We present a new version of SiteIF, a recommender system for a Web site of multilingual news. Exploiting a content-based document representation, we describe a model of the user's interests based on word senses rather that on simply words.
There are two main advantages of a content-based approach: first, the model predictions, being based on senses rather then words, are more accurate; second, the model is language independent, allowing navigation in multilingual sites. We also report the results of a comparative experiment (word-based vs. sense-based) that has been carried out to give a quantitative estimation of the content-based approach improvements.
SiteIF is a personal agent for a bilingual news web site that learns user's interests from the requested pages. In this paper we propose to use a content-based document representation as a starting point to build a model of the user's interests. As the user browses the documents, the system builds the user model as a semantic network whose nodes represent senses (not just words) of the documents requested by the user. Then, the filtering phase takes advantage of the word senses to retrieve new documents with high semantic relevance with respect to the user model (e.g. see [3] for some eperimental evidences about that).
The use of senses rather than words implies that the resulting user model is not only more accurate but also independent from the language of the documents browsed. This is particularly important for multilingual web sites, that are becoming very common especially in news sites or in electronic commerce domains.
The SiteIF web site has been built using a news corpus kindly put at our disposal by ADNKRONOS, an important Italian news provider. The corpus consists of about 5000 parallel news (i.e. each news has both an Italian and an English version) partitioned by ADNKRONOS in a number of fixed categories: culture, food, holidays, medicine, fashion, motors and news. The average length of the news is about 265 words.
In a content-based approach to user modelling there are two crucial questions to address: first, a repository for word senses has to be identified; second, the problem of word sense disambiguation, with respect to the sense repository, has to be solved.
The sense-based approach adopted for the user model component of the SiteIF system makes use of WORDNET DOMAINS, a multilingual lexical database [1] (extended from the well-known WORDNET) where English and Italian senses are aligned and where each sense (i.e. a synset in WORDNET terminology) is annotated with domain labels (such as Medicine, Architecture and Sport) selected from a set of about two hundred labels hierarchically organized.
|
A domain may include synsets of different syntactic categories: for instance MEDICINE groups together senses from Nouns, such as doctor#1 and hospital#1, and from Verbs such as operate#7. Second, a domain may include senses from different WORDNET sub-hierarchies. For example, SPORT contains senses such as athlete#1, deriving from life_form#1, game_equipment#1, from physical_object#1 sport#1 from act#2, and playing_field#1, from location#1.
For the purposes of SiteIF system we have considered 41 disjoint labels which allow a good level of abstraction without loosing relevant information (i.e. in the experiments we have used SPORT in place of VOLLEY or BASKETBALL, which are subsumed by SPORT).
A technique, recently proposed in [4], called Word Domain Disambiguation, has been adopted to disambiguate the word senses that define the user interest model.
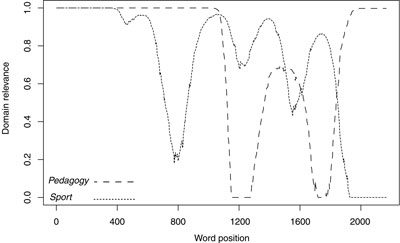
Word Domain Disambiguation is a variant of Word Sense Disambiguation where the role of domain information is exploited. The hypothesis is that domain labels (such as MEDICINE, ARCHITECTURE and SPORT) provide a natural and powerful way to establish semantic relations among word senses, which can be profitably used during the disambiguation process. In particular, domains constitute a fundamental feature of textual coherence.
The starting point in the algorithm design was the previous work in word domain disambiguation reported in [4]. The basic idea is that the whole disambiguation process can be profitably decomposed into two tasks: first, choosing a domain label for the target word among those reported in WORDNET DOMAINS; then, select a sense of the target word among those which are compatible with the selected domain. In the last version [5], WDD algorithm takes also into account domain variations, considering portions of text within which domain relevance is calculated.
Results obtained at the SENSEVAL-2 competition [6] on Word Sense Disambiguation confirm that domain information can be used to disambiguate with a very high level of precision. In particular for the task English All Words (all the words in the documents have to be disambiguated) our algorithm obtained .748 and .357 in terms of precision and recall respectively. The rather low degree of recall reflects the fact that just few words in a text carry relevant domain information (i.e. the algorithm does not take into account 'generic' senses).
Setting a comparative test among user models, going beyond a generic user satisfaction is not straightforward. However, we wanted to estimate how much the new version of SiteIF (synset-based) actually improves the performances with respect to the previous version of the system (word-based). To evaluate whether and how the exploitation of the synset representation improves the accuracy of the semantic network modelling and filtering, we arranged an experiment whose goal was to compare the output of the two systems against the judgements of a human advisor.
First, a test set of about one hundred English news from the ADNKRONOS corpus were selected homogeneously with respect to the overall distribution in categories (i.e. culture, motors, etc...). The test set has been made available as a Web site, and then 12 ITC-irst researchers were asked to browse the site, simulating a user visiting the news site. Users were instructed to select a news, according to their personal interests, to completely read it, and then to select another news, again according to their interests. This process was repeated until ten news were picked out.
After this phase, a human advisor, who was acquainted with the test corpus, was asked to analyze the documents chosen by the users, and to propose new potential interesting documents from the corpus. The advisor was requested to follow the same procedure for each document set: documents were first grouped according to their ADNKRONOS category, and a new document was searched in the test corpus within that category. If a relevant document was found, it was added to the advisor proposals, otherwise no document for that category is proposed. Eventually, an additional document, outside the categories browsed by the user could be added by the advisor. On average, the advisor proposed 3 documents for a user document set.
Standard figures for precision and recall have been calculated considering the matches among the advisor and the systems documents.
Table 2 shows the result of the evaluation. The first column takes into account the document news, the second only the ADNKRONOS categories.
Table 2: Comparison between word-based UM and synset-based UM | ||||||||||||||||||||