We propose the concept of context-dependent information exploration. User evaluations during information exploration are relative and depend on the quality of the search results. Information exploration systems for Web bookmarking and image database retrieval are described and the results of tests to verify the applicability of context-dependent information exploration are presented.
Context-Dependent, Information Exploration, Bookmarks, WWW.
Information exploration is performed to identify data from a body of information by specifying evaluation criteria. User evaluations are not absolute; relative evaluations are performed based on the quality of the information in the database. Furthermore, interpretation will differ between individuals. Therefore, it is necessary to interpret the context of the user's evaluation in order for the information exploration system to identify relevant and appropriate data.
The purpose of this paper is to propose methods for identifying the context of a search and techniques for identifying contextual data. Context has an important effect on the information exploration process and the type of search (browsing, identifying key data, deleting unnecessary data, etc.) is a form of data evaluation. Therefore, it is suggested that systems may be able to identify user's intention by analyzing the evaluation procedure.
This study will focus on the scope and content of browsed information. We will also discuss methods to identify the context of information exploration. Context-dependent bookmarking and image database retrieval systems are proposed and a discussion on specialization according to data type and the utilization of the proposed systems is presented.
In this section, existing methods for the retrieval of information from the Web and image databases are discussed.
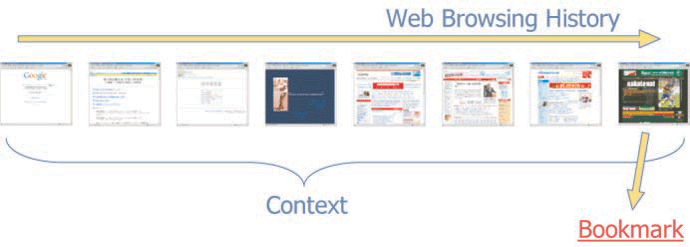
When a user searches for information on the Web, a preferred Web page is identified and is often bookmarked using standard tools in conventional browsers. This is called a conventional bookmark. Conventional bookmarking does not involve evaluation of the context of the data. Therefore it is impossible to extract the user's intention from a conventional bookmark, which contains only a title and the URL. Thus, We believe that context-dependent bookmarks should provide bookmark facility. The image of the conventional Web information retrieval appears in figure 1.
There is much related research about bookmarks. PowerBookmarks [1] an enhancement of bookmarking functionality, WebSticker [2] a development of user interface, Investigation of User Behavior [3] and so on. Many studies have been made on the use of bookmarks. However, there has been no study that tried to utilize the context of the bookmarks.
The relevance feedback in image retrieval involves a user's selection of an interesting or appropriate image among retrieval results. An image is selected based on comparisons within a group of similar images. The selected image and the differences between the selected and the rejected images therefore reflect the user's interests. Such evaluations are based solely on differences and can be regarded as context-dependent information.
The process of identifying context-dependent bookmarks involves (a) extracting relative characteristics keywords and (b) calculating context-dependent bookmark rankings.
(a)Extracting Relative Characteristics Keywords
This function extracts keywords for Web pages based on characterization of the data. It should clearly differentiate between the characteristics of bookmarked Web pages. We apply the vector space model for indexing and representation of documents and queries. In this paper, use of the TFIDF method (the Term Frequency/Inverted Document Frequency) [4] is examined. In the way of TFIDF, a dimension of a term is weighted highly if it is frequent in relevant documents but infrequent in the collection as a whole. The vector space model with TFIDF weights is relevant to search engine development. It is possible to perform a relative characterization by setting the range of the Inverted Document Frequency though the range of IDF is usually fixed, because the document sets for TFIDF are different if the contexts of browsing histories are different.
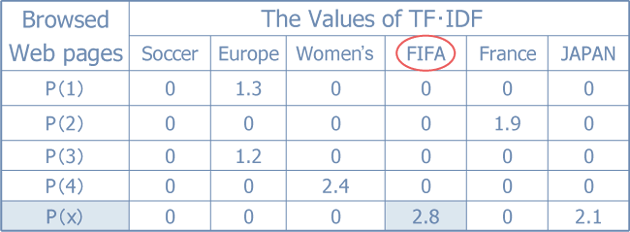
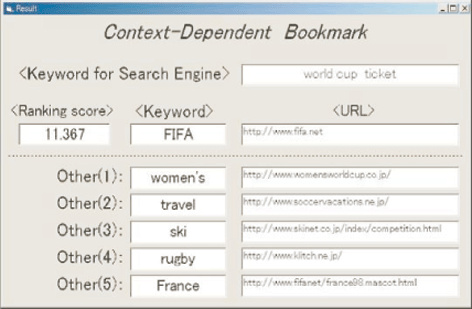
The TFIDF value is the weight of the term in each document. Figure 2 shows the extraction of relative characteristics keywords. In this table, each row corresponds to each browsed Web page. P(x) is a bookmarked Web page. Each column corresponds to a keyword as a dimension of vectors. The value in each cell corresponds to the value of TFIDF of the keyword in each Web page. The gray cell has the maximum value of TFIDF in the bookmarked page. This means that the relative characteristics keyword of bookmarked page is 'FIFA'.
(b)Calculating Context-Dependent Bookmark Rankings
We have established two hypotheses for context-dependent bookmark-ranking as follows:
Therefore, we propose the ranking can be established based on the pattern of browsing and the similarity of the results. The ranking is calculated based on the following equation:
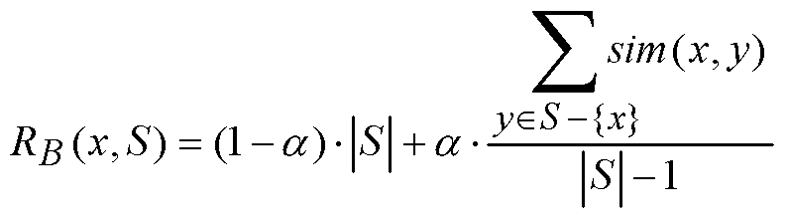

The first term states that the ranking will be high if the user browses a significant number of pages. The second term is the average similarity, and shows that the ranking is high if the sites are similar.
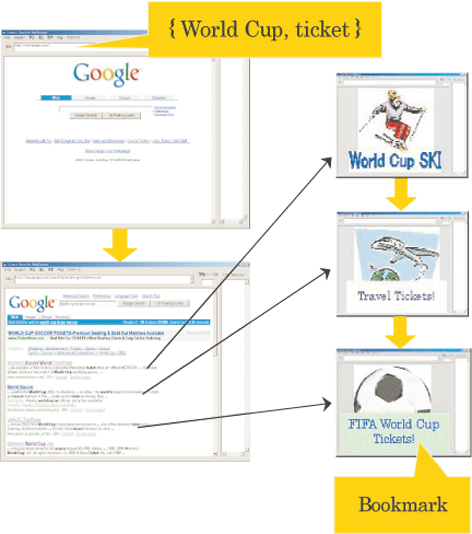
A prototype system can be applied to a popular browser (Internet Explorer) as functionality to define context-dependent bookmarks. The instance of browsing Web pages using the application of the system is shown in figure 3. The resulting final screen shot is shown in figure 4. The aim of the search was to identify Web pages that sold tickets to the 2002 FIFA World Cup. Keywords 'world cup' and 'ticket' were entered into a Web search engine, and several pages were examined. Figure 4 shows the output from the proposed system, which details the search keywords, URLs, a representative keyword and a set of rankings.
Context-Dependent Bookmarks are not only useful for remembering, visualizing and sharing bookmarks and improving reuse ratio. They can also be used as queries for unnavigated Web pages. Because they have the context including the user's intentions in Web information retrieval. Therefore, the user can automatically retrieve Web information along the user's intentions using Context-Dependent Bookmarks as queries .
In the proposed image retrieval system, the images are clustered by SOM [5]and displayed on a single screen, called a clustered information space. The user selects an image in the space and context-dependent information is derived by comparison of the selected image with the surrounding images. A query is calculated by this context-dependent information. Similar images for this query are found in a database and are then presented to the user in a clustered information space. The workflow of image retrieval is shown in Figure 5.
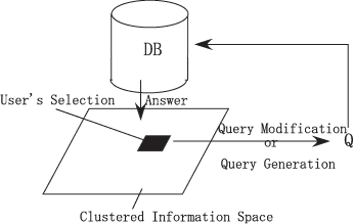
We propose two ways to calculate Context-Dependent Information. One is a Query Generation. The other is Query Modification.
1. Query Generation
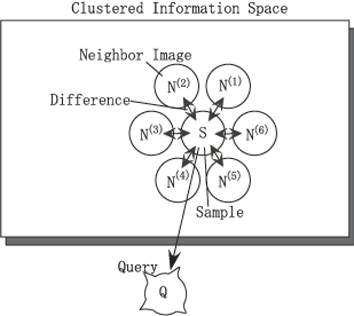
Let the feature vector of the selected image be S and the average feature vector of its immediate neighbors be N as shown in Figure 6. If the difference between ith element of S and ith element of N is bigger than the threshold, S's ith element must be modified because this element is interesting for the user. Modified value is regarded as ith element of query vector. It is defined as follows:
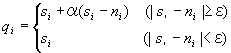
Where α is a constant that indicates the rate of amplification, and ε is the threshold value.
2. Query Modification
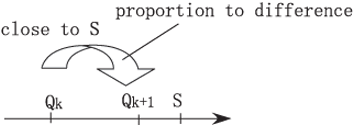
In this case, the query Qk+1 is calculated by modifying previous query Qk as ith element of Qk come close to ith element of S (as shown in figure 7). Query Modification is defined as follows:
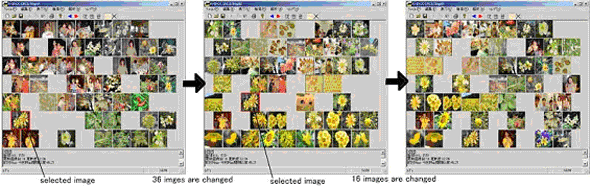
Tests were performed using Query Generation technique and the result is shown in Figure 8. The middle result is different from right result though same image is selected. The reason is that this retrieval is dependent on context.
Context-dependent information exploration systems for Web bookmarking and image retrieval were proposed. Context-dependent bookmarks use characteristic keywords of browsed Web pages and a ranking is assigned to the bookmark. Image retrieval using two search techniques and a clustered information space facilitates efficient searching of large databases. The results of tests verify the applicability of the proposed techniques.
This research is partly supported by the research for the grant of Scientific Research (12680416 and 13224054) form Ministry of Education, Science, Sports and Culture of Japan.