Copyright is held by the author/owner(s).
WWW2002, May 7-11, 2002, Honolulu, Hawaii, USA.
ACM 1-58113-449-5/02/0005.
This paper describes the process of constructing a markup language for maritime information from the starting point of ontology building. Ontology construction from source materials in the maritime information domain is outlined. The structure of the markup language is described in terms of XML schemas and DTDs. A prototype application that uses the markup language is also described.
Categories and Subject Descriptors: I.7.2 [Document and Text Processing] Document preparation - Markup Languages; I.2.m [Artificial Intelligence]: Miscellaneous
General terms: Languages, Design
Keywords: Ontologies; XML; maritime information
Copyright and permissions
Copyright is held by the author/owner(s).
WWW2002, May 7-11, 2002, Honolulu, Hawaii, USA.
ACM 1-58113-449-5/02/0005.
The use of XML format for structured documents and data on the Web requires the development of XML-based domain markup languages, which in turn requires the development of an XML vocabulary for the domain. This paper describes an effort on creating a markup language for maritime information, and its use in a prototype retrieval system that answers queries relating to maritime navigation. This language is intended to be used for multiple purposes and applications within the domain of maritime information, ranging from database interoperability to information management. The paper focuses on the markup language aspects of this efforts, in particular, outlining a straw-man version of MIML (Maritime Information Markup Language). The development of this language is described here starting from first principles, that is, construction of an ontology for the domain, to the schemas and DTDs that capture the language. A prototype application is also described.
The next section provides context for the development of this language. It is followed by a description of the sources of language entities, then a description of the language design work, and by descriptions of applications.
Mariners use a wide variety of information collected from a number of sources, ranging from maps or charts to weather reports. Large quantities of information must thus be processed, especially for near-shore travel where shore effects (tides, currents, shore installations, etc.) must be considered. Further, any map or chart represents information only in context and for a specific purpose (e.g., physical and political maps of the same region). The context in which information is sought is therefore important for creating a responsive system. The most sophisticated ENC (Electronic Navigation Chart) systems and digital cartographic systems currently available still deal with only very basic geospatial information, for example, routes and waypoints, currents, and graphic overlays of one kind or another. They are capable of only relatively basic geographic information retrieval and analysis.
The long-term aim of this effort is to allow automated systems to use geospatial information better, so that it is possible for a navigational program to `understand', for example, that shorelines can be crossed by aircraft but not by surface vessels, that tidal tables are important for near shore navigation, that routes may need to stay away from restricted waters, that cutting across shipping lanes should be minimized, etc. The near-term aims are to enhance the exchange of maritime information between disparate databases, applications, and user communities, to simplify the management of the voluminous amount of data related to this domain, to lay a foundation for the next generation of data and information distribution, and to enable better location and retrieval of information from existing formats and distribution modes.
The first step is the construction of a computational ontology for the domain of interest. In artificial intelligence, an ontology is defined as a collection of terms and concepts that exist within a domain, definitions of those concepts, and descriptions of the relationships between the concepts. A computational ontology is an ontology that can be processed by software. Figure 1 shows part of the ontology for the maritime domain.
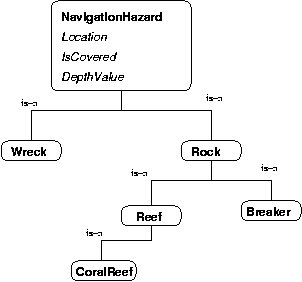
The sources used for ontological knowledge were selected from a canonical set, that is, they are documents accepted within the domain as normative and that are widely used. A deliberate effort was made to use standardized sources (i.e., official standards) wherever available, with the intention of facilitating conversion of legacy sources, easing the transition path from current data formats to XML, and enhancing the acceptability of MIML to domain experts and application developers.
Source selection was preceded by an informal analysis of documents currently in use within the domain; the aim of this analysis was to select sources that, in addition to being canonical and standardized (where possible), were either considered to be fundamental to the domain, important to the user population, or in common use (or some combination of these criteria). This analysis identified the following significant features of information processing and information transfer in this domain:
Given the features recognized in this analysis, the documents described in the rest of this section were identified as a starter set for the task of computational ontology construction and vocabulary definition. The use of these documents is described next.
The most recent normative standard for digital nautical chart content is the S-57 Standard for hydrographic data (the "S-57" standard) [10]. The `object catalog' section of this document consists of a list of chart entities, definitions, and entity attributes, which gives us a collection (sic) of domain entities that can be considered canonical as far as the scope of the standard goes. Extraction from this `object catalog' was automated by using graph traversal programs that exploit links between entities and attributes in the object catalog.
A second source was the Spatial Data Transfer Standard [5]. The parts we used were the sections that list `included terms' (analogous to a synonym list) and attribute definitions. Extraction from this was less satisfactory in some ways, since these sections are less rigorous than the object catalog of the S-57 standard, but, on the other hand, the synonym list covers more of the terms used in practice. Semantic structure is induced from this source from lexical clues and attribute sets comparison.
While the S-57 standard is normative, it suffers from several deficiencies as a source of ontological knowledge:
The primary database we have used so far is the sample Digital Nautical Chart (DNC) data files available from NIMA. It has somewhat more semantic structure than the aforementioned standards, consisting as it does of feature classifications organized by `layers', for example, environmental features, cultural features, land cover features, etc. (`Feature', as used in the domain, is equivalent to `class'). Induction of ontological knowledge from this consisted of mapping the structure to a class hierarchy. This conversion was also automated.
As with the S-57 standard, this database and schema covers only chart entities, and the terminology is even more restricted (and to some extent, more opaque) than the S-57 standard, due to the use of abbreviated names for entities and attributes, and the lack of textual definitions.
A separate effort used Protege [6] and a standard collection of symbology definitions from NOAA's Chart No. 1 [17] to create an ontology of navigation aids, hazards, and other entities. Chart No. 1 is a collection of symbology for nautical charts accompanied by brief definitions of what the symbol stands for. It is organized semantically (in that related symbols are in the same section or subsection). This was supplemented with a widely popular publication on navigation and seamanship "Chapman Piloting" [11] and an online dictionary of chart terms (discovered and used by the creator, a student unfamiliar with nautical terms). Ontology creation based on these documents consisted of manual entry of information using Protege, due to the lack of electronic versions of the symbology definitions.
The United States Coast Pilot is a 9-volume series containing information that is important to navigators of US coastal waters (including the Great Lakes) but which cannot be included in a nautical chart. Included are photographs, diagrams, and small maps. The flow of text follows the coastline geographically, e.g., from north to south. This is a `lightly structured' document, with each volume containing a preliminary chapter containing navigation regulations (which includes a compendium of rules and regulations, specifications of environmentally protected zones, restricted areas, etc.), followed by chapters dealing with successive sectors of the coast. Each chapter is further divided into sections (still in geographical order); each section is further divided into sub-sections and paragraphs describing special hazards, recognizable landmarks, facilities, etc. The internal structure of subsections and paragraphs provides taxonomical hints, indicating, for example, which leaf entities are categorizable as sub-classes of weather conditions, as well as providing a small amount of additional taxonomical information that extends taxonomies derived from other classes (e.g., tide races as a form of navigational hazard). The Coast Pilot is normative (in the sense of using well-understood terms) and comprehensive.
Extraction of ontological knowledge from this particular class of source material was done manually, i.e., entered by a human who deduced useful terms and concepts from the text. (Automatic extraction of ontological knowledge from documents is an active area of research in artificial intelligence, and this may be investigated in the future.) Other sources include the Ports list and Light list, for information on port facilities and navigation aids respectively.
One of the principles guiding the design of MIML is the provision of a clear transition path to the Semantic Web, when that idea attains a coherent form and implemented utilities and applications. Accordingly, MIML is founded on transition from computational ontologies to data types, entities, and attributes, based on the expectation that future reasoning tools will be easier to use if there is a well-defined and unambiguous relationship between computational ontologies and document entities. The transition turns out to be a two-way process - a small part of the sum of ontological knowledge was formalized through doing a sample markup of part of the Coast Pilot ab initio (without pre-determined elements, attributes, etc.). The bulk of the ontology design work to date, however, came from other sources (i.e., was generated prior to any markup). A second principle is that MIML should be capable of being used in different kinds of documents: marked-up text intended for browsers used by humans (Internet Explorer, Netscape, Opera, etc.); documents intended primarily for data transfer and extraction, such as port facility information; and database update notices intended for purely automatic processing, for example updates to nautical charts and the Light List.
The design of ontologies is described next, followed by a description of the transfer of ontological knowledge into language design.
Our strategy for constructing the computational ontology was as follows:
Ontology design was done using the Protege tool from the Stanford Medical informatics group. Figure 2 shows part of the ontology derived from the IHO S-57 standard object catalog. Shown is the "Wreck" class in that catalog.
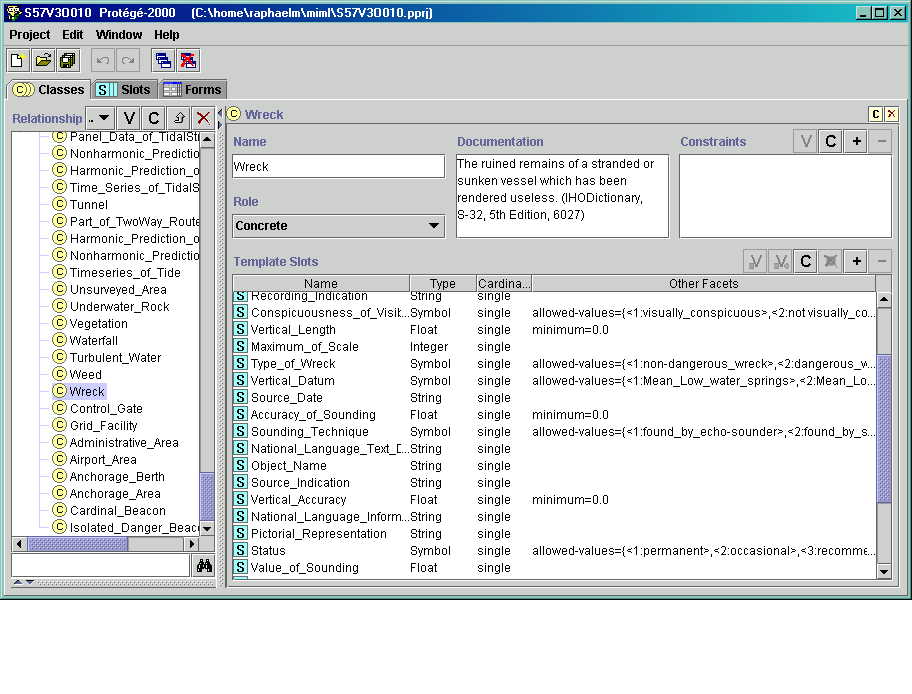
When the ontological knowledge has been compiled, the bulk of markup language definition work can begin. This is described next.
The transition from ontology to markup consisted of the following:
Unsurprisingly, very little relationship between the is-a hierarchy in the ontologies (class/subclass relationships) and the element containment relationships in the markup language exists. Part-whole relationships in the ontology do appear to be maintained across the mapping from ontology to markup but this preservation does not always exist, and is naturally uni-directional (i.e., containment in the markup language does not imply a part-whole relationship in the source ontology). This implies that information is being lost in the transition from ontology to markup and vice versa, meaning that both ontologies and markup will be needed for a proper understanding and processing of target documents.
The actual XML schema documents were generated from the Protege files using a Perl program; a plugin to generate them directly from the Protege user interface is under development.
The next section provides details about the elements so defined. It also proved necessary to define other elements for use in markup - these are also described in the next section.
The markup language definition is partitioned into different sub-languages, taking into account the source of the ontological knowledge, the use of markup, interdependencies, and expectations for change control. The existence of a specific source for a part of ontological knowledge usually indicates its use within sub-domains of the overall domain - for example, a weather ontology (or markup) will be used by forecasters, distributors of weather information, and consumers (mariners), but the digital charts community is not interested in weather insofar as the making of digital chart databases is concerned. Change control and updating of ontologies and markup will be simplified by limiting these responsibilities to the interested sub-communities.
In practice, this partitioning will be implemented using different namespaces (or another suitable partition mechanism). Figure 3 contains a conceptual overview of the partitioning of MIML into different schemas (or sub-languages).
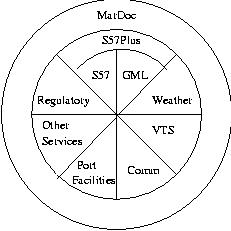
The diagram in Figure 3 shows the conceptual structure of MIML itself, with markup (sub)languages at the core consisting of:
The outer components in the figure are: a sub-language tentatively called S57Plus, intended to extend the S57 core with markup information that is generally required when S57 elements are discussed in texts, but which is not contained in the S57 standard; and a MarDoc component, intended for the markup of document structural elements that are not part of the domain itself, but which recur in target documents (for example, a "chart" element that could demarcate the part of a text document that contains information pertaining to a specific nautical chart).
Metadata in this domain is of two kinds: document metadata and information metadata. The first includes such information as document date, authority issuing it or other source, etc., while the second (information metadata) pertains to such items as date of recording (e.g., the date a depth measurement was made), the accuracy of the measurement, etc. Treatment of metadata is divided across different components at present; "MarDoc" component includes metadata about document issuing and source, while the S-57 component has its own provisions for metadata in the form of special attributes, etc. Layering in Figure 3 denotes "use relationships" - for example, elements defined in the "MarDoc" part are expected to use (contain) elements in all the other parts, but the S57 component is not expected to use elements or definitions from other parts. It should be noted that the scopes of the different components and the use relationships are not necessarily as well-demarcated as indicated in the figure. For example, the VTS component draws heavily on the "Comm" component for specifying communications channels.
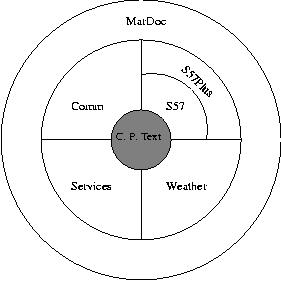
The diagram in Figure 4 illustrates the use of markup components with a specific target document or information resource (the shaded part at the center). Note that not all the components need be used to mark up any specific information resource.
The formal definition of the language is envisaged to be in terms of DTDs and schemas; the components of such a definition for our domain are described next.
As described in the earlier section, some elements were derived from the source ontologies constructed as described earlier. Attributes for objects designed for database use (for example, those defined in the S-57 object catalog) were used to define datatypes in the schemas. The primary purpose underlying this decision was controlling the ranges of allowed values for the attribute, with the intention of deriving types from these original types at some later date, which could be further constrained to better reflect actual ranges. For example, a `Color' type might take on any of a fairly large number of enumerated color names, but it might be useful to define a derived type for `running light color' derived from the original `Color' type and restrict its range to `red', `green', `yellow', and `white'. (Running lights are lights displayed by vessels so that others can detect their presence.) Where the "element or attribute" question arises, especially in the context of the entities defined in the S-57 object catalog, a deliberate decision was made to lean towards mapping ontology slots to attributes in the markup language instead of elements. This decision is not as obvious as it may appear at first glance, since there is a case for mapping the slots to sub-elements of a `container' element named afer the object (this appears to be the intuitive approach when considering the markup language as intended primarily for communication of database records). However, the schemas are intended for multiple uses, ranging from data transfer to marking up text documents, and it was felt that preferring attributes to (sub)elements would allow cleaner language design for later language development. Another issue, which we have not been able to resolve in an entirely satisfactory manner, is what should be made mandatory and what optional; this is discussed in more detail later.
Figures 5 and 6 show a sample of one such type and an element using an attribute of that type, derived from the S-57 ontology described earlier. The schema elements shown in the figure are concerned with describing the characteristics of lights (e.g., lighthouses) installed as navigation aids.
<xs:simpleType name="Nature_of_LightType">
<xs:annotation>
<xs:documentation>
Light characteristic
</xs:documentation>
</xs:annotation>
<xs:restriction base="xs:string">
<xs:enumeration value="fixed"/>
<xs:enumeration value="flashing"/>
<xs:enumeration value="long-flashing"/>
<xs:enumeration value="quick-flashing"/>
... other enumerations ...
<xs:enumeration value="alternating"/>
</xs:restriction>
</xs:simpleType>
Attribute use is specified as "optional" because the schema in its current form is intended to be used for marking up text as well as database-derived information. This is because in our target documents, some attributes may not be mentioned in the text, because only those attributes of special interest to a mariner are pointed out. On the other hand, it is not possible to know ahead of time exactly which attribute will be mentioned, because different attributes become noteworthy under different circumstances. This solution is not considered entirely satisfactory, because it leads to less rigorous constructs in derived entities, in the sense that optional attributes in a base type may need to be made compulsory in a derived type. An ideal solution would be a means of specifying (in one place) the optional/mandatory nature based on context.
<xs:element name="Lights">
<xs:complexType>
<xs:attribute name="Period_of_Signal"
type="Period_of_SignalType"
use="optional"/>
<xs:attribute name="Color"
type="ColorType"
use="optional"/>
<xs:attribute name="Nature_of_Light"
type="Nature_of_LightType"
use="optional"/>
<xs:attribute name="Visibility_of_light"
type="Visibility_of_lightType"
use="optional"/>
... other attributes ...
</xs:complexType>
</xs:element>
In passing, it may be noted that defining the elements just described amounts to creating ontologies for the specific areas (e.g., the "general document" elements constitute an ontology for a hypothetical "document" domain. The possibility of re-using existing schemas or markup languages for such elements will be explored later - at this time, we are concerned mainly with maritime and navigation markup.
A DTD has been prepared for the "shoreline" chapters of the Coast Pilot (leaving out the preliminary chapters in each volume concerning navigation regulations, etc.). Part of this is shown in Figure 7. A DTD for the Local Notice to Mariners has also been prepared, but is omitted here for reasons of brevity. A "Coast Pilot schema" was also constructed using the DTD as a starting point; the elements for Berth and Pier are shown in Figure 8. Incidentally, the elements in this figure were generated directly from the Coast Pilot, and show the differences between elements generated from entities originally defined with databases in mind (such as those in the IHO S-57 Object catalog) and those defined through examination of the documentary material; those defined from the first category generally have richer detail in the form of more attributes, but still sometimes lack associated information that is generally present when the object is actually referred. For example, the corresponding `Berths' element in the schema from the S-57 catalog lacks information (attributes) concerned with dimensions and cargo facilities. For most elements in the Coast Pilot schema, the type is "mixed", because the document currently consists of a sequence of paragraphs in English; each paragraph either expands on something in the corresponding nautical chart (e.g., adds a note about a specific navigation hazard), or contains condensed information from another document (e.g., about port facilities), or provides location-specific information (e.g., contact information for local authorities, reminders about local regulations, etc.). In other words, the Coast Pilot is basically a text document that repeats certain forms of expression in a restricted vocabulary of a natural language (English) for different parts of the coastline. It is not, at this time, intended for automated processing. We hope to move towards this goal via the DTDs and schemas described here, but meanwhile it is important to retain its human readability and use in near-term future intermediate forms.
<!DOCTYPE CoastPilot [
<!ELEMENT CoastPilot (Scope, GeneralDescription, GeneralMaterialOnChart+)>
<!ATTLIST CoastPilot Volume CDATA "" Chapter CDATA "" >
<!ELEMENT Scope (From, To )>
<!ELEMENT From EMPTY>
<!ELEMENT To EMPTY>
<!ATTLIST From Name CDATA "" Latitude CDATA "" Longitude CDATA "">
...
<!ELEMENT Pier (#PCDATA | Berth |Dimensions | Service )*>
<!ELEMENT Berth (#PCDATA | BerthNumber | Dimensions |
BerthFacilities | Service )*>
<!ELEMENT BerthNumber EMPTY>
<!ATTLIST BerthNumber No CDATA "">
<!ELEMENT Dimensions (#PCDATA)>
<!ELEMENT BerthFacilities (#PCDATA)>
...
<!ELEMENT Wharves (#PCDATA | Xlink | PierArea )*>
<!ELEMENT PierArea (#PCDATA | Pier )*>
...
<xs:element name="Pier">
<xs:complexType mixed="true">
<xs:choice minOccurs="0"
maxOccurs="unbounded">
<xs:element ref="Berth"/>
<xs:element ref="Dimensions"/>
<xs:element ref="Service" />
</xs:choice>
<xs:attribute name="Name" type="xs:string"
default=""/>
</xs:complexType>
</xs:element>
...
<xs:element name="Berth">
<xs:complexType mixed="true">
<xs:choice minOccurs="0"
maxOccurs="unbounded">
<xs:element ref="BerthNumber"/>
<xs:element ref="Dimensions"/>
<xs:element ref="BerthFacilities"/>
<xs:element ref="Service"/>
</xs:choice>
<xs:attribute name="Type" type="xs:string"
default=""/>
<xs:attribute name="Name" type="xs:string"
default=""/>
</xs:complexType>
</xs:element>
The schematic in Figure 9 shows a demonstration application developed using the computational ontology and the markup language, intended for maritime passage planning. Passage planning involves not just plotting a safe route, but also includes generating a report about hazards that may be encountered, facilities available along the route and at the destination, weather and tide conditions that may encountered during the voyage, etc. A `passage plan' is, for the purposes of this project, an answer to the questions: "How do I get from X to Y? What will I encounter on the way, and what will I find when I get there? What do I need to know for this particular journey"? The demonstration application in its current stage of development does not deal with the route-planning problem ("how do I get from X to Y"), because similar issues have long been addressed in path planning research within artificial intelligence, and the computational magnitude of this particular problem prevented anything more than a superficial solution with available resources. It does attempt to deal with the other components of what we call the `passage planning question'. Note that the passage plan depends on the context of the question, especially type of vessel and the purpose of the journey, since information that may be of interest to a freighter may be irrelevant to a small pleasure craft.
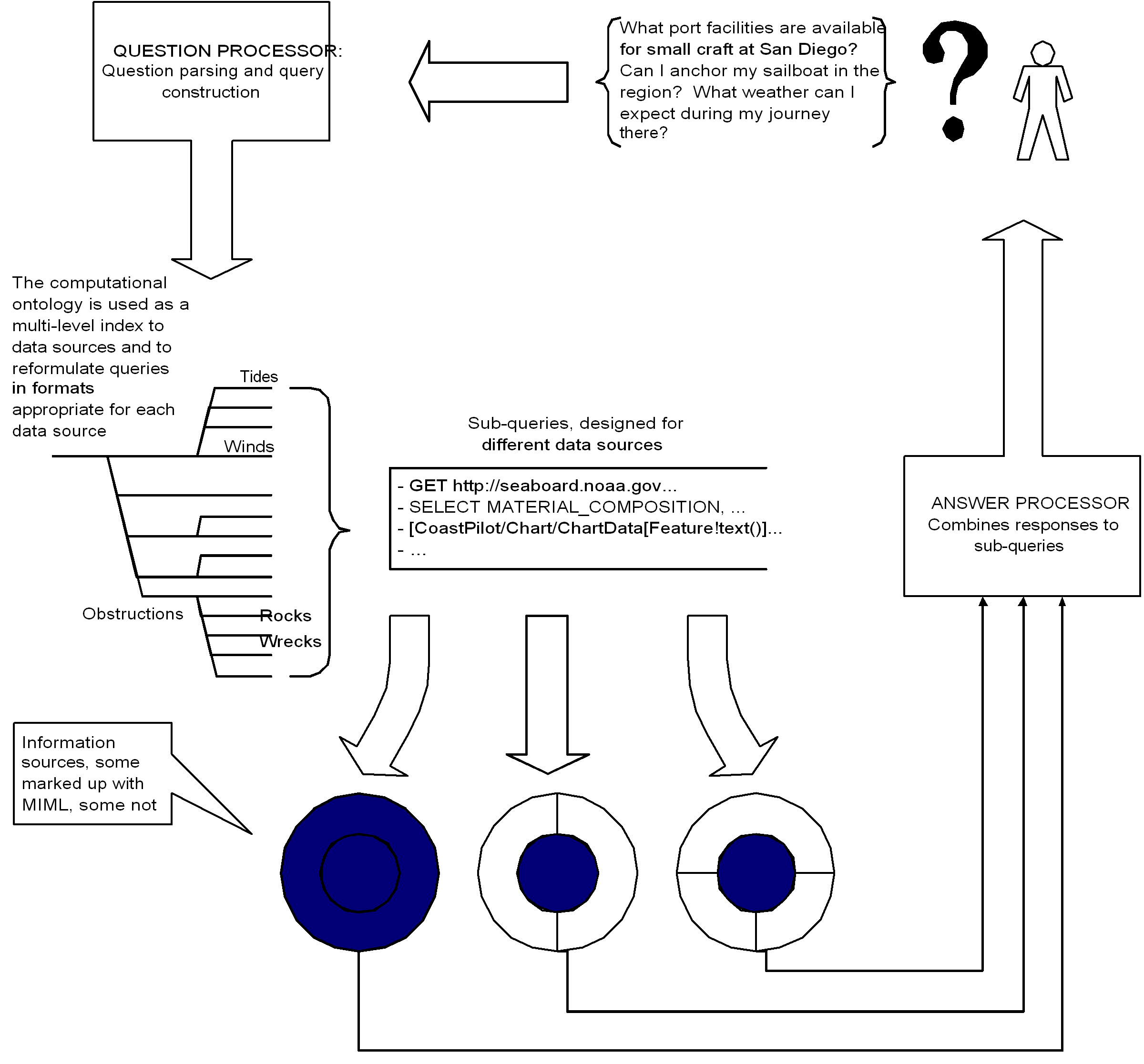
Figure 9 shows a question entered by the user in (semi) natural language being transformed to use standard terms by a black-box language processor. A multi-level index derived from computational ontologies for the domain is used to re-cast the question into knowledge-source specific formats which are dispatched to the appropriate information sources (the filled circles). The information sources may be wrapped in one or more markup languages (the unshaded arcs) or unshielded (not use any markup at all) as in the leftmost circle in the figure.
The content sources for passage planning are: Web sites with real time information, the Coast Pilot, nautical chart feature databases, and programs that generate information as and when required. More information about these sources is available elsewhere [13] and will not be repeated here.
The prototype is able to answer questions using a limited vocabulary and syntax. Questions can be asked in ways that are close to natural language (e.g., "can I anchor off San Diego"). The primary interface with the user consists of a form to be filled out with information about the journey, including the location (either source-destination or a single point), type of vessel (cargo, sail, etc.), time of journey, and, optionally, specific questions about such items as anchorages, local facilities, depths, etc. The Web backend transforms the form into a collection of queries based on the nature of the source from which the information must be collected. The answers are combined into a `passage plan' or mini `portolan chart' customized for the specific voyage.
Information about the capabilities of the information retrieval prototype is available elsewhere [13,14] and will not be repeated here, since much of it is only peripherally related to markup languages. The prototype is currently intermittently available on the project Web site (via a link on the page http://www.eas.asu.edu/~gcss/research/navigation/).
As far as the use of markup languages (i.e., MIML) goes, MIML is used to implement text extraction and condensation capabilities in the prototype. This capability allows for relevant elements from the Coast Pilot (which is marked up with MIML tags derived from the ontology constructed earlier) to be extracted for the `passage book' generated in response to a user query. Relevance is judged based on proximity to the location(s) specified (and the route between source and destination), the type of vessel and purpose of the voyage, and in response to the optional question mentioned earlier. MIML is currently being used in the prototype site to markup a target document (Chapter 4 of Volume 7 of the Coast Pilot) for subsequent query (using an implementation of XML Query) and information extraction. Some sample markup of this document is shown in Figure 10.
<Chart>
<ChartNumber>18773</ChartNumber><ChartNumber>18772</ChartNumber>
...
<Pilotage>All foreign vessels and vessels from a foreign port ... </Pilotage>
...
<Wharves>
The San Diego Unified Port District owns the deepwater commercial facilities in the bay...
<PierArea>
<Pier name ="B Street Pier, Cruise Ship Terminal">
(32 deg. 43'02"N., 117 deg. 10'28"W.): 400-foot face, 37 to 35 feet alongside;
1,000-foot N and S sides, 37 to 35 feet alongside;...
</Pier>
<Pier name ="Broadway Pier, S of B Street Pier">
135-foot face, 35 feet alongside; 1,000-foot N and S sides, 35 feet...
</Pier> ...
<Pier name ="Tenth Avenue Marine Terminal">
<Berth name="Berths 1 and 2">
Concrete bulkhead, 1,170 feet of berthing space; 27 feet alongside...
</Berth>
<Berth name="Berths 3 and 6"> ... </Berth>
<Berth name="Berths 7 and 8"> ... </Berth>
</Pier>
<PierArea>
</Wharves>
...
</Chart>
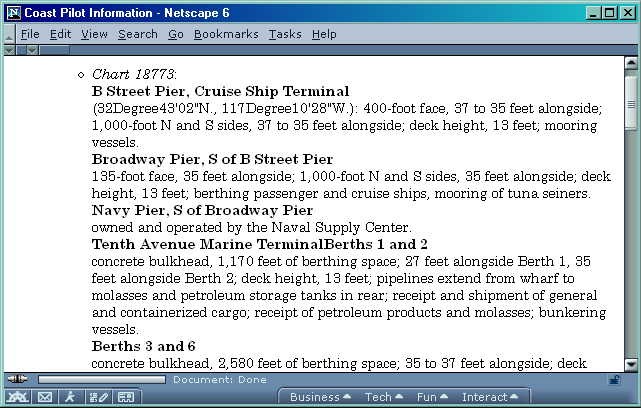
Figure 11 shows information retrieved during a sample session concerned with planning a trip in the vicinity of San Diego. Shown are extracts from the Coast Pilot concerning cargo facilities at San Diego.
Other applications envisaged for the future include federated database work, especially on reconciling different definitions and forms for similar data in different databases (e.g., the so-called Lights List and digital nautical chart databases), and information distribution for waterways.
The work most closely related to that described here appears to be that of Erdmann and Studer [3], which describes derivation of DTDs from ontologies by mapping concepts and attributes to XML elements. A tool that does this mapping (DTDmaker) is described. In purpose and function, it appears to be similar to the techniques used by us to produce XML schemas from our ontologies, except that we produce schemas instead of DTDs. Erdmann and Studer claim that both DTDs and ontologies are needed for document understanding and processing, reinforcing the observation in this paper that there is information in each that is not reproduced in the other. Hunter [9] describes a similar standard-based approach to ontology and markup definition, for MPEG-7. Mitra, Wiederhold, and Decker [16] describe the integration of heterogeneous information sources based on conversion of disparate conceptual models to a single conceptual model, similar in intent to what is being done in the prototype retrieval application described here, but apparently different in the emphasis on the reconciliation of conceptual models for interoperability. Euzenat [4] describes a formal approach to similar problems.
The primary reason for selecting XML for markup language definition, in preference to RDF or DAML+OIL is the maturity of XML technology compared to these and other languages. On the other hand, RDF and RDFS [20,21] are even more closely tied to ontologies and knowledge representation than XML, and DAML+OIL [7] is designed as an extension to XML and RDF, and is being tailored for semantic descriptions and semantic processing. Future work is expected to move to semantically richer alternatives than XML (which could be RDF/RDFS, DAML+OIL, or possibly an as-yet-unknown third alternative) for future versions.
MIML is still under development. What is described in this case study must be regarded as `first steps' in development. The most important pending issue is standardization. Imminent efforts to standardize the ontology (or ontologies) and markup language - that is, remove the straw-man status of MIML - are anticipated in conjunction with the US Coast Guard, NOAA, and other interested parties.
Work is in progress on creating markup tools for semi-automated markup of source texts with MIML. The core idea here is to exploit the inherent structure in source texts of the kind we are dealing with in the maritime information domain to recognize word patterns and other lexical and structural clues to suggest markup. Work on the other applications mentioned in the previous section will also be taken up, and efforts on enhancing the capabilities of the demonstration prototype continue. Another direction of research is concerned with combining MIML documents in accordance with semantic criteria, for example, to place weather-related information from different source MIML documents together in an output MIML document. Such combination techniques will be enhancements to current XML merging tools in that they will rely on semantic clues (for example, concept relatedness in a base ontology) for document merging, instead of lexical comparison of tags or structural comparison of elements. We feel that our insistence on well-defined relationships between basic principles of knowledge representation (ontologies) and the markup languages facilitates the development of such tools. Conversion/translation to widely accepted markup forms other than XML (e.g., DAML+OIL, RDF) is envisaged for the future. The project was originally envisaged as a Semantic Web project, and longer-term plans include addition of inferencing capabilities and this may also require extension or replacement of the current XML-schema and DTD markup with DAML+OIL, RDF, or another markup/annotation scheme.
This paper has focused on the process of markup language definition for the maritime information domain and upon and the structure of the markup language thus defined. A prototype application demonstrating the use of the language was also described. Based on the experience gained during the project here, some guidelines for vocabulary/language development are proposed below.
First, vocabulary development should commence with an analysis of current and expected information transfer and processing within the domain. This stage should be used to identify source documents that can be further analyzed for modeling concepts and relations in the domain. In addition to source documents that can be directly mined for vocabulary, it is necessary to identify a `canonical' set of documents in use for communication, updates, and other major information processing tasks in the domain. Human domain experts should be consulted for this analysis, but if the appropriate documentary samples and database designs can be identified, it is not necessary, and may even be limiting and expensive (from the point of view of resources, accuracy, and time) to use the domain experts directly for vocabulary definition instead of in a consultative role. (Engineering, medicine, and other domains where pre-Web standardization committees have been working, may be best suited for such an approach.)
Markup language vocabulary can be generated in two ways: first, the obvious relationships already inherent in database schemas, object catalogs, and similar collections; and second, through direct markup of carefully selected samples from the `canonical documents' identified in the analysis stage. The domain modeling knowledge induced from both categories of sources should be expressed as formal ontologies, in the interest of correctness and completeness. An ontological engineering tool such as Protege should be used to detect and resolve overlaps, inconsistencies, etc. Tools to convert from the specific database schemas, etc., to the format used by the ontology tools can easily be written, and tools to extract ontological knowledge from marked-up documents or DTDs are already available (e.g., Protege itself and the dtd2xs tool). Note that human verification of the ontologies thus generated will be needed, though tools to resolve problems with ontologies are available. It is not necessary to combine all the domain knowledge into a single ontology; on the other hand, it might be better to partition the domain knowledge and ontologies according to sub-communities of use, or of data generation, etc.
Once ontologies have been created, they can easily be converted to markup elements, distributed over different namespaces according to the ontology partitions mentioned in the previous paragraph. Some design decisions will be required at this stage (for example, on the attribute/element question). Whatever the design decisions made here, it is essential to maintain a rigorous and well-defined relationship between ontology components (classes, slots, ranges, etc.) and language constructs (types, elements, attributes, restrictions, etc.) and component structure.
Language design should be domain-centered, since it is likely that the resultant language will be used for different categories of applications (database updates, markup of large text documents, short messages, etc.). Domain-centric (or data-centric) design will also make it easier to develop future tools for intelligent processing.
Returning to other conclusions, our experiences during this work confirm that ontology building may be a good starting point for language definition when source standards in the domain are readily available, because of the resultant acceptability to domain experts. Where controversies about ontologies exist (for example in biological taxonomy), this may not be as useful. Further, it is not possible to capture all the information contained in ontologies in an XML schema or DTD (particularly that about relationships between concepts), nor does a one-to-one mapping exist between an ontology (or set of ontologies) and the elements required to represent a real-life domain. Semantic web developments such as DAML and a newer generation of RDF/RDFS may help, but a certain amount of back-filling or reverse ontologization - that is, defining concepts, particularly those related to document structure, in the light of experience gained from actual markup of target documents will still be required.
This work was partially supported by the National Science Foundation under grant EIA-9983267, and in part by the U.S. Coast Guard. The contributions of Jay Spalding, Kathy Shea, Oren Stembel, Leo Leong, and Helen Wu are gratefully acknowledged. Figures 4, 9, and 11 and some of the attendant material first appeared in [14], presented at the ION NTM (Jan. 2002) in San Diego, California. Figures 1, 7 and 10 first appeared in a paper presented at the the 2001 Digital Government Conference [13].
[1] H. Chalupsky. Ontomorph: a translation system for symbolic knowledge. In A. Cohn, F. Giunchiglia, and B. Selman, editors, Principles of Knowledge Representation and Reasoning: Proceedings of the Seventh International Conference (KR2000), San Francisco, CA. Morgan Kaufman, 2000.
[2] H. Chalupsky, E. Hovy, and T. Russ. Progress on an automatic ontology alignment methodology, 1997. ksl-web.stanford.edu/onto-std/hovy/index.htm.
[3] M. Erdmann and R. Studer. Ontologies as conceptual models for xml documents. In Proceedings of the 12th Workshop on Knowledge Acquisition, Modeling, and Management, 1999. At sern.ucalgary.ca/KSI/KAW/KAW99/papers.html.
[4] J. Euzenat. An infrastructure for formally ensuring interoperability in a heterogenous semantic web. In Proceedings of the First Semantic Web Working Symposium, Palo Alto, pages 345--360, 2001.
[5] FGDC. Spatial data transfer standard. Federal Geographic Data Committee, U. S. Geological Survey. Proposed standard, 1998.
[6] W. E. Grosso, H. Eriksson, R. W. Fergerson, J. H. Gennari, S. W. Tu, and M. A. Musen. Knowledge modeling at the millennium (the design and evolution of Protege-2000). Technical report, Stanford University, Institute for Medical informatics, Stanford, CA, 1999. Technical Report SMI-1999-0801.
[7] I. Horrocks, F. van Harmelen, P. Patel-Schneider, T. Berners-Lee, D. Brickley, D. Connolly, M. Dean, S. Decker, D. Fensel, P. Hayes, J. Heflin, J. Hendler, O. Lassila, D. McGuinness, and L. A. Stein. DAML+OIL, March 2001. www.daml.org/2001/03/daml+oil-index.html.
[8] E. Hovy. Combining and standardizing large-scale, practical ontologies for machine translation and other uses. In Proceedings of the 1st International Conference on Language Resources and Evaluation (LREC). Granada, Spain, 1998.
[9] J. Hunter. Adding multimedia to the Semantic Web - building an MPEG-7 ontology. In Proceedings of the First Semantic Web Working Symposium, Palo Alto, pages 261--284, 2001.
[10] International Hydrographic Organization. IHO transfer standards for digital hydrographic data, edition 3.0, 1996.
[11] E. S. Maloney. Chapman Piloting: Seamanship and Boat Handling. Hearst Marine Books, New York, 63rd edition, 1999.
[12] R. M. Malyankar. Acquisition of ontological knowledge from canonical documents. In IJCAI-2001 Workshop on Ontology Learning. IJCAI-2001, Seattle, WA, 2001.
[13] R. M. Malyankar. Maritime information markup and use in passage planning. In Proceedings of the National Conference on Digital Government, pages 25--32, Marina del Rey, California, 2001. USC/ISI Digital Government Research Center.
[14] R. M. Malyankar. Elements of semantic web infrastructure for maritime information. In Proceedings of the 2002 National Technical Meeting, San Diego, Institute of Navigation, Alexandria, VA, 2002. Institute of Navigation. To appear.
[15] D. McGuiness, R. Fikes, J. Rice, and S. Wilder. An environment for merging and testing large ontologies. In Proceedings of the Seventh International Conference on Principles of Knowledge Representation and Reasoning (KR2000), Breckenridge, Colorado, April 2000. Tech. report KSL-00-16, Knowledge Systems Laboratory, Stanford University.
[16] P. Mitra, G. Wiederhold, and S. Decker. A scalable framework for the interoperation of information sources. In Proceedings of the First Semantic Web Working Symposium, Palo Alto, pages 317--329, 2001.
[17] National Oceanic and Atmospheric Administration. Chart no. 1: Nautical chart symbols, abbreviations, and terms, 1997.
[18] N. F. Noy and M. Musen. SMART: Automated support for ontology merging and alignment. In Twelth Workshop on Knowledge Acquisition, Modeling, and Management, Banff, Canada, 1999.
[19] N. F. Noy and M. A. Musen. PROMPT: Algorithm and tool for automated ontology merging and alignment. Technical report, Stanford University, Institute for Medical informatics, Stanford, CA, 2000. Technical Report SMI-2000-0831.
[20] W3C (World Wide Web Consortium). Resource Description Framework (RDF) model and syntax specification: W3C recommendation 22 February 1999, 1999. http://www.w3.org/TR/REC-rdf-syntax/.
[21] W3C (World Wide Web Consortium). Resource Description Framework (RDF) schema specification: W3C candidate recommendation 27 March 2000, 2000. http://www.w3.org/TR/WD-rdf-schema/.