
WebCorp is an ongoing project, the aim of which is to produce a search tool designed to present examples of word usage from the Web in a form suitable for linguistic analysis. We illustrate how WebCorp adds a layer of refinement to standard Web search by allowing extended wildcard search and by providing tailored output in a customisable format.
Corpus linguistics is the study of a body of electronic text to discover facts about the language which are not observable or quantifiable by manual means. However, the design and creation of text corpora can be expensive and corpora are fixed at a point in time; they do not provide access to up-to-date information on language use or the changes which are occurring.
An obvious source of such language data is the Web. As a text-based information source, the Web also has tremendous potential value as a linguistic resource. It is orders of magnitude larger than any finite corpora, constantly updated and expanded, broad in domain coverage and potentially available without cost to the research community.
Existing Web search engines are geared towards information retrieval rather than towards the extraction of linguistic data: the user enters a searchterm and is shown the URLs of pages `matching' that searchterm in some way, perhaps with a short description of or extract from each page. Where an extract is shown it will not will it be in a format suitable for linguistic analysis, nor will it be customisable or show all of the instances of the word or phrase from each page. In order to extract a thorough set of examples of a word or phrase in context, a user must enter the searchterm and then visit each of the pages returned by the search engine individually, locate the required context on the page and extract this in some way. Existing search engines also offer very limited support for pattern matching and wildcards, which are essential for linguistic study.
Our WebCorp system (1) is designed to run `on top of' existing Web search engines, using them to locate relevant Web pages, before accessing each of these pages, parsing the HTML and extracting all occurrences of the user-specified word or phrase. The word or phrase is displayed within a context of between 1 and 50 words to the left and to the right. The user can also specify case sensitivity. WebCorp offers several output formats, including standard HTML, plain text, and HTML tables with centred searchterms (see Figure 1), a format familiar to linguists. The user can also choose whether to display the URLs of the originating Web pages. If URLs are not displayed, the concordance lines appear in a list with the searchterm as a link to the originating Web page.
Several search engines display the size in kilobytes of each matching page. This may give some indication of the relative lengths of Web texts but it may also be that file size is inflated by a large proportion of HTML markup. WebCorp instead shows both the number of running words (tokens) and the number of unique words (types) in the body of each page. The type/token ratio can be used as an indication of the lexical diversity of each text and the proportion of the text which the searchterm occupies. WebCorp also has a word list feature, where the user can click on a link under each URL to view a frequency or alphabetically ordered list of all the words on that page.
A staple of corpus linguistic research is access to information about collocates, or words to the left and right of the search term, which relate to its particular senses. WebCorp records the collocates of the searchterm in a default span of 4 words to the left and to the right (optionally filtering out stopwords). It then summarises the collocational data in a table and highlights the key phrases (see Figure 2). This information can be used to refine the original searchterm, in this case by focussing on a specific type of surgery (brain surgery, cosmetic surgery, etc). Some search engines offer a form of searchterm refinement, using records of previous queries (e.g. AltaVista's `Others searched for ...' suggestions), perhaps supplemented with external thesaural information (e.g. Excite.com's `Zoom In' feature (2)). WebCorp, however, is unique in that it derives the refined searchterms directly from the matching texts.
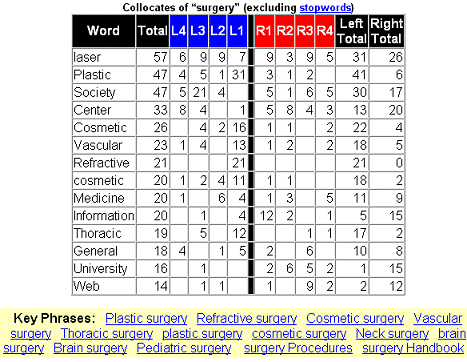
This is something which the current generation of Web search engines does not fully support but it is essential in linguistic data analysis and useful in more general Web search. Some search engines, including Google, FAST and Lycos (3), do not support wildcards at all. AltaVista offers some support for wildcards, allowing searchterms of the form `run*' (matching `run', `running', `runner', etc) but does not `*ing' (matching on word endings). None of the major search engines allows the wildcard to represent a whole word within a phrase, e.g. `the * man' where the middle word is unspecified and could match any word in a text (4).
WebCorp does support this extended use of wildcards. For example, the searchterm `two * short of a' will match `two sandwiches short of a picnic', `two cans short of a six-pack', etc. Furthermore, WebCorp offers more complex pattern matching options, where the searchterm the (boat|ship) s(u|a|i)nk* will match the boat sank, the boat sunk, the boat sinked, the ship sank, etc. This is achieved by automatically expanding all of the possible combinations in the user's searchterm in to an `OR' query: "the boat sank" OR "the boat sunk" OR ....
Rather than treat a text corpus as a static entity, our research approach is to view a corpus as a flow of chronologically ordered text. We can thus monitor changes or trends in the use of particular words or phrases and are able to detect when new coinages first appear in the language (5).
This diachronic approach to text analysis is not currently possible on the Web, where the only readily available chronological information is the `Last-modified' header passed by Web servers when a page is requested. Of the 917 pages returned by Google for the searchterm `soccer' (6), 53% included the `Last-modified' HTTP header; a large proportion of Web servers do not send this header when a page is requested by a client and there is thus no reliable way of knowing when the document was written.
Even when the server does return the `Last-modified' header, this is not ideal for linguistic purposes or for other purposes where the date of authorship or first publication of an article is required. The Resource Description Framework (RDF) put forward by the W3C as a metadata standard (7) may go some way toward solving this problem, by allowing the page author to include a qualifier to specify exactly what the `date' represents: `Created', `Valid', `Available', `Issued' or `Modified' (8). We strongly support the W3C recommendation that this specific type of date information be adopted on the Web, through the use of RDF. It is essential for diachronic linguistic analysis and invaluable in more general Web search.
The Web is of great value as a source of linguistic data but existing Web search engines are geared toward information retrieval and thus are not ideal for the task. We have shown how our WebCorp system adds layers of refinement to the Web search process, meeting the requirements for extracting examples of word or phrase usage from the Web and displaying them in a linguistically useful form. Although designed primarily for corpus linguists, WebCorp is being used by language teachers and learners, publishers, lexicographers, journalists, and people who are conducting general web searches or who seek guidance as to word use in writing.