|
Yalin Wang
Intelligent Systems Laboratory
Dept. of Electrical Engineering
Univ. of Washington
Seattle, WA 98195 US
ylwang@u.washington.edu
Jianying Hu
Avaya Labs Research
233, Mount Airy Road
Basking Ridge, NJ 07920 US
jianhu@avaya.com
Copyright is held by the author/owner(s)
WWW2002, May 7-11, 2002, Honolulu, Hawaii, USA.
ACM 1-58113-449-5/02/0005.
H.4.3 [Information System Applicatoins]: Communications Applications-Information browsers
Algorithms
Table Detection, Layout Analysis, Machine Learning, Decision
tree, Support Vector Machine, Information Retrieval
The increasing ubiquity of the Internet has brought about a
constantly increasing amount of online publications. As a compact
and efficient way to present relational information, tables are
used frequently in web documents. Since tables are inherently
concise as well as information rich, the automatic understanding of
tables has many applications including knowledge management,
information retrieval, web mining, summarization, and content
delivery to mobile devices. The processes of table understanding in
web documents include table detection, functional and structural
analysis and finally table interpretation [6].
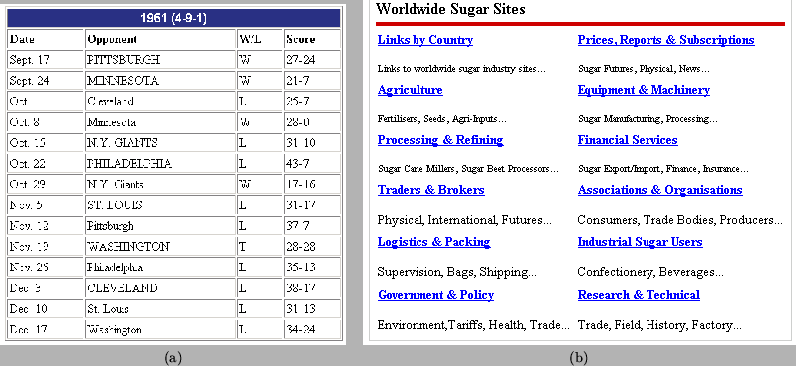
In this paper, we concentrate on the problem of table detection. The web provides users with great possibilities to use their own style of communication and expressions. In particular, people use the <TABLE> tag not only for relational information display but also to create any type of multiple-column layout to facilitate easy viewing, thus the presence of the <TABLE> tag does not necessarily indicate the presence of a relational table. In this paper, we define genuine tables to be document entities where a two dimensional grid is semantically significant in conveying the logical relations among the cells [10]. Conversely, Non-genuine tables are document entities where <TABLE> tags are used as a mechanism for grouping contents into clusters for easy viewing only. Figure 1 gives a few examples of genuine and non-genuine tables. While genuine tables in web documents could also be created without the use of <TABLE> tags at all, we do not consider such cases in this article as they seem very rare from our experience. Thus, in this study, Table detection refers to the technique which classifies a document entity enclosed by the <TABLE></TABLE> tags as genuine or non-genuine tables.
Several researchers have reported their work on web table detection [2,10,6,14]. In [2], Chen et al. used heuristic rules and cell similarities to identify tables. They tested their table detection algorithm on 918 tables from airline information web pages and achieved an F-measure of 86.50%. Penn et al. proposed a set of rules for identifying genuinely tabular information and news links in HTML documents [10]. They tested their algorithm on 75 web site front-pages and achieved an F-measure of 88.05%. Yoshida et al. proposed a method to integrate WWW tables according to the category of objects presented in each table [14]. Their data set contains 35,232 table tags gathered from the web. They estimated their algorithm parameters using all of table data and then evaluated algorithm accuracy on 175 of the tables. The average F-measure reported in their paper is 82.65%. These previous methods all relied on heuristic rules and were only tested on a database that is either very small [10], or highly domain specific [2]. Hurst mentioned that a Naive Bayes classifier algorithm produced adequate results but no detailed algorithm and experimental information was provided [6].
We propose a new machine learning based approach for table detection from generic web documents. In particular, we introduce a set of novel features which reflect the layout as well as content characteristics of tables. These features are used in classifiers trained on thousands of examples. To facilitate the training and evaluation of the table classifiers, we designed a novel web document table ground truthing protocol and used it to build a large table ground truth database. The database consists of 1,393 HTML files collected from hundreds of different web sites and contains 11,477 leaf <TABLE> elements, out of which 1,740 are genuine tables. Experiments on this database using the cross validation method demonstrate significant performance improvements over previous methods.
The rest of the paper is organized as follows. We describe our feature set in Section 2, followed by a brief discussion of the classifiers we experimented with in Section 3. In Section 4, we present a novel table ground truthing protocol and explain how we built our database. Experimental results are then reported in Section 5 and we conclude with future directions in Section 6.
Feature selection is a crucial step in any machine learning based methods. In our case, we need to find a combination of features that together provide significant separation between genuine and non-genuine tables while at the same time constrain the total number of features to avoid the curse of dimensionality. Past research has clearly indicated that layout and content are two important aspects in table understanding [6]. Our features were designed to capture both of these aspects. In particular, we developed 16 features which can be categorized into three groups: seven layout features, eight content type features and one word group feature. In the first two groups, we attempt to capture the global composition of tables as well as the consistency within the whole table and across rows and columns. The last feature looks at words used in tables and is derived directly from the vector space model commonly used in Information Retrieval.
Before feature extraction, each HTML document is first parsed
into a document hierarchy tree using Java Swing XML parser with W3C
HTML 3.2 DTD [10]. A
<TABLE> node is said to be a leaf table if
and only if there are no <TABLE> nodes among its
children [10]. Our experience
indicates that almost all genuine tables are leaf tables. Thus in
this study only leaf tables are considered candidates for genuine
tables and are passed on to the feature extraction stage. In the
following we describe each feature in detail.
In HTML documents, although tags like <TR> and <TD> (or <TH>) may be assumed to delimit table rows and table cells, they are not always reliable indicators of the number of rows and columns in a table. Variations can be caused by spanning cells created using <ROWSPAN> and <COLSPAN> tags. Other tags such as <BR> could be used to move content into the next row. Therefore to extract layout features reliably one can not simply count the number of <TR>'s and <TD>'s. For this purpose, we maintain a matrix to record all the cell spanning information and serve as a pseudo rendering of the table. Layout features based on row or column numbers are then computed from this matrix.
Given a table ![]() , assuming its numbers of rows and
columns are
, assuming its numbers of rows and
columns are ![]() and
and ![]() respectively, we
compute the following layout features:
respectively, we
compute the following layout features:
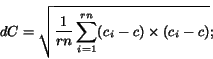
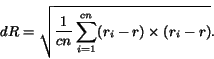
Since the majority of tables in web documents contain characters, we compute three more layout features based on cell length in terms of number of characters:
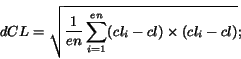
The last feature is designed to measure the cell length
consistency along either row or column directions. It is inspired
by the fact that most genuine tables demonstrate certain
consistency either along the row or the column direction, but
usually not both, while non-genuine tables often show no
consistency in either direction. First, the average cumulative
within-row length consistency, ![]() , is computed as
follows. Let the set of cell lengths of the cells from row
, is computed as
follows. Let the set of cell lengths of the cells from row ![]() be
be ![]() ,
,
![]() (considering only non-spanning
cells):
(considering only non-spanning
cells):
After the within-row length consistency ![]() is
computed, the within-column length consistency
is
computed, the within-column length consistency ![]() is computed in a similar manner. Finally, the overall
cumulative length consistency is computed as
is computed in a similar manner. Finally, the overall
cumulative length consistency is computed as
![]() .
.
Web documents are inherently multi-media and has more types of content than any traditional documents. For example, the content within a <TABLE> element could include hyperlinks, images, forms, alphabetical or numerical strings, etc. Because of the relational information it needs to convey, a genuine table is more likely to contain alpha or numerical strings than, say, images. The content type feature was designed to reflect such characteristics.
We define the set of content types
![]() . Our content type features include:
. Our content type features include:
The last feature is similar to the cell length consistency
feature. First, within-row content type consistency ![]() is computed as follows. Let the set of cell type of the
cells from row
is computed as follows. Let the set of cell type of the
cells from row ![]() as
as ![]() ,
,
![]() (again, considering only
non-spanning cells):
(again, considering only
non-spanning cells):
The within-column type consistency is then computed in a similar
manner. Finally, the overall cumulative type consistency is
computed as:
![]() .
.
If we treat each table as a ``mini-document'' by itself, table
classification can be viewed as a document categorization problem
with two broad categories: genuine tables and non-genuine tables.
We designed the word group feature to incorporate word content for
table classification based on techniques developed in information
retrieval [7,13]. After morphing [11] and removing the infrequent words, we
obtain the set of words found in the training data, ![]() . We then construct weight vectors representing
genuine and non-genuine tables and compare that against the
frequency vector from each new incoming table.
. We then construct weight vectors representing
genuine and non-genuine tables and compare that against the
frequency vector from each new incoming table.
Let ![]() represent the non-negative integer
set. The following functions are defined on set
represent the non-negative integer
set. The following functions are defined on set ![]() .
.
To simplify the notations, in the following discussion, we will
use ![]() ,
, ![]() ,
, ![]() and
and ![]() to represent
to represent ![]() ,
, ![]() ,
, ![]() and
and
![]() , respectively.
, respectively.
Let ![]() ,
, ![]() be the number of
genuine tables and non-genuine tables in the training collection,
respectively and let
be the number of
genuine tables and non-genuine tables in the training collection,
respectively and let
![]() . Without loss of
generality, we assume
. Without loss of
generality, we assume ![]() and
and ![]() . For each word
. For each word ![]() in
in ![]() ,
,
![]() , two weights,
, two weights, ![]() and
and ![]() are computed:
are computed:
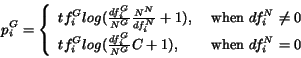
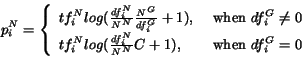
As can be seen from the formulas, the definitions of these
weights were derived from the traditional ![]() measures used in informational retrieval, with some adjustments
made for the particular problem at hand.
measures used in informational retrieval, with some adjustments
made for the particular problem at hand.
Given a new incoming table, let us denote the set including all
the words in it as ![]() . Since
. Since ![]() is constructed using thousands of tables, the words
that are present in both
is constructed using thousands of tables, the words
that are present in both ![]() and
and ![]() are only a small subset of
are only a small subset of ![]() .
Based on the vector space model, we define the similarity between
weight vectors representing genuine and non-genuine tables and the
frequency vector representing the incoming table as the
corresponding dot products. Since we only need to consider the
words that are present in both
.
Based on the vector space model, we define the similarity between
weight vectors representing genuine and non-genuine tables and the
frequency vector representing the incoming table as the
corresponding dot products. Since we only need to consider the
words that are present in both ![]() and
and ![]() , we first compute the effective word
set:
, we first compute the effective word
set:
![]() . Let the
words in
. Let the
words in ![]() be represented as
be represented as ![]() , where
, where
![]() , are
indexes to the words from set
, are
indexes to the words from set
![]() . we define
the following vectors:
. we define
the following vectors:
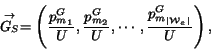
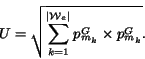
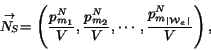
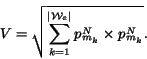
Finally, the word group feature is defined as the ratio of the
two dot products:
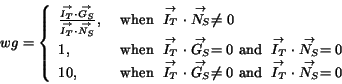
Various classification schemes have been widely used in document
categorization as well as web information retrieval [13,8]. For the table
detection task, the decision tree classifier is particularly
attractive as our features are highly non-homogeneous. We also
experimented with Support Vector Machines (SVM), a relatively new
learning approach which has achieved one of the best performances
in text categorization [13].
Decision tree learning is one of the most widely used and practical methods for inductive inference. It is a method for approximating discrete-valued functions that is robust to noisy data.
Decision trees classify an instance by sorting it down the tree from the root to some leaf node, which provides the classification of the instance. Each node in a discrete-valued decision tree specifies a test of some attribute of the instance, and each branch descending from that node corresponds to one of the possible values for this attribute. Continuous-valued decision attributes can be incorporated by dynamically defining new discrete-valued attributes that partition the continuous attribute value into a discrete set of intervals [9].
An implementation of the continuous-valued decision tree described in [4] was used for our experiments. The decision tree is constructed using a training set of feature vectors with true class labels. At each node, a discriminant threshold is chosen such that it minimizes an impurity value. The learned discriminant function splits the training subset into two subsets and generates two child nodes. The process is repeated at each newly generated child node until a stopping condition is satisfied, and the node is declared as a terminal node based on a majority vote. The maximum impurity reduction, the maximum depth of the tree, and minimum number of samples are used as stopping conditions.
Support Vector Machines (SVM) are based on the Structural
Risk Management principle from computational learning theory
[12]. The idea of structural risk
minimization is to find a hypothesis ![]() for which the
lowest true error is guaranteed. The true error of
for which the
lowest true error is guaranteed. The true error of ![]() is the probability that
is the probability that ![]() will make an error on an
unseen and randomly selected test example.
will make an error on an
unseen and randomly selected test example.
The SVM method is defined over a vector space where the goal is
to find a decision surface that best separates the data points in
two classes. More precisely, the decision surface by SVM for
linearly separable space is a hyperplane which can be written
as
The SVM problem in linearly separable cases can be efficiently solved using quadratic programming techniques, while the non-linearly separable cases can be solved by either introducing soft margin hyperplanes, or by mapping the original data vectors to a higher dimensional space where the data points become linearly separable [12,3].
One reason why SVMs are very powerful is that they are very universal learners. In their basic form, SVMs learn linear threshold functions. Nevertheless, by a simple ``plug-in'' of an appropriate kernel function, they can be used to learn polynomial classifiers, radial basis function (RBF) networks, three-layer sigmoid neural nets, etc. [3].
For our experiments, we used the ![]() system implemented by Thorsten Joachims (http://svmlight.joachims.org).
system implemented by Thorsten Joachims (http://svmlight.joachims.org).
Since there are no publicly available web table ground truth
database, researchers tested their algorithms in different data
sets in the past [2,10,14]. However,
their data sets either had limited manually annotated table data
(e.g., 918 table tags in [2], 75 HTML pages in [10], 175 manually annotated table
tags in [14]), or were collected
from some specific domains (e.g., a set of tables
selected from airline information pages were used in [2]). To develop our machine learning based
table detection algorithm, we needed to build a general web table
ground truth database of significant size.
Instead of working within a specific domain, our goal of data
collection was to get tables of as many different varieties as
possible from the web. To accomplish this, we composed a set of key
words likely to indicate documents containing tables and used those
key words to retrieve and download web pages using the Google
search engine. Three directories on Google were searched: the
business directory and news directory using key words: {table,
stock, bonds, figure, schedule, weather, score, service, results,
value}, and the science directory using key words {table,
results, value}. A total of 2,851 web pages were
downloaded in this manner and we ground truthed 1,393
HTML pages out of these (chosen randomly among all the HTML pages).
These 1,393 HTML pages from around 200 web sites
comprise our database.
There has been no previous report on how to systematically
generate web table ground truth data. To build a large web table
ground truth database, a simple, flexible and complete ground truth
protocol is required. Figure 2(a) shows
the diagram of our ground truthing procedure. We created a new
Document Type Definition(DTD) which is a superset of W3C HTML 3.2
DTD. We added three attributes for <TABLE> element,
which are ``tabid'', ``genuine table'' and ``table title''. The
possible value of the second attribute is yes or
no and the value of the first and third attributes is a
string. We used these three attributes to record the ground truth
of each leaf <TABLE> node. The benefit of this
design is that the ground truth data is inside HTML file format. We
can use exactly the same parser to process the ground truth
data.
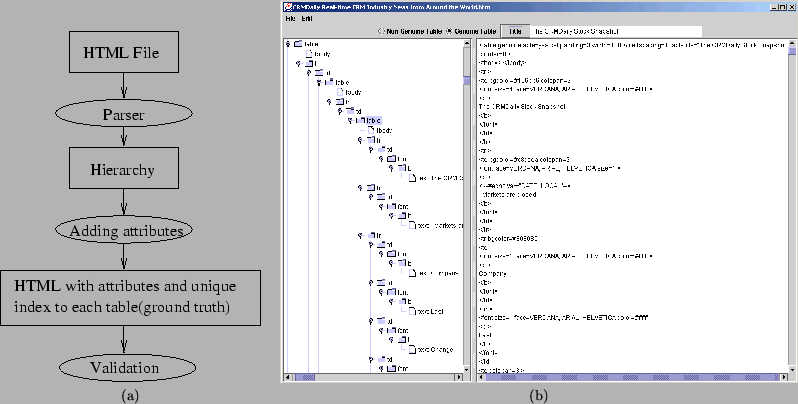
|
We developed a graphical user interface for web table ground truthing using the Java [1] language. Figure 2(b) is a snapshot of the interface. There are two windows. After reading an HTML file, the hierarchy of the HTML file is shown in the left window. When an item is selected in the hierarchy, the HTML source for the selected item is shown in the right window. There is a panel below the menu bar. The user can use the radio button to select either genuine table or non-genuine table. The text window is used to input table title.
Our final table ground truth database contains 1,393
HTML pages collected from around 200 web sites. There
are a total of 14,609 <TABLE> nodes,
including 11,477 leaf <TABLE> nodes.
Out of the 11,477 leaf <TABLE> nodes,
1,740 are genuine tables and 9,737 are non-genuine tables. Not every genuine table has its
title and only 1,308 genuine tables have table
titles. We also found at least 253 HTML files have
unmatched <TABLE>, </TABLE> pairs or
wrong hierarchy, which demonstrates the noisy nature of web
documents.
A hold-out method is used to evaluate our table classifier. We randomly divided the data set into nine parts. Each classifier was trained on eight parts and then tested on the remaining one part. This procedure was repeated nine times, each time with a different choice for the test part. Then the combined nine part results are averaged to arrive at the overall performance measures [4].
For the layout and content type features, this procedure is
straightforward. However it is more complicated for the word group
feature training. To compute ![]() for training
samples, we need to further divide the training set into two
groups, a larger one (7 parts) for the computation of the weights
for training
samples, we need to further divide the training set into two
groups, a larger one (7 parts) for the computation of the weights
![]() and
and ![]() ,
,
![]() , and a smaller one
(1 part) for the computation of the vectors
, and a smaller one
(1 part) for the computation of the vectors
![]() ,
,
![]() , and
, and
![]() . This partition
is again rotated to compute
. This partition
is again rotated to compute ![]() for each table in
the training set.
for each table in
the training set.
The output of each classifier is compared with the ground truth
and a contingency table is computed to indicate the number of a
particular class label that are identified as members of one of two
classes. The rows of the contingency table represent the true
classes and the columns represent the assigned classes. The cell at
row r and column c is the number of tables whose true
class is r while its assigned class is c. The
possible true- and detected-state combination is shown in
Table 1. Three performance measures
Recall Rate(R), Precision Rate(P) and
F-measure(F) are computed as follows:
|
|||||||||||
For comparison among different features and learning algorithms
we report the performance measures when the best F-measure is
achieved. First, the performance of various feature groups and
their combinations were evaluated using the decision tree
classifier. The results are given in Table 2.
|
||||||||||||||||||||||||||||||||||||||||
As seen from the table, content type features performed better than layout features as a single group, achieving an F-measure of 93.25%. However, when the two groups were combined the F-measure was improved substantially to 95.73%, reconfirming the importance of combining layout and content features in table detection. The addition of the word group feature improved the F-measure slightly more to 95.88%.
Table 3 compares the
performances of different learning algorithms using the full
feature set. The leaning algorithms tested include the decision
tree and the SVM algorithm with two different kernels - linear and
radial basis function (RBF).
|
As seen from the table, for this application the SVM with radial basis function kernel performed much better than the one with linear kernel. It achieved an F measure of 95.89%, comparable to the 95.88% achieved by the decision tree classifier.
Figure 3 shows two examples of
correctly classified tables, where Figure 3(a) is a genuine table and Figure 3(b) is a non-genuine table.
Figure 4 shows a few examples where our algorithm failed. Figure 4(a) was misclassified as a non-genuine table, likely because its cell lengths are highly inconsistent and it has many hyperlinks which is unusual for genuine tables. The reason why Figure 4(b) was misclassified as non-genuine is more interesting. When we looked at its HTML source code, we found it contains only two <TR> tags. All text strings in one rectangular box are within one <TD> tag. Its author used <p> tags to put them in different rows. This points to the need for a more carefully designed pseudo-rendering process. Figure 4(c) shows a non-genuine table misclassified as genuine. A close examination reveals that it indeed has good consistency along the row direction. In fact, one could even argue that this is indeed a genuine table, with implicit row headers of Title, Name, Company Affiliation and Phone Number. This example demonstrates one of the most difficult challenges in table understanding, namely the ambiguous nature of many table instances (see [5] for a more detailed analysis on that). Figure 4(d) was also misclassified as a genuine table. This is a case where layout features and the kind of shallow content features we used are not enough -- deeper semantic analysis would be needed in order to identify the lack of logical coherence which makes it a non-genuine table.

|
For comparison, we tested the previously developed rule-based
system [10] on the same database. The
initial results (shown in Table 4
under ``Original Rule Based'') were very poor. After carefully
studying the results from the initial experiment we realized that
most of the errors were caused by a rule imposing a hard limit on
cell lengths in genuine tables. After deleting that rule the
rule-based system achieved much improved results (shown in
Table 4 under ``Modified Rule
Based''). However, the proposed machine learning based method still
performs considerably better in comparison. This demonstrates that
systems based on hand-crafted rules tend to be brittle and do not
generalize well. In this case, even after careful manual adjustment
in a new database, it still does not work as well as an
automatically trained classifier.
|
A direct comparison to other previous results [2,14] is not possible currently because of the lack of access to their system. However, our test database is clearly more general and far larger than the ones used in [2] and [14], while our precision and recall rates are both higher.
Table detection in web documents is an interesting and challenging problem with many applications. We present a machine learning based table detection algorithm for HTML documents. Layout features, content type features and word group features were used to construct a novel feature set. Decision tree and SVM classifiers were then implemented and tested in this feature space. We also designed a novel table ground truthing protocol and used it to construct a large web table ground truth database for training and testing. Experiments on this large database yielded very promising results.
Our future work includes handling more different HTML styles in
pseudo-rendering, detecting table titles of the recognized genuine
tables and developing a machine learning based table interpretation
algorithm. We would also like to investigate ways to incorporate
deeper language analysis for both table detection and
interpretation.
We would like to thank Kathie Shipley for her help in collecting
the web pages, and Amit Bagga for discussions on vector space
models.