Ziv Bar-Yossef1 |
Sridhar Rajagopalan | |
University of California at Berkeley 387 Soda Hall Berkeley, CA 94720-1776, USA zivi@cs.berkeley.edu |
San Jose, CA 95120, USA sridhar@almaden.ibm.com |
Copyright is held by the author/owner(s).
WWW2002, May 7-11, 2002, Honolulu, Hawaii, USA.
ACM 1-58113-449-5/02/0005.
The creation of a link on the WWW represents the following type of judgment: the creator of page p by linking to page q has to some measure conferred authority on q.Brin and Page [3,23] in defining the PageRank ranking metric say that links express a similar motive:
The intuition behind PageRank is that it uses information external to the pages themselves - their backlinks, which provides a kind of peer review.
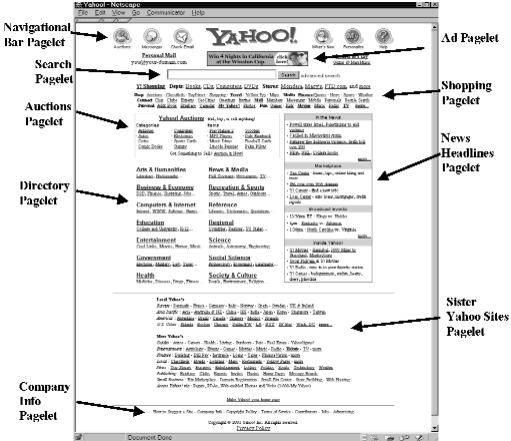
It affords an immediate step, however, to associative indexing, the basic idea of which is a provision whereby any item may be caused at will to select immediately and automatically another. This is the essential feature of the memex. The process of tying two items together is the important thing.An extension of the Lexical Affinity Principle is detailed in Chakrabarti's work [6]. In this work, he proposes that distance between entities within a document should be measured by considering document structure and not simply some linearization of it. For instance, the distances between all pairs of elements within an itemized list should be uniform.
|
Partition(p) {
Tp := HTML parse tree of p
Queue := root of Tp
while (Queue is not empty) {
v := top element in Queue
if (v has a child with at least k links)
push all the children of v to Queue
else
declare v as a pagelet
}
|
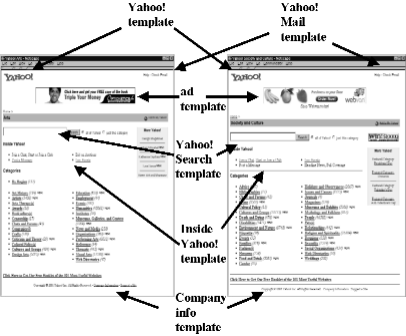
(1) Eliminate duplicate pages in G (2) Sort and group the pagelets in G according to their shingle. Each such group represents a template. (3) Enumerate the groups, and output the pagelets belonging to each group. |
(1) Select all the pagelet shingles in PAGELETS that have at least two occurrences. Call the resulting table TEMPLATE_SHINGLES. These are the shingles of the re-occurring pagelets. (2) Extract from PAGELETS only the pagelets whose shingle occurs in TEMPLATE_SHINGLES. Call the resulting table TEMPLATE_CANDIDATES. These are all the pagelets that have multiple occurrences in G. (3) For every shingle s that occurs in TEMPLATE_SHINGLES define Gs to be the shingle's group: all the pages that contain pagelets whose shingle is s. By joining TEMPLATE_CANDIDATES and LINKS find for every s all the links between pages in Gs. Call the resulting relation TEMPLATE_LINKS. (4) Enumerate the shingles s in TEMPLATE_SHINGLES. For each one, load into main memory all the links between pages in Gs. (5) Use a BFS algorithm to find all the undirected connected components in Gs. Each such component is either a template or a singleton. Output the component if it is not a singleton. |
| # | Title | URL |
| 27. | Sun Microsystems | www.sun.com |
| 29. | HTML Goodies Home Page | www.htmlgoodies.com |
| 30. | Linux Enterprise Ausgabe 11 2001 November | www.linuxenterprise.de/ |
| 31. | DevX Marketplace | marketplace.devx.com |
| 32. | Der Entwickler Ausgabe 6 2001 November Dezember | www.derentwickler.de/ |
| 33. | ITtoolbox Knowledge Management | knowledgemanagement.ittoolbox.com |
| 34. | EarthWeb com The IT Industry Portal | www.developer.com |
| 35. | entwickler com | www.entwickler.com |
| 36. | ITtoolbox EAI | eai.ittoolbox.com |
| 38. | www.xml-magazin.de/ | |
| 39. | DevX | www.devx.com |
| 41. | The Hot Meter | www.thehotmeter.com |
| 43. | HTML Clinic | www.htmlclinic.com |
| 45. | ITtoolbox Networking | networking.ittoolbox.com |
| 46. | FontFILE fonts... | www.fontfile.com |
| 47. | ITtoolbox Data Warehousing | datawarehouse.ittoolbox.com |
| 49. | ITtoolbox Portal for Oracle | oracle.ittoolbox.com |
| 50. | ITtoolbox Home | www.ittoolbox.com |
| Query | Fraction of Template Pages |
| affirmative action | 45% |
| alcoholism | 42% |
| amusement parks | 43% |
| architecture | 68% |
| bicycling | 49% |
| blues | 25% |
| cheese | 39% |
| citrus groves | 32% |
| classical guitar | 38% |
| computer vision | 32% |
| cruises | 46% |
| Death Valley | 51% |
| field hockey | 54% |
| gardening | 56% |
| graphic design | 28% |
| Gulf war | 40% |
| HIV | 43% |
| Java | 62% |
| Lipari | 53% |
| lyme disease | 32% |
| mutual funds | 67% |
| National parks | 33% |
| parallel architecture | 21% |
| Penelope Fitzgerald | 68% |
| recycling cans | 64% |
| rock climbing | 40% |
| San Francisco | 64% |
| Shakespeare | 39% |
| stamp collecting | 41% |
| sushi | 43% |
| table tennis | 44% |
| telecommuting | 39% |
| Thailand tourism | 37% |
| vintage cars | 22% |
| volcano | 48% |
| zen buddhism | 44% |
| Zener | 13% |
| Average | 43% |