In this paper, we describe the JAFER ToolKit project which is developing a simplified XML based API above the Z39.50 protocol [1]. The ToolKit allows the development of 39.50 based applications (both clients and servers) without detailed knowledge of the complexities of the protocol. We have used this toolkit to build a number of web applications based on XSLT and also some experimental WebServices.
Z39.50, XML, XSLT, Java, programming, WebServices, SOAP
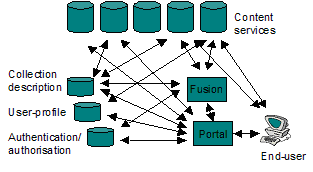
JAFER (Java Access For Electronic Resources) is a project funded by the JISC (http://www.jisc.ac.uk) in the UK under their Distributed National Electronic Resource (DNER) programme. The DNER is an attempt to integrate the various online educational and informational resource into a national managed environment for accessing high quality assured information resources. The proposed architecture for the DNER [2] involved aggregating different services via middleware brokers. The end user would interact with a portal which would bring together different resources into an integrated web-based user interface. This is illustrated in Figure 1.
The DNER sees the NISO/ISO Z39.50 Search and Retrieval protocol [1] as one of the key components of this initiative acting as one of the major protocols between the middleware and the content providers. Whilst Z39.50 is used by the majority of library systems, its complexity has resulted in a lack of mainstream implementations outside of the library sector. The JAFER toolkit is developing a simplified XML based Application Programming Interface (API) implemented in Java above the Z39.50 protocol thus enabling Z39.50 to be used within XML frameworks such as Cocoon, JetSpeed or Java Server Page based web servers.
Z39.50 is a NISO standard (also ratified by ISO) for a generic search and retrieve protocol intended for searching any database or data-source. It is a stateful protocol i.e. a connection is established and maintained between client and server throughout their interactions. It offers the following basic services:
It also offers an Explain service for determining the capabilities of a Z39.50 server, and Extended Services for adding additional capabilities (such as database updating). Typically a Z39.50 server will only offer a subset of these services.
Z39.50 abstracts the database to allow interoperability between clients and servers. A Z39.50 query is constructed by using search points which are then mapped by the server onto the underlying database. A set of agreed search points is called an attribute set. The most common attribute set is bib-1 used primarily for bibliographic searching and which defines search points, known as Use attributes, such as author, title etc.
A Z39.50 client will also request records in a particular format called a Record schema. If a Z39.50 server claims support for that format, it should construct records in that format from the underlying database. As a result of this, a client needs to know nothing about the underlying structure of the database in order to operate with a server, it merely needs to know the attribute sets and record schema supported by a server. Many bibliographic Z39.50 servers use a library specific record structure known as MARC as the default record format. The binary structure of a MARC record is defined by ISO 2709. A few Z39.50 servers can also return XML based records. Z39.50 has its own equivalent to XML called GRS.1 (Generic Record Syntax 1). Like XML this is an extensible tree based format. In order to understand a GRS.1 record you need to know its Tag Set - this is essentially the list of element names that occur within the GRS.1 record and so is analogous to an XML DTD.
The primary goal of the JAFER project has been to produce a toolkit which allows the development of applications which use the Z39.50 protocol but which hides its complexities. The JAFER toolkit includes both client tools (allowing the searching of Z39.50 servers) and server tools (allowing a database to be accessible by Z39.50 clients). In both cases, the JAFER toolkit provides an abstraction layer above the Z39.50 protocol. As we developed the toolkit we based this abstraction layer very heavily on XML; in many aspects JAFER behaves as a bridge between Z39.50 and XML. JAFER is written in Java and is licensed under OpenSource. More information about the toolkit and downloads can be found at http://www.jafer.org.
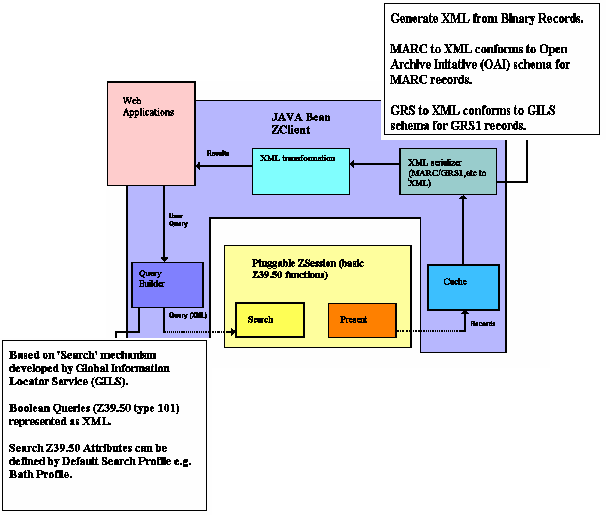
The JAFER client has been implemented as a Java bean so that it can be used in a variety of applications and environments. Its overall structure is shown in Figure 2.
The query language used for submitting queries to the bean is based on an XML schema, so it can be passed to the bean as an XML structure. We originally considered using XML query for this schema but discounted this for a number of reasons:
The query syntax adopted is an XML'ised form of the Z39.50 Type 101 query based on the 'search' mechanism being developed by the Global Information Locator Service (GILS) [3]. A typical query is shown in Figure 3.
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<query>
<boolean>
<and>
<constraintModel>
<constraint>
<semantic>4</semantic> title
<relation>3</relation> equals
<position>3</position> any position in field
<structure>2</structure> word
<truncation>100</truncation> do not truncate
<completeness>1</completeness> incomplete
</constraint>
<model>Macbeth</model> SEARCH TERM
</constraintModel>
<constraintModel>
<constraint>
<semantic>1003</semantic> author
<relation>3</relation>
<position>3</position>
<structure>2</structure>
<truncation>100</truncation>
<completeness>1</completeness>
</constraint>
<model>Shakespeare</model> SEARCH TERM
</constraintModel>
</and>
</boolean>
</query>
The bean also provides a QueryBuilder object which provides a programmatic way of building a query by exposing an API with functions such as node(String semantic, String term), and(Node, Node), or(Node, Node) and not(Node). The XML based query syntax supported by the bean has the natural Boolean operators of AND, OR and NOT. The type-101 Z39.50 query syntax, however, has three binary operators AND, OR and AND-NOT. The JAFER bean applies de Morgan rules to convert queries using the more natural Boolean operators to the Z39.50 operators. The bean then handles the process of establishing a Z39.50 connection and issuing the search.
In terms of record retrieval, the bean offers a record cursor based API. The function SetCurrentRecord is used to indicate the record of interest. The bean checks whether this record has already been retrieved into the cache, and if not then uses the Z39.50 Present service to pull down a number of records into the cache. Fine tuning of the cache behaviour can be achieved by changing the properties of the JAFER bean. The record can be accessed directly in its raw format, but the power of the JAFER bean is that it can present the record to the user in an XML format. This is a two stage process. An XML serialiser converts the record from its binary format to an XML representation of the format, for instance, a MARC record (such as UKMARC, MARC21 etc. [4]) is converted to the Open Archives Initiative (OAI) XML schema for MARC [5]. A typical record is shown in Figure 4.
MARC 21 Field 260: 260##$aNew York, N.Y. : $bElsevier, $c1984.
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<MARCRecord dbName="MAIN*BIBMAST">
…
<varfield id=â€260†i1=â€â€ i2=â€â€>
<subfield label=â€aâ€>New York, N.Y. : </subfield-a>
<subfield label=â€bâ€> Elsevier,</subfield-b>
<subfield label=â€câ€>1984</subfield-c>
</varfield>
The record can be accessed in this format, but this is often not an intuitive format to work with. The bean can therefore transform this XML to a more "user-friendly" XML schema, for instance the OAI MARC XML is converted to MODS schema (a new schema for bibliographic records being developed by the Library of Congress which uses element names such as "author", "title" etc.). This transformation is controlled by an XSLT transform so can be configured as required. The whole configuration of the bean (such as serialisers and transformers for different record syntaxes) is also configured by XML. A similar approach is taken with GRS.1 records. Since GRS.1 is a tree based structure there is canonical representation in XML. However, for ease of use an XSLT defined transform maps this to an XML schema derived from the Global Information Location Service (GILS) record schema [6].
The user of the JAFER bean can then process the XML record in a number of ways - they can use their own tools for walking the DOM such as a SAX parser; they can use a simplified interface supplied by the bean for accessing XML elements based on a GetField API, or they can convert the XML to a suitable form via an XSLT engine (the XSLT utility classes used by the bean can be re-used for this purpose). Alternatively the bean can be used as an XML generator for publishing frameworks such as Cocoon [7] or portals such as JetSpeed [8].
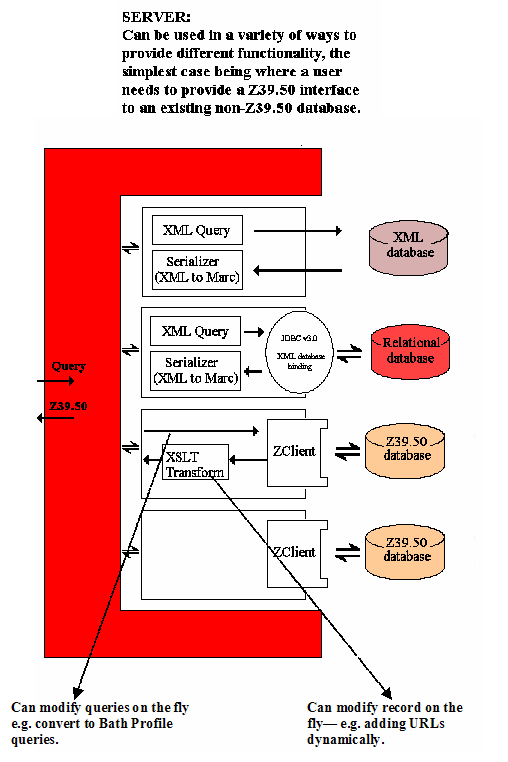
The JAFER Server component of the toolkit is still very much in development, but in its current design it forms a mirror image to the client bean. Whereas the client provides an XML layer above the Z39.50 protocol, the server can be viewed as providing a Z39.50 layer above XML. This is illustrated in Figure 5. The server handles incoming Z39.50 requests by querying against an XML view of a database, and in this case uses a serializer when responding to Z39.50 requests to convert from a suitable XML format (for example OAI MARC XML) to the required binary format (for example MARC). The data-provider is responsible for providing a suitable XML view of the data. This may be a simple XSLT transformation if the data is coming from an XML database, or maybe an XML binding to a relational database.
The JAFER client bean may itself be used as an XML datasource for the JAFER server. This allows the construction of Z39.50 proxies for authentication purposes or additional record processing on the fly (for example providing record syntax conversion services). It also allows multiple separate physical Z39.50 services to be combined as a single Z39.50 server for the purposes of cross-searching.
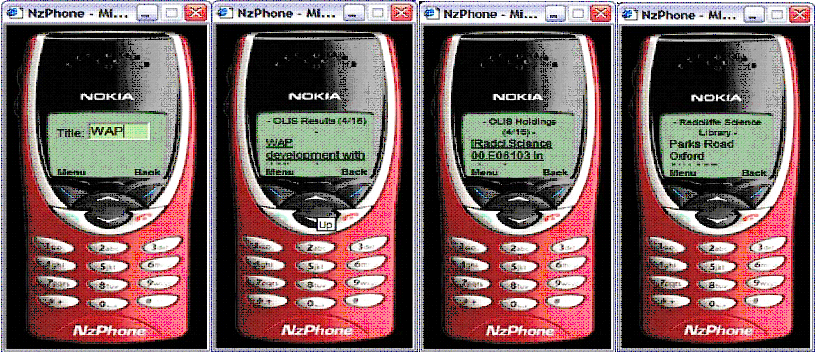
We have used the JAFER toolkit to build a number of applications illustrating various aspects of the toolkit including its versatility and ease of use. These applications have been developed rapidly once the toolkit had been developed. The applications include:
We have also done some experimental work with WebServices including implementing some simplified SOAP search protocols and an UDDI to GILS gateway.
Another obstacle to mainstream acceptance of Z39.50 in today's WebService based environment is that fact that it uses a binary encoding for transmitting the messages between the client and server. The structure of the Z39.50 messages is specified in ASN.1 (Abstract Syntax Notation 1) defined by ISO 8824. ASN.1 is a type description language and hence forms the same role for Z39.50 as Interface Definition Languages (IDL) form for Remote Procedural Calls (RPC) applications. Typically ASN.1 structures are encoded using Basic Encoding Rules (BER) defined in ISO 8825. ASN.1 and BER are often used in security applications such as smart-cards due to the efficient use of space and error correction facilities offered by BER. However, there is work progressing on encoding ASN.1 defined structures to XML thus producing a specification for XML Encoding Rules (XER) [11]. It is thus possible to generate an XML Schema definition of the ASN.1 definition for Z39.50 and thus produce a WSDL definition of the various Z39.50 operations such as search, retrieve, sort etc.
Such a WSDL definition would include a SOAP binding which would pass XER encoding XML within a SOAP:Envelope thus becoming a fully fledged WebService. However, since WSDL is extensible to including other bindings it could be possible to define a BER binding within the same description. A full exposition of this can be found at http://www.lib.ox.ac.uk/jafer/ez3950.html/z3950-wsdl.html.
At present, however, such a WebService is still difficult to implement for a number of reasons:
The JAFER bean described above offers a fairly straightforward mechanism for implementing a simple search WebService onto existing Z39.50 servers. Both the query and the returned records are XML documents and so could easily be wrapped into a SOAP:Envelope. Such an approach would need to be augmented. In particular, additional parameters would need to be added to the SOAP request to determine which database to search, what record format to return, how many records to return and the initial record to return. The response would need to include multiple records (requiring an additional XML root node) and other information about the server. An approach developed by ourselves and other members of the GILS community can be found at http://www.gils.net/search. This approach also uses XML namespaces to support alternative query syntaxes which is in keeping with Z39.50 in general, although this makes it difficult to implement using standard SOAP toolkits.
A similar SOAP search service is also under development as an experimental protocol by various members of the Z39.50 community, ourselves included, in an initiative called ZiNG (Z39.50 Next Generation). This WebService is simpler than the GILS approach (for example it does not support different query languages) and as such should be supported by most existing SOAP toolkits. It also uses a text based query language rather than an XML structure so that the service can be implemented over HTTP GET as well as HTTP POST. Further details of this can be found at http://www.loc.gov/z3950/agency/zing. Both the ZiNG and the GILS approaches lose much of the versatility of the original Z39.50, however.
Another WebService that we have developed using the JAFER client bean is a UDDI to GILS gateway. GILS (Global Information Location Service) is an open standard for searching basic information descriptions. As part of how an organization manages information content, these "locator records" give users inside and outside the organization a simple way to find information. Such descriptions may be inserted into Web documents, generated from databases or just stored as documents. Providers offer locator records over the Internet through GILS-compliant software, including Internet search engines, database systems like Oracle, or traditional library catalogue systems[12]. UDDI is a protocol and schema for accessing and managing registries of WebServices currently under development lead by a number of software vendors including Microsoft, IBM, Sun etc. [13]. Many GILS servers can be search via Z39.50 and return the location information as a GRS.1 record. The JAFER bean can thus be used to search a GILS server and return the records as XML which conforms to the GILS XML Schema. There is a fairly straightforward crosswalk between a GILS XML record and the businessEntity and businessService XML structures in UDDI. We have expressed this mapping as an XSLT transforms and thus can generate UDDI XML documents from a GILS server. The actual UDDI gateway is more complex than this in that it also allow replication of records from the GILS server into a central UDDI registry on a most recently used basis and also supports the publication of UDDI records by acting as a proxy to a central UDDI registry. A fuller description of the UDDI to GILS gateway can be found at http://www.gils.net/uddi.html.
Firstly we would like to aknowledge the JISC DNER programming without whose funding the development of the JAFER toolkit would not have been realized. We would also like to thank our co-conspirators within the GILS community (namely Sebastian Hammer of IndexData, Dave Vieglais at the University of Kansas, and Eliot Christian at the United States Geological Survey), who have been working on the GILS Search WebService and advised on the UDDI to GILS Gateway, and also all the participants in the development of the experimental ZiNG WebServices (including Thomas Place, Tilburg University; Ian Ibbotson, Knowledge Integration Ltd; Mark Needleman, Alan Kent, SIRSI; Ralph LeVan, Kelly Womble and Pat Stevens, OCLC; Ben Soares, EDINA; Jan Gatenby and Rob Koopman, PICA; Poul Henrik Jørgensen, DBK; Theo van Veen, Koninlijke Bibliotheek; and Ray Denenberg and Larry Dixson, Library of Congress).
![]()