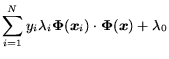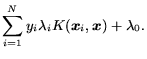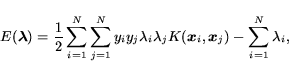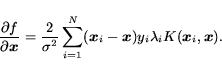Gary W. Flake![]() , Eric J. Glover
, Eric J. Glover![]() ,Steve Lawrence
,Steve Lawrence![]() , C. Lee Giles
, C. Lee Giles![]() ,
,
![]() flake,compuman,lawrence
flake,compuman,lawrence![]() @research.nj.nec.com
@research.nj.nec.com![]()
![]() giles
giles![]() @ist.psu.edu
@ist.psu.edu![]()
| NEC Research Institute |
School of Information Sciences and Technology |
|
| 4 Independence Way | The Pennsylvania State University | |
| Princeton, NJ 08540 | 001 Thomas Bldg | |
| University Park, PA, 16802 |
Copyright is held by the author/owner(s).
WWW2002, May 7-11, 2002, Honolulu, Hawaii, USA.
ACM 1-58113-449-5/02/0005.
H.3.3 [Information Storage and Retrieval]:Information Search and Retrieval - query formulation ; I.5.1 [Pattern RecognitionModels]: statistical
Algorithms, Experimentation
query modification, rule extraction, support vector machine, sensitivity analysis
When searching the WWW, users often desire results from a specific category, such as personal home pages or conference announcements. Unfortunately, many search engines return results from multiple categories, thus forcing the user to manually filter the results. One solution is to use an automated classifier that identifies whether a given result is close to the user's desired category. However, since search engines often have low precision for a given category, it may be necessary to retrieve a large number of documents from the engines, which may be expensive or impossible (search engines typically only allow retrieving a certain maximum number of hits for a query). A single query modification (such as +"home page") can improve precision, but often at the expense of recall. To allow for both high precision and high recall, we introduce a method to generate a collection of query modifications that satisfies the user's desired precision and attempts to maximize recall.
We use a nonlinear support vector machine (SVM) to initially classify all documents. The problem of building classifiers that generalize-well is especially important in the domain of text classification because typical problem instances have high-dimensional input spaces (mapping to a word vector) with a relatively small number of positive examples. The scarcity of positive examples is related to the cost of having humans hand-classify examples. SVMs are specifically designed to generalize-well in high-dimensional spaces with few examples. Moreover, they have been shown to be extremely accurate and robust on text classification problems [8,9], which is why we use SVMs in favor of other classification methods.
We also know of no other work that extracts symbolic information from SVMs; hence, we are also motivated by the desire to use the high accuracy of SVMs to extract valuable symbolic features, similar to earlier works that did the same for multilayer perceptrons [14].
Our feature extraction process uses sensitivity analysis on the underlying SVM to identify a linear model and a single query modification that explains a subset of the desired documents. We extract additional query modifications by iterating the procedure with a new dataset composed of the false negatives of the linear model and all negative examples. The procedure repeats, generating additional query modifications, until no further progress is made. In this way, our feature extraction method is similar to RIPPER [1] in that we iteratively extract rules; however, our method differs in that we use the SVM to guide our choice in rule selection.
In the end, we can identify a set of query modifications whose combination ``covers'' a large portion of the positive documents, but greatly reduces the number of false positives. Our method yields precise search results and can be built on top of existing search engines in the form of a metasearch engine. Moreover, by using SVMs to guide the rule search, our extracted rules are predisposed to have many of the same generalization qualities that the originating SVM possesses.
This approach differs from our other work on learning query modifications [6] by producing a set of query modiifications that work together to improve recall, as opposed to a set of individually effective modifications, that may or may not work well together.
This paper is divided into five sections. In Section 2, we discuss WWW search engines and metasearch engines, with an emphasis on how our results can be used to improve metasearch engines. In Section 3, we describe our method for producing effective query modifications, which uses text preprocessing, SVM classification, sensitivity analysis, and a dataset deflation procedure. Section 4 gives experimental results for identifying personal home pages and conference pages and shows that our method gives both high precision and improved recall. Finally, Section 5 summarizes our work with a discussion on how web page patterns are exploited by our method's dimensionality reduction properties.
The primary tool for accessing data on the Web is a search engine such as AltaVista, Northern Light, Google, Excite, and others. All search engines accept keyword queries and return a list of relevance ranked results, where relevance is usually a topical measure. As every search engine user has experienced, typical search queries often return thousands of URLs, placing a burden on the user to manually filter the results.
One common trick for combating this problem is to ``spike'' a search query with a modification that is designed to narrow the results to a specific context or category. For example, if searching for the personal home pages of machine learning researchers, adding the term "home page" can increase the density of valuable results by encouraging a search engine to rank personal home pages higher than non-home pages. However, using any single query modification increases the search precision at the expense of recall, i.e., many home pages (e.g., those that do not contain ``home page'') may be missed.
The coverage of a search query can be improved by using a metasearch engine, such as DogPile, SavvySearch [7], MetaCrawler [13], or Profusion [3]. Each submits the user's query to multiple search engines and fuses the results, allowing for potentially higher recall. Most simple metasearch engines fuse results by considering only the titles, URLs and short summaries returned from the underlying search engines. As a result, it is more difficult for them to assess topical relevance or to determine if a particular result is of the type desired by the user. In addition, since metasearch engines combine many search engine results, there is a risk of one search engine causing the total precision to drop.
Unlike typical metasearch engines, content-based metasearch engines, such as Inquirus [10], download all possible results and consider the full HTML of each page when ranking them. Although this strategy may improve the accuracy of relevance ranking, it does not allow users to control the desired category of results and, at best, only organizes existing results. Just as with any metasearch engine, Inquirus can have low precision if the underlying search engines also have low precision. As a result, the improved coverage does not guarantee improved recall.
Some search and metasearch engines, such as Northern Light and SavvySearch, allow users to specify a desired category from a limited set of categories. Northern Light constrains user searches to results known to fall into the chosen cluster, while SavvySearch only submits the query to search engines known to be of the desired category, such as MP3 or news sites. Each approach offers the user improved control, but both are still limited.
A problem arises when a user's desired document category does not exactly match the provided choices, or the user wishes to submit his query to a general purpose search engine (to improve recall). There is no way to provide custom categories to these search tools, neither of which have a category for ``personal home pages'' or ``conference pages.'' Nevertheless, users often desire documents in a well-defined category that is not easily localized like those covered by specialized metasearch engines.
Our work is motivated by the desire to build a metasearch engine that can adaptively specialize to many different document categories. Our prototype system, Inquirus 2 [5,4], currently allows users to focus a search on categories such as ``personal home pages,'' ``research papers,'' and ``product reviews.'' Previous versions of Inquirus 2 used hand-coded query modifications to improve the search performed by the search engines. This work gives a method by which effective query modifications that have both high precision and high recall can be generated automatically.
Our method for automatically identifying effective query
modifications is a five-step process that uses labeled examples.
The first stage is to preprocess the textual content of an HTML
document into ![]() -gram features
that appear to have discriminatory power. With the document
features and labels, we then train a nonlinear SVM to classify the
documents. Sensitivity analysis on the SVM is used to estimate the
importance of document features to the SVM classifier. The most
important features are exhaustively analyzed to find the
combination of query modifications that yields the highest recall
for a desired level of precision.
-gram features
that appear to have discriminatory power. With the document
features and labels, we then train a nonlinear SVM to classify the
documents. Sensitivity analysis on the SVM is used to estimate the
importance of document features to the SVM classifier. The most
important features are exhaustively analyzed to find the
combination of query modifications that yields the highest recall
for a desired level of precision.
Documents that are labeled as true positives by the best query modification are removed from the dataset. The process then repeats with a new SVM classifier until no new query modifications are found. The entire method is described in greater detail in the next four subsections.
Our preprocessing extracts the full text and title text of a document and converts it into features that consist of up to three consecutive words. All non-letter characters are converted to whitespace and all capital letters are converted to lower case.
After every page in the training set is converted, two feature histograms are constructed for positive and negative exemplars. Since the number of features per document can be on the order of thousands, we reduce the number of features by eliminating those features that are too rare (such as proper names). Common features, such as stop words, are removed by the feature scoring process as well. However, since we distinguish between title text and the full document text, a particular stop word such as ``s'' in the title (from apostrophe ``s''), could be a strong feature, even though it is common in the text.
This dimensionality reduction considers the relative ability of any given feature to distinguish between positive and negative exemplars by assigning a score to each feature. The score is generated via the following four sets:
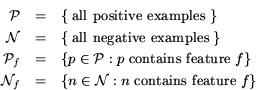
Ignoring higher order correlations, the best features for
classifying are those which occur only in one set and the worst
features are those which occur in an equal percentage of each set,
or occur very frequently in both sets. A simple scoring function,
![]() , that captures this
notion is:
, that captures this
notion is:
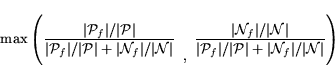
After each feature is scored the top ![]() are taken. For our experiments we used
are taken. For our experiments we used ![]() equal to 100 for the personal
home pages, and 300 for conference pages. After the top
equal to 100 for the personal
home pages, and 300 for conference pages. After the top ![]() features are determined, each
page is converted to a binary vector, where each feature is
assigned
features are determined, each
page is converted to a binary vector, where each feature is
assigned ![]() , with
, with
![]() indicating that a
feature is absent.
indicating that a
feature is absent.
Consider a set of data,
![]() , such that
, such that
![]() is an
input and
is an
input and
![]() is a
target output. A support vector machine is a model that is
calculated as a weighted sum of kernel function outputs. The kernel
function of an SVM is written as
is a
target output. A support vector machine is a model that is
calculated as a weighted sum of kernel function outputs. The kernel
function of an SVM is written as
![]() and it can be an inner product, Gaussian, polynomial, or
any other function that obeys Mercer's condition [15].
and it can be an inner product, Gaussian, polynomial, or
any other function that obeys Mercer's condition [15].
In the simplest case, where
![]() and the training data is linearly separable, computing an
SVM for the data corresponds to minimizing
and the training data is linearly separable, computing an
SVM for the data corresponds to minimizing
![]() such that
such that
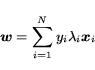
The formalism behind SVMs has been generalized to accommodate
nonlinear kernel functions and slack variables for
miss-classifications. We write the output of a nonlinear SVM
as:
Equation 2 will always
have a single minimum with respect to the Lagrange multipliers,
![]() .
The minimum to Equation 2
can be found with any of a family of algorithms, all of which are
based on constrained quadratic programming. We used a faster
variation [2] of the
Sequential Minimal Optimization algorithm [11,12]
in all of our experiments.
.
The minimum to Equation 2
can be found with any of a family of algorithms, all of which are
based on constrained quadratic programming. We used a faster
variation [2] of the
Sequential Minimal Optimization algorithm [11,12]
in all of our experiments.
When Equation 2 is
minimal, Equation 1 will
have a classification margin that is maximized for the training
set. For the case of a linear kernel function (
![]() ), an SVM finds a decision boundary that is balanced between
the class boundaries of the two classes. In the nonlinear case, the
margin of the classifier is maximized in the nonlinear feature
space, which results in a nonlinear classification boundary.
), an SVM finds a decision boundary that is balanced between
the class boundaries of the two classes. In the nonlinear case, the
margin of the classifier is maximized in the nonlinear feature
space, which results in a nonlinear classification boundary.
In our experiments we used a Gaussian kernel function of the
form
After training a nonlinear SVM to classify our labeled training
data, we use a form of sensitivity analysis to identify components
of the document feature space that are important to the classifier.
Suppose that our classifier is linear in the input space, i.e.,
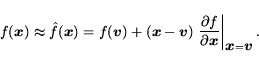
|
|
But what value should
![]() take?
An interesting aspect of SVM learning is that the non-zero Lagrange
multipliers correspond to data points that are crucial to
determining the maximum margin classifier. Any data point with a
zero Lagrange multiplier is redundant in the sense that its removal
would not alter the solution. All other data points, with Lagrange
multipliers at the solution taking non-zero values, are the
so-called ``support vectors'' which are the only data points
strictly needed in order to build the SVM model. For many
real-world problems (text classification among them), the number of
support vectors may be dramatically fewer than the number of data
points. Thus, our search for useful values of
take?
An interesting aspect of SVM learning is that the non-zero Lagrange
multipliers correspond to data points that are crucial to
determining the maximum margin classifier. Any data point with a
zero Lagrange multiplier is redundant in the sense that its removal
would not alter the solution. All other data points, with Lagrange
multipliers at the solution taking non-zero values, are the
so-called ``support vectors'' which are the only data points
strictly needed in order to build the SVM model. For many
real-world problems (text classification among them), the number of
support vectors may be dramatically fewer than the number of data
points. Thus, our search for useful values of
![]() can be
simplified by only searching those points in the input space that
are also support vectors (i.e., have non-zero Lagrange
multipliers). Moreover, since we are more interested in discovering
rules that identify positive members of the document category, we
restrict our attention to those positive support vectors that have
can be
simplified by only searching those points in the input space that
are also support vectors (i.e., have non-zero Lagrange
multipliers). Moreover, since we are more interested in discovering
rules that identify positive members of the document category, we
restrict our attention to those positive support vectors that have
![]() equal to 1. In this
way, our search is restricted the few data points that are actually
important to the SVM model.
equal to 1. In this
way, our search is restricted the few data points that are actually
important to the SVM model.
The input sensitivity of the SVM from Equation 1 with the Gaussian kernel from
Equation 3 is easily derived
as:
![\includegraphics[width=3.25in]{groups}](../../CDROM/refereed/403/img62.png) |
To find an effective query modification, we use the procedure
described in Table 1.
The procedure iterates over all positive training examples that
have a non-zero Lagrange multiplier. A family of query
modifications is found by identifying the largest ![]() components of the sensitivity vector.
Since no mainstream search engine allows the user to specify
weights for individual terms (i.e., they only allow +term
and -term), we cannot use all of the information in the
coefficients of the sensitivity vector.
components of the sensitivity vector.
Since no mainstream search engine allows the user to specify
weights for individual terms (i.e., they only allow +term
and -term), we cannot use all of the information in the
coefficients of the sensitivity vector.
Instead, we treat positive coefficients as having a weight of 1,
negative with -1, and all others 0. In this way, a query
modification can be thought of as a simple threshold classifier
with weights that are all in ![]() . At line 3 in Table 1, we examine all possible variations
of a query modification that optionally zero out one or more terms.
This restricted search is necessary because of the implicit
thresholding that we are performing on the weights. However, the
search is not as expensive as the bounds for the second for loop
suggest because the sensitivity analysis may produce duplicate
suggestions. In this case, we can hash the test query
modifications, and only evaluate those that have not been evaluated
thus far.
. At line 3 in Table 1, we examine all possible variations
of a query modification that optionally zero out one or more terms.
This restricted search is necessary because of the implicit
thresholding that we are performing on the weights. However, the
search is not as expensive as the bounds for the second for loop
suggest because the sensitivity analysis may produce duplicate
suggestions. In this case, we can hash the test query
modifications, and only evaluate those that have not been evaluated
thus far.
In the end, we find a query modification that (almost always) satisfies a pre-specified desired precision, but tends to maximize recall. If no query modification is found by the procedure, the search for effective query modifications is finished.
After finding the first effective query modification, we find additional query modifications by altering the training dataset for the SVM. All true positive training exemplars are removed from the dataset, leaving all negative exemplars and false negatives.
By deflating the dataset in this manner, we can find multiple local linear rules that are all effective, especially when fused together. Figure 1 shows a stylized example of how the method can work. In the example, we have three regions that are mostly disjoint from one another. For each region, the sensitivity analysis discovers a linear rule with the following properties. First, the location of the decision boundary will always be on the edge of the region that is closest to the other regions (which is guaranteed by only searching over support vectors). Second, the decision boundary will be parallel to the direction of greatest sensitivity of the region (which also implies that the decision boundary will be perpendicular to the region's direction of greatest variance). As a result of these two properties, each decision boundary can be viewed as the tightest ``slice'' that removes a region from the rest of the training examples.
Composing multiple ``slices'' in this way allows us to potentially separate large regions of positive examples with a small number of rules. Moreover, the procedure is structured so that each rule is a conjunction of terms while the composition of the rules is formed as a disjunction (i.e., disjunctive normal form); as a result, the rules can be submitted to a search engine as multiple queries.
We now describe how our method has been used to generate effective query modifications for identifying personal home pages and conference pages. For our results, we use the notation title:term to indicate that term should occur in the title of a document. Many search engines, such as AltaVista, support queries of this form. All other query modifications specify terms that should appear in the title or the full text of the document.
The training set for this experiment consisted of 250 personal
home pages and 999 random URLs that were given negative labels. All
of the documents were preprocessed into vectors of 100 features.
The negative exemplars contained approximately 1% false positives,
based on human inspection of random samples. We set the desired
precision to be at least 50%. The SVM was optimized with ![]() set to 7,
set to 7, ![]() set to 5, and
set to 5, and ![]() from the extraction procedure was set to 5. The
extracted query modifications are listed in Table 2
from the extraction procedure was set to 5. The
extracted query modifications are listed in Table 2
| QM# | extracted query modification |
|---|---|
| 1 | title:s title:page "about me" |
| 2 | "i am" "my favorite" "sign my" |
| 3 | "is my" "my page" "interests" |
| 4 | title:home "s home" |
| 5 | interests "my page" "me at" |
| 6 | "sign my" title:home |
| 7 | "my page" interests "welcome to my" |
In the table, one line represents a single query modification. Notice that all of the query modifications contain less than four additional search terms even though our procedure searched for as many as five terms in a single modification.
To measure the effectiveness of the query modifications, we tested three queries without any modifications and with the first four generated query modifications. The results are presented in Table 4. Whenever a search engine returned more than 50 results, we only manually classified the first 50 pages; performing the statistics in this manner is consistent with our goal since we are using the query modifications to bias the search engine's ranking function.
As can be seen in Table 4, the fourth query modification for home pages gives better precision in all cases, but the merged results of all four query modifications gives the highest recall as indicated by the low overlap between returned results. Moreover, in each case, the combined precision is at least as high as the desired precision of 50%.
We also note that our test produced many pages that were listings of links to personal home pages, ``about me'' type pages, or CV and resume pages; thus, while these pages were labeled as false positives for our statistics, they are not too far from being desirable results.
| QM# | extracted query modification |
|---|---|
| 1 | "call for" |
| 2 | "program committee" |
| 3 | conference hotel workshops |
| 4 | "this workshop" |
| 5 | "fax email" "the conference" |
| "sponsored by" |
| home | total | ||
|---|---|---|---|
| query | pages | pages | precision |
| +"information retrieval" | 0 | 50 | 0% |
| +"information retrieval" +title:s +title:page +"about me" | 3 | 3 | 100% |
| +"information retrieval" +"i am" +"my favorite" +"sign my" | 0 | 1 | 0% |
| +"information retrieval" +"is my" +"my page" +"interests" | 0 | 12 | 0% |
| +"information retrieval" +title:home +"s home" | 46 | 50 | 96% |
| MERGING ALL 4 QUERY MODIFICATIONS AND REMOVING DUPLICATES | 49 | 66 | 74% |
| (NO DUPLICATES) | |||
| +"beagles" | 1 | 50 | 2% |
| +"beagles" +title:s +title:page +"about me" | 5 | 7 | 71% |
| +"beagles" +"i am" +"my favorite" +"sign my" | 7 | 32 | 22% |
| +"beagles" +"is my" +"my page" +"interests" | 0 | 9 | 0% |
| +"beagles" +title:home +"s home" | 39 | 50 | 78% |
| MERGING ALL 4 QUERY MODIFICATIONS AND REMOVING DUPLICATES | 47 | 94 | 50% |
| (4 POSITIVE DUPLICATES) | |||
| +"starcraft" | 0 | 50 | 0% |
| +"starcraft" +title:s +title:page +"about me" | 24 | 34 | 71% |
| +"starcraft" +"i am" +"my favorite" +"sign my" | 27 | 50 | 54% |
| +"starcraft" +"is my" +"my page" +"interests" | 15 | 49 | 31% |
| +"starcraft" +title:home +"s home" | 44 | 50 | 88% |
| MERGING ALL 4 QUERY MODIFICATIONS AND REMOVING DUPLICATES | 101 | 174 | 58% |
| (9 POSITIVE DUPLICATES) |
| conference | total | ||
|---|---|---|---|
| query | pages | pages | precision |
| +"neural networks" | 1 | 20 | 5% |
| +"neural networks" +"call for" | 10 | 20 | 50% |
| +"neural networks" +"program committee" | 12 | 20 | 60% |
| +"neural networks" +conference +hotel +workshops | 17 | 20 | 85% |
| +"neural networks" +"this workshop" | 16 | 20 | 80% |
| MERGING ALL 4 QUERY MODIFICATIONS AND REMOVING DUPLICATES | 51 | 75 | 68% |
| (4 POSITIVE DUPLICATES, 1 NEGATIVE DUPLICATE) | |||
| +"learning" | 0 | 20 | 0% |
| +"learning" +"call for" | 5 | 20 | 25% |
| +"learning" +"program committee" | 9 | 20 | 45% |
| +"learning" +conference +hotel +workshops | 15 | 20 | 75% |
| +"learning" +"this workshop" | 6 | 20 | 30% |
| MERGING ALL 4 QUERY MODIFICATIONS AND REMOVING DUPLICATES | 35 | 80 | 44% |
| (NO DUPLICATES) | |||
| +"linux" | 3 | 20 | 15% |
| +"linux" +"call for" | 5 | 20 | 25% |
| +"linux" +"program committee" | 9 | 20 | 45% |
| +"linux" +conference +hotel +workshops | 12 | 20 | 60% |
| +"linux" +"this workshop" | 10 | 20 | 50% |
| MERGING ALL 4 QUERY MODIFICATIONS AND REMOVING DUPLICATES | 34 | 78 | 44% |
| (2 POSITIVE DUPLICATES, 2 NEGATIVE DUPLICATES) |
The conference web page data consisted of 529 negative examples
and 150 positive examples. All of the documents were preprocessed
into vectors of 300 features. As before, we set the desired
precision to be 50%. The SVM was optimized with ![]() set to 15,
set to 15, ![]() set to 10, and
set to 10, and ![]() from the extraction procedure was set
to 5 as in the earlier test. The first five extracted query
modifications are shown in Table 3.
from the extraction procedure was set
to 5 as in the earlier test. The first five extracted query
modifications are shown in Table 3.
As in the earlier test case, we used the top four query modifications to augment three test search queries: "neural networks", "learning", and "linux". The test results are summarized in Table 5. For this experiment, we manually classified the first 20 web pages for all queries (classifying conference pages by hand is more difficult than home pages).
As can be seen, the merged results maintained a precision level that was close to the desired precision, while increasing recall compared to the individual query modifications. Moreover, the combined query modifications offer some insurance in case any single query modification fails.
As stated in Section 2, our motivation for this work is to automate the process of generating effective query modifications for the Inquirus 2 metasearch engine. Previously, our query modifications were human-generated and selected based on the very unscientific notion that they seemed to ``make sense.'' While some of the human-generated queries were supported by our experiments, our automated method discovered many novel query modifications, which, in turn, suggest some interesting facts about documents on the Web and about the method we propose in this paper.
As part of this work, we performed many experiments on personal home pages that revealed interesting trends for the types of home pages that exist, and the different usages of language on the pages, which can be used to distinguish among them. For example, in one experiment we found geocities to be a very effective modifier because of the large number of free personal web pages hosted by GeoCities. We also found that children's home pages often made reference to their favorite things, while academics often wrote of their research interests. Thus, our method for finding multiple query modifications appears to identify language trends that occur in subgroups of a category.
While it is unlikely to derive a set of query modifications that has 100% recall and 100% precision, we believe that our work supports the use of multiple query modifications for increasing recall while maintaining a desired precision.
One key facet of our proposed method is the dataset deflation step, which eliminates all true positives from the training data, and retrains the SVM. The procedure in Table 1 performs a constrained and limited search for an effective query modification. To make an analogy, the query modification found in the step is akin to an``eigenquery'' in that it spans a large portion of the training data.
By removing the true positives from the dataset, at the next iteration we force a procedure to find query modifications that complement the previously found query modifications. Continuing the analogy, data deflation is similar to factoring out an eigenvector from a matrix so that the next eigenvector can be found.
In this way, our proposed method attempts to span a large portion of document space by identifying as many ``eigenqueries'' as possible.
Another benefit of our approach is that it performs
dimensionality reduction in at least four different ways. During
preprocessing, we eliminate ![]() -grams that are either too common or too uncommon.
While it is possible for this preprocessing to eliminate features
that are key to identifying a subset of the positive examples, we
believe that reducing the feature space via our preprocessing is
warranted considering that without it the feature space would
consist of hundreds of thousands of words or phrases.
-grams that are either too common or too uncommon.
While it is possible for this preprocessing to eliminate features
that are key to identifying a subset of the positive examples, we
believe that reducing the feature space via our preprocessing is
warranted considering that without it the feature space would
consist of hundreds of thousands of words or phrases.
Our search for sensitive positive exemplars is also assisted by the use of SVMs as a nonlinear model because the discovered support vectors (exemplars with positive Lagrange multipliers) are exactly the training points whose removal would alter the solution. Thus, by only searching sensitivities for positive support vectors, we reduce the number of documents which must be considered.
The sensitivity analysis also provides a ranking of features in
the input space. By only considering the largest ![]() components, we can efficiently search
for the optimal
components, we can efficiently search
for the optimal ![]() -dimensional query modification that uses those
-dimensional query modification that uses those ![]() input features.
input features.
Finally, and as previously mentioned, the dataset deflation step eliminates a significant portion of the training data at each step, which has the effect of speeding training time for the SVM and simplifying the document space for which we are searching.
Two alternative extremes for identifying query modifications would use linear classifiers and an exhaustive search in the feature space. The former method fails because it cannot work effectively in the linearly inseparable case. The latter approach is problematic because of the exponential number of binary classifiers that would need to be considered. Our approach exploits the underlying regularity of the documents that make up the WWW. We can discover higher-order correlations in the form of query modifications that contain multiple terms--even with a linearly inseparable feature space--but we can also guarantee that our procedure will terminate in a reasonable amount of time.
It is also interesting to compare our approach to a ``straw man'' approach represented by a more aggressive procedure that attempts to construct a large set of ridiculously complicated query modifications, each of which identifies only one or two pages. Such a set essentially acts as a lookup table for the training data. In this case, one would have little hope of generalizing to real-world data. By enforcing dimensionality reduction at many steps, we find query modifications that appear to generalize to real-world data despite the relatively small size of our training sets.
This last issue is especially important for very restricted searches, say, one in which we are trying to find the personal home page of a particular person (with a very common name) instead of one about a particular topic. By restricting the complexity of our query modifications and striving for maximum recall, our approach of using multiple query modifications can further increase the likelihood of finding very narrow search results which might normally be ranked beyond the limit of a given search engine.
We thank Frans Coetzee for insightful discussions, Sven Heinicke and Andrea Ples for help in performing experiments, and the anonymous reviewers for many helpful comments.
All SVM experiments performed in this work were done with NODElib, which can be downloaded from http://www.neci.nec.com/homepages/flake/nodelib/html/.