ABSTRACT
Over the years software engineering researchers have suggested numerous techniques for estimating development effort. These techniques have been classified mainly as algorithmic, machine learning and expert judgement. Several studies have compared the prediction accuracy of those techniques, with emphasis placed on linear regression, stepwise regression, and Case-based Reasoning (CBR). To date no converging results have been obtained and we believe they may be influenced by the use of the same CBR configuration.
The objective of this paper is twofold. First, to describe the application of case-based reasoning for estimating the effort for developing Web hypermedia applications. Second, comparing the prediction accuracy of different CBR configurations, using two Web hypermedia datasets.
Results show that for both
datasets the best estimations were obtained with weighted Euclidean distance,
using either one analogy (dataset 1) or 3 analogies (dataset 2).
We suggest therefore that
case-based reasoning is a candidate technique for effort estimation and, with
the aid of an automated environment, can be applied to Web hypermedia
development effort prediction.
Keywords
Web effort prediction, Web hypermedia, case-based reasoning, Web hypermedia metrics, prediction models.
Word count: 6,509
1. INTRODUCTION
Software
practitioners recognise the importance of realistic estimates of effort to the
successful management of software projects, the Web being no exception. Having
realistic estimates at an early stage in a project's life cycle allow project
managers and development organisations to manage resources effectively.
Several techniques for cost and effort estimation have been proposed over the last 30 years, falling into three general categories [49]:
1)
Expert
judgement (EJ)
- a technique widely used, aims to derive estimates based on an expert's
previous experience on similar projects. The means of deriving an estimate are
not explicit and therefore not repeatable. However, although always difficult
to quantify, expert judgement can be an effective estimating tool on its own or
as an adjusting factor for algorithmic models [23].
2)
Algorithmic
models (AM)
- to date the most popular in the literature, attempt to represent the
relationship between effort and one or more of a project's characteristics. The
main “cost driver” in such a model is usually taken to be some notion of
software size (e.g. the number of lines of source code, number of pages, number
of links). Algorithmic models need calibration to be adjusted to local
circumstances. Examples are the COCOMO model [5], the SLIM model [40] and
function points [1].
3)
Machine
learning (ML)
- Machine learning techniques have in recent years been used as a complement or
alternative to the previous two techniques. Examples include fuzzy logic models
[31], regression trees [46], neural networks [51], and case-based reasoning
[53]. A useful summary of these techniques is presented in [22].
Recently
several comparisons have been made between the three categories of prediction
techniques aforementioned, based on their prediction accuracy
[2,8,9,19,21,22,24-27,29,33,35,36,39,43,47,48]. However no convergence has been
obtained to date. It is believed that the reasons for this are twofold [27].
First, the characteristics of the dataset used have an impact on the
effectiveness of any prediction technique. For example, CBR seems to be
favoured when datasets do not present strong linear relationships between
effort and the product size used, contrary to algorithmic models. Second, when
using CBR, there are several decisions that must be made (e.g., number of
analogies, similarity measures) which may as well influence the accuracy of
estimations.
To
date most literature in effort prediction generates and compares prediction
models using attributes (e.g. lines of code, function points) of conventional
software. This paper looks at effort prediction based on attributes of Web
hypermedia applications instead.
The
World Wide Web (Web) has become the best known example of a hypermedia system.
To date, numerous organisations across the Globe have developed thousands of
commercial and/or educational Web applications. The Web has been used as the
delivery platform for two types of applications: Web hypermedia applications
and Web software applications [10]. A Web hypermedia application is a
non-conventional application characterised by the structuring of information
using nodes (chunks of information), links (relations between nodes), anchors,
access structures (for navigation) and the delivery of this structure over the
Web. Whereas a Web software application represents any conventional software
application that depends on the Web, or uses the Web's infrastructure, for
execution. Typical applications include legacy information systems such as
databases, booking systems, knowledge bases etc. Many e-commerce applications
fall into the latter category.
Our
research focus is on proposing and comparing [17,33-36] development effort
prediction models for Web hypermedia applications. These applications have a
potential in areas such as software engineering [18], literature [52],
education [37], and training [41], to mention but a few. Readers interested in
effort estimation models for Web software applications are referred to [42,38].
This paper has two objectives. The first is to describe the application of case-based reasoning to estimating the effort for developing Web hypermedia applications. The second is to compare the prediction accuracy of several CBR configurations, based on two datasets of Web hypermedia projects.
Those objectives are reflected in the following research questions:
1) Will different CBR configurations generate significantly different prediction accuracy?
2) Which of the CBR configurations employed in this study gives the most accurate predictions for the datasets employed?
These issues are investigated using data gathered through two case studies where sets of suggested metrics for effort prediction were measured. These metrics reflect current industrial practices for developing multimedia and Web hypermedia applications [14,15].
Both
case studies gathered data on Web hypermedia projects developed by Computer
Science Honours or postgraduate students,
attending a Hypermedia and Multimedia Systems course at the University of
Auckland. The first case study took place during the first semester of 2000 and
the second, a replication of the first, took place during the first semester of
2001. The metrics collected were classified as size, effort and confounding
factors [16].
Both
case studies looked at effort prediction for design and authoring processes,
adopting the classification proposed by Lowe and Hall [32]. Using this
classification, authoring encompasses the management of activities for the actual
content and structure of the application and its presentation. Design covers
the methods used for generating the structure and functionality of the
application, and typically does not include aspects such as application
requirements elicitation, feasibility consideration and applications
maintenance.
In
this paper we chose to use CBR as a prediction technique for the following
reasons:
·
An early study comparing CBR to other prediction
techniques [33], CBR presented the best prediction accuracy when using a
dataset of Web hypermedia projects.
·
A second study, using a different dataset, also
showed good prediction accuracy using CBR [34].
·
CBR is an intuitive method and there is evidence
that experts apply analogic reasoning when making estimates [24].
·
CBR is simple and flexible, compared to
algorithmic models.
·
CBR can be used on qualitative and quantitative
data, reflecting closer types of datasets found in real life.
The
rationale for CBR is to characterise the project, for which the estimate is to
be made, relative to a number of attributes (e.g. application complexity, link
complexity etc). This description is then used to find other similar already
finished projects, and an estimate for the new project is made based on the
known effort values for those finished projects.
This
paper is organised as follows: Section 2 presents related work in development
effort prediction for Web hypermedia applications. Section 3 presents in more
depth the technique of case-based reasoning and in Section 4 we describe the
two case studies where the datasets were collected. Section 5 describes the
empirical results of applying CBR. Finally, Section 6 concludes with an
analysis of the strengths and weaknesses of using CBR and suggestions on future
work.
2. RELATED WORK
To our knowledge, there are relatively few examples in the literature of studies that investigate effort prediction models generated using data from Web hypermedia applications [17,33-36]. Most research in Web/hypermedia engineering has concentrated on the proposal of methods, methodologies and tools as a basis for process improvement and higher product quality [3,11,20,45].
Mendes
et al. [33] describe a case study involving the development of Web sites
structured according to the Cognitive Flexibility Theory (CFT) [50] principles
in which simple size metrics were collected. Several prediction models are
generated (linear regression, stepwise regression and case-based reasoning) and
compared. Results show that the best predictions were obtained using case-based
reasoning, confirming similar results using non-hypermedia applications
[47,49]. Their metrics can be applied to any hypermedia application, and
represent an initial step towards the proposal of development effort prediction
models for Web hypermedia applications. However, some of these metrics are
subjective, which may have influenced the validity of their results.
Mendes et al. [35] describes
a case study evaluation in which 37 Web hypermedia applications were used.
These were also structured according to the CFT principles and the Web
hypermedia metrics collected were organised into five categories: length size,
complexity size, reusability, effort and confounding factors. The size and
reusability metrics were used to generate top down and bottom up prediction
models using linear and stepwise regression techniques. These techniques were
then compared based on their predictive power and stepwise regression was not
shown to be consistently better than multiple linear regression. A limitation
of this study is that it only compared prediction models generated using
algorithmic techniques. The same dataset was also used as input to a case based
reasoning tool to predict effort [17], where results obtained were most
favourable.
Mendes
et al. [36] presents a case study where size attributes of Web hypermedia
applications were measured. Those attributes correspond to three size
categories, namely Length, Complexity and Functionality. For each size category
they generated prediction models using linear and stepwise regression. The
accuracy of the predictions for those six models was compared using boxplots of
the residuals, as suggested in [30]. Results suggested that all the models
offered similar prediction accuracy. The limitation of this study is also that
it only compared prediction models generated using algorithmic techniques.
Fewster
and Mendes [17] propose a prediction model for authoring and designing Web
applications and for project risk analysis using a General Linear Model. They
suggest two types of metrics: those applied to static Web hypermedia
applications and those applied to dynamic Web hypermedia applications. The
former metrics can also be used to measure other types of hypermedia and Web
applications. Their results were also an initial step towards the proposal of
effort prediction models for Web hypermedia development.
3. CASE-BASED REASONING
Case-based Reasoning involves [47]:
§ Characterising a project p for which an estimate is required, i.e., identifying project attributes (application size, link complexity etc) which can influence effort.
§ Use of this characterisation as a basis for finding similar (analogous) completed projects, for which effort is known.
§ Use of these effort values, possibly with adjustment, to generate a predicted value of effort for p.
When using CBR there are a number of parameters to decide upon [47,49]:
· Similarity Measure
· Scaling
· Number of analogies
· Analogy Adaptation
Each
parameter in turn can be split into more detail, and maybe incorporated for a
given CBR tool, allowing several CBR configurations.
3.1 Similarity Measure
Similarity Measure measures the level of similarity
between projects, i.e., cases. To our knowledge, the similarity measure most
frequently used in Software engineering and Web engineering literature is the unweighted
Euclidean distance. In the context of this investigation we have used three
measures of similarity, namely the unweighted Euclidean distance, the weighted
Euclidean distance and the Maximum measure, each of which are detailed below:
All formulas presented in this sub-section assume
that x and y represent size attributes for Web hypermedia applications, e.g., x might be page-count and y page-complexity. The pair (xi, yi) represents instances of x and y for project i.
Unweighted Euclidean
distance:
The
Euclidean distance d between the
points (x0,y0) and (x1,y1) is given
by (1) and illustrated in figure 1 by representing co-ordinates on a
two-dimensional space:
![]() (1)
(1)
The number of
attributes employed will determine the number of dimensions used.
Weighted Euclidean distance:
It is common in CBR for the attributes, i.e., features vectors to be weighted to reflect the relative importance of each feature. The weighted Euclidean distance d between the points (x0,y0) and (x1,y1) is given by the formula:
![]() (2)
(2)
where wx and wy are the weights of x and y respectively.
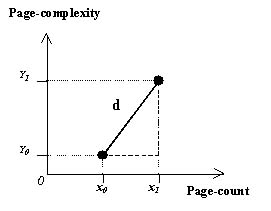
Figure 1 - Weighted Euclidean distance
using two size attributes
Maximum measure:
Using the maximum measure, the maximum feature similarity defines the case similarity. For two points (x0,y0) and (x1,y1), the maximum measure d is equivalent to the formula:
![]() (3)
(3)
This
effectively reduces the similarity measure down to a single feature, although
the maximum feature may differ for each retrieval episode.
3.2 Scaling or Standardisation
Standardisation represents the transformation of attribute values according to a defined rule such that all attributes are measured using the same unit. One possible solution is to assign one to the maximum observed value m [28] and then divide all values by m. This was the strategy chosen for the analysis carried out using CBR-Works (see Section 5).
3.3 Number of Analogies
The
number of analogies refers to the number of similar projects (cases) that will
be used to generate the estimation. In general, only the most similar cases are
selected. For Angelis and Stamelos [2] when small sets of data are used it is
reasonable to consider only a small number of analogies. In this study we have
used 1, 2 and 3 analogies, similarly to [8,9,25,26,2,43,33,34].
3.4 Analogy Adaptation
Once
the most similar case(s) has/have been selected the next step is to decide how
to generate the estimation. Choices of analogy adaptation techniques presented
in the Software engineering literature vary from the nearest neighbour [8,26],
the mean of the closest analogies [48], the median [2], inverse distance
weighted mean and inverse rank weighted mean [28], to illustrate just a few. In
the Web engineering literature, the adaptation used to date is the mean of the
closest analogies [34,36]. We opted for the mean, median and the inverse rank
weighted mean.
Mean: Represents the average of k analogies, when k>1.
Inverse rank weighted mean: Allows higher ranked analogies to have more influence than lower ones.
For example, using 3 analogies, the closest analogy (CA) would have a weight =
3, the second closest (SC) a weight = 2 and the last one (LA) a weight =1. The
estimation would then be calculated as:
(3*CA + 2*SC + LA)/6 (4)
Median: Represents the median of k analogies, when k>2.
All the estimations presented in this paper were generated using CBR-Works [44], a commercial CBR environment [44] the result of years of collaborative European research by the INRECA I & II projects [4]. It is available commercially from Empolis a knowledge management company (www.tecinno.com). The tool provides a variety of retrieval algorithms (Euclidean, weighted Euclidean, Maximum Similarity etc) as well as fine control over individual feature similarity metrics. In addition, it provides sophisticated support for symbolic features and taxonomies hierarchies as well as providing adaptation rules and formulae.
4. THE CASE STUDIES
4.1 Datasets
The analysis presented in this paper was based on two datasets containing information about Web hypermedia applications developed by Computer Science Honours or postgraduate students, attending a Hypermedia and Multimedia Systems course, at the University of Auckland.
The
first dataset (DS1, 34 applications) was obtained using a case study (CS1)
consisting of the design and authoring, by each student, of Web hypermedia
applications aimed at teaching a chosen topic, structured according to the
Cognitive Flexibility Theory (CFT) principles [50], using a minimum of 50
pages. Each Web hypermedia application provided 46 pieces of data [35], from
which we identified 8 attributes, shown in Table 1, to characterise a Web
hypermedia application and its development process.
The second dataset (DS2, 25 applications) was obtained using another case study (CS2) consisting of the design and authoring, by pairs of students, of Web hypermedia applications structured using an adaptation of the Unified Modelling Language [7], with a minimum of 25 pages. Each Web hypermedia application provided 42 pieces of data, from which we identified 6 attributes, shown in Table 2, to characterise a Web hypermedia application and its development process.
Tables
1 and 2 show the attributes that form a basis for our data analysis. Total
effort is our dependent/response variable; remaining attributes our
independent/predictor variables. All attributes were measured on a ratio scale.
The criteria used to select the attributes was [14]: i) practical relevance for Web hypermedia developers; ii) metrics which are easy to learn and cheap to collect; iii) counting rules which were simple and consistent.
Table 1 - Size and Complexity Metrics for DS1
|
Metric |
Description |
|
Page Count (PaC) |
Total number of html or shtml files |
|
Media Count (MeC) |
Total number of original media files |
|
Program Count (PRC) |
Total number of JavaScript files and Java applets |
|
Reused Media Count (RMC) |
Total number of reused/modified media files. |
|
Reused Program Count (RPC) |
Total number of reused/modified programs. |
|
Connectivity Density (COD) |
Average number of internal links[1] per page. |
|
Total Page Complexity (TPC) |
Average number of different types of media per page. |
|
Total Effort (TE) |
Effort in person hours to design and author the application |
On both case studies two questionnaires were used to collect data. The first[2] asked subjects to rate their Web hypermedia authoring experience using five scales, from no experience (zero) to very good experience (four). The second questionnaire[3] was used to measure characteristics of the Web hypermedia applications developed (suggested metrics) and the effort involved in designing and authoring those applications. On both questionnaires, we describe in depth each scale type, to avoid misunderstanding. Members of the research group checked both questionnaires for ambiguous questions, unusual tasks, and number of questions and definitions in the Appendix.
Table 2 - Size and Complexity Metrics for DS2
|
Metric |
Description |
|
Page Count (PaC) |
Total number of html files. |
|
Media Count (MeC) |
Total number of original media files. |
|
Program Length (PRL) |
Total number of statements used in either Javascript or Cascading Style Sheets. |
|
Connectivity Density (COD) |
Average number of links, internal or external, per page. |
|
Total Page Complexity (TPC) |
Average number of different types of media per page. |
|
Total Effort (TE) |
Effort in person hours to design and author the application |
To
reduce learning effects in both case studies, subjects were given a coursework
prior to designing and authoring the Web hypermedia applications, consisting of
creating a simple Web hypermedia application and loading the application onto a
Web server. In addition, in order to measure possible factors that could
influence the validity of the results, we also asked subjects about the main
structure (backbone) of their applications[4],
their authoring experience before and after developing the applications, and
the type of tool used to author/design the Web pages[5].
Finally,
CS1 subjects received training on the Cognitive Flexibility Theory authoring
principles (approximately 150 minutes) and CS2 subjects received training on
the UML's adapted version (approximately 120 minutes). The adapted version
consisted of Use Case Diagrams, Class Diagrams and Transition Diagrams.
4.2 Validity of Both Case Studies
Here
we present our comments on the validity of both case studies:
·
The metrics collected, except for effort,
experience, structure and tool, were all objective, quantifiable, and re-measured
by one of the authors using the applications developed, which had been saved on
a CD-ROM. The scales used to measure experience,
structure and tool were described in detail in both questionnaires.
· Subjects' authoring and design experiences were mostly scaled little or average, with a low difference between skill levels. Consequently the original datasets were left intact.
· To reduce maturation effects, i.e. learning effects caused by subjects learning as an evaluation proceeds, subjects had to develop a small Web hypermedia application prior to developing the application measured. They also received training in the CFT principles, for the first case study, and in the UML's adapted version, for the second case study.
· The majority of applications used a hierarchical structure.
·
Notepad and FirstPage were the two tools most
frequently used on CS1 and FirstPage was the tool most frequently used on CS2.
Notepad is a simple text editor while FirstPage is freeware offering
button-embedded HTML tags. Although they differ with respect to the
functionality offered, data analysis using DS1 revealed that the corresponding
effort was similar, suggesting that confounding effects from the tools were
controlled.
·
As the subjects who participated in the case studies were
either Computer Science Honours or postgraduate students, it is likely that
they present skill sets similar to Web hypermedia professionals at the start of
their careers. The use of students as subjects, while sometimes considered
unrealistic, is justified for two reasons: firstly, empirical evidence [6,13]
indicates that students are equal to professionals in many quantifiable
measures, including their approach to developing software; secondly, for
pragmatic considerations, having students as subjects was the only viable
option for both case studies.
5. COMPARING CBR APPROACHES
5.1 Evaluation Criteria
The
most common approaches to assessing the accuracy of prediction models are:
·
The Mean Magnitude of Relative Error (MMRE) [49]
·
The Median Magnitude of Relative Error (MdMRE) [39]
·
The Prediction at level n (Pred(n)) [48]
The MMRE is defined
as:
![]() (5)
(5)
Where i represents each observation for which effort is predicted.
The
mean takes into account the numerical value of every observation in the data
distribution, and is sensitive to individual predictions with large Magnitude
of Relative Error (MRE), where MRE is calculated as:
MREi = ![]() (6)
(6)
where
i represents each observation for
which effort is predicted.
An
option to the mean is the median, which also represents a measure of central
tendency, however it is less sensitive to extreme values. The median of MRE
values for the number i of
observations is called the MdMRE.
Another indicator which is commonly used is the Prediction
at level l, also known as Pred(l). It measures the percentage of
estimates that are within l% of the actual values. Suggestions have been made
[12] that l should be set at 25% and
that a good prediction system should offer this accuracy level 75% of the time.
We have used all
three approaches to assess the accuracy of the different CBR configurations
presented in this paper.
5.2 Method Used
As stated earlier,
during the process of applying case-based reasoning users need to configure the
CBR tool according to four different parameters (similarity measure, scaling,
number of analogies and analogy adaptation).
We
wanted to answer the following questions:
1) Will different CBR configurations generate significantly different prediction accuracy?
2)
Which of the CBR configurations employed in this study
gives the most accurate predictions for the datasets employed?
Therefore, we compared the
prediction accuracy of several estimations generated using different categories
for a given parameter (see Table 3).
We
calculated effort according to the jackknife method (also known as leave one
out cross-validation), as follows:
Step 1 CBR-works was configured to the type of distance to be used: unweighted Euclidean, weighted Euclidean or maximum.
Step 2 One datapoint was chosen and marked as "unconfirmed", in order to be considered as a new project for the purpose of this evaluation.
Step 3 The remaining 33/24 datapoints were kept in the dataset and used in the estimation process.
Step 4 For the "unconfirmed", its actual effort data was discarded, and only the known size metrics kept. This was done in an attempt to simulate a new project for use with CBR-Works to calculate estimated effort.
Step 5 Effort was estimated for 1 to 3 analogies and recorded on a spreadsheet to be used to calculate mean, median, inverse rank weighed mean, mmre, mdmre and pred(25).
Step 6 The datapoint that had been changed to "unconfirmed" was changed back to "confirmed".
Step 7 Steps 2 through 6 were repeated until all 34/25 projects had had their effort estimated. Then another distance would be chosen and the entire jackknife method would be repeated.
Table 3 - CBR approaches that were compared
|
Distance |
Analogies |
Adaptation |
Standardised variables? |
|
Unweighed Euclidean Distance |
1 |
Closest analogy |
Yes |
|
2 |
Mean |
Yes |
|
|
IRWM |
Yes |
||
|
3 |
Mean |
Yes |
|
|
IRWM |
Yes |
||
|
Median |
Yes |
||
|
Weighted Euclidean Distance |
1 |
Closest analogy |
Yes |
|
2 |
Mean |
Yes |
|
|
IRWM |
Yes |
||
|
3 |
Mean |
Yes |
|
|
IRWM |
Yes |
||
|
Median |
Yes |
||
|
Maximum Distance |
1 |
Closest analogy |
Yes |
|
2 |
Mean |
Yes |
|
|
IRWM |
Yes |
||
|
3 |
Mean |
Yes |
|
|
IRWM |
Yes |
||
|
Median |
Yes |
||
|
IRWM - Inverse Rank Weighed Mean |
|||
When using the Weighted Euclidean distance we attributed
weight=2 to measures Page Count (PaC), Media Count (MeC) and Reused Media Count
(RMC) for dataset 1 (DS1) and measures PaC and MeC for dataset 2 (DS2). All
remaining measures received weight =1. The chosen measures were those that
presented the strongest statistical relationship with effort, based on the
datasets used. An alternative to measuring the statistical relationship would
be to ask Web hypermedia authors.
5.3 Comparative Results
The
results in Tables 4 and 5 have been obtained by considering: three similarity
measures (unweighted Euclidean, weighted Euclidean and Maximum), three choices
for the number of analogies (1, 2 and 3), three choices for the analogy
adaptation (mean, inverse rank weighted mean and median) and one alternative
regarding the standardisation of the attributes. The legend used on both tables
is as follows:
|
Dist. =
distance K = number of
analogies Adap. =
adaptation
UE = Unweighted
Euclidean |
WE = Weighted
Euclidean MX = Maximum CA = Closest
Analogy IRWM = Inverse
Rank Weighed Mean |
The
maximum distance gave much worse estimations than the other two distances, on
both datasets, for all the measures of accuracy employed. The weighted
Euclidean distance gave for both datasets the best estimates, however not
always for the same number of analogies: using DS1 the best estimations were
obtained using the closest analogy whereas for DS2 the best estimations were
obtained using the mean for the three closest analogies.
Estimations obtained using DS1 were all better than those obtained using DS2. One reason might be that DS1 had 36% more projects than DS2 reflecting more options during the jack-knifing process. Another reason might be that projects on DS1 were more similar to each other or had more similar clusters than those on DS2. Further investigation of both datasets confirmed that DS1 was more homogenous than DS2.
Table 4 - Comparison of CBR approaches for DS1
|
Distance |
K |
Adaptation |
MMRE |
MdMRE |
Pred(25) |
|
UE |
1 |
CA |
0.12 |
0.10 |
88.24 |
|
2 |
Mean |
0.15 |
0.12 |
82.35 |
|
|
IRWM |
0.13 |
0.11 |
85.29 |
||
|
3 |
Mean |
0.14 |
0.11 |
82.35 |
|
|
IRWM |
0.13 |
0.12 |
85.29 |
||
|
Median |
0.14 |
0.10 |
76.47 |
||
|
WE |
1 |
CA |
0.10 |
0.09 |
94.12 |
|
2 |
Mean |
0.13 |
0.11 |
94.12 |
|
|
IRWM |
0.12 |
0.11 |
97.06 |
||
|
3 |
Mean |
0.13 |
0.09 |
88.24 |
|
|
IRWM |
0.12 |
0.12 |
94.12 |
||
|
Median |
0.14 |
0.10 |
82.35 |
||
|
MX |
1 |
CA |
0.32 |
0.34 |
26.47 |
|
2 |
Mean |
0.23 |
0.17 |
67.65 |
|
|
IRWM |
0.25 |
0.23 |
58.82 |
||
|
3 |
Mean |
0.25 |
0.15 |
76.47 |
|
|
IRWM |
0.23 |
0.16 |
67.65 |
||
|
Median |
0.31 |
0.17 |
58.82 |
One
interesting aspect of this investigation is that it suggests that, at least for
Web hypermedia projects, the weighted Euclidean distance might be the best
distance to choose to obtain good estimations. Both datasets were collected at
different points in time, using different subjects, different application
domains and still the best estimations were both obtained using the weighted
Euclidean.
Table 5 -
Comparison of CBR approaches for DS2
|
Dist. |
K |
Adap. |
MMRE |
MdMRE |
Pred(25) |
|
UE |
1 |
CA |
0.14 |
0.11 |
52.94 |
|
2 |
Mean |
0.18 |
0.18 |
44.12 |
|
|
IRWM |
0.22 |
0.17 |
55.88 |
||
|
3 |
Mean |
0.16 |
0.18 |
44.12 |
|
|
IRWM |
0.21 |
0.16 |
50.00 |
||
|
Median |
0.22 |
0.13 |
47.06 |
||
|
WE |
1 |
CA |
0.13 |
0.11 |
55.88 |
|
2 |
Mean |
0.09 |
0.11 |
67.65 |
|
|
IRWM |
0.11 |
0.09 |
67.65 |
||
|
3 |
Mean |
0.08 |
0.08 |
70.59 |
|
|
IRWM |
0.10 |
0.09 |
70.59 |
||
|
Median |
0.13 |
0.10 |
64.71 |
||
|
MX |
1 |
CA |
0.64 |
0.54 |
26.47 |
|
2 |
Mean |
0.67 |
0.57 |
05.88 |
|
|
IRWM |
0.86 |
0.55 |
14.71 |
||
|
3 |
Mean |
0.64 |
0.83 |
05.88 |
|
|
IRWM |
0.86 |
0.57 |
08.82 |
||
|
Median |
0.88 |
0.66 |
05.88 |
The answer to our first question is therefore, positive: different CBR configurations did indeed generate significantly different prediction accuracy.
In addition, the answer to our second question is that the most accurate predictions for the datasets employed were generated using the weighted Euclidean distance.
How can the results and prediction methodology presented in this paper be of benefit to Web hypermedia developers?
Whatever type of Web
hypermedia application (educational, business etc) there is at least one phase
of their development common to all - authoring. Furthermore, several Web
hypermedia applications are still developed using static HTML, even when
translated from XML. Consequently, the metrics suggested in this paper may be
of interest and useful to a wide range of Web hypermedia authors. In addition,
the prediction methodology we have used can be applied to any organisation and
to any type of application and development environment.
6. CONCLUSIONS AND FUTURE WORK
This paper described the application of case-based reasoning to estimating the effort for developing Web hypermedia applications and compared the prediction accuracy of different CBR configurations, using two Web hypermedia datasets. These datasets were obtained using two separate case studies where effort and product size measures were collected using questionnaires.
All the estimations were performed using a
Case-based reasoning tool - CBR Works. The best prediction on both datasets
were obtained using the weighted Euclidean distance, with one analogy for the
first dataset and the median of the closest three analogies for the second
dataset.
These results suggest that Case-based reasoning is a candidate technique to effort
estimation and that with the aid of an automated environment it is a practical
technique to apply to Web hypermedia development effort prediction. Further
empirical investigation is also necessary to determine if these results can
also apply to Web software applications.
As
part of our future work we plan to compare the performance of case-based
reasoning against human estimation and regression techniques, in a similar way
to [23,39,43].
To
conclude, there is an urgent need for adequate hypermedia development effort
prediction at an early stage in the development. As the use of the Web as a delivery environment increases, effort
estimation can contribute significantly to the reduction of costs and time
involved in developing Web hypermedia applications.
7. ACKNOWLEDGMENTS
Our thanks to all the referees for their insightful comments.
8. REFERENCES
[1] Albrecht,
J., and Gaffney, J. R., Software function, source lines of code, and
development effort prediction: a software science validation, IEEE Transactions
on Software Engineering, 9, 6, 639-648, 1983.
[2] Angelis, L., and Stamelos, I., A Simulation Tool
for Efficient Analogy Based Cost Estimation, Empirical Software Engineering, 5,
35-68, 2000.
[3] Balasubramanian,
V., Isakowitz, T., and Stohr, E. A., RMM: A Methodology for Structured
Hypermedia Design, Communications of the ACM, 38, 8, (August 1995).
[4] Bergmann,
R. Highlights of the INRECA Projects. In Case-Based Reasoning Research &
Development. Aha, D. & Watson, I. (Eds.) pp. 1-15. Springer Lecture Notes
in AI 2080. Berlin. 2001.
[5] Boehm,
W., Software Engineering Economics. Prentice-Hall: Englewood Cliffs, N.J.,
1981.
[6] Boehm-Davis,
D. A., and Ross, L. S., Program design methodologies and the software
development process, International Journal of Man-Machine Studies, 36, 1-19, Academic Press Limited, 1992.
[7] Booch,
G., Rumbaugh, J., and Jacobson, I.. The Unified Modelling Language User Guide,
Addison-Wesley, 1998.
[8] Briand,
L.C., El-Emam, K., Surmann, D., Wieczorek, I., and Maxwell, K.D. An Assessment
and Comparison of Common Cost Estimation Modeling Techniques, Proceedings of
ICSE 1999, Los Angeles, USA, 313-322, 1999.
[9] Briand,
L.C., Langley, T., and Wieczorek, I., A Replicated Assessment and Comparison of
Common Software Cost Modeling Techniques, Proceedings of ICSE 2000, Limerick,
Ireland, 377-386, 2000.
[10] Christodoulou, S. P.,
Zafiris, P. A., Papatheodorou, T. S., WWW2000: The Developer's view and a
practitioner's approach to Web Engineering Proc. Second ICSE Workshop on Web
Engineering, 4 and 5 June 2000; Limerick, Ireland, 75-92, 2000.
[11] Coda, F., Ghezzi, C.,
Vigna, G., and Garzotto, F., Towards a Software Engineering Approach to Web Site
Development, Proceedings of the 9th International Workshop on Software
Specification and Design, 8-17, 1998.
[12] Conte, S., Dunsmore,
H., and Shen, V., Software Engineering Metrics and Models. Benjamin/Cummings,
Menlo Park, California, 1986.
[13] Counsell, S., Swift,
S., Tucker, A., and Mendes, E. An Empirical Investigation of Fault Seeding in
Requirements Documents. Proceedings of EASE'01 - Fifth International
Conference on Empirical Assessment and Evaluation in Software Engineering,
Keele University, Staffordshire, UK, April, 2001.
[14] Cowderoy A.J.C.,
Donaldson, A.J.M., and Jenkins, J.O., A Metrics framework for multimedia
creation, Proceedings of the 5th IEEE International Software Metrics Symposium,
Maryland, USA, 1998.
[15] Cowderoy, A.J.C.
Measures of size and complexity for web-site content, Proceedings of the
Combined 11th European Software Control and Metrics
Conference and the 3rd SCOPE conference on Software Product Quality,
Munich, Germany, 423-431, 2000.
[16] DeMarco, T.,
Controlling Software Projects: Management, Measurement and Estimation, Yourdon:
New York, 1982.
[17] Fewster, R. and
Mendes, E., Measurement, Prediction and Risk Analysis for Web Applications,
Proceedings of the IEEE 7th International Software Metrics Symposium,
London, UK, 338-348.
[18] Fielding, R.T., Taylor,
R.N. Principled design of the modern Web architecture. Proceedings of the 2000
International Conference on Software Engineering. ICSE 2000 the New Millennium,
ACM, 407-16. New York, NY, USA,2000.
[19] Finnie, G.R., Wittig, G.E., and Desharnais, J-M.,
A Comparison of Software Effort Estimation Techniques: Using Function Points
with Neural Networks, Case-Based Reasoning and Regression Models, Journal of
Systems and Software, 39, 281-289, 1997.
[20] Garzotto, F.,
Paolini, P., and Schwabe, D., HMD – A Model-Based Approach to Hypertext
Application Design, ACM Transactions on Information Systems, 11, 1, (January
1993).
[21] Gray, A. and MacDonell, S., Applications of Fuzzy
Logic to Software Metric Models for Development Effort Estimation, Proceedings
of the 1997 Annual Meeting of the North American Fuzzy Information Processing
Society - NAFIPS, Syracuse NY, USA, IEEE, 394-399.
[22] Gray, A.R., and
MacDonell, S.G. A comparison of model building techniques to develop predictive
equations for software metrics. Information and Software Technology, 39,
425-437, 1997.
[23] Gray, R., MacDonell,
S. G., and Shepperd, M. J., Factors Systematically associated with errors in
subjective estimates of software development effort: the stability of expert
judgement, IEEE 6th International Metrics Symposium, Boca Raton,
November 5-6, 1999.
[24] Hughes, R.T., An
Empirical investigation into the estimation of software development effort, PhD
thesis, Dept. of Computing, the University of Brighton, UK, 1997.
[25] Jeffery, R., Ruhe,
M., and Wieczorek, I., A Comparative study of two software development cost
modeling techniques using multi-organizational and company-specific data,
Information and Software Technology, 42, 1009-1016, 2000.
[26] Jeffery, R., Ruhe,
M., and Wieczorek, I., Using Public Domain Metrics to Estimate Software
Development Effort, Proceedings of the IEEE 7th International
Software Metrics Symposium, London, UK, 16-27.
[27] Kadoda, G., Cartwright, M., and Shepperd, M.J.,
Issues on the effective use of CBR technology for software project prediction,
Proceedings of the 4th International Conference on Case-Based Reasoning, ICCBR
2001, Vancouver, Canada, (July/August 2001), 276-290.
[28] Kadoda, G., Cartwright, M., Chen, L., and
Shepperd, M.J., Experiences Using Case-Based Reasoning to Predict Software
Project Effort, Proceedings of the EASE 2000 Conference, Keele, UK, 2000.
[29] Kemerer, C.F., An Empirical Validation of
Software Cost Estimation Models, Communications of the ACM, 30, 5, 416-429.
[30] Kitchenham, B.A.,
Pickard, L.M., MacDonell, S.G., Shepperd, M.J., What accuracy statistics really
measure, IEE Proceedings - Software Engineering, (June 2001), 148, 3.
[31] Kumar, S., Krishna,
B.A., and Satsangi, P.S. Fuzzy systems and neural networks in software
engineering project management. Journal of Applied Intelligence, 4, 31-52,
1994.
[32] Lowe, D., and Hall,
W. Hypertext and the Web - An Engineering Approach, John Wiley & Sons Ltd.,
eds., 1998.
[33] Mendes, E., Counsell,
S., and Mosley, N., Measurement and Effort Prediction of Web Applications,
Proc. Second ICSE Workshop on Web Engineering, 4 and 5 June 2000; Limerick,
Ireland, 2000.
[34] Mendes, E., Counsell,
S., and Mosley, N., Towards the Prediction of Development Effort for Hypermedia
Applications, Proceedings of the ACM Hypertext'01 Conference, Aahrus, Denmark,
2001.
[35] Mendes, E., Mosley, N.,
and Counsell, S. Web Metrics – Estimating Design and Authoring Effort. IEEE
Multimedia, Special Issue on Web Engineering, (January-March 2001), 50-57.
[36] Mendes, E., Mosley,
N., and Counsell, S., A Comparison of Length, Complexity & Functionality as
Size Measures for Predicting Web Design & Authoring Effort, Proceedings of
the 2001 EASE Conference, Keele, UK, 1-14, 2001.
[37] Michau, F., Gentil,
S., Barrault, M. Expected benefits of web-based learning for engineering
education: examples in control engineering. European Journal of Engineering
Education, 26, 2, (June 2001), 151-168. Publisher: Taylor & Francis, UK.
[38] Morisio, M.,
Stamelos, I., Spahos, V. and Romano, D., Measuring Functionality and
Productivity in Web-based applications: a Case Study, Proceedings of the Sixth
International Software Metrics Symposium, 111-118, 1999.
[39] Myrtveit, I., and
Stensrud, E., A Controlled Experiment to Assess the Benefits of Estimating with
Analogy and Regression Models, IEEE Transactions on Software Engineering, 25,
4, (July/August 1999), 510-525.
[40] Putnam, L. H., A
General Empirical Solution to the Macro
Sizing and Estimating Problem, IEEE Transactions on Software Engineering, SE-4,
4, 345 - 361, 1978.
[41] Ranwez, S., Leidig,
T., Crampes, M. Formalization to improve lifelong learning. Journal of
Interactive Learning Research, 11, 3-4, 389-409. Publisher: Assoc. Advancement
Comput. Educ, USA,2000.
[42] Reifer, D.J., Web
Development: Estimating Quick-to-Market Software, IEEE Software,
(November/December 2000), 57-64.
[43] Schofield, C. An
empirical investigation into software estimation by analogy, PhD thesis, Dept.
of Computing, Bournemouth University, UK, 1998.
[44] Schulz, S. CBR-Works
- A State-of-the-Art Shell for Case-Based Application Building, Proceedings of
the German Workshop on Case-Based Reasoning, GWCBR'99 (1999).
[45] Schwabe, D. and
Rossi, G., From Domain Models to Hypermedia Applications: An Object-Oriented
Approach, Proceedings of the International Workshop on Methodologies for
Designing and Developing Hypermedia Applications, Edimburgh, (September 1994).
[46] Selby, R.W. and
Porter, A.A. Learning from examples: generation and evaluation of decision
trees for software resource analysis. IEEE Transactions on Software
Engineering, 14, 1743-1757, 1998.
[47] Shepperd, M.J., and Kadoda, G., Using Simulation
to Evaluate Prediction Techniques, Proceedings of the IEEE 7th International Software
Metrics Symposium, London, UK, 349-358, 2001.
[48] Shepperd, M.J., and Schofield, C., Estimating
Software Project Effort Using Analogies. IEEE Transactions on Software Engineering,
23, 11, 736 - 743, 1997.
[49] Shepperd, M.J., Schofield, C., and Kitchenham,
B., Effort Estimation Using Analogy. Proc. ICSE-18, IEEE Computer Society
Press, Berlin, 1996.
[50] Spiro, R. J.,
Feltovich, P. J., Jacobson, M. J., and
Coulson, R. L., Cognitive Flexibility, Constructivism, and Hypertext: Random
Access Instruction for Advanced Knowledge Acquisition in Ill-Structured
Domains, In: L. Steffe & J. Gale, eds., Constructivism, Hillsdale,
N.J.:Erlbaum, 1995.
[51] Srinivasan, K. and
Fisher, D. Machine Learning approaches to estimating software development
effort. IEEE Transactions on Software Engineering, 21, 126-137, 1995.
[52] Tosca, S.P. The
lyrical quality of links hypertext, Proceedings of Hypertext '99. Returning to
our Diverse Roots. The 10th ACM Conference on Hypertext and Hypermedia. ACM,
217-218. New York, NY, USA,1999.
[53] Watson, I. Applying
Case-Based Reasoning: techniques for enterprise systems. Morgan Kaufmann, San
Francisco, USA, 1997.