A Software Architecture for Personalized Product Catalog System for On-Line Shopping
Jayanta Basak, Raghuram Krishnapuram
IBM India Research Lab
Block – I, Indian Institute of Technology
Hauz Khas, New
Delhi – 110016
India
e-mail : bjayanta@in.ibm.com, kraghura@in.ibm.com
and
Tushit Jain
Department of
Electrical Engineering
Indian
Institute of Technology
Madras
India.
Abstract
A personalized product catalog is a hierarchically arranged subset of products displayed in accordance with the interest of an individual user. In this paper, we introduce a product graph that stores the products (the product-ids) as the vertices and the similarities between product attributes in the edges. The user’s interests are stored in user interest hierarchy (UIH), which in turn stores one exemplar product-id in each leaf node. The product catalog is dynamically generated from the product graph and UIH. Personalized Product Catalog System (PPCS) is more storage-efficient than storing individual catalogs for individual customers.
- Introduction:
In catalogs [1], generally product categories are arranged in the form of a hierarchy such that each node down the hierarchy represents a subcategory and the leaf nodes represent the actual products. In a personalized product catalog, it is desirable to generate product hierarchies according to the user interests as opposed to having a static hierarchy. However, maintaining product hierarchies for each individual customer requires enormous storage.
Attempts have been made to design
product catalogs based on collaborative filtering [1,2,4,5], and analysis of
clickstreams. Here we present a personalized product catalog where each user’s
interests are stored in the form of a hierarchy called User Interest Hierarchy
(UIH). The products and their attributes are stored in a database table called
product table (PT) and the relationships between the products are stored in the
form of a graph called product graph (PG). The product table (PT) and the
product graph (PG) are the static parts of the personalized product
recommendation model and are common for all users. The user interest hierarchy
(UIH) is a dynamic data structure and can be updated depending on his/her
behavior (e.g., purchase history and clickstream) or feedback. Whenever a
customer logs in, the products satisfying his interests, are retrieved from the
product graph and the product table based on his/her UIH.
- Description of PPCS
Figure 1 schematically describes the software architecture for the personalized product catalog system (PPCS) where PT and PG are static data structures and UIH is specific to the user. UIH can change dynamically for each user. The interest patterns stored in the UIH correspond to a set of product attributes that are present in the product table, and the similarities that are stored in the edges of the product graph are the similarities between these product attributes.
Product Table (PT) stores the products in a database table in form of product-ids and the corresponding set of attributes assuming that the product attributes exhaustively address all customers’ interests.
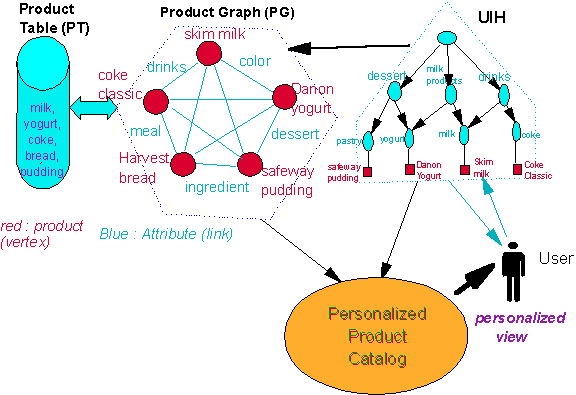
Figure 1 : A schematic diagram of the software architecture of PPCS
Product Graph (PG) is
described as M = {P, R} where ![]() is the set of
vertices representing product-ids, and
is the set of
vertices representing product-ids, and ![]() is the set of edges
representing similarity indices between the attributes of products
is the set of edges
representing similarity indices between the attributes of products ![]() and
and ![]() such that
such that
![]() (1)
(1)
where each ![]() denotes a numeric
value in [0,1] indicating the degree of similarity between the values of
k-th attribute of the two products
denotes a numeric
value in [0,1] indicating the degree of similarity between the values of
k-th attribute of the two products ![]() and
and ![]() .
.
User Interest Hierarchy (UIH)
is a hierarchical representation of a user’s interests. Each leaf node of a UIH
stores an exemplar product-id. Each node i in UIH is assigned a weight (![]() ) indicating the relative degree to which user is interested
in that subcategory. The UIH of a user can be built off-line, or on-line [6]
(e.g., by considering the navigational pattern of a user through the web site).
In the off-line mode of generation, given a set of products, a user can select
a list of products of his/her choice. From the chosen list of products, a UIH
can be generated by using a hierarchical clustering algorithm or by building a
classification tree (classifying the products into classes “chosen” and “not
chosen”) [3]. The leaf nodes containing the products the user did not like can
be pruned, giving rise to the UIH. The exemplar product at each leaf node can
be set by considering the most typical product in that leaf node.
) indicating the relative degree to which user is interested
in that subcategory. The UIH of a user can be built off-line, or on-line [6]
(e.g., by considering the navigational pattern of a user through the web site).
In the off-line mode of generation, given a set of products, a user can select
a list of products of his/her choice. From the chosen list of products, a UIH
can be generated by using a hierarchical clustering algorithm or by building a
classification tree (classifying the products into classes “chosen” and “not
chosen”) [3]. The leaf nodes containing the products the user did not like can
be pruned, giving rise to the UIH. The exemplar product at each leaf node can
be set by considering the most typical product in that leaf node.
3 Generation of Product Hierarchy
Procedure Traverse(i)
describes a recursive method for generating the product catalog by traversing
the UIH. Sort(i) returns a sorted list of indices to product attributes under node ![]() , sorted according to the weights (
, sorted according to the weights (![]() ). Property(k)
is a list of attributes that are associated with the nodes in the path
from the root to the node k of the UIH (
). Property(k)
is a list of attributes that are associated with the nodes in the path
from the root to the node k of the UIH (![]() ). Append(L1,L2)
appends list L2 with list L1 and returns the concatenated list.
Get_product(i) returns the
exemplar product-id stored at the leaf node of UIH. Match(i,j,Property(k)) returns a value if the attributes specified
by the list Property(k) takes a high value in the corresponding link. It
invokes a similarity measure between two products i and j.
Various similarity measures exist in the literature [7]. We have defined two
measures in the following ways :
). Append(L1,L2)
appends list L2 with list L1 and returns the concatenated list.
Get_product(i) returns the
exemplar product-id stored at the leaf node of UIH. Match(i,j,Property(k)) returns a value if the attributes specified
by the list Property(k) takes a high value in the corresponding link. It
invokes a similarity measure between two products i and j.
Various similarity measures exist in the literature [7]. We have defined two
measures in the following ways :
![]() (2)
(2)
and
![]() (3)
(3)
the product j is
retrieved if ![]() where product i is
the in the leaf node of hierarchy.
where product i is
the in the leaf node of hierarchy.
Begin
Property(root) = null;
Traverse(root)
End
Procedure Traverse(i) //Traverses from the i-th node of UIH //
Begin
If level(i) != LEAF then
Begin
Sort(i);
For each k in Sort(i),
Begin
Property(k) = Append(Property(i), attribute(k));
Traverse(k);
End
End
Else
p = Get_product(i);
For all j in ![]() (i.e., the set of
edges connected to product p in the product graph)
(i.e., the set of
edges connected to product p in the product graph)
Begin
If ![]() != NULL then
!= NULL then
Begin
If Match(p,j, Property(i))
= HIGH then
Begin
Set(i)
= Set(i)![]()
End
End
End
Return();
End
If the number of products (n) is much less than the number of customers (m), and the average number of categories a user interested (N) in is much less than the total number of products (n) then PPCS is much more storage efficient than maintaining individual product catalogs. For example, if N = 10, n = 100, and m = 1000 then the personalized catalogue requires a space of O(104) and static catalogues will require a space of O(105).
4
Experimental Results
To verify the effectiveness of
PPCS, we have implemented a pilot model along with the necessary GUIs for
retrieving cars (automobiles) of different models from a database of 200
automobiles.
The UIH is generated from a decision tree which is a classification
hierarchy such that the products are divided into those which the user likes
and those he does not like. UIH is
obtained by removing the leaf nodes of no interest to the user. A measure for
the degree of interest in a node is obtained as
m ( NL
) = D r( NL ) = r ( NP ) - PL.r
( NL ) (4)
where NL
and NP are the indices of the present and parent nodes,
r( N ) = nN
/ ( yN + nN ) and PL = ( nL + yL ) / ( nP +yP )
nN :
number of products not chosen by user at node N
yN :
number of products chosen by user at node N
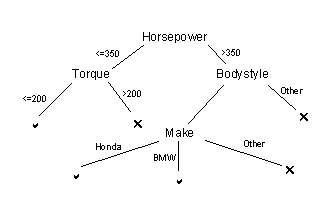
Figure 2 : A decision tree generated from the
user’s feedback about his likes and
dislikes for a list of products.
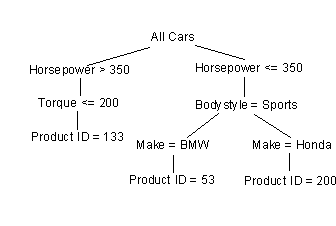
Figure 3 : A UIH generated from the decision tree in
Figure 2.
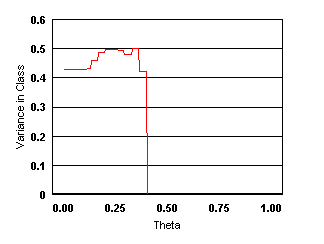
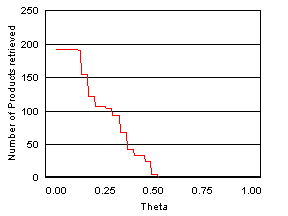
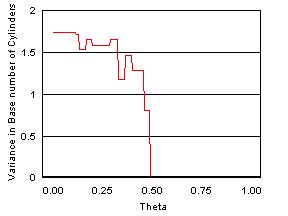
It is seen from the results that with the increase in threshold ![]() (i.e., choosiness
of the user), the number of products
retrieved decreases in a linear fashion. The variation in the attribute values
does not show much dependency on the threshold initially but decreases very
rapidly after a certain value. The behavior is almost the same for both
similarity measures (the figures illustrate results for the second measure).
(i.e., choosiness
of the user), the number of products
retrieved decreases in a linear fashion. The variation in the attribute values
does not show much dependency on the threshold initially but decreases very
rapidly after a certain value. The behavior is almost the same for both
similarity measures (the figures illustrate results for the second measure).
5 Discussion
We proposed a software architecture for a personalized product catalog. Studies can be made for performance improvement by considering various similarity metrics and matching algorithms, and methods for on-line and off-line construction of user interest hierarchy. The present article presents one such method for the task of dynamic generation of a product catalog. The impact of this software architecture can be tested from the user satisfaction from their feedback.
A dual problem in the B2C paradigm is to dynamically select customers (users) for targeting certain products or advertisements so that the expected click-through is maximized. In order to perform this dual task, a customer graph (CG) may be maintained instead of a product graph where each customer is connected to every other customer based on some similarities of their profiles.
|
|
|
|
|
|
|
|
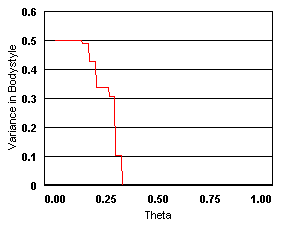
Figure 4 : The nature of variation
in the number of products and different product attributes with the threshold ![]() .
.
References :
(1) M.S. Lee and A. W. Moore, “Learning Automated Product Recommendations without Observable Features : An Initial Investigator,” The Robotics Institute, Carnegie Mellon University, pp. 1-35 (April 1995).
(2) D. M. Chickering and D. Heckerman, “Targeted Advertising with Inventory Management,” Proc. ACM Electronic Commerce, pp. 17-20, 2000.
(3) L. Brieman et al. Classification and Regression Trees, Wadsworth, Belmont, California, 1984.
(4) A. Prestchner and S. Gauch, “Personalization on the web,” Technical Report ITTC-FY2000-TR-13591-01, Dept. of Electrical Engineering and Computer Science, University of Kansas, USA.
(5) M. Pazzani, “A framework for collaborative, content-based and demographic filtering,” Artificial Intelligence Review, pp. 393-408, 1999.
(6) D.H. Widyantoro, T.R. Iorger, and J.Yen, “An adaptive algorithm for learning changes in user interests,” Proc. CIKM, Kansas, 405-412, 1999.
(7) S. Santini and R.C. Jain, “Similarity measures,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 2, pp. 871-883, 1999.