ABSTRACT
The
OpenVXI is a portable open source based toolkit that interprets the VoiceXML
dialog markup language. It is designed to serve as a framework for system
integrators and platform vendors who want to incorporate VoiceXML into their
platform. A first version of the toolkit was released in the winter of 2001,
with a second version released in September of 2001. A number of companies and
individuals have adopted the toolkit for their platforms. In this paper we
discuss the architecture of the toolkit, the architectural issues involved with
implementing a framework for VoiceXML, performance results with the OpenVXI,
and future directions for the toolkit.
Categories and Subject Descriptors
H.5.2 [Voice I/O]: User Interfaces (D.2.2, H.1.2, I.3.6) – Voice I/O.
General Terms
Design, Standardization, Languages
Keywords
VoiceXML, OpenVXI
1. INTRODUCTION
The W3C released a draft of VoiceXML 2.0 in Fall, 2001. VoiceXML 2.0 is a speech dialog description language that allows developers to write voice applications in a way that is analogous to writing a web application. Developers write server side applications that output VoiceXML 2.0. The VoiceXML 2.0 script is then rendered on a voice browser that understands the language.
The power of VoiceXML is that it standardizes voice application development by leveraging the full set of available web development tools and techniques. For example, developers can write a single server-side program that can be used to display stock quotes on the web or read-back stock quotes over the phone. This program would use the same backend code for getting the quotes, but would have code for two user interfaces one for speech and one for HTML.
We expect that this mechanism will lead to a convergence of HTML development with companies that do voice development. Multi-modal devices with speech and text input and display and speech output will accelerate this convergence.
Converged application development would have a number of advantages for application users because the visual and voice interfaces could share a common set of functionality and a common language. This would lead to a common usage model for the user and increased user efficiencies since both interfaces would exploit the same words and offer similar capabilities.
In order to accelerate this convergence and expand the availability of VoiceXML interfaces, SpeechWorks released OpenVXI 2.0 in
|
Copyright is held by the author/owner(s). WWW 2002, May 7-11, 2002, Honolulu,
Hawaii, USA. Copyright 2002 ACM
1-58113-449-5/02/0005…$5.00. |
September 2001. This is an open source VoiceXML implementation that covers most of VoiceXML 2.0. This was a major release update from OpenVXI 1.4, the previous April 2001 release. Since the release, there have been over 1000 downloads of the 1.4 release and over 500 downloads of the 2.0 release. The mailing group shows that there is great interest in incorporating the OpenVXI into new platforms for VoiceXML 2.0.
In this paper we cover the architecture of the OpenVXI. We highlight some of the architectural decisions and issues that we resolved in developing the software, and finally we discuss the issues that arise when using the OpenVXI to implement a VoiceXML browser.
2. ARCHITECTURE
A VoiceXML browser is a server that takes one or more input telephone calls on a telephony platform and executes an application that lives on one or more web servers by interpreting VoiceXML markup. In the case of VoiceXML 2.0, the application consists of the call-flow logic, the prompts for the application, and any associated speech grammars (See figure 1). The VoiceXML browser renders the VoiceXML markup within an interpreter context, perhaps changing the context, and then makes calls into the implementation platform. The implementation platform contains all of the resources needed by the markup interpreter to render the dialog.
Figure 1 shows the components of a VoiceXML system. When a call is received it is detected by the implementation platform. The platform sends an event to the markup interpreter, which looks in its context for the URI of the initial document to fetch. The interpreter then sends a Request to the Document Server for the initial document. The Document Server then sends the document back to the Markup Interpreter that then instructs the Implementation Platform on the first steps to perform on behalf of the caller. The Markup Interpreter then interprets the result of an execution in the Implementation Platform. The interpretation may result in the Markup Interpreter making additional document requests to the Document Server.
The figure also shows the system architecture where the OpenVXI is integrated onto a platform by adding recognition, text-to-speech technology and platform monitoring, administration, and hardware functionality. This integrated platform receives VoiceXML pages from a document server. The document server consists of a web server, potentially an application framework, and a VoiceXML application. The VoiceXML application can be one or more VoiceXML files, or these files can be dynamically generated using CGI scripts or other computations.
|
Figure 1: OpenVXI System Architecture |
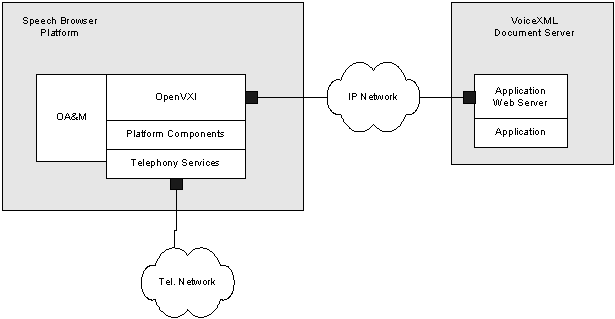
The speech browser platform executes the VoiceXML pages to provide the speech service to the caller connected over the telephone network. The Client logically consists of four parts:
1. An operations administration and maintenance (OA&M) system and main process.
This collection of tools is responsible for system management and error reporting. This critical component also invokes the speech browser within a thread it creates to begin execution.
2. The OpenVXI.
This is the component that interprets the VoiceXML markup and calls into the implementation platform to render the markup.
3. The platform.
The platform provides the services necessary for the system to run. The OpenVXI software specifies platform APIs and services that must be implemented in order for the system to function. The APIs do not define the mechanism for communication between the implementation of the API and the underlying speech technology engines. This could be done using client/server or direct communication. Generally the most important service provided by the platform is call management and call event handling.
4. The hardware and base services.
The hardware and base services layer contains the base operating system services and the hardware needed to receive phone calls. The OpenVXI does not provide an API for this level, and is agnostic to this part of the implementation.
3. OPENVXI TOOLKIT FUNCTIONALITY
Figure 2 shows the OpenVXI toolkit architecture and its component parts. All components are designed to be portable across WINDOWS and Unix operating systems. The OpenVXI currently compiles on RedHat 6.2, RedHat 7.1, Solaris 7, Mac OS X, and WINDOWS.
1.
The OpenVXI
The VXI interprets all VoiceXML markup and acts as the main control loop. The VXI fully implements the VoiceXML 1.0 language and supports VoiceXML 2.0 except for inline W3C grammars within CDATA tags.
The VXI is tied directly into the Xerces parser. The OpenVXI uses the SAX version of the Xerces parser and does VoiceXML validation for every document. The VXI uses the SAX parser to convert the VoiceXML to an internal binary format that is then available for caching. This leads to a significant performance improvement.
2.
JavaScript API
A JavaScript engine API provides access to a JavaScript interpreter. An implementation of the API that integrates with the Mozilla SpiderMonkey JavaScript interpreter is also provided. The OpenVXI implementation adds audio to the types available in JavaScript through this API.
3.
An Internet and cache Library API
The Internet/cache interface provides platform independent access to the Internet and the ability to do write back caching of compiled information. An implementation of the API for Libwww is provided as part of the toolkit.
4.
A Logging API
A logging API is provided to hook into operations, administration, and maintenance (OA&M) capabilities. The API defines logging methods for errors, events, and diagnostics.
The core resets on a set of platform APIs. Each of the platform APIs must be implemented by anyone who wishes to use the OpenVXI to build a VoiceXML browser. The platform APIs include:
1. A Recognizer API
The Recognizer API must support the full VoiceXML specification. This requires that the API support dynamic grammar construction and grammar enabling. We discuss the recognizer requirements in the implementation section.
2. A Prompt API
The prompt API is a simple synchronous API. An API implementation must provide all the prompting services needed by the VXI interpreter. This includes: 1) the ability to play filler audio in order to support the fetchaudio capability, 2) fetch audio by URL, 3) fetch and possibly handle the Speech Synthesis Markup Language (SSML) for Text-to-Speech (TTS) processing, 4) interleave audio and TTS.
The prompt API is built around a MIME prompt typing system. It is the dual of the recognizer API because it takes any MIME typed text and returns audio. For some prompts, the VXI will build SSML strings and send them to the prompting engine to get audio output.
3. A Telephony API
The Telephony API must support all the telephony events that can be delivered and call control methods in VoiceXML.
4. DESIGN ISSUES
4.1 INTERFACES AND FRAMEWORK
The OpenVXI is designed to be a framework with each component replaceable either at run-time or at main initialization time. A number of technologies exist for this, but none of them are generally cross-platform across all flavors of UNIX and WINDOWS. C++ pure virtual interfaces also cause problems with memory management across platforms. Destruction of these interfaces across a DLL boundary can be problematic. Therefore, the OpenVXI is built on a set of C jump table interfaces. Each interface consists of a set of C function pointers collected in a structure. This allows for run-time replacement of components with different implementations, running different implementations on different lines, and is still compatible with cross DLL boundary memory management. In addition, the OpenVXI 2.0 release introduced version and implementation names into the interfaces for every component so that mixes of implementations or versions could change their behavior based on this information.

![]() The
OpenVXI is designed so that it can be integrated with a wide variety of
underlying speech technologies. The prompting, telephony, and recognition
interfaces were designed from the view point of VoiceXML. We reviewed a number
of available telephony and speech APIs including JTAPI, TAPI, JSAPI, SAPI and
the Sphinx III recognizer interface in designing these interfaces. We choose to
put into the APIs only those functions and mechanisms that are required for
VoiceXML 1.0 and VoiceXML 2.0.
The
OpenVXI is designed so that it can be integrated with a wide variety of
underlying speech technologies. The prompting, telephony, and recognition
interfaces were designed from the view point of VoiceXML. We reviewed a number
of available telephony and speech APIs including JTAPI, TAPI, JSAPI, SAPI and
the Sphinx III recognizer interface in designing these interfaces. We choose to
put into the APIs only those functions and mechanisms that are required for
VoiceXML 1.0 and VoiceXML 2.0.
Thus, all the interfaces are synchronous interfaces and don't have the added complexity of a callback mechanism because VoiceXML is a synchronous computing model at the VoiceXML level. All asynchronous event handling is delegated to the underlying platform implementations for telephony, prompting, and recognition. Telephony event handling, URL fetch timeouts, asynchronous audio delivery and a host of additional events must be handled within an implementation of these platform components. We have found this model to be effective and flexible with SpeechWorks technology, Dialogic technology, and VoIP technology. Based on discussions users of the toolkit are doing integrations to S.300, SAPI, and a number of proprietary recognizer and platform interfaces.
4.2 PROMPTING OUTPUT
VoiceXML 2.0 prompting is considerably more complex than playing a set of audio files and TTS prompts. The prompting implementation should be able to:
- Download audio and TTS from the Internet.
- Support fetchaudio if no other prompt is playing.
- Support SSML including interleaving TTS and audio for playback.
- Handle fetch failures and swapping to TTS when audio fetches fail.
Because of our synchronous model for the interpreter, we decided that the best way to implement prompting for the VoiceXML interpreter was to delegate the generation of all prompting to a single component and to leverage SSML. When the interpreter encounters a prompt component that contains SSML, it delegates the generation of the entire prompt to the component. The Queue method of the interface provides this delegation.
The Queue method takes the URL source, possibly the text, and a MIME type that specifies how to generate the prompt. Queue then blocks until the data is fetched, or the stream is started so that any errors can be returned back to the interpreter. The Queue method must then invoke any of its underlying services including URL fetching and TTS generation to start the generation of audio for the prompt.
Fetchaudio, or music on hold, is another tricky area for the interfaces. The semantics of fetchaudio are that the indicated URL should be used for playing audio, if no other audio is currently playing. Since the semantics for this segment are different from the standard audio segments, we chose to separate it out as a separate play function.
SSML is a new specification and few text-to-speech vendors fully support the specification. Many implementations of the prompting engine will have to provide a way to split the SSML into segments and queue it separately into audio and TTS until multiple engines support SSML.
4.3 RECOGNITION INPUT
The rec component is responsible for processing user input. In VoiceXML 1.0, this consisted of simple recordings and recognitions against speech and DTMF (touch-toneÒ) grammars. VoiceXML 2.0 added a required W3C Speech Recognition Grammar Format (SRGF), n-best hypotheses, and a new model for collecting multiple pieces of data with one utterance. An implementation of the rec interface should be able to:
- Support recognition against multiple parallel grammars.
- Allow for both speech and DTMF entry.
- Return one or more (n-best) recognition hypotheses with corresponding confidence scores.
- Implement the 'builtin' grammars for simple types (e.g. date, time, and currency).
- Return the waveforms from recognition utterances and recordings.
Recordings in VoiceXML may be terminated by either DTMF or an application-specified duration of silence. These parameters are passed in to the Record function of the rec interface via properties. This component must, therefore, incorporate end-of-speech detection. Likewise, DTMF grammars are supported with application-specified inter-digit timeouts and termination criteria. This requires that the rec component communicate with the hardware layer to collect DTMF, audio, and possibly hang-up or other events. Each recognizer and hardware integration will manage this complexity differently. The OpenVXI does not make any assumptions about how the rec component implements timers, links to the recognizer, or interacts with the hardware layer. Instead, the developer is expected to pass any resources (e.g. hardware channel handles) to the rec component during its initialization.
Grammars may be specified within VoiceXML directly within the grammar element or indirectly. In the second case, the text serves a dual purpose of generating text-to-speech enumerations and speech grammars. The corresponding grammar must be generated within the rec component. The W3C SRGF allows grammars to include subgrammars from specified URIs. This may require passing an Internet access component instance to the rec component on initialization. Because of the tight coupling of grammars and URI handling in the W3C specifications, we chose to delegate all fetching of grammar URLs to the recognizer interface. The implementation of the rec component must fetch the desired grammar URI and any dependent URIs that are included via the grammar import directive.
Recognition results are returned using the newly specified W3C Natural Language Semantic Markup Language (NLSML). This standard is targeted at complex grammars that may return multiple pieces of data with one utterance. For instance, the user might say "I'd like to fly from Boston to San Francisco on the Fourth" with the recognizer receiving both data directly specified by the user and determined by the grammar: { DEPART='BOS'; DESTINATION='SFO'; DATE='20010604'; AIRLINE='any'; }.
The NLSML specification is the only standard in the Voice Browser working group set that defines a return format for a recognition result, so we used this to produce a standard return interface. NLSML is also very convenient for distributed models that may be considered in a multi-modal implementation. The use of NLSML has also pointed out that the largest current gap in the VoiceXML specification is the relationship between a grammar and what is returned for a given recognition.
4.4 THE VOICEXML INTERPRETER
The VoiceXML interpreter provides direct support for both VoiceXML 1.0 and 2.0. As the document is parsed, these are converted into a common internal representation. Priority was given to 2.0 when the 1.0 specification was unclear. The language continued to evolve as the interpreter was developed and tested. A few of the challenges are explored below.
The current language combines elements of declarative and procedural models resulting in a paradigm unfamiliar to many C / C++ / Java developers. Many elements are resolved in 'document order', so handlers may appear before or after the associated code. Others like embedded ECMAScript functions and expressions are procedural. Subdialogs even provide explicit parameter lists and return values. Event handlers are scoped 'as-if-by-copy' and by name. This differs from Java and C++ in that generic event handlers defined locally have lower precedence than specific handlers defined at a lower level.
The processing for subdialog and recognition return values added considerable complexity to the VXI. Subdialogs execute in an independent ECMAScript context, requiring that root documents and associated links be reprocessed (and potentially reloaded) and that the original state be preserved. Recognition result processing depends on which of the multiple parallel grammars produced the highest confidence hypothesis. This grammar may be defined at several levels within a document or in a separate document entirely. Because of this, the interpretation process following recognition may proceed from where the grammar was defined, not where the recognition occurred. This forces the VXI to hold the recognition result until the relevant part of the document is reinitialized.
Based on interactions with our user community, we have found that this aspect of VoiceXML is the largest source of developer confusion. Developers expect a page order of execution and are surprised when the form interpretation algorithm deviates from this order.
A tight integration with ECMAScript is vital because of the explicit linkage between VoiceXML and ECMAScript. . Many elements create ECMAScript variables or have attributes containing expressions to evaluate. VoiceXML requires a very specific chain of variable scopes. All scope chain management and ECMAScript variable management is delegated to the VXIjs JavaScript interface. This interface was also used to extend the ECMAScript type system to support audio variables stored as ECMAScript variables.
4.5 ADDING CALL CONTROL
The Call Control sub-group of the W3C voice-working group is moving forward with a call control markup language. The goal of this language is to enable conference calling services, personal assistant applications, and other applications requiring advanced call control. An example use case for a personal assistant might be having the assistant place a call and then interrupt the user when the call is set-up. The interrupt might be delivered while the user is listening to voice mail through a VoiceXML browser. The call control process, which is interpreting the call control markup language, is designed to run as a peer of the VoiceXML interpreter. The call control process treats the VoiceXML interpreter as a potential end-point in call control legs. Rosenberg et. al. provide an example model in their IETF draft.
As the call control mechanism is flushed out it will have an effect on VoiceXML implementations, but currently the impact is minimal. For the OpenVXI, the issue is that call control events, which can be generic events, must be delivered during one of the blocking function calls. For example, a "telephony.newcall" event might be a future event that must be delivered to the VoiceXML layer while the system is playing a long email through text-to-speech. In the OpenVXI, this might be handled by having the Wait function in VXIprompt or the recognition function return this event back to the VoiceXML layer. The platform layer would still be handling the asynchronous events and the interpreter would continue to work with a call return model of control.
5. PERFORMANCE
Three issues dominate throughput in the OpenVXI: document loading from URIs, parsing the VoiceXML, and interpreting ECMAScripts. The performance of a fully integrated VoiceBrowser is dominated by the cost of the recognition engine and speech synthesis engine if they run on the same server. We have done extensive experiments with just the OpenVXI and have implemented a number of optimizations to enhance performance.
Document loading issues are completely analogous to traditional web servers with caching instructions, server performance, and bandwidth among the bottlenecks. For ECMAScript interpretation, the ability to handle large numbers of small scripts is useful. SpiderMonkey has proven quite capable in most tests. Surprisingly, the speed of document parsing proved to be the greatest cost in the VXI. The XML parser must perform validation against a DTD or schema and must transcode the incoming characters into Unicode. Document conversion and additional validity checks are also performed in this stage. Considerable performance benefits were obtained by compiling incoming documents and storing the result in a local cache. The size of this gain depends on the document, but it typically results in a gain of 2-10 times in OpenVXI performance. Because very few applications are truly dynamic, this efficiency gain can lead to substantial system improvements.
6. USERS
A preliminary survey shows considerable interest among academic users in the United States and within the European Community. The focus of these groups appears to be on using VoiceXML to describe speech applications, with considerably less focus on the telephony needs.
OpenVXI users are generally happy with the quality of the release. The changes in the interfaces, although not the semantics from 1.4 to 2.0 were an issue for many users of 1.4. We chose to make this change to provide a stronger base for OpenVXI development moving forward.
One issue developers find surprising is the use of C interfaces instead of C++ interfaces. We created C interfaces because this allows dynamic binding and swapping at execution time, not just at compilation and linking time, across all target operating systems. However, as an open source release C++ interfaces are easier to use and match community expectations.
Finally, implementers find the record functionality very difficult to implement correctly. The posting of very large recordings should be done using a post of multipart/mime. This requires a full implementation of POST and a compatible web server. In addition the web server slows down during large POSTS so that other requests timeout. The VoiceXML specification should be extended to make this easier to use and provide mechanism for higher performance.
7. REFERENCES
[1] Walker, M.R., Hunt, A. (eds).
Speech Synthesis Markup Language Specification for the Speech Interface
Framework, W3C working draft 3, January 2001, http://www.w3.org/TR/speech-synthesis
[2] McGlashan, S., Burnett, D.,
Danielsen, P., Ferrans, F., Hunt, A., Karam, G., Ladd, D., Lucas, B., Porter,
B., Rehor, K., Tryphonas, S. (eds). Voice Extensible Markup Language (VoiceXML)
Version 2.0, W3C Working Draft, October, 2001, http://www.w3.org/TR/2001/WD-voicexml20-20011023
[3] SpeechWorks OpenVXI 2.0, http://fife.speech.cs.cmu.edu/openvxi
[4] Rosenberg, Mataga, and Ladd,
A SIP Interface to VoiceXML Dialog Servers, IETF Internet Draft draft-rosenberg-sip-vxml-00.txt