Copyright is held by the author/owner(s).
WWW2002, May 7-11, 2002, Honolulu, Hawaii, USA.
ACM 1-58113-449-5/02/0005.
The web's hyperlinks are notoriously brittle, and break whenever a resource migrates. One solution to this problem is a transparent resource migration mechanism, which separates a resource's location from its identity, and helps provide referential integrity. However, although several such mechanisms have been designed, they have not been widely adopted, due largely to a lack of compliance with current web standards. In addition, these mechanisms must be updated manually whenever a resource migrates, limiting their effectiveness for large web sites. Recently, however, new web protocols such as WebDAV (Web Distributed Authoring and Versioning) have emerged, which extend the HTTP protocol and provide a new level of control over web resources. In this paper, we show how we have used these protocols in the design of a new Resource Migration Protocol (RMP), which enables transparent resource migration across standard web servers. The RMP works with a new resource migration mechanism we have developed called the Resource Locator Service (RLS), and is fully backwards compatible with the web's architecture, enabling all web servers and all web content to be involved in the migration process. We describe the protocol and the new RLS in full, together with a prototype implementation and demonstration applications that we have developed. The paper concludes by presenting performance data taken from the prototype that show how the RLS will scale well beyond the size of today's web.
Keywords: Resource Migration Protocol; WebDAV; Referential integrity; Link rot; Resource Locator Service; Web
Copyright is held by the author/owner(s).
WWW2002, May 7-11, 2002, Honolulu, Hawaii, USA.
ACM 1-58113-449-5/02/0005.
The size of the World Wide Web has grown beyond its original expectations, placing considerable stress upon its architecture. As more people use the web, and more information is published on it, so any limitations and flaws in its architecture become exposed. Perhaps the biggest flaw is the resource identifier that the web uses: the URL [4]. Because the URL binds a resource's name to its location, it breaks whenever a resource moves from one server to another ("migrates"), leaving the URL to reference a non-existent resource. Over time, an increasing number of links on an unmaintained web page will break in this manner, giving the appearance of the links rotting. Link rot, as it is known, is becoming a serious problem, with studies showing that 23% of all hyperlinks no longer work after a year [17].
The problem is widely acknowledged, and many solutions have been designed to provide the web with some form of referential integrity (e.g. [6], [14], [16], [22], [26]). However, these solutions are largely proprietary, and rely on the user updating them whenever the resource migrates.
Recently, however, a new set of protocols has been developed by the IETF that can be used to design a new solution. The Web Distributed Authoring and Versioning (WebDAV) protocol [13], [29] is designed to allow remote authoring of resources, but its features are ideal for enabling automatic resource migration across web servers. As such, in this paper, we demonstrate how we have used WebDAV and its associated protocols in a novel way to develop a backwards compatible Resource Migration Protocol (RMP).
The paper begins by describing the background to link rot and reviewing existing solutions. This is followed by an overview of a new solution that we have developed, called the Resource Locator Service (RLS), which transparently migrates resources across existing web servers. The paper continues by showing how we applied the WebDAV protocol to resource migration in the design of the RLS's Resource Migration Protocol. Finally, the paper concludes by presenting a prototype of the RLS and several demonstration applications, together with performance measurements that illustrate the scalability and effectiveness of the design.
One solution to link rot is the introduction of a 'transparent resource migration mechanism', which helps provide referential integrity by ensuring a resource's location is separate from its identifier, and persistently maintaining the resource's location [15]. This is difficult to achieve on the web, however, as the URL was designed to identify a resource by its location. Indeed, most existing systems simply replace it with their own proprietary identifier, but this is unacceptable if the mechanism is to be widely adopted across the web, as the URL is too pervasive to be replaced. To be successful, an effective mechanism must work within existing web standards rather than seek to replace them.
However, even standards based approaches can fail. For example, the IETF's Uniform Resource Name (URN) is a "persistent, location-independent, resource identifier" [19]. However, the URL was defined and used before the URN's working group was chartered, and its ubiquitous use has ensured that no other identifier has since been adopted.
To compound matters further, the DNS is also part of the resource location process, but because it identifies hosts rather than resources, it is unable to prevent link rot when individual resources migrate. As such, we argue that both the URL and the DNS need to be replaced or augmented if the web is to address link rot. The challenge lies in replacing them without breaking the web's existing architecture.
For this paper, we are concerned with three core components of a transparent resource migration mechanism:
Current solutions fall into two main categories:
Solutions using the standards based approach include the Resolver Discovery Service [24] and the PURL [22], both of which separate the resource's identifier from its location, but do not provide a migration mechanism. The proprietary solutions include W3Objects [14] and the Handle system [26], but although W3Objects provides an API for programmatic access to its resources and servers, neither provides an explicit migration mechanism, and neither integrates well with the web's existing architecture. At best they can interoperate with the web, but they provide separate networks that are not fully integrated. As such, while both approaches attempt to solve link rot, only the standards based approach attempts to provide an architectural solution, and neither provides a protocol for automatic resource migration. A more thorough description of existing solutions can be found in [8], while a comprehensive framework that models the approaches adopted by these solutions can be found in [7].
To address the limitations of existing systems, we have developed the Resource Locator Service (RLS), which has been designed to provide a transparent resource migration mechanism for all web resources [9]. The RLS is a distributed database, deployed across a network of nodes called Locators that form the RLS's Locator Network. A Locator is analogous to a Resolver [24], and performs a similar role to the DNS, but with granularity at the resource level.
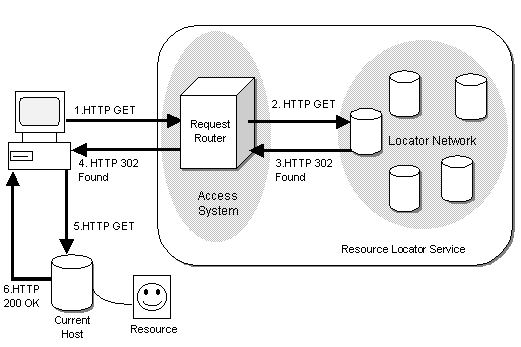
Figure 1 shows a high level view of the RLS. The Locator Network provides the RLS's resolution service, mapping a resource's name onto its location, and redirecting the client to the resource's correct location using the HTTP redirect mechanism [10]. Although this is not the most efficient approach, it facilitates backwards compatibility, enabling all web entities to use the RLS.
In order for the client to query the Locator that holds the required name/location mapping, some form of mediation is required between the client and the RLS that can transparently route the client's request, without requiring any modifications to the client or server. Our solution to this problem, called the Request Router, is described in the following sub-sections.
The Request Router (RR) is a flexible component that routes HTTP requests to an appropriate Locator, and has been designed to be used wherever it is required, whether it be the client, server, or elsewhere in the network. It provides transparent, scalable mediation between the web and the RLS through the use of a hash routing algorithm, which takes a string and maps it onto a hash space. The hash space is partitioned such that the string is mapped onto one and only one node in a distributed system [21], [27]. Using a hash routing algorithm as the basis for locating nodes in the RLS, therefore, enables any string to deterministically identify the Locator that contains the required name/location mapping. Thus, the hash routing algorithm enables the RLS to use any naming scheme, regardless of syntax.
The RR uses the same hash routing algorithm as the Cache Array Routing Protocol (CARP) [28], which maps a URL onto a specific cache in a distributed caching system. The algorithm used in CARP can scale to over 4 billion (232 = 4,294,967,296) Locators, performing single-hop resolution throughout [18], and so is an ideal choice for the RR as it is fully scalable (see [9] for more details of the RR's scalability).
The CARP algorithm works by using a hash function to map the URLs of the resources that need to be cached onto a partitioned hash space, with each set of URLs in a partition being associated with one caching node [21]. The hash function ensures all resources are distributed uniformly across the system, thus distributing the load. Applying the hash function to a URL will therefore deterministically locate the caching node that hosts the resource in the cache array.
Although highly effective in large cache arrays, however, the CARP protocol has been adapted for use in the RR to better meet the needs of the RLS. Specifically, each node in a CARP system keeps a list of the URLs of all the caches in the system, as these must be hashed with the URL of the resource to minimise the disruption caused by a change in the number of caching nodes [21]. This list must be continuously maintained, which causes a level of network overhead that would be intolerable in a web-wide system. The RLS avoids this by requiring each Locator's URL to conform to a URL pattern, which encapsulates a number that identifies that Locator. The numbering is sequential, and is zero-based. An example URL pattern is:
http://www.nodeX.Locator.net/
where X represents the Locator's number in the system. Effectively, the URL pattern of the Locators acts as a well-known URL in a similar way to the well-known ports defined for TCP applications. Note that the URL pattern must be sequential, and there can be no gaps in the sequence. The URLs of a complete sequence of nodes, each of which has a URL that corresponds to the URL pattern, is therefore known as a URL sequence. In this way, the URLs of the Locators themselves become deterministic, and so a continuously maintained list of the Locator's URLs is not required. Thus, the only information required by the RR is the URL pattern, and the limit of the URL Sequence, which it can find by querying each node in the sequence until no reply is received.
Adding a new Locator to the RLS will cause the hash routing algorithm to re-map 1/n name/location mappings in an n - node system (note that n includes the new node) [21], [27]. As such, if a Request Router is unaware of this change in the system's configuration, then 1/n of its requests will go to the wrong Locator, which will return an HTTP 404 Not Found message. However, this will cause the RR to re-check the configuration of nodes in the RLS. Specifically, the RR queries the existence of the Locators that have a node number above and below the existing limit. If the limit remains unchanged, then the RR knows that the resource is unregistered with the RLS; otherwise, the RR simply rehashes the resource's name using the updated value, and sends the request to the newly calculated Locator. In this way, the RR is completely decoupled from the configuration of the Locator Network, and does not need to be synchronized with it, and so any change in the configuration of the system does not result in a flood of update messages.
To automate the process of changing the configuration, we have defined a Locator Control Protocol that ensures all name/location mappings are moved transparently to the correct Locator whenever the configuration changes. The details of this operation, together with its impact on system performance, are extensively documented in [9]. Due to space constraints, the interested reader is directed to this paper for more information.
In order to remain backwards compatible with existing web entities, the RLS is a loosely coupled system. That is, the system provides a mechanism for resource owners to ensure that links to their resource persist, rather than automatically maintaining link integrity for all existing links on the web [7]. More specifically, it adopts what Davis calls the Unique Names solution to link rot, whereby every resource is provided with a globally persistent and unique name [7]. The RLS differs from other systems that adopt this approach, such as the PURL and the URN, however, in three key areas:
This allows the RR to be integrated into the web wherever it is required. In this way, the number of resources registered with the RLS can grow over time as more people decide they wish to use its services. As such, we envisage the adoption of the RLS to be evolutionary, rather than revolutionary, proceeding in a distributed way across different sectors of the web, as its services become useful to different types of user.
Although the RLS will only support those resources that are registered with it, its advantages over existing systems should give it a much better chance of adoption. In addition, we feel that this is the most practical approach to referential integrity in a system the size of the web, whose architecture has long been defined and implemented. As Davis argues, not all links need preserving [7], and the RLS gives the resource owner the choice of preservation without requiring the modification of existing web entities.
The RLS's migration mechanism makes novel use of WebDAV and its associated protocols, which are ideally suited to automating resource migration on the web. In particular, WebDAV defines a set of functions that relate to security, safe file transfer, and server querying (see [23] for a complete list) that are particularly useful, as the following sub-sections show.
Because WebDAV enables web resources to be authored remotely, it is imperative that only authorized users are granted write access. In addition, WebDAV supports file locking on remote web servers [29], and so requires clients to be authenticated before locks are granted. WebDAV achieves these aims by using a combination of a related protocol called the Access Control Protocol (ACP) [5], and HTTP authentication schemes (e.g. Digest access authentication [11], and Basic authentication over SSL [12]).
The same security concerns that WebDAV has addressed also apply to resource migration. Just as a client must be authorized before being allowed to write to a resource, so a client must be authorized before being allowed to move a resource from one server to another. Moving a resource without permission can be considered theft. Equally, moving a resource onto a server that does not wish to host it can be considered trespass. As such, the client must be authorized before it is granted the right to move a resource, and the destination must grant access before hosting the resource.
HTTP provides rudimentary file transfer features that enable a resource to be downloaded, uploaded, or deleted. However, distributed authoring needs more control than HTTP can provide. For example, HTTP does not enable a resource to be moved, only copied [10]. Equally, HTTP cannot lock files, and so suffers from the lost update problem [20], in which two or more parties updating a resource will inadvertently overwrite previous versions, and thus lose any updates created by the other party. WebDAV was designed specifically to overcome these problems, and does so by extending HTTP to incorporate new methods for file locking, moving and copying [29].
A variation of the lost update problem also affects resource migration. For the process to be truly transparent, the resource must be accessible at all times, even when the resource is in the middle of migrating from one server to the next. With HTTP, however, a resource could potentially be updated during the migration process, causing the wrong version to be updated and migrated. As such, WebDAV's file locking mechanism can ensure the integrity of the content during the migration operation.
HTTP provides rudimentary querying of a web server, but only in relation to content negotiation [10]. A client can request different versions of the same resource according to the resource's media-type, language, etc., or the client's own capabilities. However, there is no standard interface for querying a web server according to a resource's properties. For example, a client cannot determine a resource's author, or its subject matter, unless it uses a non-standard protocol on top of HTTP that both the client and server supports.
WebDAV resolves this by enabling a set of properties to be associated with a resource using a new HTTP method called PROPPATCH, and queried using a new HTTP method called PROPFIND [13]. An associated protocol, DASL (DAV Searching and Locating [3]) provides a new HTTP method, SEARCH, for explicitly searching through these properties, enabling them to be fully queried, updated and deleted, all using the ACP to ensure proper authorization.
Resource properties are important to resource migration, as they can be used by the destination server to determine whether or not it wants to host the resource. For example, a server may wish to deny a request to host a resource based on the resource's author or subject. Equally, an automatic migration mechanism must enable a client to automatically update a resolution service. This can be achieved through treating each resource's name/location mapping in a name server as a resource, with the name and location acting as properties of the resource. Thus, updating a resource's location within the name server becomes a matter of updating the resource's properties in the name server. Using WebDAV to achieve this functionality allows HTTP to be used as the interface to the name server, thus providing interoperability with existing web entities.
The majority of resource migration protocols are used within distributed processing systems, such as RM-ODP implementations [15]. As such, these systems implement the protocol using Remote Procedure Calls, which are far more efficient and opaque than the text-based messages of protocols based on HTTP. However, these systems generally migrate objects or processes, which require sophisticated handling mechanisms to ensure that the object's code, its data, and its current state are all migrated safely. In contrast, web resources are far simpler, largely consisting of HTML documents or images. Objects and applets can be migrated, but the protocol described here provides no support for migrating an object that is currently executing: resources are considered as simple files during the migration process.
Another disadvantage of WebDAV is that, although the specification provides MOVE and COPY methods for moving and copying a resource, most implementations do not currently support moving or copying a resource onto a different WebDAV server [25]. This limitation prevents these methods from being used at this stage of the RMP's development, and so we use standard HTTP GET, PUT, and DELETE methods to move a resource. We will explore implementing WebDAV's MOVE and COPY methods in future revisions of the RMP.
The RLS uses WebDAV as the basis for its Resource Migration Protocol, which forms the core of its migration mechanism. The following sub-sections describe the RMP, and show how the migration mechanism transparently migrates web resources.
The entities involved in the migration process are:
A Migration Manager is any entity overseeing the migration operation, and could be, for example, a client, or an intelligent agent wishing to migrate itself, or a dedicated server acting on behalf of the resource owner. It is the only participant allowed to act as a client in the whole operation, ensuring, for security purposes, that the Source and Destination servers do not communicate with one another. In this way, the Manager can safely pass authentication details directly to the other entities involved in the migration process, without requiring those details to be forwarded onto another machine.
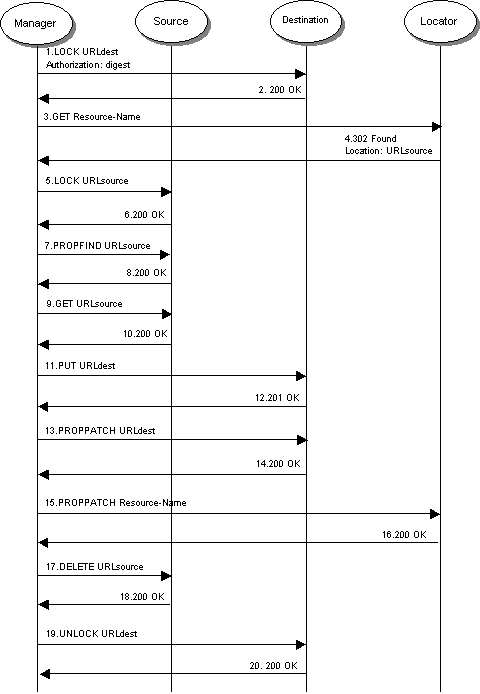
To begin the migration, the Manager must be given the URL of the resource at its Source (URLsource), and the resource's new URL at its location on the Destination (URLdest). The following sub-sections, together with the Message Sequence Chart shown in figure 2, describe the operation in more detail.
The
process begins with the Manager reserving URLdest on the Destination, and determining
whether it will accept the resource from the resource owner. The Manager
achieves this by sending a WebDAV LOCK message (message 1) to the Destination
for the resource identified by URLdest. At this stage, the
migrating resource is still hosted by the Source, and so URLdest is bound to
a null resource on the Destination. A null resource is "a resource
which responds with a 404 (Not Found) to any HTTP/1.1 or DAV method except for
PUT, MKCOL, OPTIONS and LOCK" [13]. Locking a null
resource effectively reserves the associated URL, and so message 1 ensures that
no other user can use URLdest until the Manager unlocks it.
The LOCK message also provides the Destination with the chance to authorize the resource owner. The Manager acts on behalf of the resource owner, and sends authentication details to the Destination server as an HTTP request header in the LOCK message. If the Destination does not authorize the request, it returns a standard HTTP 401 Unauthorized response message and the migration process ends.
The second stage of the process involves moving the resource from the Source to the Destination in such a way that all clients can access it at all times. To begin with, the Manager sends an HTTP GET request to the Locator that holds the resource's details (message 3). The Locator will return an HTTP 302 Found response (message 4) containing the current location of the resource (i.e. URLsource). The Manager then contacts the Source and LOCKs the resource (messages 5 and 6), ensuring it is not updated in the middle of the migration operation. The Manager must not migrate the resource until it has been successfully locked. The Manager then sends a WebDAV PROPFIND request to retrieve the properties of the resource (messages 7 and 8), before sending an HTTP GET message to retrieve the resource itself (messages 9 and 10). The resource is copied to the Destination using an HTTP PUT message (messages 11 and 12), using URLdest as the new location for the resource on the Destination. Once this has been accepted, the resource is hosted on the Destination and ceases to be in the lock-null state [13].
The resource is now hosted by both the Source and the Destination. The Manager continues by sending the resource's properties onto the Destination via a WebDAV PROPPATCH request (messages 13). The properties contain meta-data such as the resource's subject, its author, copyright information, etc. At this stage, the Destination may decide it cannot host the resource on content grounds; in other words, it will have authorized the resource owner and agreed to host their resources (using messages 1 and 2), but it cannot authorize the content contained in this specific resource (for example, it may refuse to host resources about a particular subject). Note that content authorization can only be granted after the resource has been copied, as a PROPPATCH cannot be performed on a null resource. Although not optimal, this method has the advantage of complying with WebDAV, ensuring backwards compatibility with existing WebDAV servers.
If the Destination does not wish to host the resource, it must return an HTTP 403 Forbidden response, and delete the resource. The Manager must then unlock the resource on the Source, and the migration process will have ended once more. The resource will still be located on the Source (which, at this stage, has no idea a migration operation is in progress), and the Locator will not have been updated, so the resource will still be accessible from its original location. Note that a standard WebDAV server cannot perform content authorization, as it will simply accept the PROPPATCH request and change the resource's properties accordingly (assuming no errors occur). However, content authorization is not required by the RMP for successful migration; rather, it has been defined to give modified servers more control over the migration process if required.
Once the Destination agrees to host the resource and sends a 201 OK message in response (message 14), the Manager must update the appropriate Locator. It does this by sending another PROPPATCH message (message 15), with the resource's persistent URL as the identity of the resource (i.e. its name), and URLdest as the property to be updated (i.e. its location). Again, authorization must be performed by the Locator. Note that the persistent URL representing the resource's name can be any string, and does not have to be a URL, so long as it is unique within the RLS.
Both the Source and the Destination now host copies of the resource. Only after the Manager receives a 200 OK message (message 16) from the Locator, indicating the location has been updated, can the Manager send an HTTP DELETE request (message 17) to the Source, instructing it to delete the resource. Note that both HTTP and WebDAV define a DELETE method, with the WebDAV method providing more control over what is being deleted, and its associated response message (a WebDAV 207 Multi-status response [13]) providing details about Lock states. As such, the Manager should accept either the HTTP version (200 OK, 202 Accepted, or 204 No Content [10]), or the WebDAV version of the response to DELETE. Once the successful response to DELETE has been received (message 18), the manager UNLOCKs the resource on the Destination (message 19), and the migration process is complete.
If a web server does not support WebDAV, it can still participate in the migration process, albeit with less control. For example, WebDAV servers can use the Access Control Protocol to grant or deny access rights, whereas a standard HTTP server must rely on HTTP authentication schemes. Equally, a WebDAV server can perform content authorization, whereas an HTTP server can only authorize the resource owner.
Because of the design of WebDAV, a non-compliant server will still be able to communicate with the Migration Manager, even though it does not recognize WebDAV methods such as LOCK. In this case, the Manager will receive an HTTP 405 Method Not Allowed message [10], from which it can infer that the server does not support WebDAV. As such, it can continue the process using standard HTTP commands only, but needs some way of persisting the resource's properties onto the non-WebDAV server. The Manager achieves this by saving the XML-formatted PROPFIND body that contains the properties (message 7) as an XML file on the Destination, with the same name as the resource, but with 'PROP' appended. When the resource needs to migrate again, the Destination becomes the Source. When a Manager realises the Source is not WebDAV compliant, it ensures it GETs not only the resource, but the associated XML property file as well. If the new Destination is WebDAV compliant, the property file can be sent embedded within the body of a WebDAV PROPPATCH message. In this way, properties can persist across all servers involved in the migration process, regardless of their compliance with WebDAV or the RMP.
In order to test the design of the RLS, we have developed a prototype, with the Locator functionality implemented on a Microsoft NT4 server using Active Server Pages, and the RR embedded in a custom C++ proxy server, which routes HTTP requests to the correct Locator [9]. We have also developed a Management Interface (figure 3), which includes a Request Router object for querying the Locator Network, and an RMP client that enables it to act as the Migration Manager during a migration operation.
The Management Interface provides a Windows-explorer like user interface that controls the RMP. A web resource can be dragged from its source directory on one web server onto a destination directory on another server, in the same way that files are copied and moved using Windows Explorer. However, because the Management Interface implements the RMP, the files are actually migrated over to another web server, with the correct Locator updated automatically, such that any client using our proxy server (or any other entity containing the same Request Router) is able to access the resource at all times throughout the migration operation. As such, the interface demonstrates automatic resource migration, as well as the backwards compatibility of the system, as the web servers shown in figure 3 have not been altered in any way, and are completely unaware of the RLS as a system.
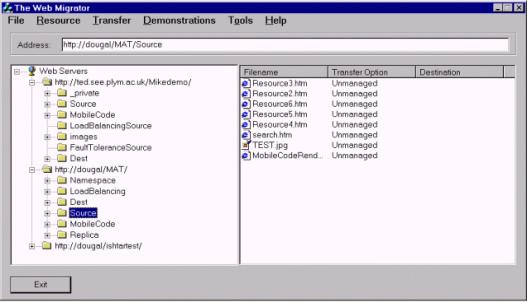
The web servers shown in figure 3 use Microsoft's IIS 4 under Windows NT 4. However, because RMP uses standard HTTP and WebDAV message, the interface will work with any web server, whether it is WebDAV compliant or not, so long as each server grants write access to the Manager (username and password settings can be stored within the Management Interface). For example, the web servers in figure 3 are standard web servers, with two supporting WebDAV. None of the servers explicitly support RMP; rather, each server simply responds to the individual HTTP and WebDAV requests that are sent by the RMP client within the interface. As such, the servers are entirely unaware that they are involved in a migration operation.
The prototype RLS is functional enough for us to develop some demonstrations of the services it can provide. We discuss these and other features in the following sub-sections.
The web provides little support for load balancing. The DNS can be used to provide a crude load balancing service by returning different IP addresses for the same hostname, but this 'round robin' functionality [1] only works at the host level, as browsers generally only perform a DNS query once for a whole web site.
In contrast, the RLS can provide a more sophisticated load balancing service at the resource level. Replicated resources will have the same name but different locations. Assigning sequence orders to each replicated resource enables a Locator to return different URLs for the same resource for every HTTP request. This has been implemented in our prototype RLS, which permits resources to be placed on different servers according to media type, demand, or processing requirements, which is a level of management not supported by the DNS. The management interface monitors the load on various resources. If the load gets too high, it migrates the resources to different predetermined web servers under its management, using the RMP. Once the load reduces, the resources are migrated back again.
Mirroring a web site provides the web with a manual form of fault tolerance, but requires the resource owner to provide a different link to each of the various mirrors. If one of the mirrors falls over, the link to that mirror is broken, and the user must manually try another mirror through another link. Clustering servers provides a more transparent alternative, but only at the level of individual servers.
In contrast, the RLS can be used to automatically route around mirrors that have fallen over, and allow the resource owner to provide only one link. In addition, fault tolerance can be set at the resource level, enabling different levels of tolerance to be set for different resources depending upon their importance. The management interface we have developed provides a demonstration of this. Firstly, the user selects appropriate destinations for each resource that needs to be managed. Secondly, the management interface automatically replicates these resources onto selected web servers, using RMP. The interface then monitors the resources. If it cannot access them, it updates the appropriate Locator, marking the inaccessible resource as inaccessible, and switching access over to the replicated resources. Once the original server comes back up, the interface brings the Locator back to its original state. This demonstrates the usefulness of an automatic resource migration mechanism.
Mobile agents are items of code that migrate across machines to perform their required task. However, they are not helped by the web's architecture, which causes the agent's URL to break each time it migrates. With the use of the RLS, however, any code can freely migrate, as it is treated by the RLS as just another resource.
Our prototype system demonstrates mobile code by migrating a resource onto a random server every minute. We have four servers set up in the same room. The resource is a file containing a fragment of HTML, which is migrated onto the same directory on the server as a mobile code-specific web page. This web page contains JavaScript that looks for the existence of the resource every 10 seconds; if it finds it, it reads the HTML contained within the resource and displays it. If not, it displays a blank screen. Each server permanently displays the web page through a browser. As the interface moves the resource across the servers, the HTML contained within the resource is displayed on a different machine, providing a visual demonstration of migration. The user can change this HTML in the mobile code at any time, no matter where the resource is currently located. To do this, the interface sends an HTTP GET request to the appropriate Locator, which returns an HTTP 302 Found response, with the current location of the response contained within the location header. The interface uses this location to issue an HTTP PUT request, updating the resource with the new HTML entered by the user, regardless of where the resource happens to reside. This demonstrates the transparency of the migration operation, as any client connected to the proxy can download the resource and view its HTML contents at any time, regardless of which server hosts the resource, or where it is in the migration process.
Although a trivial implementation, this demonstrates the ability of the RLS and RMP to act as a platform for mobile code and mobile agents. As such, a real mobile agent would contain more functionality than a simple HTML file, and could be designed to contact a Migration Manager to migrate itself onto a different machine.
To be effective, the RLS and RMP must not impose significant overhead. In practice, the performance of the RLS in locating a resource is far more critical than the performance of the RMP, which will not normally be under any time constraint as the resource is always available throughout the migration process. As such, to demonstrate the effectiveness of the design of the RLS, we measured the performance of the RR for differing numbers of (virtual) Locators. The results are presented below, while more extensive details are presented in [9].
The design of the RLS is such that the network overhead is constant (one additional HTTP request and response), regardless of how many Locators are in the system, whereas the CPU overhead required by the RR scales linearly with respect to the number of Locators. As such, the scalability of the design is constrained more by CPU overhead than network overhead.
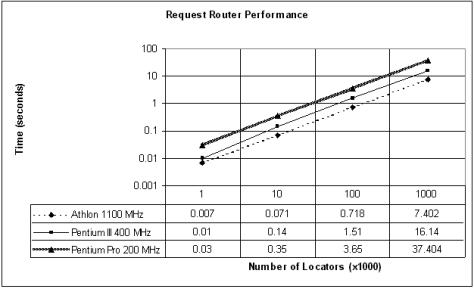
We tested our Request Router on a Pentium Pro 200MHz with 64MB RAM, a Pentium III 400MHz with 128MB RAM, and an Athlon 1.1GHz with 128MB RAM. We set the number of Locators that the RR believed existed within the RLS to different levels, and measured the length of time that the RR took to identify the correct Locator. The results are presented in figure 4, which clearly reveals the linear relationship between time and the number of Locators. The results show that for small numbers of Locators, the time taken is insignificant, and that even with more Locators, the time taken is still small. As such, even with a relatively slow processor such as the Pentium Pro 200MHz, the RR can determine the correct Locator from a 10,000-node Locator Network in only 0.35 seconds.
The total overhead introduced by the system was measured to provide a real-world indication of the system's performance. To do this, we first measured the time it took to visit the homepage of www.lycos.co.uk using a standard browser (Microsoft IE 5.0) and no RLS. The web site was visited 25 times, with the browser's cache deleted each time. We then connected the browser to our proxy server with the embedded RR, and visited the same sites again, once more taking 25 distinct measurements. The experiment was run using an Athlon 1.1 GHz PC with 128MB RAM, which acted as the proxy server with an embedded RR, and a Pentium Pro 200MHz PC with 64MB RAM, which encoded the functionality of the Locator. Both machines used Microsoft Windows NT 4 Server, and were connected via a 10Mbps Ethernet LAN.
The RR in the proxy server was manually configurable, allowing us to artificially set the number of Locators according to requirements. For this experiment, we varied the number of Locators in the system from one to 1 million. The results presented in table 1 show the time taken to visit the Lycos web site both with the RLS, and without it, using one, 1,000, 10,000, 100,000, and 1 million Locators in the system. Each value is the 10% trimmed mean of 25 trials, with the overhead calculated by subtracting the mean from the value obtained without the RLS. The results show that the overhead introduced by the RLS ranges from 0.869 seconds with only one Locator in the system, to 8.38 seconds with 1 million Locators. However, despite the large overhead for 1 million Locators, it remains small up to 100,000 Locators, with 1.582 seconds recorded. In addition, the design of the RR is not optimal, as it rehashes every Locator URL for every request that it routes, but unless the number of Locators changes, these hash values will remain static.
|
Number of Locators |
Download time for www.lycos.co.uk (time without RLS = 7.608 sec) |
Overhead |
|
1 |
8.477 seconds |
0.869 seconds |
|
1,000 |
8.483 seconds |
0.875 seconds |
|
10,000 |
8.546 seconds |
0.938 seconds |
|
100,000 |
9.190 seconds |
1.582 seconds |
|
1,000,000 |
15.985 seconds |
8.377 seconds |
With the advent of new Web Services using protocols such as SOAP, WSDL, and UDDI, the RLS has the opportunity to provide its resource migration and location services to more functional objects than simple static resources. The UDDI web service discovery protocol is a registry that uses the URL to identify the location of web services. As such, the links contained within UDDI will be as fragile as traditional web hyperlinks, and so the RLS could be used to significantly increase the reliability of the UDDI service. The functionality of the RLS can also be extended by providing the Locators with a native SOAP-based interface, which will enable Web Services to use the RLS using their native messaging protocol.
In addition, the concepts of the Request Router can be extended to any distributed system, thus enabling other distributed systems to be integrated into the web regardless of their naming scheme. Furthermore, the open namespace of the RLS can enable the URN and other naming schemes to be deployed on the web seamlessly.
To realize this vision, the security and integrity of the system must be assured. As such, future work will focus on integrating WebDAV's ACP into the RMP to enhance security, and handling error situations such that the RLS and participating servers can be safely rolled back.
We have presented a Resource Migration Protocol based on WebDAV that enables transparent resource migration across existing web servers. The RMP is a novel use of WebDAV, and is fully compliant with current and new web standards, enabling all existing web resources and servers to be involved in the migration process. The protocol has been presented along with a new Resource Locator Service, which has been developed as a new naming system and resource migration mechanism for the web. We have described our prototype implementation of this protocol, and provided performance data that show its effectiveness and scalability. As such, we see the RMP and the RLS as a useful new addition to the web that can provide advanced new services over existing servers.
[1] Albitz, P. and Liu, C. (1997), DNS and BIND, O'Reilly & Associates, Inc., California, USA, 1997.
[2] Arms, W., Daigle, L., Daniel, R., LaLiberte, D., Mealling, M., Moore, K. and Weibel, S. (1996), Uniform Resource Names - A Progress Report, D-Lib magazine, February 1996, http://www.dlib.org/dlib/february96/02arms.html
[3] Babich, A., Davis, J., Henderson, R., Lowry, D. and Reddy, S. (2000), DAV Searching and Locating, Internet Draft, April 20, 2000, http://www.webdav.org/dasl/protocol/draft-davis-dasl-protocol-00.html
[4] Berners-Lee, T., Masinter, L. and McCahill, M. (1994), Uniform Resource Locators (URL), RFC 1738.
[5] Clemm, G., Hopkins, A., Sedlar, E. and Whitehead, J. (2000), WebDAV Access Control Protocol, Internet Draft, June 21, 2001, draft-ietf-webdav-acl-06.txt
[6] Daniel, R. and Mealling, M. (1997), Resolution of Uniform Resource Identifiers using the Domain Name System, RFC 2168, June 1997.
[7] Davis, H. (1998), Referential Integrity of Links in Open Hypermedia Systems, Proceedings of ACM Hypertext 1998, pp. 207-216, 1998.
[8] Evans, M., Phippen, A., Mueller, G., Furnell, S., Sanders, P. and Reynolds, P. (1999) Strategies for Content Migration on the World Wide Web, Internet Research, vol. 9, no. 1, pp. 25-34, 1999.
[9] Evans, M.P., and Furnell, S.M. (2001), The Resource Locator Service: Fixing a Flaw in the Web, Computer Networks, Vol. 37 (3-4) (2001) pp. 307-330, November 2001.
[10] Fielding, R, Gettys, J., Mogul, J.C., Nielsen, H.F., Masinter, L., Leach, P. and Berners-Lee, T. (1999), HyperText Transfer Protocol HTTP/1.1, RFC 2616, June 1999.
[11] Franks, J., Hallam-Baker, P., Hostetler, J., Lawrence, S., Leach, P., Luotonen, A. and Stewart, L. (1999), HTTP Authentication: Basic and Digest Access Authentication, RFC 2617, June 1999.
[12] Frier, A., Karlton, P., and Kocher, P. (1996) The SSL 3.0 Protocol, Netscape Communications Corp., Nov. 18th, 1996.
[13] Goland, Y., Whitehead, J., Faizi, A., Carter, S. and Jensen, D. (1999), HTTP Extensions for Distributed Authoring - WebDAV, RFC 2518, February 1999.
[14] Ingham, D., Caughey, S. and Little, M. (1996), Fixing the 'Broken-Link' Problem: The W3Objects Approach, In The Fifth International World Wide Web Conference, Paris, France, May 6-10 1996.
[15] ISO/IEC (1993), Draft Recommendation X.901: Basic Reference Model of Open Distributed Processing - Part 1: Overview and Guide to use, ISO/IEC, 30th August 1993.
[16] Kappe, F. (1995), A Scalable Architecture for Maintaining Referential Integrity in Distributed Information Systems, J.UCS Vol. 1, No. 2, Springer, February 1995, pp. 84-104.
[17] Lawrence, S., Pennock, D.M., Flake, G.W., Krovetz, R., Coetzee, F.M., Glover, E., Nielsen, F.A., Kruger, A. and Giles, C.L. (2001), Persistence of Web References in Scientific Research, IEEE Computer, pp. 26-31, February 2001.
[18] Microsoft Corporation (1997), Cache Array Routing Protocol (CARP) and Microsoft Proxy Server 2.0, 1997, http://msdn.microsoft.com/library/backgrnd/html/carp.htm.
[19] Moats, R (1997), URN Syntax, RFC 2141, May 1997
[20] Nielsen, H.F. and LaLiberte, D. (1999), Editing the Web: Detecting the Lost Update Problem Using Unreserved Checkout, W3C NOTE, May 10, 1999, http://www.w3.org/1999/04/Editing/
[21] Ross, K.W., (1997), Hash Routing for Collections of Shared Web Caches, IEEE Network, November/December (1997), pp. 37-44.
[22] Shafer, K., Weibel, S., Jul, E. and Fausey, J. (1996), Introduction to Persistent Uniform Resource Locators, In Proceedings of INET96, Montreal, Canada, 24-28 June 1996.
[23] Slein, J., Vitali, F., Whitehead, J. and Durand, D. (1998), Requirements for a Distributed Authoring and Versioning Protocol for the World Wide Web, RFC 2291, February 1998.
[24] Sollins, K. (1998), Architectural Principles of Uniform Resource Name Resolution, RFC 2276, January 1998.
[25] Stein, G. (2001), Entry on WebDAV discussion forum by Greg Stein, May 2001, http://mailman.webdav.org/pipermail/neon/2001-May/000462.html
[26] Sun, S.X. and Lannom, L. (2000), The Handle System: A Persistent Global Name Service - Overview and Syntax, Internet-draft, draft-sun-handle-system-04.txt, February 2000.
[27] Thaler, D.G. and Ravishankar, C.V. (1998), Using Name Based Mappings to Increase Hit Rates, IEEE/ACM Transactions on Networking, 6(1), Feb. 1998.
[28] Valloppillil, V. and Ross, K.W. (1998) Cache Array Routing Protocol v1.0, Internet Draft, draft-vinod-carp-v1-02.txt, February 26, 1998.
[29] Whitehead, E.J. Jr., and Goland, Y.Y. (1999), WebDAV: A Network Protocol for Remote Collaborative Authoring on the Web, Proc. Sixth European Conference on Computer-Supported Cooperative Work, Sept. 12-16, 1999, Copenhagen, Denmark, pages 291-310.