Web
proxy server, data transfer overheads represent a relatively
large fraction of the request processing overheads, in particular when content is not cacheable or the proxy cache
is memory-based. The study is conducted with a socket-
level implementation of TCP Splice. Compared to IP-level
implementations, socket-level implementations make possible the splicing of connections with different TCP characteristics, and improve response times by reducing recovery
delay after a packet loss. The experimental evaluation is focused on HTTP request types for which the proxy can fully
exploit the TCP Splice service, which are the requests for
non-cacheable content and SSL tunneling. The experimental
testbed includes an emulated WAN environment and benchmark applications for HTTP/1.0 Web client, Web server,
and Web proxy running on AIX RS/6000 machines. Our
experiments demonstrate that TCP Splice enables reductions in CPU utilization of 10-43% of the CPU, depending
on file sizes and request rates. Larger relative reductions are
observed when tunneling SSL connections, in particular for
small file transfers. Response times are also reduced by up
to 1.8sec.
Categories and Subject Descriptors:
D.4.4 [Operating Systems]: Communications Management,D.4.8 Performance[measurements]
General Terms:
Measurement, Performance.
Keywords:
TCP Splice, Web proxy.
Web proxy servers represent a popular method for improving the performance of Web serving with respect to both bandwidth consumption and user-perceived response times. Web proxy caches are placed on the network paths that connect relatively large client populations, such as university campuses and ISP client pools, to the rest of the Internet. Web proxies process HTTP requests issued by clients, serving some of them from the local cache, and forwarding the rest to other proxies or to origin Web servers. In addition, Web proxies tunnel SSL connections between clients and Web servers.
The performance of Web proxy servers has been addressed by an extensive body of research, most of which has focused on components directly related to the caching functionality. For instance, previous studies addressed topics like cache replacement policies [4, 10], cache consistency protocols [11, 12], memory management [21], and disk I/O operations [17].
The work presented in this paper addresses Web proxy functionality not directly related to caching. Substantially less effort has been made to understand this type of functionality. For instance, only a few studies have addressed the proxy’s interaction with the networking subsystem, such as the implications of connection caching [7] and object bundling [28] on user-perceived response times.
This study addresses the problem of reducing the overheads of connection splicing, specifically, the process of transferring Web content between client and server connections. This process can represent a significant share of per-request service overheads, in particular when content is not cacheable or when the proxy cache is memory-based, like in some reverse proxy configurations [9].
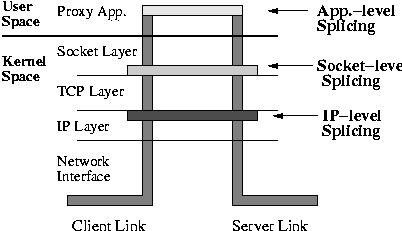
Traditionally, Web proxies implement connection splicing at the application level, by reading from one socket and writing to another. An alternative solution is to exploit the TCP Splice kernel service. This service was proposed as an approach to reducing the overheads of connection splicing in the more general context of split-connection proxies, like firewalls and mobile gateways [14, 27]. Figure 1 illustrates the conceptual difference between the traditional application- and kernel-level connection splicing. Namely, with the kernel service, packets are moved between server and client connections without copying data to/from application-level buffers. As a result, IP-level implementations of TCP Splice provide 25-50% CPU load reductions when evaluated in the context of mobile gateways [13], content-based routers [6], and TCP forwarders [27].
In this study, we use a TCP Splice service implemented at the socket level (see Figure 1). Socket-level implementations provide more flexibility than IP-level implementations in efficiently supporting the content-transfer needs of Web proxy caches, albeit at the cost of higher overheads.
The goal of this study is to evaluate, by way of experimentation, the improvements in CPU utilization and response times gained from using TCP Splice for various types of HTTP requests, request rates, and object sizes. As the first stage in an ongoing project, this study evaluates the use of TCP Splice for serving non-cacheable content and for tunneling SSL connections.
Our experiments demonstrate that TCP Splice enables substantial reductions in CPU utilization and response times. On an AIX RS/6000 proxy, the reduction in CPU utilization is 10-43% of the CPU. Larger relative reductions are observed when handling SSL connections, in particular for small file sizes. Response times for HTTP/1.0 requests are also reduced by 40ms-1.8sec for files larger than 5KBytes, and are almost unchanged for 1KByte files. In addition, our experiments demonstrate that the separation of client and server packet flows, intrinsic to socket-level TCP Splice, provides additional benefits, such as faster recovery from packet loss. These results are representative for many popular systems, given that the AIX-based TCP Splice implementation is derived from the BSD stack.
The remainder of this paper is organized as follows. Section 2 discusses the implications of TCP Splice in the context of Web proxies, and provides details on the socket-level TCP Splice mechanism. Section 3 describes the experimental methodology and testbed. Section 4 presents the experimental results. Section 5 discusses related research and Section 6 concludes the paper with a summary of our contributions.
Web proxy servers represent a particular case of split- connection proxies, namely servers that are interposed between the end server and the client machines to mediate their communication and/or to provide improved service value. A TCP connection carrying Web traffic may be split at several points between client and end server, such as at the boundaries of their domains, or at ISP servers.
Besides the World Wide Web, sample Internet services using split-connection proxies include firewalls, gateways for mobile hosts, and stream transducers. In traditional implementations, these proxy servers use application-level modules to transfer data between client and server connections. Previous studies demonstrate that the performance of these solutions is limited by the substantial overhead of handling a large number of active TCP connections in user space [2].
The TCP Splice kernel service was proposed as a mechanism for lowering the overheads of split-connection proxies. This is achieved by eliminating the double data copy between kernel and application buffers incurred for each packet exchanged between corresponding client and server endpoints. In the basic interaction mode, a firewall application can exploit TCP Splice as follows: receive and process the client request, establish the connection to the server, send response to the client, and invoke TCP Splice for the two connections. The TCP Splice kernel service transfers data between the two connections, in both directions, until one of the endpoints closes its connection.
|
|
A Web proxy cache can exploit the basic TCP Splice service to handle SSL tunnels and HTTP/1.0 requests for content determined to be non-cacheable based on the request message. Figure 2 presents the pseudo-code for sample procedures for handling CONNECT and GET requests; both procedures are invoked after the proxy accepts the client connection, analyzes the request, and opens the server connection.
Previous implementations of the TCP Splice kernel service connect pairs of client and server TCP connections at IP level, through IP forwarding and TCP sequence number rewriting (see Figure 1) [6, 14, 27]. Besides eliminating data copies, IP-level implementations eliminate some of the overhead of TCP processing. With most of these implementations [6, 14], a Web proxy can exploit TCP Splice only for the basic types of transfers presented in Figure 2. A richer interface, available in a communication-specialized operating system, allows the proxy to splice after part of the server reply is received (e.g., HTTP headers), and to unsplice when data is received from the client (e.g., subsequent HTTP requests) [27]. With this interface, a Web proxy can invoke TCP Splice after it reads the reply headers and determines that the content is not cacheable.
However, for Web proxy caches, IP-level TCP Splice implementations pose several limitations. First, the spliced client and server connections must have identical TCP characteristics (e.g., SACK, Maximum Segment Size, timestamps, and window scale). Therefore, when a client lacks SACK, like Windows 95 clients do, the proxy cannot exploit SACK for the server transfer, which may penalize the performance [18]. Second, when using an IP-level implementation to cache the content passing through the TCP Splice [15], the effectiveness of the Web proxy is highly sensitive to the abort behavior of client connections. When the client aborts the transfer, as often occurs in Web proxy workloads [7], the proxy has to abort the caching procedure because it cannot receive the complete copy of the content. Therefore, all of the proxy resources spent for the particular transfer are wasted. Finally, with an IP-level implementation, it is not possible to unsplice client and server connections on response boundaries. A Web proxy has to force the server connection to HTTP/1.0 mode in order to fully exploit its cache.
These limitations derive from the characteristic of IP- level TCP Splice of not interfering in the flow of data and ACK packets exchanged by the endpoints. Namely, as data packets are acknowledged only by the two endpoints of a data connection, client and server connections’ characteristics must match. This characteristic enables an IP-level TCP Splice implementation to preserve the end-to-end semantics of TCP, feature deemed important for wireless base station or gateways [1, 13], but not relevant for Web proxy caches.
In contrast to IP-level implementations, socket-level TCP Splice implementations interfere in the flow of data and ACK packets exchanged between client and server, isolating almost completely the two spliced connections. This allows the splicing of any two connections, independent of their TCP characteristics, thus overcoming this limitation of IP-level TCP Splice. The extent of coupling between two spliced connections is determined only by their maximum data transfer rates, and by the size of their send and receive socket buffers on the proxy.
Socket-level TCP Splice incurs larger CPU and memory overheads than IP-level Splice due to TCP layer processing (see Figure 1). However, the difference in CPU overheads is much smaller than the reductions due to removing the data copies between kernel and user buffers (see Section 4.1), and, as a result, TCP Splice allows a Web proxy application to benefit from significant overhead reductions.
Unlike IP-level implementations, socket-level TCP Splice can be naturally extended to provide the proxy application with a copy of the transferred content, and to splice over HTTP/1.1 connections. A TCP Splice invocation can be associated with transfer attributes such as the amount of content to be transferred and the method of handling new data packets received from the client. The proxy can regain control of the spliced connections when the current transfer is completed and input is received on one of the connections. Moreover, with socket-level TCP Splice, the proxy cache can collect the server’s reply even if the client connection is aborted. This enables the proxy to reduce the negative effects of connection aborts on bandwidth consumption.
Therefore, we submit that a socket-level implementation of the TCP Splice kernel service allows us to address the complex content delivery scenarios that occur in a Web proxy. Previous work has only considered socket-level implementations for their bandwidth benefits in kernel-mode split- connection wireless routers [2]. No study has considered yet its potential benefits and tradeoffs in a Web proxy system.
The socket-level implementation of TCP Splice used in this study is an extension of the BSD-based TCP/IP stack of AIX, IBM’s Unix. The current implementation is restricted to the basic functionality, which can be exploited only for handling CONNECT requests and GET requests for non-cacheable content over HTTP/1.0 connections. Extensions fully exploiting the flexibility offered by the socket-level implementation paradigm are under development.
The kernel service is accessible at the application level through the splice() system call. By calling splice(A,B), an application relinquishes the control of the socket pair (A, B) to the TCP Splice kernel service. TCP Splice moves data packets between the two sockets through simple manipulations of their receive and send buffers. Namely, after an incoming data packet on connection A is successfully processed by the TCP layer, it is added to B’s send buffer, if space is available. The data packet is sent out on connection B as soon as B’s congestion control window allows it. If B’s send buffer is full, the packet is added to A’s receive buffer. The packet is moved to B’s send buffer and sent out when space becomes available.
The ACK flows on the two connections are independent. For instance, ACKs are sent to the server independently of the state of the client connection. ACKs received from the client are processed by the proxy and not forwarded to the server.
One of the appealing attributes of a socket-layer TCP Splice implementation is simplicity. Our implementation consists of approximately 100 lines of C code. Although scientifically unimportant, simplicity played an important role in its acceptance in the 5.10 release of AIX.
The goal of our experimental study is to evaluate the impact of using the TCP Splice kernel service in a Web proxy system, focusing on performance metrics like per-request CPU utilization and response time. Therefore, the experimental environment aims to isolate the communication- related procedures from the variability induced by other Web proxy-specific functionality, like HTTP processing and cache management. Thus, rather than using complex proxy applications, like Squid or Apache, our study is conducted with a suite of simple benchmark applications. Similarly, the experimental environment aims to control the variability of workload parameters, like file sizes and request types. Thus, rather than using more realistic proxy workloads, like PolyMix [23], our study is conducted with streams of requests for fixed-size content and controlled type distributions. Using our experimental results, one can infer the expected impact for relevant Web proxy traces, based on the corresponding distributions of object sizes.
This study takes a high-level view at the benefits deriving from TCP Splice. It does not attempt to determine the individual contributions of the various sources of CPU overhead eliminated by TCP Splice, such as data copies or context switches.
This section describes the experimental environment used for the experimental evaluation presented in the paper. Section 3.1 describes the hardware and software used in our experiments. Section 3.2 describes the experimental testbed and the emulated network conditions. Finally, Section 3.3 describes the experimental methodology.
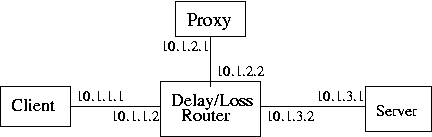
Three IBM RS/6000 servers and one PC are used in the experiments. The three servers run the Web client, the Web server, and the Web proxy applications. The PC acts as a router that emulates wide-area network conditions, introducing packet losses and delays, and enforcing bandwidth limitations. Table 1 describes the hardware configurations of the four machines.
| CPU Type | Speed (MHz) | Memory (MBytes) | |
| Web Client | 32-bit PPC |
200 |
256 |
| Web Server | 64-bit PPC |
200 |
256 |
| Web Proxy | 32-bit PPC |
133 |
128 |
| Router | PentiumPro |
200 |
256 |
The Web client, server, and proxy run AIX 5.10; the network router runs RedHat 7.1 Linux with the 2.4.9 kernel. The AIX TCP implementation is derived from BSD 4.4 and it has been previously extended to support NewReno, SACK, Limited Transmit, ECN, and to handle large workloads [18]. On the router machine, a Linux kernel extension is used for network emulation; no applications run on this machine. The client, server, and router machines are never overloaded in these experiments.
The client machine generates HTTP workload using an extended version of the s-client [3], a low-overhead, event- driven generator of HTTP requests. The client machine runs one instance of the s-client configured to emulate a specified number of concurrent clients (i.e., connections). For each emulated client, the s-client performs the following four steps: (1) open connection to proxy, (2) send HTTP/1.0 request, (3) wait for response, and (4) close connection. When a connection is closed, a new one is immediately opened. The s-client is a single-threaded process. It is built around a select loop including all of the application’s open sockets. The request rates produced by this request generation model depends on the number of concurrent clients and the service delays in the Web infrastructure.
The s-client is extended to issue a mix of GET and CONNECT requests. GET requests can be for cacheable or non-cacheable content. CONNECT requests involve an SSL- like handshake followed by a regular GET. Request types are generated according to a specified distribution.
To emulate the SSL handshake, the s-client is extended with a mechanism for generating a configurable message exchange before sending the HTTP GET command. In our experiments, client and server applications exchange messages of the same length and in the same order as in typical SSL handshakes [25]. Neither the client nor the server run the SSL protocol, but the proxy handles a realistic SSL workload.
The server machine runs an HTTP-server emulator, which returns the appropriate HTTP headers and uses a random stream of characters for the HTTP body. The length of the HTTP body is determined by an application-specific HTTP header in the request.
The proxy machine runs a very simple Web proxy with an emulated memory-based cache. The proxy handles GET and CONNECT requests and uses the select() system call to monitor socket activity for all of its pending connections. For a GET request, the proxy uses the request headers to decide between serving the request locally and forwarding it to the server. For a GET serviced from the “cache”, the proxy generates the reply message using the same procedure as the HTTP server emulator described above. For a GET serviced from the server, the proxy opens a connection to the server, forwards the request, and transfers the reply to the client. For a CONNECT request, the proxy establishes a new connection to the server and starts tunneling data between the two connections.
The proxy can be configured to use the TCP Splice kernel service or to perform application-level splice. When using TCP Splice for GET requests, the proxy can be configured to splice the connection either immediately after the connection to the server is established, or after reading the HTTP headers from the server. When splicing at application level, the per-connection I/O buffer is 32Kbytes. No copy between server and client-connection buffers is incurred.
In comparison to Squid, a real-world proxy application, our proxy uses the same select-based approach to handling active connections, but it has limited HTTP header processing, no access rights control, and no cache management overheads.
In all experiments, the three AIX machines are configured on separate subnets connected by the router. For improved predictability of the emulated network, the AIX machines are connected to the router directly, by crossover Ethernet cables and Fast Ethernet network interfaces (see Figure 3); an additional interface connects the client machine to the corporate network.
On the router, network delay and loss conditions are emulated with a modified version of NISTNet [19]. NISTNet is extended with a two-state dependent loss model in which the loss probability of a packet following a dropped packet is different from the probability of the initial loss in the packet stream. This change is motivated by several Internet studies [22, 26] which show that the probability of a packet being dropped is much higher when it immediately follows a dropped packet than otherwise. In addition, a cache of (network filter, mask)-pairs is added in front of NISTNet’s hash-based packet filter in order to avoid trying multiple masks for each packet. This modification lowers the CPU overheads of the emulator, particularly important for experiments with high traffic volume.
| Client-Proxy | Proxy-Server | |
| Corporate | 10ms/(0.1%,40%) | 90ms/(1%,40%) |
| 56K Modem, Loss 1% | 50ms/(0.1%,40)%) | 90ms/(1%,40%) |
| 56K Modem, Loss 2% | 50ms/(0.1%,40%) | 90ms/(2%,40%) |
The selection of network condition parameters aims to approximate existing Internet conditions. Table 2 presents the three wide-area delay/packet loss settings used in this study. The first setting aims to emulate network conditions experienced by corporate or broadband users. For the range of transfers considered in these experiments, users do not experience any bandwidth limitations. The other two settings aim to emulate the conditions experienced by 56k-modem users, and differ only by the initial loss parameter on the proxy-server link. Each modem connection is limited to 56kbits/sec downstream and 28kbits/sec upstream. These restrictions are implemented as 6000 separate NISTNet rules and the client machine is configured to allocate ephemeral TCP ports within the range covered by these rules.
The parameters varied in this study are the following: (1) number of Web clients, (2) size of transferred Web objects, (3) type of requests, (4) connection splice method, (5) network conditions, and (6) connection characteristics. In the experiments with homogeneous request types (i.e., all GET or all CONNECT), the number of Web clients varies from 20 to 140 in increments of 20. In the experiments with mixed request types, Web clients vary from 40 to 160 in increments of 40. The selected object sizes are 1, 5, 10, 15, 20, 33, 45, 64, 71, 90, 100, 110, and 128 Kbytes. With this set of parameters, the client and server machines are never overloaded. Unless otherwise mentioned, NewReno and Limited Transmit are on, and SACK is off.
| Handshake | Sequence: Source(bytes) |
| Full | Clt(98) Srv(2239) Clt(73) Srv(6) Clt(67) Srv(61) |
| Abbreviated | Clt(98) Srv(79) Srv(6) Srv(61) Clt(6) Clt(61) |
For experiments with SSL traffic, message exchanges emulate both full and abbreviated SSL handshakes [25]. Among all handshakes, 60% are abbreviated [16]. The message exchange is described in Table 3. For instance, the full handshake starts with a 98-byte message from the client, followed by a 2239-byte message from the server, another 73- byte message from the client, and so on. These message sequences are derived from observed traffic and SSL specification [25]. The SSL exchange is included in the reported response latency.
For each experiment, we collect the statistics displayed by the client application, and the statistics produced by vmstat and tcpstat running on the client, proxy, and server machines. Client statistics include request rates and response times. vmstat provides information on CPU utilization, and tcpstat provides information on TCP transfers. TCP statistics are used to verify the emulated loss rates.
Each data point on the performance graphs is the average of ten runs. Each run includes sampling intervals of 120 sec for experiments emulating corporate networks, and of (20 * file_size/1024) seconds for experiments emulating modem traffic. All runs have 20 sec warm-up intervals and 20 sec shutdown intervals.
To compare the CPU overheads in various configurations, we consider the per-request CPU utilization rather than the total CPU utilization. This is because the experiments we compare are characterized by different request rates.
All plots of performance metrics for a single configuration include 90-percent confidence intervals, calculated with the T-student distribution. Note that the confidence intervals are very small, sometimes hardly visible on the plots. This is due to the workload model and to the relatively large number of samples. To show relative performance for two configurations, we plot the difference between the corresponding values in the two configurations; these plots do not include confidence intervals.
This section presents experimental results regarding the following topics: (1) basic packet forward delays with application- and socket-level splice (Section 4.1); (2) implications of socket-level splice on transfer overheads and latencies for GET requests (Section 4.2); (3) implications on performance for SSL tunneling (Section 4.3); (4) interactions between splicing for cache misses and serving cache hits (Section 4.4); and finally, (5) implications of socket-level TCP Splice on response times for slow dial-up clients (Section 4.5).
This suite of experiments evaluates the packet forwarding overheads associated with application- and socket-level splice. Towards this end, we measure the time it takes the proxy to forward an HTTP request from client to server, and to forward the first data packet of the response from server to client. We use tcpdump traces taken on the proxy machine; as a result, adapter and device driver delays are not included. The client application is configured to emulate one Web client; therefore, there is only one outstanding request at any time.
For an HTTP request packet, the forwarding delay is measured as the time between the receipt of the first data packet on the client connection and the send of the first data packet on the server connection. For a server response packet, the forwarding delay is measured as the time between the arrival of the first data packet from the server connection and the departure of the first data packet on the client connection.
| Packet Type | App. Level | Socket Level | IP Forward |
| HTTP Req. | 182,128 us |
182,173 us |
-- |
| Server Resp. | 1,240 us |
278 us |
159.8 us |
The results are summarized in Table 4; the values are averages of 15 measurements of loss-free connection establishments. As expected, the forwarding delays for HTTP requests are similar for the two splicing methods. Note that for both methods, request forwarding delays include the 180ms RTT between proxy and server, that is incurred when establishing the server connection.
For server responses, the difference in forwarding delays is significantly larger; socket-level splicing is about 75% faster than application-level splicing. This is because socket-level splice eliminates two system calls, and the associated data copies and context switches.
We also want to compare socket- and IP-level splicing. Because no implementation of IP-level splice is available on AIX, we consider the simpler process of IP forwarding. The IP forwarding delay is an underestimate for IP-level splice forwarding delay for server responses. As expected, forwarding delays for socket-level splice are larger than IP forwarding delays. However, the (approx) 120 us difference is substantially smaller than the savings of socket- vs. application-level splice. Note that these measurements cannot be used to estimate the CPU overheads of any of the splicing methods. This is because the delays measured with tcpdump traces do not include all of the overhead-related components, such as interrupt processing.
This suite of experiments evaluates the implications of using TCP Splice to service HTTP requests. Towards this end, we choose a transfer-bound proxy workload, composed only of GET requests for non-cacheable objects. The proxy can decide the object’s cacheability based on request parameters. Therefore, in the experiments using socket-level splice, the proxy invokes the splice system call without waiting for server reply.
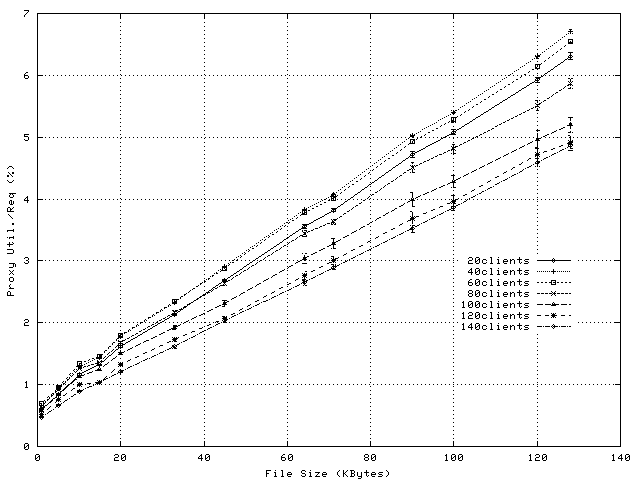
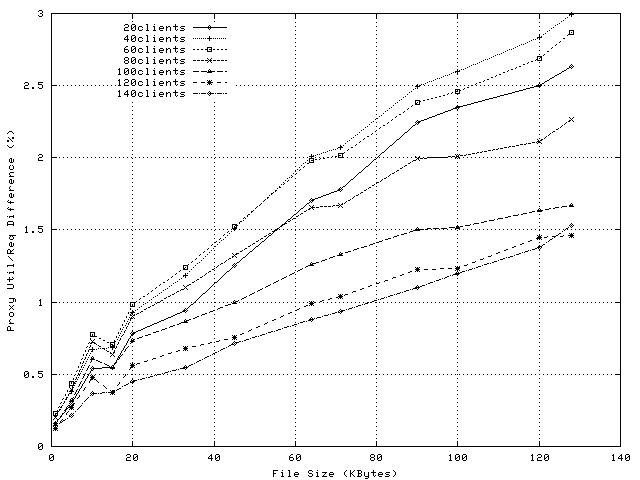
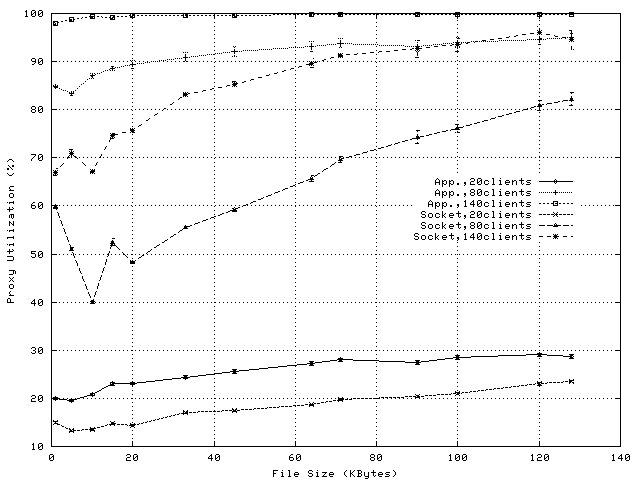
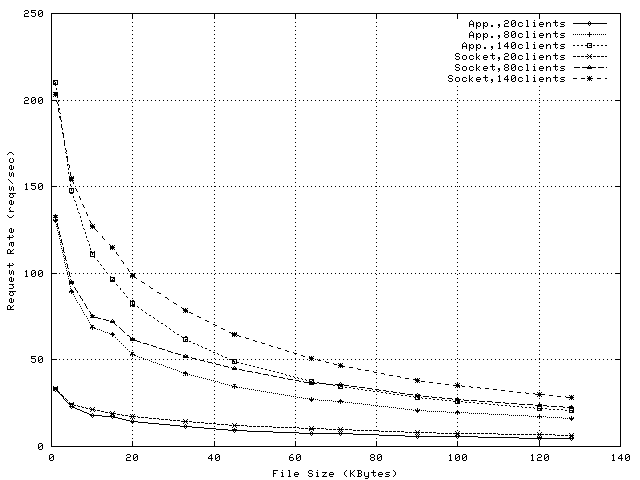
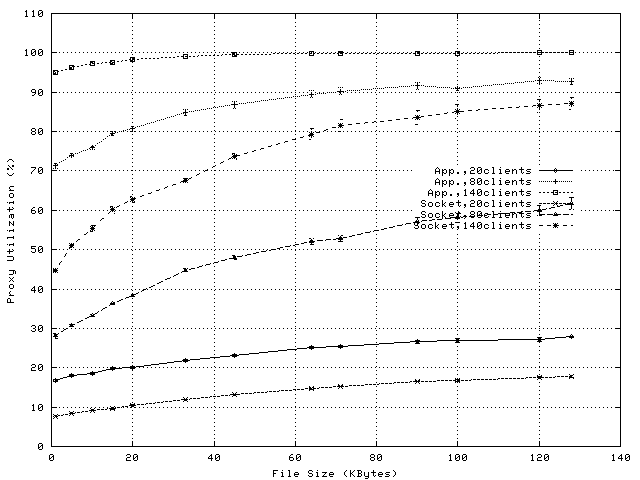
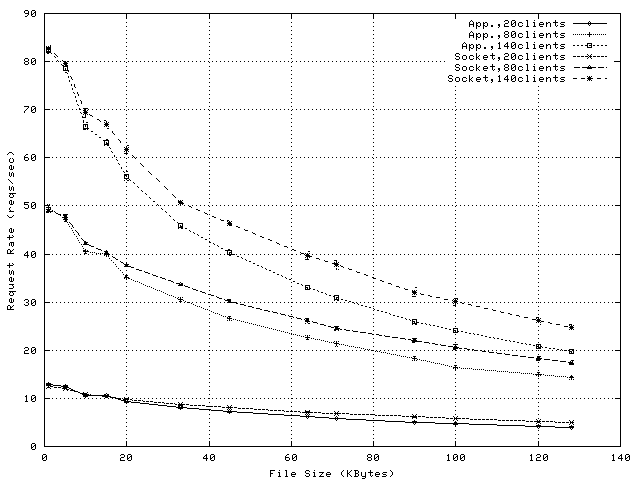
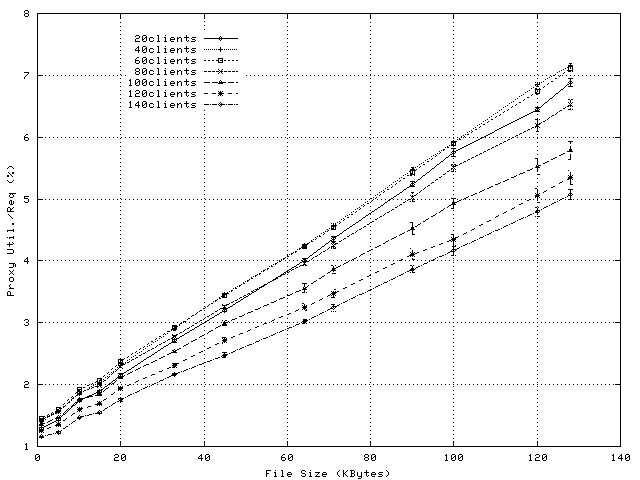
Figure 4 shows the per-request CPU overheads on the proxy when using application-level splicing and Figure 5 shows the savings in CPU overhead achieved by exploiting socket-level TCP Splice. Proxy loads observed during these experiments vary between 15% and 100% (see Figure 6) and observed request rates vary between 10 and 200reqs/sec (see Figure 7).
Figure 5 illustrates that for this type of workload, the reductions in per-request CPU utilization represent 0.2-3% of the CPU. As expected, the difference in CPU utilization increases with object size. Reductions in CPU utilization are observed even for 1KByte files. This means that the overhead of setting up the spliced transfer is smaller than the overhead of transferring one 1Kbyte data block to, and from application level.
The drop observed between 10 and 15KBytes is because the increase in per-request overheads for application-level splice is smaller than the corresponding increase for socket- level splice. This phenomenon, as well as the decrease in the slopes of the CPU-savings plots (Figure 5) when the load increases is explained by an intrinsic adaptability of application-level splice. Namely, as the number of clients or the file size increases, the amount of data read in one operation by the proxy application increases. This reduces the number of system calls per transfer, and the number of ACK packets sent to the server(see Note1). Consequently, the per-request overheads of a proxy using application-level splicing diminish with the load increase.
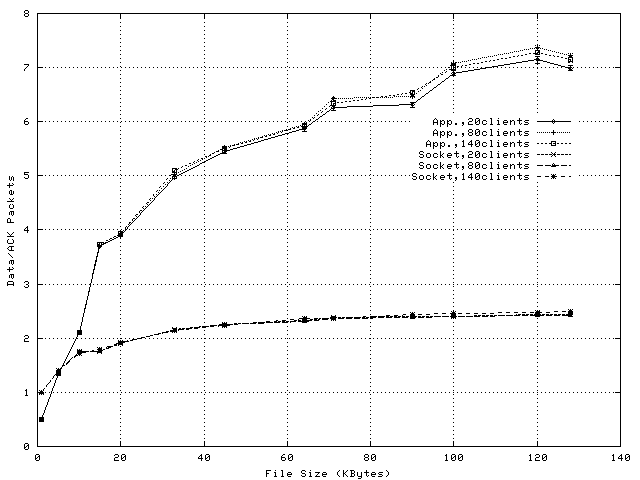
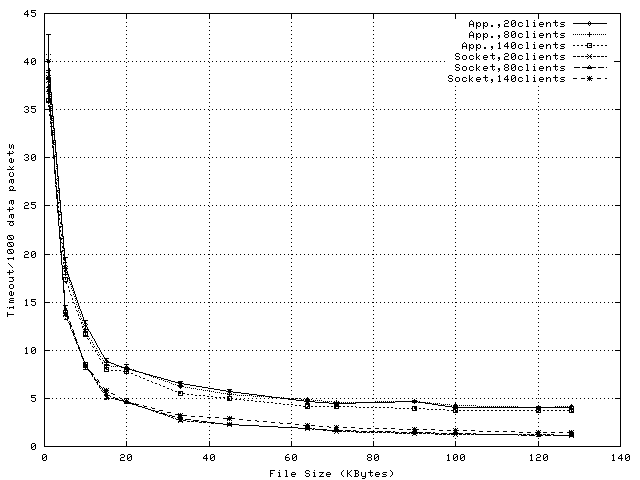
To illustrate the variation of ACK-related load, Figure 8 shows the number of data packets sent by the server machine for each received ACK packet. The plots show that a proxy using socket-level splice sends an ACK packet for every two data packets received, independent of the file size and proxy load, which closely matches the typical TCP ACK pattern. This demonstrates that this splicing method does not exhibit an intrinsic adaptability to load increase, and therefore, its CPU savings decrease for large object sizes and number of clients. However, sending an ACK for every two received data packets increases the server congestion window faster and reduces the number of TCP timeout retransmissions, as shown in Figure 9.
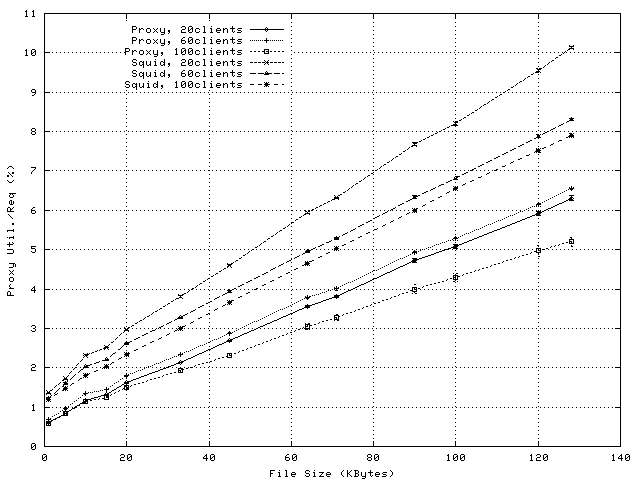
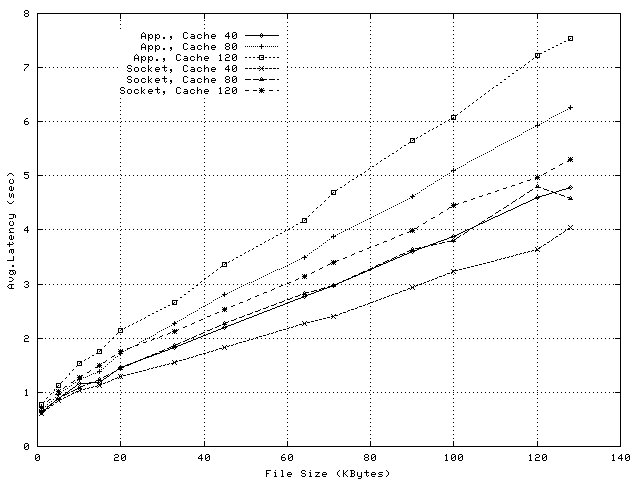
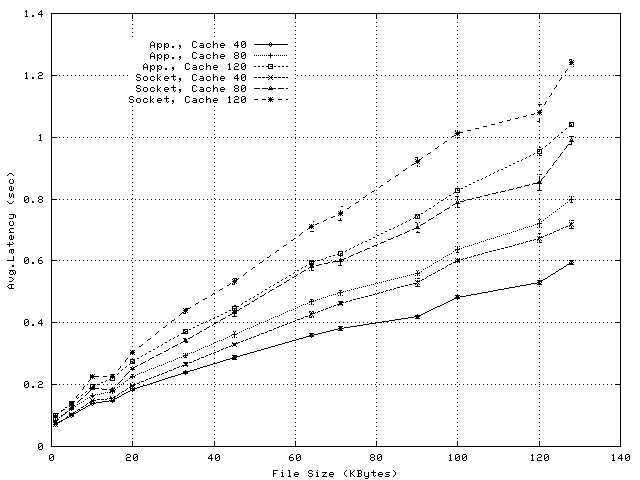
In order to evaluate the relevance of the CPU reductions achieved by socket-level splice for a real proxy application, we compare the per-request CPU utilizations of the benchmark proxy application and of Squid, running in a configuration like the one used for the Third Web Cache Cache-off [24]. The results, presented in Figure 12, illustrate that the savings enabled by splicing at socket level (see Figure 5) represent a relevant share of the per-request overheads incurred by Squid.
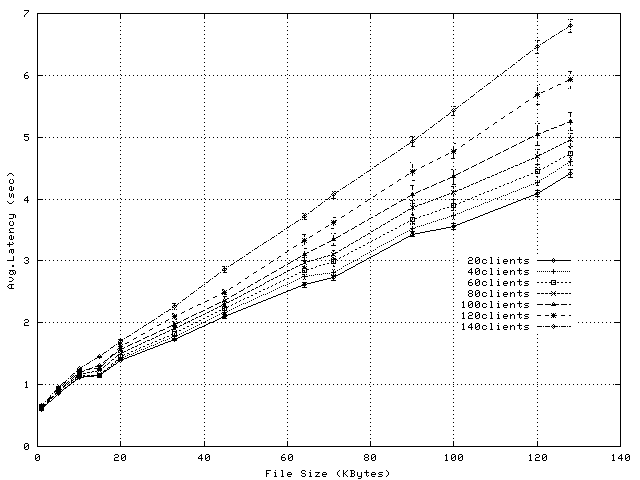
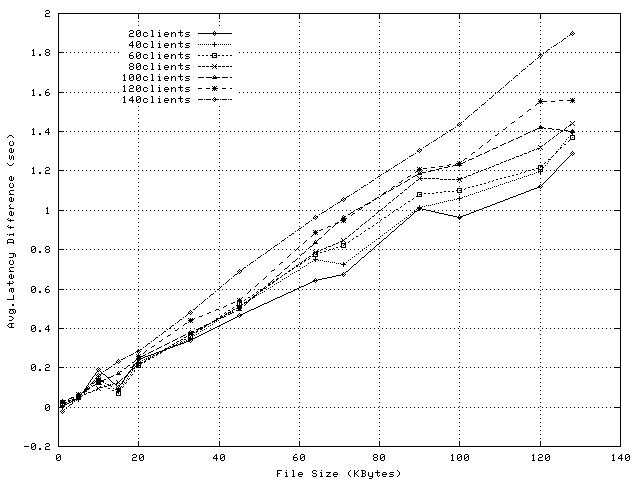
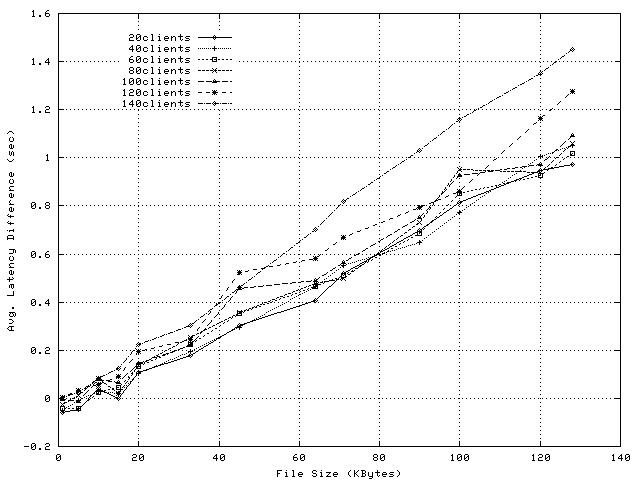
In addition to lowering proxy overheads, socket-level splice improves the response latency. Figure 10 shows the average response time of application-level splice and Figure 11 shows the reductions enabled by socket-level splice. For files larger than 5KBytes, the latency reduction ranges from 3ms to 1.8sec. For 1KByte files, and in particular under very high load, socket-level splice is characterized by higher latency than application-level splice. In these experiments, we observe an increase only for 140 clients; namely, at about 210reqs/sec, latency increases by 24ms, from 664ms to 688ms. We believe this is because bursts of packet transfers occurring at socket level delay the processing of packets at application level.
In summary, the experiments presented in this section demonstrate that socket-level TCP Splice can result in significant CPU savings compared to application-level splice, with larger benefits as the transferred object size increases. In addition, socket-level splice improves client-perceived response times, provided the kernel-level transfers do not delay significantly the application-level processing.
This suite of experiments evaluates the impact of SSL tunneling on a proxy server and the benefits of using socket-level TCP Splice. While large Web proxy clusters have routers that redirect the SSL traffic to bypass the servers, small, single-node systems have to handle SSL traffic. Therefore, we consider it useful to study the Web proxy performance with SSL traffic.
For these experiments, each s-client connection involves a CONNECT requests to the proxy, the SSL handshake protocol with the server, and a GET request (reaching directly the server). Figure 15 shows the per-request overheads on the proxy, and Figures 13-14 present variation of (total) CPU utilizations and request rates, respectively.
As expected, the SSL handshake increases substantially the per-request overheads of the proxy. For small objects, the handshake more than doubles the per-request CPU utilization (for comparison, see Figure 4). The relative increase in proxy overheads is smaller for larger objects, for which the ratio of the SSL handshake packets into the total number of transferred packets gets smaller.
Using socket-level splice to tunnel SSL connections reduces the per-request overheads by 0.6-3.5% of the CPU (see Figure 16). In contrast to regular HTTP transfers (see Figure 5), when tunneling SSL requests, the relative overhead reduction is higher for smaller objects, as the SSL handshake overhead is independent of object size. Figure 17 presents the reductions in average latency. These reductions are lower than for regular HTTP transfers. This is because the number of packets transferred at socket level is larger with SSL, and thus the likelihood of large bursts that delay application-level processing is higher.
This suite of experiments evaluates the implications of using socket-level TCP Splice when the Web proxy is handling a mix of request types, including (1) requests for cacheable objects, served by the proxy, (2) requests for non-cacheable objects, forwarded by the proxy to the server, and (3) requests over SSL connections, tunneled by the proxy to the server. Our interest is to observe how the processing of cache hits influences the transfers from the server on spliced connections, and conversely.
In the first experiment, the average number of concurrent requests that go to the server is fixed to an average of 40, of which 25 are requests for non-cacheable objects, and 15 are requests for SSL tunnels. The average number of requests for cacheable objects is varied between 0 (out of 40) and 120 (out of 160).
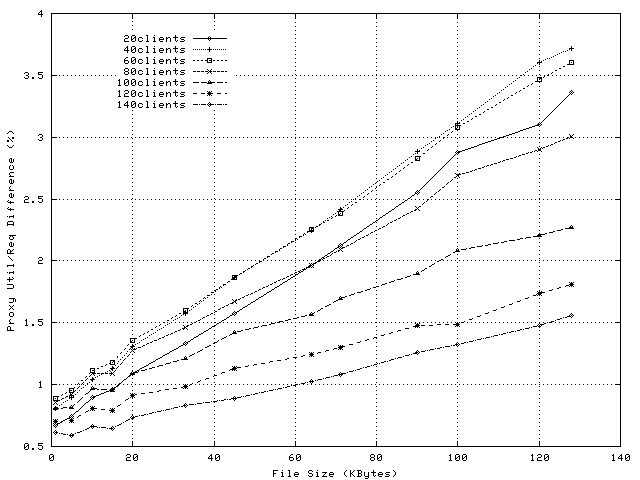
Figure 18 presents the average latency observed by spliced, non-SSL transfers when the average number of cache-served requests is varied. The plots show that the latency increase is substantially slower when the requests that are forwarded or tunneled to the server are spliced at socket level rather than at application level.
In the second experiment, the average number of cache- served requests is fixed at 40, and the average number of spliced requests is varied from 0 to 120. No SSL connections are used in this experiment.
Figure 19 presents the average latency increase observed by cache-served requests. The plots illustrate that application- level splicing results in a smaller penalty on the latency of cacheable requests. The performance penalty of socket-level splice increases with the file size and number of concurrent connections that are spliced. This penalty is not determined by a difference in request rates, which are quasi-identical for the two splicing methods.
To summarize, these experiments illustrate two facts. First, ’local’ proxy activity has a smaller impact when TCP connections are spliced in the kernel, at socket level. Second, kernel-level splicing can induce performance penalties on the ’local’ proxy activity because of the higher service priority that spliced requests observe when handled at kernel-level. We plan to address this issue in the future. Note that this is less of a concern when the proxy uses the sendfile system service to send cached content to clients, like Apache does, because most of the related processing is performed at same priority level as the spliced transfers.
This suite of experiments evaluates the implications of decoupling the client and server connections, feature that differentiates the socket- and IP-level implementations of TCP Splice. This feature enables the decoupling of low- speed client-proxy connections from the higher-speed proxy- server connections, and the use of advanced TCP features, like SACK, on the proxy-server connection.
For these experiments, the IP-level implementation of TCP Splice is approximated by removing the proxy from the path between client and server. Thus, the observed response times are smaller than for a real IP-level implementation, as no IP-forwarding delay is actually incurred.
The workload includes only requests for non-cacheable objects. The emulated network conditions correspond to the two ”modem” settings described in Table 2, for which the initial loss rates on the proxy-server link are 1% and 2%, respectively. For the experiments with (socket-level splicing) proxy, the router is configured to emulate exactly these settings. For the experiments without a proxy, the emulated network latency and initial loss rate are equal to the sum of the corresponding parameters for the client-proxy and proxy-server network segments; the conditional loss rate and bandwidth limit are the same as in the experiments with proxy. SACK is always disabled on the client machine.
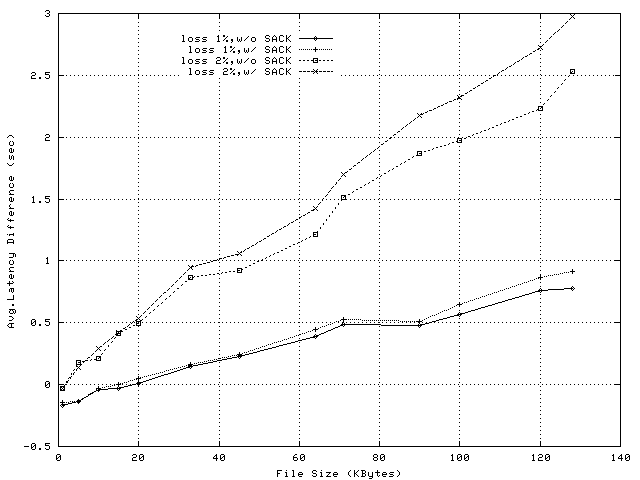
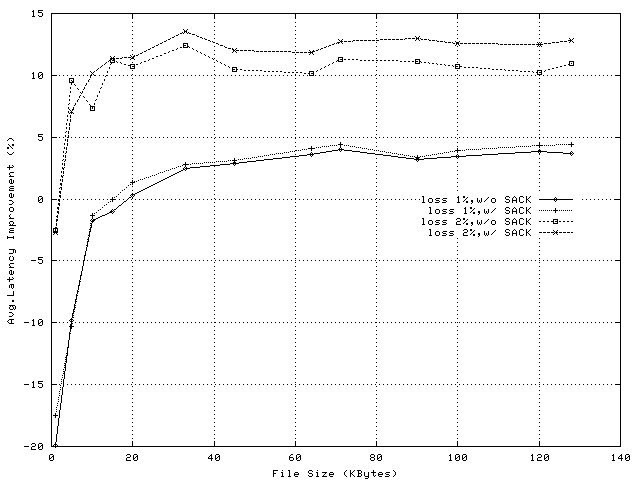
Figure 20 shows the difference in response latency between the no-proxy and proxy configurations in experiments with 20 clients. For small files and lower loss rate, the latency difference is negative; the minimum response times (see Note2) in the no-proxy configuration are (approx.) 200ms lower than the corresponding times in the proxy configuration. This difference is determined by the service delays in the proxy application. For larger files or larger loss rate, the difference becomes positive as the presence of the proxy (see Figure 8) helps reduce average transfer times. It is worth noting that the observed latency differences, which are up to 0.75sec for 1% loss and 2.3sec for 2% loss, do not translate in significant relative improvements. Figure 21 presents the improvement, computed as [(1 - latency.proxy/latency.no_proxy)* 100]. Our experiments also illustrate that using SACK between server and proxy can further improve average response times.
The latency reductions illustrated by these experiments are independent on whether the client TCP stack implements the SACK feature, and can only be achieved with socket-level implementations of TCP Splice. IP-level implementations cannot improve the TCP transfer rates between client and server machines.
Recent research on Web (proxy) server performance has focused on optimizing the operating system functions on the critical path of request processing. For instance, [21] proposes a unified I/O buffering and caching system that eliminates all data copies involved in serving client requests and eliminates multiple buffering of I/O data. In this paper, we focus on the overheads of the I/O subsystem, evaluating for the first time, a mechanism that Web proxy servers can use in a flexible manner to handle non-cacheable content and SSL tunneling.
Numerous studies on TCP and server performance demonstrate that the overhead of copying data between kernel and user-space buffers is a limiting factor for the achievable transfer bandwidths. For instance, [5] demonstrates about 26% bandwidth improvement at 8KByte MTU, when the application is not touching the data, like a Web proxy handling SSL connections or non-cacheable content. The socket-level TCP Splice mechanism, that we propose to exploit in Web proxy severs, is particularly targeted to reduce these overheads; the experimental results presented in this paper demonstrate relevant CPU overhead reductions.
Previous research has proposed and evaluated several mechanisms for kernel-level splicing of TCP connections. Some of these solutions [2, 6, 8, 20] do not make the splicing interface available at application level. These solutions are integrated with kernel-level modules for HTTP request distribution and are implemented either between the TCP and socket layers [2, 20] or in the IP layer [6, 8]. The evaluation in [6] compares content-based router implementations using kernel- and application-level splice, demonstrating that kernel-level TCP Splice helps reduce CPU overheads for both short- and long-transfer connections. Extending these results, our research evaluates the impact of TCP Splice when exploited for serving Web requests passing through a proxy cache, considering different levels of proxy load, request types, and network conditions, and additional performance parameters, such as proxy response times and server TCP timeout activity.
Kernel-level TCP Splice implementations that can be exploited at application level have been proposed in [2, 14, 27]. The proposal in [14] is based on IP forwarding. Aiming to preserve the end-to-end semantics of the TCP model, this splicing model does not interfere with the flow of ACK packets sent by the two endpoints and require that the spliced TCP connections have similar characteristics. The proposal in [27] is based on TCP-level forwarding and can be optimized to work at IP level, like the proposal in [14]. Similar to [14], the splicer does not interfere with the ACK flows and require identical TCP connection characteristics.
Socket-level TCP Splice, the alternative kernel-level implementation that we propose for Web proxy severs, overcomes the most important limitations of existing IP-level implementations. By interfering with the ACK flows, socketlevel TCP Splice enables the splicing of connections with different characteristics. As illustrated by our experimental results, this feature reduces the number of retransmission timeouts and improves response times. Despite the additional TCP packet processing, socket-level TCP Splice enables reductions in CPU overhead comparable to those achievable with IP-level splicing.
Socket-level TCP Splice was previously used for an in-kernel, split-connection router for wireless networks to isolate the server transfers from the loss behavior of the wireless link [2]. The study does not evaluated the TCP Splice implementation with respect to the overhead reductions relative to application-level connection splicing.
Web proxies spend a substantial amount of CPU cycles transferring data between server and client connections. These overheads represent a significant share of per-request processing overheads, in particular when content is not cacheable or the proxy cache is memory-based. To reduce these overheads, this paper proposes and evaluates the use of a socket-level implementation of TCP Splice. Characterized by overhead savings comparable to those enabled by IP-level implementations, socket-level TCP Splice implementations can be exploited by Web proxy caches in serving a wider range of requests. For instance, a socket-level implementation enables transfers between connections with different sets of TCP features, and it can be naturally extended for handling pipelined requests and caching.
Our study is the first to evaluate the performance implications of using TCP Splice in a Web proxy serving regular HTTP, and HTTP over SSL traffic. Experiments conducted across emulated wide-area networks show that a socket-level implementation of TCP Splice reduces the proxy overheads associated with handling non-cacheable objects by 10-43% of the CPU, depending on object sizes and request rates. The relative reductions are larger for the overheads associated with SSL traffic. Socket-level TCP Splice can also lead to response time reductions ranging from tens of milliseconds to more than one second.
Our study addresses the interactions between requests served from the cache and requests spliced from the server. Our experiments reveal that the higher service priority that spliced traffic observes when kernel-level TCP Splice is used, can increase response times for requests served from the local cache.
We conclude that Web proxies should use socket-level implementations of TCP Splice, which can significantly benefit transfer rates for any combinations of client and server characteristics while introducing request-forwarding delays similar to other types of TCP Splice implementations. In the future, we plan to extend the basic TCP Splice interface evaluated in this paper to handle transfers for cacheable objects over HTTP/1.1 connections.
Authors would like to acknowledge the major contribution of Venkat Venkatsubra to the implementation of the socket- level TCP Splice in AIX 5.1. Authors thank Suresh Chari for his help in understanding SSL message patterns, and Khalil Amiri, Erich Nahum, and Anees Shaikh for their comments on earlier versions of this paper.
[1] H. Balakrishnan, S. Seshan, E. Amir, R. Katz, Improving TCP/IP Performance over Wireless Networks, ACM International Conference on Mobile Computing and Networking (Mobicom), 1995.
[2] H. Balakrishnan, V. Padmanabhan, S. Seshan, R. Katz, A Comparison of Mechanisms for Improving TCP Performance over Wireless Links, ACM SIGCOMM, 1996.
[3] G. Banga, P. Druschel, Measuring the capacity of a Web server under realistic loads, World Wide Web Journal, 2(1), May 1999.
[4] P. Cao, S. Irani, Cost-Aware WWW Proxy Caching Algorithms, USENIX Symposium on Internet Technologies and Systems, 1997.
[5] J. Chase, A. Gallatin, K. Yocum, End-System Optimizations for High-Speed TCP, IEEE Communications, 39(4), Apr. 2001.
[6] A. Cohen, S. Rangarajan, H. Slye, On the Performance of TCP Splicing for URL-aware Redirection, USENIX Symposium on Internet Technologies and Systems, 1999.
[7] A. Feldmann, R. Caceres, F. Douglis, G. Glass, M. Rabinovich, Performance of Web Proxy Caching in Heterogeneous Bandwidth Environments, IEEE INFOCOM, 1999.
[8] G. Hunt, G. Goldszmidt, R. King, R. Mukherjee, Network Dispatcher: A Connection Router for Scalable Internet Services, International World Wide Web Conference, 1998.
[9] A. Iyengar, J. Challenger, D. Dias, P. Dantzig, High-Performance Web Site Design Techniques, IEEE Internet Computing, 4(2) 2000.
[10] S. Jin, A. Bestavros, Popularity-Aware Greedy Dual-Size Web Proxy Caching Algorithm, International Conference on Distributed Computing Systems, 2000.
[11] J. Yin, L. Alvisi, M. Dahlin, A. Iyengar, Engineering server-driven consistency for large scale dynamic web services, International World Wide Web Conference, 2001.
[12] C. Liu, P. Cao, Maintaining Strong Consistency in the World Wide Web, International Conference on Distributed Computing Systems, 1997.
[13] D. Maltz, P. Bhagwat, MSOCKS: An Architecture for Transport Layer Mobility, INFOCOM, 1998.
[14] D. Maltz, P. Bhagwat, TCP Splicing for Application Layer Proxy Performance, IBM Research Report RC 21139, Mar. 1998.
[15] D. Maltz, P. Bhagwat, Improving HTTP Caching Proxy Performance with TCP Tap, IBM Research Report RC 21147, Mar. 1998.
[16] D. Menasce, V. Almeida, Scaling for e-Business, Prentice Hall, 2000.
[17] E. Markatos, M. Katevenis, D. Pnevmatikatos, M. Flouris, Secondary Storage Management for Web Proxies, USENIX Symposium on Internet Technologies and Systems (USITS), 1999.
[18] E. Nahum, M. Ro¸su, S. Seshan, J. Almeida, The Effects of Wide Area Conditions on WWW Server Performance, SIGMETRICS, 2001.
[19] National Institute of Standards and Technology, NIST Net Home Page, http://snad.ncsl.nist.gov/itg/nistnet.
[20] IBM Corporation, IBM Netfinity Web Server Accelerator V2.0, http://www.pc.ibm.com/ us/solutions/ netfinity/ server_accelerator.html.
[21] V. Pai, P. Druschel, W. Zwaenepoel, IO-Lite: A Unified I/O Buffering and Caching System, USENIX Symposium on Operating Systems Design and Implementation (OSDI), 1999.
[22] V. Paxon, End-to-end Internet packet dynamics, IEEE/ACM Transactions on Networking, 7(3), June 1999.
[23] Web Polygraph, Workloads, http://www.web-polygraph.org/docs/workloads.
[24] Web Polygraph, The Third Cache-Off, Oct. 2000, http://www.measurement-factory.com/results/ public/cacheoff/N03/.
[25] T.Dierks, C. Allen, The TLS Protocol, Version 1.0, IETF, Network Working Group, RFC 2246.
[26] D. Rubenstein, J. Kurose, D. Towsley, Detecting shared congestion of flows via end-to-end measurement, SIGMETRICS, 2000.
[27] O. Spatscheck, J. Hansen, J. Hartman, L. Peterson, Optimizing TCP Forwarder Performance, IEEE/ACM Transactions on Networking, 8(2), April 2000, also Dept. of CS, Univ. of Arizona, TR 98-01, Feb.1998.
[28] C. Wills, M. Mikhailov, H. Shang, N for the Price of 1: Bundling Web Objects for More Efficient Content Delivery, International World Wide Web Conference, 2001.
Notes:
1. ACK packets are sent by many BSD-based TCP
stacks, AIX included, either by the fast timer routine, as delayed ACKs,
or after two or more data segments are read from the receive buffer.
2. Minimum response times correspond to no loss transfers.