|
Copyright is held by the author/owner(s).
WWW2002, May 7-11, 2002, Honolulu, Hawaii, USA.
ACM 1-58113-449-5/02/0005.
A program that makes an existing website look like a database is called a wrapper. Wrapper learning is the problem of learning website wrappers from examples. We present a wrapper-learning system that can exploit several different representations of a document. Examples of such different representations include DOM-level and token-level representations, as well as two-dimensional geometric views of the rendered page (for tabular data) and representations of the visual appearance of text as it will be rendered. Additionally, the learning system is modular, and can be easily adapted to new domains and tasks. The learning system described is part of an ``industrial-strength'' wrapper management system that is in active use at WhizBang Labs. Controlled experiments show that the learner has broader coverage and a faster learning rate than earlier wrapper-learning systems.
Many websites contain large quantities of highly structured, database-like information. It is often useful to be able to access these websites programmatically, as if they were true databases. A program that accesses an existing website and makes that website act like a database is called a wrapper. Wrapper learning is the problem of learning website wrappers from examples [16,22].
In this paper we will discuss some of the more important representational issues for wrapper learners, focusing on the specific problem of extracting text from web pages. We argue that pure DOM- or token-based representations of web pages are inadequate for the purpose of learning wrappers.
We then propose a learning system that can exploit multiple document representations. Additionally, this learning system is extensible: it can be easily ``tuned'' to a new domain by adding new learning components. In more detail, the system includes a single general-purpose ``master learning algorithm'' and a varying number of smaller, special-purpose ``builders'', each of which can exploit a different view of a document. Implemented builders make use of DOM-level and token-level views of a document; views that take more direct advantage of visual characteristics of rendered text, like font size and font type; and views that exploit a high-level geometric analysis of tabular information. Experiments show that the learning system achieves excellent results on real-world wrapping tasks, as well as on artificial wrapping tasks previously considered by the research community.
One important challenge faced in wrapper learning is picking the representation for documents that is most suitable for learning. Most previous wrapper learning systems represent a document as a linear sequence of tokens or characters [22,3]. Another possible scheme is to represent documents as trees, for instance using the document-object model (DOM). This representation is used by a handful of wrapper learning systems [7,6] and many wrapper programming languages (e.g, [27]).
Unfortunately, both of these representations are imperfect. In a website, regularities are most reliably observed in the view of the information seen by human readers-that is, in the rendered document. Since the rendering is a two-dimensional image, neither a linear representation nor a tree representation can encode it adequately.
One case in which this representational mismatch is important is the case of complex HTML tables. Consider the sample table of Figure 1. Suppose we wish to extract the third column of Figure 1. This set of items cannot easily be described at the DOM or token level: for instance, the best DOM-level description is probably ``td nodes such that the sum of the column width of all left-sibling td nodes is 2, where column width is defined by the colspan attribute if it is present, and is defined to be one otherwise.'' Extracting the data items in the first column is also complex, since one must eliminate the ``cut-in'' table cells (those labeled ``Actresses'' and ``Singers'') from that column. Again, cut-in table cells have a complex, difficult-to-learn description at the DOM level (``td nodes such that no right-sibling td node contains visible text'').
|
Another problemmatic case is illustrated by Figure 2. Here a rendering of a web page is shown, along with two possible HTML representations. In the first case, the HTML is very regular, and hence the artist names to be extracted can be described quite easily and concisely. In the second case, the underlying HTML is irregular, even though it has the same appearance when rendered. (Specifically, the author alternated between using the markup sequences ![]() i
i![]()
![]() bfoo/b
bfoo/b![]()
![]() /i
/i![]() and b
and b![]()
![]() i
i![]() bar
bar![]() /i
/i![]()
![]() /b
/b![]() in constructing italicized boldfaced text.) This sort of irregularity is unusual in pages that are created by database scripts; however, it is quite common in pages that are created or edited manually.
in constructing italicized boldfaced text.) This sort of irregularity is unusual in pages that are created by database scripts; however, it is quite common in pages that are created or edited manually.
In summary, one would like to be able to to concisely express concepts like ``all items in the second column of a table'' or ``all italicized boldfaced strings''. However, while these concepts can be easily described in terms of the rendered page, they may be hard to express in terms of a DOM- or token-level representation.
The remarks above are not intended to suggest that DOM and token representations are bad--in fact they are often quite good. We claim simply that neither is sufficient to successfully model all wrappers concisely. In view of this, we argue that an ideal wrapper-learning system will be able to exploit several different representations of a document--or more precisely, several different views of a single highly expressive baseline representation.
In this paper we will describe such a learning system, called the WhizBang Labs Wrapper Learner (WL![]() ). The basic idea in WL
). The basic idea in WL![]() is to express the bias of the learning system as an ordered set of ``builders''. Each ``builder'' is associated with a certain restricted language
is to express the bias of the learning system as an ordered set of ``builders''. Each ``builder'' is associated with a certain restricted language ![]() . However, the builder for
. However, the builder for ![]() is not a learning algorithm for
is not a learning algorithm for ![]() . Instead, to facilitate implementation of new ``builders'', a separate master learning algorithm handles most of the real work of learning, and builders need support only a small number of operations on
. Instead, to facilitate implementation of new ``builders'', a separate master learning algorithm handles most of the real work of learning, and builders need support only a small number of operations on ![]() . Builders can also be constructed by composing other builders in certain ways. For instance, two builders for languages
. Builders can also be constructed by composing other builders in certain ways. For instance, two builders for languages ![]() and
and ![]() can be combined to obtain builders for the language
, or the language
can be combined to obtain builders for the language
, or the language
![]() .
.
We will describe builders for several token-based, DOM-based, and hybrid representations, as well as for representations based on properties of the expected rendering of a document. Specifically, we will describe builders for representations based on the expected formatting properties of text nodes (font, color, and so on), as well as representations based on the expected geometric layout of tables in HTML.
|
We finally note that an extendible learner has other advantages. One especially difficult type of learning problem is illustrated by the example page of Figure 3, where the task is to extract ``office locations''. Only two examples are available, and there are clearly many generalizations of these, such as: ``extract all list items'', ``extract all list items starting with the letter P'', etc. However, not all generalizations are equally useful. For instance, if a new office in ``Mountain View, CA'' were added to the web page, some generalizations would extract it, and some would not.
In order to obtain the most desirable of the many possible generalizations of the limited training data, most previous wrapper-learning systems have been carefully crafted for the task. Another advantage of an extensible learning architecture is that it allows a wrapper-learning system to be tuned in a principled way.
We will begin with a general scheme for describing subsections of a document, and then define languages based on restricted views of this general scheme.
We assume that structured documents are represented with the document object model (DOM). (For pedagogical reasons we simplify this model slightly in our presentation.) A DOM tree is an ordered tree, where each node is either an element node or a text node. An element node has an ordered list of zero or more child nodes, and contains a string-valued tag (such as table, h1, or li) and also zero more string-valued attributes (such as href or src). A text node is normally defined to contain a single text string, and to have no children. To simplify the presentation, however, we will assume that a text node containing a string ![]() of length
of length ![]() will have ``character node'' children, one for each character in
will have ``character node'' children, one for each character in ![]() .
.
Items to be extracted from a DOM tree are represented as spans. A span consists of two span boundaries, a right boundary and a left boundary. Conceptually, a boundary corresponds to a position in the structured document. We define a span boundary to be a pair (,![]() ), where
), where ![]() is a node and
is a node and ![]() is an integer. A span boundary points to a spot between the
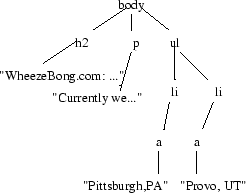
is an integer. A span boundary points to a spot between the ![]() -th and the -th child of . For example, if is the rightmost text node in Figure 4, then
-th and the -th child of . For example, if is the rightmost text node in Figure 4, then ![]() is before the first character of the word ``Provo'', and is after the last character of the word ``Provo''. The span with left boundary
is before the first character of the word ``Provo'', and is after the last character of the word ``Provo''. The span with left boundary ![]() and right boundary
and right boundary ![]() corresponds to the text ``Provo''.
corresponds to the text ``Provo''.
As another example, if ![]() is the leftmost li node in Figure 4, then the span from
is the leftmost li node in Figure 4, then the span from ![]() to
to ![]() contains the text ``Pittsburgh, PA''. It also corresponds to a single DOM node, namely, the leftmost anchor (a) node in the DOM tree. A span that corresponds to a single DOM node is called a node span.
contains the text ``Pittsburgh, PA''. It also corresponds to a single DOM node, namely, the leftmost anchor (a) node in the DOM tree. A span that corresponds to a single DOM node is called a node span.
A predicate ![]() is a binary relation on spans. To execute a predicate
is a binary relation on spans. To execute a predicate ![]() on span
on span ![]() means to compute the set
means to compute the set
![]() . For example, consider a predicate
. For example, consider a predicate ![]() which is defined to be true iff (a)
which is defined to be true iff (a) ![]() contains
contains ![]() , and (b) is a node span corresponding to an element node with tag li. Let
, and (b) is a node span corresponding to an element node with tag li. Let ![]() be a span encompassing the entire document of Figure 4. Then
be a span encompassing the entire document of Figure 4. Then
![]() contains two spans, each corresponding to an li node in the DOM tree, one containing the text ``Pittsburgh, PA'', and one containing the text ``Provo, UT''.
contains two spans, each corresponding to an li node in the DOM tree, one containing the text ``Pittsburgh, PA'', and one containing the text ``Provo, UT''.
We will assume here that every predicate is one-to-many and that membership in a predicate can be efficiently decided (i.e., given two spans ![]() and
and ![]() , one can easily test if
, one can easily test if ![]() is true.) We also assume that predicates are executable--i.e., that
is true.) We also assume that predicates are executable--i.e., that
![]() can be efficiently computed for any initial span
can be efficiently computed for any initial span ![]() . The extraction routines learned by our wrapper induction system are represented as executable predicates. Since predicates are simply sets, it is possible to combine predicates by Boolean operations like conjunction or disjunction; similarly, one can naturally say that predicate
. The extraction routines learned by our wrapper induction system are represented as executable predicates. Since predicates are simply sets, it is possible to combine predicates by Boolean operations like conjunction or disjunction; similarly, one can naturally say that predicate ![]() is ``more general than'' predicate
is ``more general than'' predicate ![]() .
.
We note that these semantics can be used for many commonly used extraction languages, such as regular expressions and XPath queries.![[*]](../../CDROM/refereed/355/footnote.png) Many of the predicates learned by the system are stored as equivalent regular expressions or XPath queries.
Many of the predicates learned by the system are stored as equivalent regular expressions or XPath queries.
A wrapper induction system is typically trained by having a user identify items that should be extracted from a page. Since it is inconvenient to label all of a large page, a user should have the option of labeling some initial section of a page. To generate negative data, it is assumed that the user completely labeled the page or an initial section of it.
A training set ![]() for our system thus consists of a set of triples
for our system thus consists of a set of triples
![]() ,
,
![]() , ..., where in each pair
, ..., where in each pair ![]() is usually a span corresponding to a web page,
is usually a span corresponding to a web page, ![]() is the part of
is the part of ![]() that the user has completely labeled, and
that the user has completely labeled, and
![]() is the set of all spans that should be extracted from
is the set of all spans that should be extracted from ![]() .
.
Constructing positive data from a training set is trivial. The positive examples are simply all pairs
![]() . When it is convenient we will think of
. When it is convenient we will think of ![]() as this set of pairs.
as this set of pairs.
While it is not immediately evident how negative data can be constructed, notice that any hypothesized predicate ![]() can be tested for consistency with a training set
can be tested for consistency with a training set ![]() by simply executing it on each outer span in the training set. The spans in the set
by simply executing it on each outer span in the training set. The spans in the set
![]() are false negative predictions for
are false negative predictions for ![]() , and the false positive predictions for
, and the false positive predictions for ![]() are spans
are spans ![]() in the set
in the set
The bias of the learning system is represented by an ordered list of builders. Each builder ![]() corresponds to a certain restricted extraction language . To give two simple examples, consider these restricted languages:
corresponds to a certain restricted extraction language . To give two simple examples, consider these restricted languages:
For example, executing the predicate
![]() on the span for the document of Figure 3 would produce a single span containing the text ``two''.
on the span for the document of Figure 3 would produce a single span containing the text ``two''.
![]() is one example of a language based on viewing the document as a sequence of tokens.
is one example of a language based on viewing the document as a sequence of tokens.
For example, executing the predicate
![]() on the span for the document of Figure 3 would produce the two spans ``Pittsburgh, PA'' and ``Provo, UT''.
on the span for the document of Figure 3 would produce the two spans ``Pittsburgh, PA'' and ``Provo, UT''.
![]() is an example of a language based viewing the document as a DOM.
is an example of a language based viewing the document as a DOM.
Each builder ![]() must implement two operations. A builder must be able to compute the least general generalization (LGG) of a training set
must implement two operations. A builder must be able to compute the least general generalization (LGG) of a training set ![]() with respect to
with respect to ![]() --i.e., the most specific concept
--i.e., the most specific concept ![]() that covers all positive training examples in
that covers all positive training examples in ![]() . Given an LGG concept
. Given an LGG concept ![]() and a training set
and a training set ![]() , a builder must also be able to refine
, a builder must also be able to refine ![]() with respect to
with respect to ![]() --i.e., to compute a set of concepts
--i.e., to compute a set of concepts
![]() such that each
such that each ![]() covers some but not all of the positive examples
covers some but not all of the positive examples
![]() .
.
Below we will write these operations as
![]() and
and
![]() . We will also assume that there is a special ``top predicate'', written ``
. We will also assume that there is a special ``top predicate'', written ``
![]() '', which is always true (and hence is not executable.)
'', which is always true (and hence is not executable.)
Other builders will be described below, in Sections 4.1, 4.2, and 4.3.
|
The master learning algorithm used in WL![]() is shown in Figure 5. It takes two inputs: a training set
is shown in Figure 5. It takes two inputs: a training set ![]() , and an ordered list of builders. The algorithm is based on FOIL [24,26] and learns a DNF expression, the primitive elements of which are predicates. As in FOIL, the outer loop of the learning algorithm (the learnPredicate function) is a set-covering algorithm, which repeatedly learns a single ``rule''
, and an ordered list of builders. The algorithm is based on FOIL [24,26] and learns a DNF expression, the primitive elements of which are predicates. As in FOIL, the outer loop of the learning algorithm (the learnPredicate function) is a set-covering algorithm, which repeatedly learns a single ``rule'' ![]() (actually a conjunction of builder-produced predicates) that covers some positive data from the training set, and then removes the data covered by
(actually a conjunction of builder-produced predicates) that covers some positive data from the training set, and then removes the data covered by ![]() . The result of learnPredicate is the disjunction of these ``rules''.
. The result of learnPredicate is the disjunction of these ``rules''.
The inner loop (the learnConjunction function) first
evaluates all LGG predicates constructed by the builders. If any LGG
is consistent with the data, then that LGG is returned. If more than
one LGG is consistent, then the LGG produced by the earliest builder
is returned. If no LGG is consistent, the ``best'' one is chosen as a
the first condition in a ``rule''. Executing this ``best'' predicate
yields a set of spans, some of which are marked as positive in ![]() , and some of which are negative. From this point
the learning process is quite conventional: the rule is specialized by
greedily conjoining builder-produced predicates together. The
predicate choices made in the inner loop are guided by the same
information-gain metric used in FOIL.
, and some of which are negative. From this point
the learning process is quite conventional: the rule is specialized by
greedily conjoining builder-produced predicates together. The
predicate choices made in the inner loop are guided by the same
information-gain metric used in FOIL.
There are several differences between this learning algorithm and FOIL. One important difference is the initial computation of 's using each of the builders. In many cases some builder's ![]() is consistent, so often the learning process is quite fast. Builders are also used to generate primitive predicates in the learnConjunction function, instead of instead of testing all possible primitive predicates as FOIL does. This is useful since there are some languages that are difficult to learn using FOIL's top-down approach. Extensive use of the
is consistent, so often the learning process is quite fast. Builders are also used to generate primitive predicates in the learnConjunction function, instead of instead of testing all possible primitive predicates as FOIL does. This is useful since there are some languages that are difficult to learn using FOIL's top-down approach. Extensive use of the ![]() operation also tends to make learned rules fairly specific. This is advantageous in wrapper-learning since when a site changes format, it is usually the case that old rules will simply fail to extract any data; this simplifies the process of ``regression testing'' for wrappers [15].
operation also tends to make learned rules fairly specific. This is advantageous in wrapper-learning since when a site changes format, it is usually the case that old rules will simply fail to extract any data; this simplifies the process of ``regression testing'' for wrappers [15].
Another difference is that WL![]() uses the ordering of the builders to prioritize the primitive predicates. Predicates generated by earlier builders are preferred to later ones, if their information gains are equal. Notice that because there are very few positive examples, there are many ties in the information-gain metric.
uses the ordering of the builders to prioritize the primitive predicates. Predicates generated by earlier builders are preferred to later ones, if their information gains are equal. Notice that because there are very few positive examples, there are many ties in the information-gain metric.
A final difference is the way in which negative data is generated. In our algorithm, negative data is generated after the first predicate of a ``rule'' is chosen, by executing the chosen predicate and comparing the results to the training set. After this generation phase, subsequent hypothesis predicates can be tested by simply matching them against positive and negative example pairs--a process which is usually much more efficient than execution.
A number of recent extraction systems work by generating and classifying candidate spans (e.g., [9,10]). Using ![]() predicates to generate negative data is an variant of this approach: essentially, one
predicates to generate negative data is an variant of this approach: essentially, one ![]() predicate is selected as a candidate span generator, and subsequent predicates are used to filter these candidates.
predicate is selected as a candidate span generator, and subsequent predicates are used to filter these candidates.
Certain other extraction systems cast extraction as an automata induction problem [11,3]. As noted above, this sort of approach requires a commitment to one particular sequential view of the document--as a sequence of tokens. The approach taken here is somewhat more flexible, in that the document can be viewed (by different builders) as a DOM tree or as a token sequence.
Many of the ideas used in this learning system are adapted from work in inductive logic programming (ILP) [20,8]. In particular, the approach of defining bias via a set of builders is reminiscent of earlier ILP work in declarative bias [5,1]. The hybrid top-down/bottom-up learning algorithm is also broadly similar to some earlier ILP systems like CHILL [30]. The approach taken here avoids the computational complexities involved in ILP, while keeping much of the expressive power. We also believe that this approach to defining a learning system's bias is easier to integrate into a production environment than an approach based on a purely declarative bias language.
The builders described above are examples of primitive builders. It is also possible to construct new builders by combining other builders. In fact, one reason for using the only the ![]() and
and ![]() operations in builders is that
operations in builders is that ![]() and
and ![]() can often be defined compositionally.
can often be defined compositionally.
|
One useful composite builder is a chain builder. Given two builders
![]() and
and
![]() , a chain builder learns (roughly) the composition of
, a chain builder learns (roughly) the composition of ![]() and
and ![]() .
.
For efficiency reasons we implemented a slightly restricted form of builder composition. A chain builder is a composite builder based on two builders and a user-provided decomposition function ![]() . Intuitively, the decomposition function takes as an argument the span
. Intuitively, the decomposition function takes as an argument the span ![]() to be extracted and returns an intermediate span
to be extracted and returns an intermediate span ![]() : i.e.,
: i.e., ![]() . The chain builder will learn concepts
. The chain builder will learn concepts ![]() of the form
of the form
Given the decomposition function ![]() , it is straightforward to define the necessary operations for a chain builder
, it is straightforward to define the necessary operations for a chain builder
![]() for two builders
for two builders ![]() and
and ![]() .
.
Given these training sets, one can next use ![]() and
and ![]() to compute the
to compute the ![]() for the composition. Let
and
for the composition. Let
and
![]() . Then
is
. Then
is ![]() , where the set
, where the set ![]() is simply the set defined in Eq. 2.
is simply the set defined in Eq. 2.
Another combination is conjunction. Given builders ![]() and
and ![]() , it is straightforward to define a builder
, it is straightforward to define a builder
![]() for the language of predicates of the form
for the language of predicates of the form
![]() such that
such that ![]() and
and ![]() .
.
Another useful composite builder is a filtered builder. A filtered builder
![]() extends a builder
extends a builder ![]() with an arbitrary training set query
with an arbitrary training set query ![]() , and is defined as follows, where
, and is defined as follows, where ![]() is a special null concept.
is a special null concept.
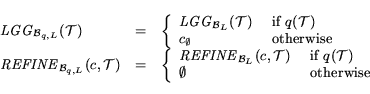
The following examples help illustrate how composite builders might be used.
Example 1. Let
![]() return the span corresponding to the smallest DOM node that contains
return the span corresponding to the smallest DOM node that contains ![]() . Chaining together
. Chaining together
![]() and
and
![]() using the decomposition function
using the decomposition function
![]() is a new and more expressive extraction language. For instance, let the strings
is a new and more expressive extraction language. For instance, let the strings ![]() and
and ![]() represent left and right parentheses, respectively. For the page of Figure 6, the composite predicate
represent left and right parentheses, respectively. For the page of Figure 6, the composite predicate
![]() would extract the locations from the job descriptions. Notice that
would extract the locations from the job descriptions. Notice that ![]() alone would also pick out the area code ``888''.
alone would also pick out the area code ``888''.
Example 2. Let
![]() return the first ``small'' text node preceding
return the first ``small'' text node preceding ![]() (for some appropriate definition of ``small''), and let
(for some appropriate definition of ``small''), and let ![]() be a language of bag-of-words classifiers for DOM nodes. For example,
be a language of bag-of-words classifiers for DOM nodes. For example, ![]() might include concepts like
might include concepts like
![]() ``
``![]() contains
contains ![]() and
and ![]() contains the words `job' and `title'.'' Let
contains the words `job' and `title'.'' Let ![]() contain classifiers that test the distance in the DOM tree between the nodes corresponding to
contain classifiers that test the distance in the DOM tree between the nodes corresponding to ![]() and
and ![]() . For example,
. For example, ![]() might include concepts like
might include concepts like
![]() ``there are between 1 and 3 nodes between
``there are between 1 and 3 nodes between ![]() and
and ![]() (in a postfix traversal of the tree)''.
(in a postfix traversal of the tree)''.
Chaining together
![]() and
and
![]() using the decomposition function
using the decomposition function
![]() would lead to a builder that learns concepts such as the following
would lead to a builder that learns concepts such as the following ![]() :
:
For the sample page in Figure 6, this predicate might pick out the table cell containing the text: ``Send c.v. via e-mail...''.
is the first text node preceding
that contains three or fewer words;
contains the words ``To'' and ``apply'';
is between 1 and 4 nodes after
, and
is reached from
by a tagpath ending in
.
Figure 2 illustrates an important problem with DOM-based representations: while regularity in the DOM implies a regular appearance in the rendered document, regular documents may have very irregular DOM structures. In the figure, the markup sequences ![]() i
i![]()
![]() b
b![]() foo
foo![]() /b
/b![]() /i
/i![]() and
and ![]() b
b![]()
![]() i
i![]() foo
foo![]() /i
/i![]()
![]() /b both produce italicized boldfaced text, but have different token- and DOM-level representations. Alternating between them will lead to a document that is regular in appearance but irregular in structure. Our experience is that this sort of problem is quite common in small-to-medium sized web sites, where much of the content is hand-built or hand-edited.
/b both produce italicized boldfaced text, but have different token- and DOM-level representations. Alternating between them will lead to a document that is regular in appearance but irregular in structure. Our experience is that this sort of problem is quite common in small-to-medium sized web sites, where much of the content is hand-built or hand-edited.
Our solution to this problem is to construct builders that rely more directly on the appearance of rendered text. We achieve this with a mixture of document preprocessing and reasoning at learning time.
In a preprocessing stage, HTML is ``normalized'' by applying a number of transformations. For instance, the strong tag is replaced by the b tag, em is replaced by i tag, and constructs like font=+1 are replaced by font=![]() (where
(where ![]() is the appropriate font-size based on the context of the node.) This preprocessing makes it possible to compute a number of ``format features'' quickly at each node that contains text. Currently these features include properties like font size, font color, font type, and so on.
is the appropriate font-size based on the context of the node.) This preprocessing makes it possible to compute a number of ``format features'' quickly at each node that contains text. Currently these features include properties like font size, font color, font type, and so on.
A special builder then extracts nodes using these features. These properties are treated as binary features (e.g.,, the property ``font-size=3'' is treated as a Boolean condition ``fontSizeEqualsThree=true''). The format builder then produces as its ![]() the largest common set of Boolean format conditions found for the inner spans in its training set. Refinement is implemented by adding a single feature to the
the largest common set of Boolean format conditions found for the inner spans in its training set. Refinement is implemented by adding a single feature to the ![]() set.
set.
Consider again the sample tables in Figure 1. We would like to provide the learner with the ability to form generalizations based on the geometry of the tables, rather than their HTML representation. This is important since text strings that are nearby in the rendered image (and thus likely to be closely related) need not be nearby in the HTML encoding.
The first step in doing this is to recognize ``interesting'' tables in a document. Specifically, we are interested in collections of data elements in which semantic relationships between these elements are indicated by geometric relationships--either horizontal or vertical alignment. These ``interesting'' tables must be distinguished from other uses of the HTML table element. (In HTML, tables are also used for arbitrary formatting purposes, for instance, to format an array of images.) For more detailed discussion refer to Hurst [13] or Wang [29].
To recognize this class of tables, we used machine learning techniques. Specifically, we learned to classify HTML table nodes as data tables (``interesting'' tables) and non-data tables.
We explored two types of features: those derived directly from the DOM view of the table, and those derived from an abstract table model built from the table. (The abstract table model is described below). The best classifier contains only the abstract table model features, which are: the number of rows and columns (discretized into the ranges 1, 2, 3, 4, 5, 6--10, and 11+); the proportion of cells with string content; and the proportion of singular cells. A singular cell is a cell which has unit size in terms of the logical grid on which the table is defined.
We collected a sample of 339 labeled examples. To evaluate performance, we averaged five trials in which 75% of the data was used for training and the remainder for testing. We explored several learning algorithms including multinomial Naive Bayes [17,19], Maximum Entropy [23], Winnow [18,2], and a decision tree learner modeled after C4.5 [25]. Of these, the Winnow classifier performs the best with a precision of 1.00, a recall 0.922, and an F-measure of 0.959.
Table classification is not only the first step in table processing: it is also useful in itself. There are several builders that are more appropriate to apply outside a table than inside one, or vice versa. One example is builders like that of Example 2 in Section 4.1, which in Figure 6 learns to extract text shortly after the phrase ``To apply:''. This builder generally inappropriate inside a table--for instance, in Figure 1, it is probably not correct to generalize the example ``Lawless'' to ``all tables cells appearing shortly after the string `Lucy'''.
A number of builders in WL![]() work like the builder of Example 2, in that the extraction is driven primarily by some nearby piece of text. These builders are generally restricted to apply only when they are outside a data table. This can be accomplished readily with filtered builders.
work like the builder of Example 2, in that the extraction is driven primarily by some nearby piece of text. These builders are generally restricted to apply only when they are outside a data table. This can be accomplished readily with filtered builders.
More complex use of tables in wrapper-learning requires knowledge of the geometry of the rendered table. To accomplish this, we construct an abstract geometric model of each data table. In an abstract geometric model, a table is assumed to lie on a grid, and every table cell is assumed to be a contiguous rectangle on the grid. An abstract table model is thus a set of cells, each of which is defined by the co-ordinates of the upper-left and lower-right corners, and a representation of the cell's contents. In the case of HTML tables, the contents are generally a single DOM node.
Since we aim to model the table as perceived by the reader, a table model cannot be generated simply by rendering the table node following the algorithm recommended by W3C [12]. Further analysis is required in order to capture additional table-like sub-structure visible in the rendered document. Examples of this type of structure include nested table elements, rows of td elements containing aligned list elements, and so on. Our table modeling system thus consists of several steps.
First, we generate a table model from a table node using a variation of the algorithm recommended by W3C. We then refine the resulting table model in the following ways.
To exploit the geometric view of a table that is encapsulated in an abstract table model, we choose certain properties to export to the learning system. Our goal was to choose a small but powerful set of features that could be unambiguously derived from tables. More powerful features from different aspects of the abstract table model were also considered, such as the classification of cells as data cells or header cells--however, determining these features would require a layer of classification and uncertainty, which complicates their use in wrapper-learning.
To export the table features to WL![]() , we used the following procedure. When a page is loaded into the system, each table node is annotated with an attribute indicating the table's classification as a data table or non-table table. Each node in the DOM that acts as a cell in an abstract table is annotated with its logical position in the table model; this is expressed as two ranges, one for column position and one for row position. Finally, each tr node is annotated with an attribute indicating whether or not it contains a ``cut-in'' cell (like the ``Actresses'' and ``Singers'' cells in Figure 1.)
, we used the following procedure. When a page is loaded into the system, each table node is annotated with an attribute indicating the table's classification as a data table or non-table table. Each node in the DOM that acts as a cell in an abstract table is annotated with its logical position in the table model; this is expressed as two ranges, one for column position and one for row position. Finally, each tr node is annotated with an attribute indicating whether or not it contains a ``cut-in'' cell (like the ``Actresses'' and ``Singers'' cells in Figure 1.)
Currently this annotation is done by adding attributes directly to the DOM nodes. This means that builders can easily model table regularities by accessing attributes in the enriched, annotated DOM tree. Currently four types of ``table builders'' are implemented. The cut-in header builder represents sets of nodes by their DOM tag, and the bag of words in the preceding cut-in cell. For example, in the table of Figure 1, the bag of words ``Actresses'' and the tag td would extract the strings ``Lucy'', ``Lawless'', ``images'', ``links'', ``Angelina'', ``Jolie'', and so on. The column header builder and the row header builder are analogous. The fourth type of table builder is an extended version of the builder for the
![]() language, in which tagpaths are defined by a sequence of tags augmented with the values of the attributes indicating geometric table position and if a row is a cut-in. As an example, the ``extended tagpath''
language, in which tagpaths are defined by a sequence of tags augmented with the values of the attributes indicating geometric table position and if a row is a cut-in. As an example, the ``extended tagpath''
table,tr(cutIn=`no'),td(colRange=`2-2')would extract the strings ``Lawless'', ``Jolie'', ``Spears'' (but not ``Madonna'', because her geometric column co-ordinates are ``1-2'', not ``2-2''.) Finally, the conjunction of this extended tagpath and the example cut-in expression above would extract only ``Lawless'' and ``Jolie''.
To evaluate the learning system, we conducted a series of experiments. The first set of experiments compare WL![]() with previous wrapper-learning algorithms.
with previous wrapper-learning algorithms.
The discussion in this paper has been restricted to ``binary extraction tasks'', by which we mean tasks in which a yes/no decision is made for each substring in the document, indicating whether or not that substring should be extracted. There are several existing schemes for decomposing the larger problem of wrapping websites into a series of binary extraction problems [22,14]. WL![]() is embedded in one such system. Thus, the basic evaluation unit is a ``wrapper-learning problem'', which can be broken into a set of ``binary extraction problems''.
is embedded in one such system. Thus, the basic evaluation unit is a ``wrapper-learning problem'', which can be broken into a set of ``binary extraction problems''.
Muslea et al [21] provide a detailed comparison of STALKER and WIEN on a set of four sample wrapper-learning problems. STALKER [21] is a wrapper-learning system which learns wrappers expressed as ``landmark automata''. WEIN [16] is an earlier wrapper-learning system. The sample problems were chosen as representative of the harder extraction problems to which WIEN was applied.
In the experiments of Muslea et al, STALKER is repeatedly run on a sample of ![]() labeled records, for
labeled records, for ![]() , and then tested on all remaining labeled records. The process of gradually incrementing
, and then tested on all remaining labeled records. The process of gradually incrementing ![]() was halted when the wrapper's average accuracy is 97% or better (averaging over the different samples of
was halted when the wrapper's average accuracy is 97% or better (averaging over the different samples of ![]() training examples). The value of
training examples). The value of ![]() shown in the column labeled ``STALKER(
shown in the column labeled ``STALKER(![]() )'' of Table 1 shows the number of examples required for STALKER to achieve 97% accuracy. (This value is taken from Muslea et al.) The value of shown in the column labeled WIEN(
)'' of Table 1 shows the number of examples required for STALKER to achieve 97% accuracy. (This value is taken from Muslea et al.) The value of shown in the column labeled WIEN(![]() ) is Muslea et al's estimate of the number of examples needed by WIEN to learn an exact (100% accurate) wrapper. Note that neither WIEN nor STALKER successfully learns wrappers for problems S3 and S4.
) is Muslea et al's estimate of the number of examples needed by WIEN to learn an exact (100% accurate) wrapper. Note that neither WIEN nor STALKER successfully learns wrappers for problems S3 and S4.
To perform the same flavor of evaluation, we ran WL![]() on the same four problems. We wish to emphasize that WL
on the same four problems. We wish to emphasize that WL![]() was developed using completely different problems as benchmarks, and hence these problems are a fair prospective test of the system. In the column labeled ``WL
was developed using completely different problems as benchmarks, and hence these problems are a fair prospective test of the system. In the column labeled ``WL![]() (
(![]() )'', we show the number of examples
)'', we show the number of examples ![]() required to obtain perfect accuracy on every binary extraction problems associated with a wrapper-learning task. Unlike Muslea et al we did not average over multiple runs: however, informal experiments suggest that performance of WL
required to obtain perfect accuracy on every binary extraction problems associated with a wrapper-learning task. Unlike Muslea et al we did not average over multiple runs: however, informal experiments suggest that performance of WL![]() is quite stable if different subsets of the training data are used.
is quite stable if different subsets of the training data are used.
Although no result is not shown in the table, WL![]() can also be used to learn approximate wrappers. On these problems, WL
can also be used to learn approximate wrappers. On these problems, WL![]() learns 95%-accurate wrappers from only two examples for all of the problems from Muslea et al but one. The most ``difficult'' problem is S2, which requires six examples to find even an approximate wrapper. This is due to the fact that many fields on this web page are optional, and it requires several records before every field has been seen at least once.
learns 95%-accurate wrappers from only two examples for all of the problems from Muslea et al but one. The most ``difficult'' problem is S2, which requires six examples to find even an approximate wrapper. This is due to the fact that many fields on this web page are optional, and it requires several records before every field has been seen at least once.
 |
|
 |
We now turn to some more additional benchmark problems. Table 2 gives the performance of WL![]() on several real-world wrapper-learning problems, taken from two domains for which WL has been used internally at WhizBang Labs. The first seven problems are taken from the domain of job postings. The last six problems are taken from the domain of continuing education courses. These problems were selected as representative of the more difficult wrapping problems encountered in these two domains. Each of these problems contains several binary extraction problems--a total of 34 problems all told.
on several real-world wrapper-learning problems, taken from two domains for which WL has been used internally at WhizBang Labs. The first seven problems are taken from the domain of job postings. The last six problems are taken from the domain of continuing education courses. These problems were selected as representative of the more difficult wrapping problems encountered in these two domains. Each of these problems contains several binary extraction problems--a total of 34 problems all told.
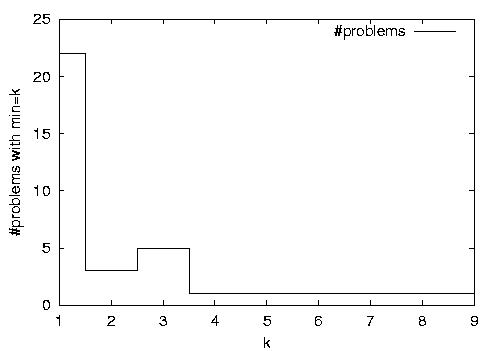
Along with each problem we record the minimum number of labeled records needed to learn a wrapper with 100% accuracy. The largest number of examples needed is nine (for one field of an extremely irregular site) and the median number of examples is between 2 and 3. Figure 8 gives some additional detail: it plots the number of field-extraction problems that required a minimum of ![]() labeled records, for value of
labeled records, for value of ![]() . About two-thirds of the binary extraction problems could be learned with one example, and about four-fifths could be learned with three examples.
. About two-thirds of the binary extraction problems could be learned with one example, and about four-fifths could be learned with three examples.
In some cases, it is useful to obtain approximate wrappers, as well as perfect ones. To measure the overall quality of wrappers, we measured the recall and precision of the wrappers learned for each problem from ![]() examples, for
examples, for ![]() 1, 2, 3, 5, 10, 15, and 20. Recall and precision were measured by averaging across all individual field extraction problems associated with a wrapper-learning task. The learning system we use is strongly biased toward high-precision rules, so precision is almost always perfect, but recall varies from problem to problem. We then plotted the average F-measure across all problems as a function of .
1, 2, 3, 5, 10, 15, and 20. Recall and precision were measured by averaging across all individual field extraction problems associated with a wrapper-learning task. The learning system we use is strongly biased toward high-precision rules, so precision is almost always perfect, but recall varies from problem to problem. We then plotted the average F-measure across all problems as a function of .
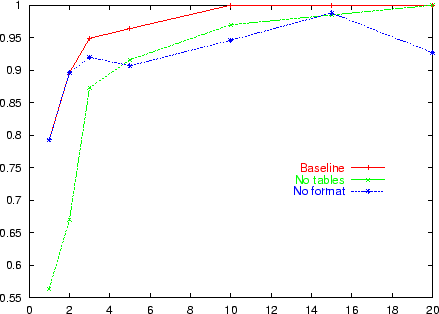
Figure 7 shows these curves for the baseline WL system on the real-world wrapping tasks of Table 2. The curves marked ``no format'' and ``no tables'' show the performance of two restricted versions of the system: a version without the format-oriented builders of Section 4.2, and a version without the table-oriented builders of Section 4.3. These curves indicate a clear benefit from using these special builders.
To summarize, we have argued that pure DOM- or token-based representations of web pages are inadequate for wrapper learning. We propose instead a wrapper-learning system called WL![]() that can exploit multiple document representations. WL
that can exploit multiple document representations. WL![]() is part of an ``industrial-strength'' wrapper management system that is in active use at WhizBang Labs. Controlled experiments show that the learning component performs well. Lesion studies show that the more exotic builders do indeed improve performance on complex wrapper-learning tasks, and experiments on artificial data suggest that the system has broader coverage and a faster learning rate than two earlier wrapper-learning systems, WEIN [16] and STALKER [21,22].
is part of an ``industrial-strength'' wrapper management system that is in active use at WhizBang Labs. Controlled experiments show that the learning component performs well. Lesion studies show that the more exotic builders do indeed improve performance on complex wrapper-learning tasks, and experiments on artificial data suggest that the system has broader coverage and a faster learning rate than two earlier wrapper-learning systems, WEIN [16] and STALKER [21,22].
The system includes a single general-purpose master learning algorithm and a varying number of smaller, special-purpose ``builders'', which can exploit different views of a document. Implemented builders make use of both DOM-level and token-level views of a document. More interestingly, builders can also exploit other properties of documents. Special format-level builders exploit visual characteristics of text, like font size and font type, that are not immediately accessible from conventional views of the document. Special ``table builders'' exploit information about the two-dimensional geometry of tabular data in a rendered web page.
The learning system can exploit any of these views. It can also learn extractors that rely on multiple views (e.g., ``extract all table `cut-in' cells that will be rendered in blue with a font size of 2''). Another advantage of the learning system's architecture is that since builders can be added and removed easily, the system is extensible and modular, and hence can be easily adapted to new wrapping tasks.
The authors thank Rich Hume, Rodney Riggs, Dallan Quass, and many of their other colleagues at WhizBang! for contributions to this work.