The enormous growth of the World Wide Web in recent years has made it important to develop document discovery mechanisms based on intelligent and focused crawling techniques. The next-generation Web, the Semantic Web, that is currently being developed as a meta Web, building on the existing one, changes the classical crawling task. Metadata that is based on ontologies will exist distributed fragments over the Web. Thus, means for the intelligent and ontology-focused metadata discovery are required. In this paper we propose a comprehensive framework for ontology-focused crawling of Web documents and RDF-based relational metadata in parallel. The framework includes means for adding a lexical layer to RDF(S)-based ontologies and metadata, relevance computation strategies, an implementation and an empirical evaluation that has shown promising results.
Ontology, Metadata, Semantic Web, Focused Crawling.
Recently, it has been seen that ontologies and metadata are the key ingredients for the Semantic Web. In this context, ontologies describe domain theories for the explicit representation of the semantics of the metadata. The Semantic Web relies heavily on these formal ontologies that structure underlying metadata enabling comprehensive and transportable machine understanding [1]. Furthermore, one of the core design principles and a reason for the success of the WWW was decentralization (see [2]). The same should apply for the Semantic Web with the result that anyone should be able to design or reuse an existing ontology, to define metadata according to this ontology, and, finally to put this metadata on the Web without any registration process. At this point it is becomes obvious that metadata will exist in distributed fragments. Thus, means for the intelligent and ontology-focused metadata discovery are required. The enormous growth of the World Wide Web in recent years has made it important to develop document discovery mechanisms based on intelligent and focused crawling techniques [5,6,7]. In its classical sense a crawler is a program that retrieves Web pages, commonly used by a search engine or a Web cache. Focused crawling is a technique which is able to crawl particular topical portions of the World Wide Web quickly without having to explore all Web pages. In this paper we propose means for the intelligent, ontology-focused discovery of distributed RDF-based metadata and documents, in parallel. Thus, the crawling framework that builds on and extends existing work in the area of intelligent and focused document crawling. We here propose an ontology-focused crawling framework and an implemented system, CATYPERL, that provide the following main achievements:
Ontology and Metadata Management, including a lexical layer (see http://kaon.semanticweb.org/2001/11/kaon-lexical.rdf) for RDF(S)-based ontologies and metadata.
Relevance Computation based on conceptual and linguistic means reflecting ontological structures.
A user interface embedded into the comprehensive tool environment supporting the overall engineering and maintenance process.
The framework has been empirically evaluated. The evaluation results have shown that the crawling based on the rich ontological structures as background knowledge clearly outperforms standard crawling techniques.
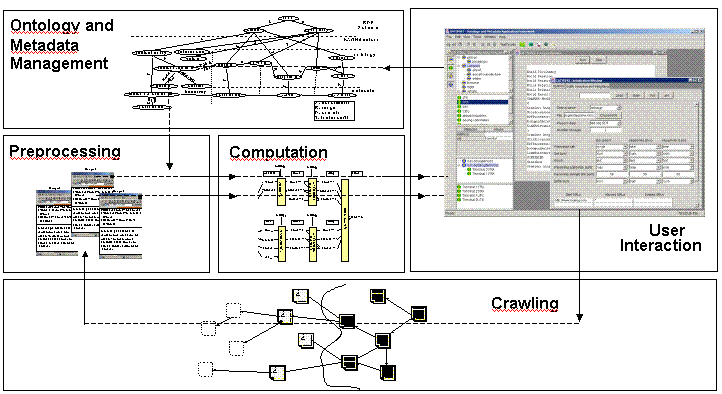
The overall focused crawling process that we support consists of two main cycles. First, the ontology and metadata management cycle, second, the crawling cycle. The figure below depicts the two cycles in the context of the different system components. The first cycle is mainly driven by the human engineer. He defines the crawling target in the form of the instantiated ontology and the metadata, respectively. This cycle also provides the output of the crawling process to the user in the form of a document list, further metadata structures and proposals for ontology evolvement to the user. The second cycle comprises ontology-focused crawling. This cycle interacts automatically with the data contained on the Web. It connects to the ontology, the metadata and their lexica to determine relevance and to focus the further search for ontology-relevant metadata and documents contained on the Web.
The two interconnected cycles served as input for the specification of the system architecture, where we pursue a modular, component-based approach. The figure introduced above depicts the overall crawling architecture, the main components and their interactions. It roughly consists of the following five core components:
User Interaction (provided by comprehensive graphical user interface),
Ontology and Metadata Management (based on our RDF(S)-extensions, see http://kaon.semanticweb.org/2001/11/kaon-lexical.rdf)
Preprocessing (including means for simple linguistic normalization, RDF extraction, etc.)
Relevance Computation (to determine relevance of a given page for focusing the overall search)
Web Crawling
The focused crawler takes at least as input an ontology with its lexicon. If according to the ontology existing metadata is already available (e.g. coming from a relational database, manual annotation, authoring process, etc.) it serves also as input. An important aspect is that for the metadata also the metadata lexicon serves as input to the crawler. Thus, if an instance of the class "Person" is defined and the metadata instance is identified with "Raphael Volz", then this lexical information serves as background knowledge for the crawler. Finally, several parameters may be defined. This includes the definition of ontology and metadata constraints, threshold, the selection of an relevancy measure. The output of the focused crawler is a set of documents (for each document a set of most relevant concepts is assigned), discovered metadata according to the selected ontology, and suggestions for the evolvement of the ontology. Based on the user input as described above, the crawling process is started, resulting in a first set of retrieved documents. The retrieved documents are preprocessed using the preprocessing module. Preprocessing is splitted into several steps, roughly distinguishable in RDF metadata extraction and validation against the ontology, text processing and normalization and hyperlink extraction. The preprocessed segments of a document serve as input to the relevance computation process that extends the URL list for further processing, the document list and the RDF metadata container. The user may now inspect the results of the crawling process, add RDF metadata to the local system and refine the evolving ontology based on analysis of the documents contained in the document list.
The overall crawling framework has been fully implemented and evaluated using standard measures like harvest rate. The evaluation studies have shown that the knowledge-intensive focused crawling approach clearly outperforms standard techniques for crawling and focused crawling strategies relying on keywords and taxonomies. A detailed description of the overall framework, its implementation and evaluation is online available at [4].